











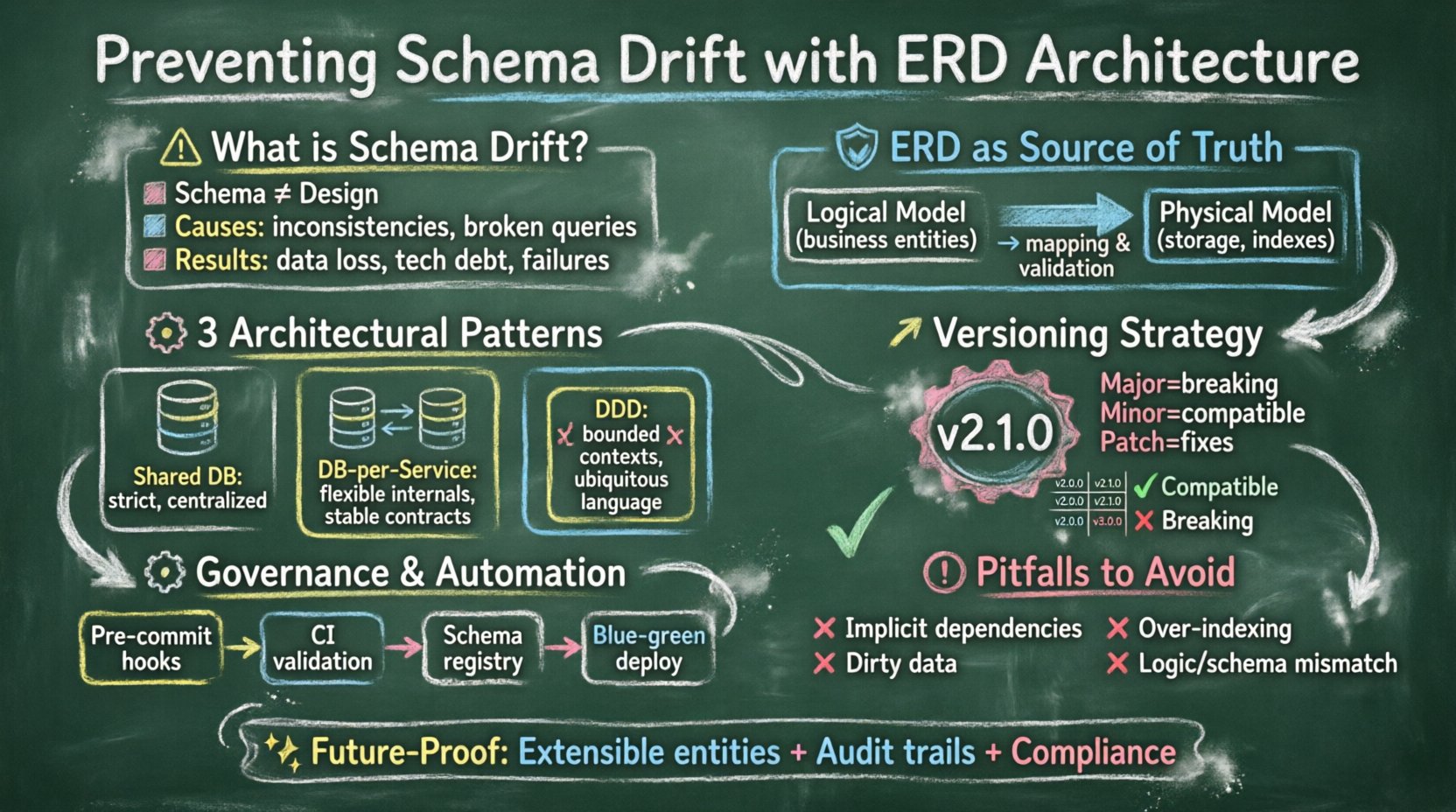
A medida que los sistemas crecen en complejidad, la estabilidad de las estructuras de datos subyacentes se convierte en la base de la confiabilidad operativa. Uno de los desafíos más persistentes enfrentados por los equipos de ingeniería es el desvió de esquema. Este fenómeno ocurre cuando el esquema de la base de datos se desvía del diseño esperado, lo que genera inconsistencias, consultas rotas y un comportamiento de aplicación impredecible. Aunque a menudo se trata como un problema de administración de bases de datos, la causa raíz frecuentemente reside en cómo se arquitecta y gestiona el Diagrama de Relación de Entidades (ERD) desde el inicio.
