











Diseñar una estructura de datos robusta es la columna vertebral de cualquier sistema de información confiable. En el corazón de este diseño se encuentra el Diagrama de Relaciones de Entidades (ERD), un plano visual que define cómo interactúan las entidades de datos. Sin embargo, un diagrama solo no garantiza eficiencia. El verdadero poder de un ERD surge cuando se combina con estrategias rigurosas de normalización. El objetivo es claro: lograr un almacenamiento sin redundancia cero. Esto significa eliminar los datos duplicados para garantizar la integridad, reducir los costos de almacenamiento y simplificar el mantenimiento.
La redundancia no es meramente un problema de almacenamiento; es una falla lógica esperando causar inconsistencias. Cuando los datos se repiten en múltiples filas o tablas sin una relación estricta, las anomalías de actualización se vuelven inevitables. Un cambio en un solo atributo podría requerir actualizaciones en decenas de lugares. Si uno se omite, la base de datos se corrompe. Esta guía explora la mecánica de la normalización en el contexto del diseño de ERD, centrándose en la aplicación práctica y la pureza estructural.
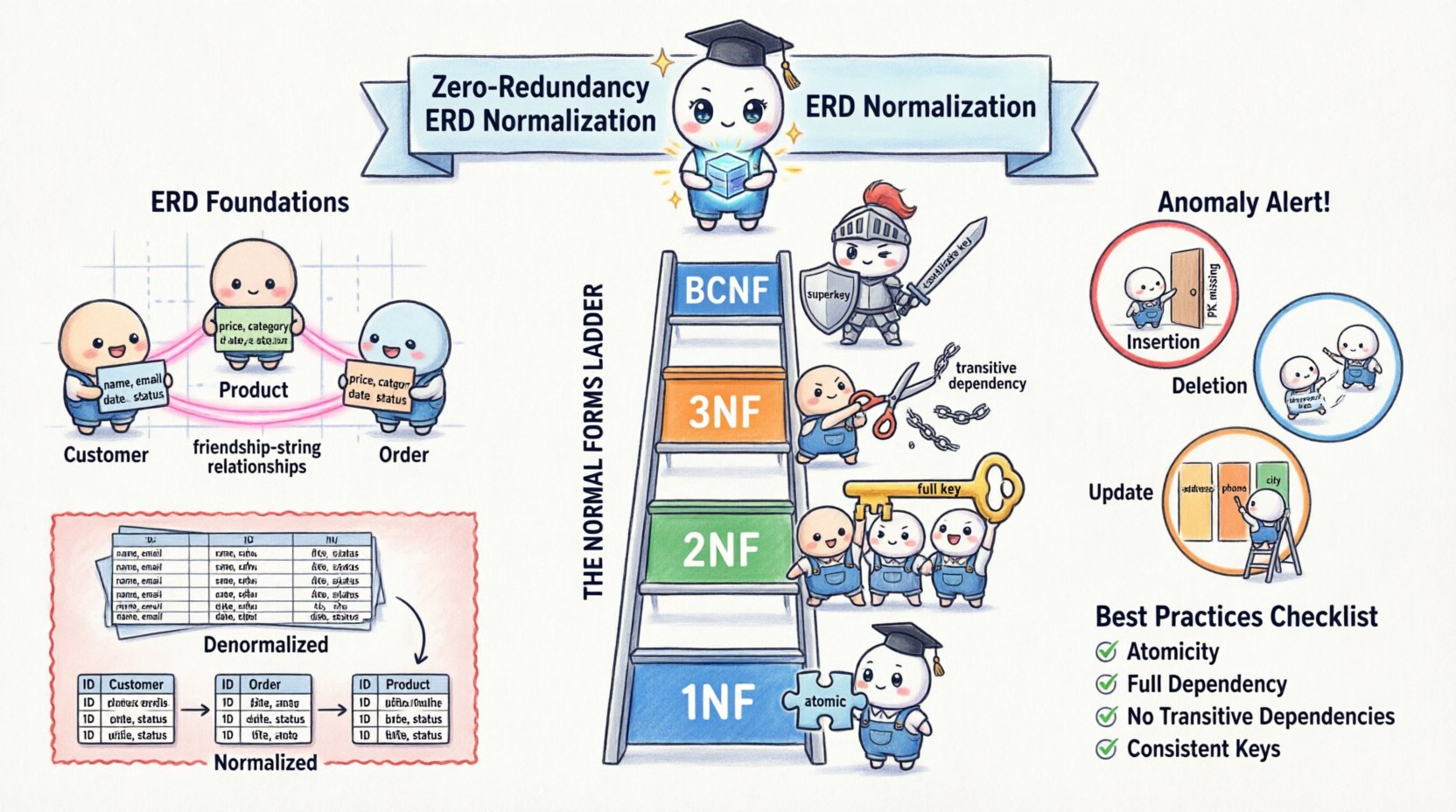
🧱 Comprendiendo las bases de la modelización de datos
Antes de aplicar las reglas de normalización, uno debe comprender los componentes del Diagrama de Relaciones de Entidades. Un ERD consta de entidades, atributos y relaciones. Las entidades representan objetos o conceptos, como un Cliente o un Producto. Los atributos son las propiedades que describen estas entidades, como un Nombre o un Precio. Las relaciones definen cómo se conectan las entidades, a menudo mediante claves foráneas.
La normalización es el proceso de organizar estos atributos para minimizar la redundancia y la dependencia. Implica dividir tablas grandes en otras más pequeñas y lógicamente conectadas, y definir relaciones entre ellas. El objetivo es aislar los datos de modo que cada hecho se almacene en un solo lugar.
Considere la diferencia entre un enfoque denormalizado y uno normalizado. En una vista denormalizada, una sola tabla podría contener toda la información sobre un pedido, incluyendo la dirección y el número de teléfono del cliente cada vez que se realiza un pedido. Si el cliente se muda, debe actualizar cada registro de pedido. En una vista normalizada, la dirección del cliente existe en una tabla separada de Clientes. La tabla de Pedidos simplemente contiene una referencia al ID del Cliente. Esta separación es la esencia de la ausencia de redundancia.
📉 Los riesgos de los datos no normalizados
¿Por qué es tan crítica la ausencia de redundancia? La respuesta radica en los tipos de anomalías que ocurren cuando se ignora la normalización. Estas anomalías amenazan la confiabilidad de todo el sistema.
- Anomalías de inserción:No puede agregarse datos para una entidad sin agregar datos para otra. Por ejemplo, si un nuevo empleado aún no ha sido asignado a un proyecto, podría no poder registrarse su existencia si la tabla requiere un ID de proyecto.
- Anomalías de eliminación:Eliminar datos para una entidad podría eliminar involuntariamente datos para otra. Si elimina el último pedido de un cliente, podría perder toda la información de contacto del cliente.
- Anomalías de actualización:Este es el problema más común. Si la dirección de un cliente se almacena en múltiples registros de pedidos, actualizar la dirección requiere encontrar y cambiar cada registro individual. El fracaso en hacerlo resulta en datos conflictivos.
Lograr la ausencia de redundancia mitiga directamente estos riesgos. Al garantizar que cada pieza de información tenga una única ubicación, el sistema se vuelve autoreparador. Las actualizaciones ocurren una sola vez, y el cambio se propaga lógicamente a través de las relaciones.
🪜 El camino hacia las formas normales
La normalización no es un solo paso, sino una progresión a través de etapas distintas llamadas Formas Normales. Cada forma aborda tipos específicos de redundancia. Aunque los modelos teóricos llegan hasta la Quinta Forma Normal (5FN), el diseño práctico de bases de datos generalmente se centra en las tres primeras formas y la Forma Normal de Boyce-Codd (BCNF).
1️⃣ Primera Forma Normal (1FN)
La primera regla de la normalización es garantizar la atomicidad. Una tabla está en 1FN si no contiene grupos repetidos ni arreglos. Cada columna debe contener un solo valor, y cada fila debe ser única.
- Valores atómicos:Un campo no puede contener una lista de valores. En lugar de una columna llamada “Habilidades” que contenga “Java, SQL, Python”, debería crear filas separadas para cada habilidad o una tabla separada para las habilidades.
- Filas únicas:Cada fila debe ser distinguible de todas las demás filas. Esto generalmente requiere una clave primaria.
En el contexto de un ERD, esto significa revisar cada atributo. Si un atributo describe una propiedad multivaluada, debe extraerse. Este es el paso fundamental. Sin 1FN, las formas superiores no pueden aplicarse de manera efectiva.
2️⃣ Segunda Forma Normal (2FN)
Una vez que una tabla está en 1FN, debe cumplir con los criterios de 2FN. Una tabla está en 2FN si está en 1FN y todos los atributos no clave dependen completamente de toda la clave primaria.
Esta regla aborda principalmente tablas con claves compuestas (claves formadas por múltiples columnas). Si una tabla tiene una clave compuesta, cada atributo debe depender de toda la clave, no solo de parte de ella.
- Dependencia completa:Si una columna depende únicamente de una parte de una clave compuesta, pertenece a una tabla separada.