Un ERD bien estructurado hace más que visualizar relaciones; actúa como un contrato entre la lógica de la aplicación y la capa de almacenamiento de datos. En entornos escalables donde múltiples servicios interactúan con datos compartidos, este contrato debe ser rígido pero suficientemente flexible para acomodar el crecimiento. Esta guía explora los patrones arquitectónicos y metodologías que estabilizan los modelos de datos y evitan el desvió de esquema antes de que afecte la producción.
📉 Comprendiendo el Desvió de Esquema en Entornos Distribuidos
El desvió de esquema no es meramente una cuestión de olvidar actualizar una tabla. Es un problema sistémico en el que la implementación física del modelo de datos se desvía de su definición lógica con el tiempo. En sistemas monolíticos, esto podría manifestarse como unas cuantas columnas olvidadas. En arquitecturas distribuidas y de microservicios, puede provocar condiciones de carrera en las que el Servicio A escribe datos en un formato que el Servicio B no puede leer.
Las consecuencias del desvió no controlado incluyen:
- Pérdida de Integridad de Datos:Las restricciones se evitan, permitiendo estados inválidos.
- Aumento de la Deuda Técnica:Los desarrolladores dedican más tiempo a depurar problemas de datos que a construir características.
- Fallas en los Servicios:Las APIs fallan cuando esperan tipos de campo específicos o su existencia.
- Complejidad de la Migración:Cazar el retraso se vuelve más difícil a medida que el abismo aumenta.
Evitar esto requiere un enfoque arquitectónico al ERD que imponga consistencia sin frenar la agilidad. Implica definir reglas para los cambios, versionar el modelo de datos y establecer una gobernanza alrededor del propio diagrama.
🛡️ La Fundación: ERD como Fuente de Verdad
El primer paso para prevenir el desvió es elevar el Diagrama de Relación de Entidades de un dibujo estático a un documento vivo que guíe la implementación. Cuando el ERD se trata como un artefacto secundario, el desvió se vuelve inevitable. Cuando se trata como la fuente principal de verdad, la arquitectura apoya la estabilidad.
1. Separación Lógica frente a Física
Para mantener la flexibilidad al tiempo que se asegura la estabilidad, separa el modelo de datos lógico de su implementación física. El ERD lógico debe describir entidades del negocio y sus relaciones sin restricciones técnicas. El ERD físico maneja el índice, la partición y los tipos específicos de almacenamiento.
Esta separación permite que la lógica de negocio evolucione sin obligar a cambios físicos inmediatos. Crea una zona de amortiguamiento donde los cambios pueden validarse frente a los requisitos del negocio antes de afectar la capa de almacenamiento.
2. Modelos de Datos Canónicos
En sistemas escalables, múltiples servicios a menudo necesitan comprender los mismos datos. Establecer un modelo de datos canónico asegura que todos los servicios referencien las mismas definiciones. El ERD define estas entidades canónicas.
- Fuente Única de Verdad:El ERD define el esquema exacto para entidades críticas como Usuario, Pedido o Inventario.
- Contratos de Servicio:Los servicios consumen datos según la definición del ERD, no consultas ad hoc.
- Nomenclatura Estándar:Las convenciones de nomenclatura definidas en el ERD previenen la ambigüedad entre diferentes instancias de base de datos.
🧩 Patrones Arquitectónicos para la Estabilidad del ERD
Las diferentes arquitecturas de sistemas requieren estrategias diferentes para el ERD. Los siguientes patrones ayudan a mantener la consistencia a medida que el sistema escala.
1. El patrón de base de datos compartida
En algunos sistemas monolíticos o fuertemente acoplados, se utiliza una base de datos compartida. Aquí, el diagrama ERD debe ser extremadamente estricto. Los cambios en el ERD requieren coordinación entre todos los módulos que acceden a esa base de datos.
- Gestión centralizada del esquema:Un solo equipo posee las actualizaciones del ERD.
- Control de acceso estricto:Solo los scripts autorizados pueden alterar el esquema.
- Seguimiento de dependencias:El ERD debe representar claramente las dependencias entre tablas para identificar el impacto antes de los cambios.
2. El patrón de base de datos por servicio
En arquitecturas de microservicios, cada servicio posee sus propios datos. Esto reduce el acoplamiento directo, pero introduce el riesgo de definiciones de datos inconsistentes entre servicios. La arquitectura del ERD aquí se centra en la interfaz entre servicios, más que en el almacenamiento interno de cada uno.
- Flexibilidad interna:Cada servicio puede evolucionar su esquema interno siempre que la interfaz externa permanezca estable.
- Contratos externos:El ERD define los contratos compartidos. Si el servicio A necesita datos del servicio B, el ERD define la estructura esperada.
- Captura de eventos:El ERD puede definir los eventos que transportan datos, asegurando inmutabilidad y trazabilidad.