- Dependencia parcial:Esta es la redundancia específica que elimina la 2NF. Por ejemplo, en una tabla que vincula Estudiantes con Cursos, si se almacena el “Nombre del Estudiante”, este depende únicamente del ID del Estudiante, no del ID del Curso. Esto genera redundancia.
Resolver esto implica dividir la tabla. Creas una tabla de Estudiantes y una tabla de Cursos, con una tabla de unión que las enlaza. Esto garantiza que los detalles del estudiante no se repitan para cada curso que cursa.
3️⃣ Tercera Forma Normal (3FN)
La tercera forma normal trata las dependencias transitivas. Una tabla está en 3FN si está en 2FN y ningún atributo no clave depende de otro atributo no clave.
En términos más simples, los atributos no deberían depender de otros atributos que no formen parte de la clave primaria. Esto suele ocurrir cuando una columna describe a otra columna en lugar de la fila misma.
- Dependencia transitiva: Si A determina B, y B determina C, entonces A determina C. Si B no es una clave, C se almacena de forma redundante.
- Ejemplo: En una tabla de Empleados, si almacenas el “Nombre del Departamento” y el “Gerente del Departamento”, el gerente depende del Nombre del Departamento. Si cambia el Nombre del Departamento, la columna de Gerente podría volverse inconsistente si no se gestiona con cuidado.
Para corregir esto, mueve la información del departamento a una tabla separada de Departamentos. La tabla de Empleados solo contendrá un ID de Departamento. Esto aísla los datos del departamento, asegurando que si un departamento cambia de nombre, lo actualices en un solo lugar.
4️⃣ Forma Normal de Boyce-Codd (FNBC)
La FNBC es una versión más estricta de la 3FN. Se aplica cuando hay múltiples claves candidatas o cuando un atributo no clave determina otro atributo no clave de una manera específica. Una tabla está en FNBC si, para cada dependencia funcional X → Y, X es una superclave.
Esta forma maneja escenarios complejos donde la 3FN aún podría permitir anomalías. Garantiza que cada determinante sea una clave candidata. Aunque no siempre es necesario para cada esquema, buscar la FNBC proporciona el más alto nivel de integridad estructural para eliminar redundancias.
🛠️ Manejo de anomalías: Una visión comparativa
Comprender el impacto de la normalización requiere una visión clara de cómo se manifiestan las anomalías. La tabla a continuación describe las diferencias entre los estados normalizados y denormalizados respecto a problemas comunes de datos.
| Tipo de anomalía | Estado denormalizado | Estado normalizado (sin redundancia) |
|---|---|---|
| Actualización | Requiere cambiar datos en múltiples filas. Alto riesgo de inconsistencia. | Requiere cambiar datos en una sola fila. La consistencia es automática. |
| Inserción | Puede requerir datos ficticios para cumplir con las restricciones de clave foránea. | Las nuevas entidades se pueden agregar de forma independiente sin datos relacionados. |
| Eliminación | Eliminar un registro puede eliminar datos esenciales sobre otra entidad. | Eliminar un registro afecta únicamente a la entidad específica, preservando las demás. |
| Almacenamiento | Alto uso de almacenamiento debido a cadenas y valores repetidos. | Uso mínimo de almacenamiento; los valores se hacen referencia mediante identificadores. |
Como se muestra, el enfoque normalizado reduce significativamente la sobrecarga operativa de la gestión de datos. El costo es una consulta ligeramente más compleja, ya que se requieren uniones para recuperar toda la información. Sin embargo, el equilibrio favorece la integridad y la mantenibilidad a largo plazo.
🛠️ Estrategias para la implementación
Implementar estas estrategias durante la fase de diseño del ERD es crucial. Es mucho más fácil prevenir la redundancia que corregirla después de que los datos hayan sido poblados. A continuación se presentan pasos concretos para los diseñadores.
1. Identifique las dependencias funcionales desde el principio
Antes de trazar líneas entre entidades, enumere los atributos y determine qué determina qué. Si sabe que el atributo A determina el atributo B, sabe que probablemente deberían residir en la misma entidad, a menos que A no sea una clave.
- Elabore todos los relaciones.
- Pregunte: «¿Este atributo depende de toda la clave?»
- Pregunte: «¿Este atributo depende de otro atributo no clave?»
2. Separe entidades según su ciclo de vida
Las entidades con frecuencias de actualización diferentes a menudo deben separarse. Si una tabla de referencia estática (como una lista de países) se mezcla con una tabla transaccional (como pedidos), los datos estáticos crean redundancia innecesaria en la tabla transaccional.
3. Use claves de sustitución
En lugar de usar datos naturales como clave primaria, considere el uso de una clave de sustitución (un identificador único generado por el sistema). Esto evita problemas en los que la clave misma cambia con el tiempo, lo que rompería las relaciones en un sistema normalizado.