3. El enfoque de Diseño Orientado al Dominio (DDD)
El Diseño Orientado al Dominio alinea el esquema de la base de datos con los dominios empresariales. El ERD se divide por contextos delimitados. Esto evita el problema de la ‘tabla diosa’ en la que entidades sin relación se ven obligadas a estar en un solo esquema.
- Mapeo de contexto:El ERD mapea las relaciones entre contextos delimitados.
- Lenguaje universal:Los nombres de entidad en el ERD coinciden con la terminología empresarial.
- Encapsulamiento:Las entidades internas están ocultas; solo se expone el límite del dominio.
🔄 Estrategias de versionado para la evolución del esquema
El cambio es inevitable. El objetivo es gestionarlo sin romper a los consumidores existentes. Versionar el esquema dentro de la arquitectura del ERD es fundamental.
1. Versionado semántico para esquemas
Al igual que el código de software utiliza versionado semántico, los esquemas de datos también deberían hacerlo. Una versión de esquema puede indicarse como Mayor.Menor.Parche.
- Mayor:Cambios que rompen la compatibilidad (por ejemplo, eliminar una columna, cambiar un tipo).
- Menor: Adiciones compatibles con versiones anteriores (por ejemplo, agregar una columna nullable).
- Parche: Correcciones internas u optimizaciones que no afectan la API.
2. Reglas de compatibilidad hacia atrás
Para evitar desviaciones, adhiera a reglas estrictas sobre cómo evoluciona el esquema. La siguiente tabla describe cambios seguros frente a cambios no seguros.
| Acción | Compatibilidad | Requisito |
|---|---|---|
| Agregar nueva columna | Compatible con versiones anteriores | Debe permitir valores nulos inicialmente |
| Agregar nueva tabla | Compatible con versiones anteriores | Asegúrese de que no haya dependencias de clave foránea inicialmente |
| Eliminar columna | Cambio que rompe la compatibilidad | Depreciar primero, luego eliminar más adelante |
| Cambiar tipo de datos | Cambio que rompe la compatibilidad | Requiere un plan completo de migración |
| Agregar clave foránea | Condicionado | Asegúrese de que los datos existentes cumplan con la restricción |
3. Patrones de escritura dual
Cuando se requiere un cambio en el esquema, evite el corte inmediato. Implemente una estrategia de escritura dual en la que los datos se escriban en ambas estructuras, la antigua y la nueva. Con el tiempo, el tráfico se desplaza hacia la nueva estructura. El diagrama ER debe documentar ambas versiones durante esta transición.
- Camino de lectura: Continúe leyendo desde el esquema estable.
- Camino de escritura: Escriba en ambos esquemas simultáneamente.
- Validación:Monitorear la consistencia de los datos entre los dos esquemas.
- Cutover:Una vez verificado, dejar de escribir en el esquema antiguo.
⚙️ Gestión y gobernanza de migraciones
Aunque se utilice control de versiones, las migraciones son necesarias. La arquitectura debe permitir migraciones seguras, reversibles y automatizadas.
1. Scripts de migración como código
Las migraciones deben controlarse con versiones junto con el código de la aplicación. El ERD sirve como estado objetivo para estos scripts. Cada archivo de migración debe referenciar la versión específica del ERD que implementa.
- Idempotencia:Los scripts deben ser seguros para ejecutarse múltiples veces.
- Capacidad de reversión:Cada actualización debe tener un script de deshacer correspondiente.
- Atomicidad:Los cambios deben ser transaccionales siempre que sea posible para evitar actualizaciones parciales.
2. Registro de esquemas
Implementar un registro de esquemas para rastrear el estado del ERD en todos los entornos. Esto garantiza que los entornos de desarrollo, pruebas y producción estén alineados.
- Paridad de entornos:Evita la desalineación entre desarrollo y producción.
- Flujos de aprobación:Los cambios en el esquema requieren revisión antes de su promoción.
- Validación:Comprobaciones automatizadas garantizan que el esquema desplegado coincida con el ERD registrado.
3. Documentación como código
La documentación debe generarse directamente desde el ERD. Esto garantiza que los diagramas y las descripciones de texto permanezcan sincronizados. La documentación manual suele volverse obsoleta rápidamente.
- Generación automatizada:Las herramientas pueden generar documentación a partir del archivo ERD.
- Documentos vivos:Las actualizaciones de documentación forman parte del proceso de revisión de código.
- Notas contextuales:Incluir notas de lógica de negocio directamente en los metadatos del ERD.
📝 Automatización e integración de CI/CD
El error humano es una causa principal del desplazamiento de esquemas. La automatización reduce este riesgo al imponer reglas durante la canalización de despliegue.