4. Valide con datos de prueba
Antes de finalizar el ERD, intente poblarlo con datos de muestra. Intente crear las anomalías descritas anteriormente. Si puede insertar con éxito un cliente sin un pedido, y eliminar un pedido sin perder al cliente, es probable que su diseño sea sólido.
⚖️ Equilibrio entre rendimiento y pureza
Alcanzar cero redundancia no significa maximizar el número de tablas. Una normalización excesiva puede provocar degradación del rendimiento. Cuando una consulta requiere datos de diez tablas diferentes, el sistema debe realizar diez uniones. Esto puede ralentizar significativamente las operaciones de lectura.
Cuándo denormalizar
Existen razones válidas para reintroducir intencionalmente la redundancia. A menudo se denomina denormalización.
- Sistemas con carga de lectura alta:En almacenes de datos o herramientas de informes, se prioriza la velocidad de lectura sobre la consistencia de escritura. Las columnas precalculadas pueden reducir la complejidad de las uniones.
- Instantáneas históricas:Si necesita saber cuál era la dirección de un cliente en el momento de un pedido, no puede confiar en la dirección actual en la tabla de Clientes. Debe almacenar la dirección en la tabla de Pedidos.
- Ajuste de rendimiento:Si las consultas son consistentemente lentas debido a uniones, puede ser necesario agregar una columna redundante que se actualice mediante desencadenadores o lógica de aplicación.
La clave está en la intencionalidad. No acepte la redundancia como predeterminada. Aceptémosla solo cuando haya una ventaja de rendimiento medible que supere el costo de mantenimiento.
🔄 Revisión y mantenimiento de su esquema
La normalización no es una tarea única. Los requisitos del negocio cambian y los datos crecen. Un esquema que fue normalizado hace cinco años podría necesitar ajustes hoy.
Auditorías regulares
Programa revisiones periódicas de su ERD. Busque patrones de datos repetidos. Si encuentra la misma cadena de texto apareciendo en múltiples tablas, investigue por qué. Podría ser una señal de una falla de diseño o una elección intencional de denormalización que requiere documentación.
Control de versiones para modelos de datos
Trata tu diagrama ER como código. Usa sistemas de control de versiones para rastrear cambios. Esto te permite revertir si un cambio introduce redundancia o rompe relaciones. Documenta la razón detrás de cada cambio estructural importante.
Capacitación del equipo
Asegúrate de que todos los involucrados en la entrada de datos o el desarrollo de aplicaciones entiendan las reglas de normalización. Si los desarrolladores evitan el esquema para insertar datos directamente, pueden reintroducir redundancia mediante la lógica de la aplicación. La documentación clara sobre por qué el esquema está estructurado de esta manera es esencial.
📝 Resumen de las mejores prácticas
Para mantener un alto estándar de calidad de datos y eficiencia de almacenamiento, sigue la siguiente lista de verificación durante tu proceso de diseño.
- Atomicidad: Asegúrate de que cada columna contenga un solo valor (1FN).
- Dependencia completa: Asegúrate de que los atributos no clave dependan de toda la clave primaria (2FN).
- Sin dependencias transitivas: Asegúrate de que los atributos no clave no dependan de otros atributos no clave (3FN).
- Claves consistentes: Asegúrate de que cada determinante sea una clave candidata (FNBC).
- Documenta decisiones: Registra por qué se introdujeron redundancias específicas.
- Monitorea el crecimiento: Vigila patrones de datos repetidos a medida que la base de datos crece.
Al seguir estos principios, creas un sistema resistente al cambio. Los datos permanecen limpios y la lógica sigue siendo sólida. La ausencia de redundancia no se trata solo de ahorrar espacio en disco; se trata de construir una base donde se preserve la verdad de los datos.
🚀 Reflexiones finales sobre la integridad estructural
El camino hacia un almacenamiento sin redundancia es una inversión en la longevidad de tu arquitectura de datos. Aunque requiere disciplina durante la fase de diseño, los beneficios se manifiestan en errores reducidos, costos de mantenimiento más bajos y mayor confianza en el sistema de información.
Cuando miras un diagrama de relaciones de entidades, no lo veas solo como una colección de cajas y líneas, sino como un mapa de la verdad. Cada línea representa una relación de necesidad. Cada caja representa un hecho distinto. Al normalizar de forma efectiva, aseguras que este mapa permanezca preciso, incluso cuando cambie el terreno de tu negocio.
Enfócate en la lógica, no solo en el almacenamiento. Deja que la estructura sirva a los datos, no al revés. Con una comprensión clara de las estrategias de normalización, estarás preparado para construir sistemas que resistan la prueba del tiempo y del volumen de datos.