1. Ganchos previos al commit
Implemente ganchos que validen los cambios de esquema antes de que se confirmen en el repositorio. Estos ganchos verifican cambios que rompen la definición actual del ERD.
- Linting: Imponga convenciones de nomenclatura y reglas de estructura.
- Validación: Asegúrese de que las nuevas restricciones no entren en conflicto con los datos existentes.
- Revisión: Exija aprobación manual para cambios de alto riesgo.
2. Verificaciones de integración continua
Durante el proceso de CI, ejecute la validación de esquema contra una base de datos de prueba. Esto detecta problemas antes del despliegue.
- Entornos de prueba (sandbox): Despliegue en un entorno temporal para probar las migraciones.
- Pruebas de integración: Ejecute consultas que dependen del esquema para asegurar la funcionalidad.
- Verificaciones de rendimiento: Asegúrese de que los nuevos índices no degraden el rendimiento de escritura.
3. Despliegues azul-verde para datos
Similar a los despliegues de aplicaciones, utilice estrategias azul-verde para datos. Mantenga dos versiones del esquema en paralelo hasta que la nueva versión sea estable.
- Tiempo de inactividad cero: Los usuarios no se ven afectados por los cambios de esquema.
- Reversión instantánea: Si surgen problemas, vuelva a la versión anterior del esquema.
- Sincronización de datos: Asegúrese de que los datos sean coherentes entre ambas versiones durante la transición.
🚨 Peligros comunes que deben evitarse
Aunque se cuente con una arquitectura sólida, los equipos a menudo caen en trampas que reintroducen el desplazamiento. La conciencia de estos peligros es esencial para la estabilidad a largo plazo.
1. Dependencias implícitas
El código a menudo depende de estructuras de datos que no están definidas explícitamente en el ERD. Los nombres de columnas codificados o las suposiciones sobre la presencia de datos provocan fallas silenciosas.
- Tipado explícito:Utilice un tipado fuerte en todas las capas de acceso a datos.
- Contratos de interfaz:Defina interfaces claras para el acceso a datos.
- Refactorización:Revise periódicamente el código en busca de suposiciones implícitas.
2. Ignorar la calidad de los datos
Un esquema puede ser perfecto, pero si los datos que entran en él están contaminados, el sistema falla. El diagrama ER debe incluir restricciones que garanticen la calidad de los datos.
- Restricciones de verificación:Valide los valores a nivel de base de datos.
- Restricciones únicas:Evite entradas duplicadas.
- Restricciones NOT NULL:Asegúrese de que los campos obligatorios siempre estén completos.
3. Sobrecarga de índices
Agregar índices para resolver el rendimiento de lectura a menudo ralentiza las escrituras. Esto puede provocar cambios en el esquema que interrumpan la ruta de escritura.
- Mida primero:Monitoree el rendimiento de las consultas antes de agregar índices.
- Revise periódicamente:Elimine los índices no utilizados para reducir la sobrecarga.
- Equilibrio:Encuentre el equilibrio adecuado entre el rendimiento de lectura y escritura.
4. Desacoplar la lógica del esquema
Aplicar la lógica de negocio en la capa de aplicación cuando debería estar en la base de datos conduce a inconsistencias. El diagrama ER debe guiar dónde reside la lógica.
- Restricciones de base de datos:Mueva la lógica a desencadenantes o procedimientos almacenados cuando sea apropiado.
- Validación:Asegúrese de que la lógica de la aplicación no evite las reglas de la base de datos.
- Claridad:Documente dónde reside la lógica en las notas del diagrama ER.
🔮 Futurización del modelo de datos
Los sistemas escalables deben estar preparados para el futuro. La arquitectura del ERD debe anticipar el crecimiento y los cambios.
1. Extensibilidad
Diseñe entidades para que sean extensibles. Utilice tipos de datos flexibles o columnas JSON para atributos que puedan variar, manteniendo la estructura central rígida.
- Conjuntos de atributos:Almacene atributos variables en un mapa estructurado.
- Etiquetas y rótulos:Utilice pares clave-valor para metadatos dinámicos.
- Campos de versión:Incluya números de versión en las entidades para rastrear cambios.
2. Huellas de auditoría
Cada cambio en los datos debe ser rastreable. El ERD debe incluir tablas de auditoría para registrar quién cambió qué y cuándo.
- Tablas de historial:Mantenga un historial de los cambios en los registros.
- Registros de cambios:Registre los cambios en el esquema por separado de los cambios en los datos.
- Registros de acceso:Rastree quién consulta datos sensibles.
3. Cumplimiento y seguridad
Los modelos de datos deben cumplir con los requisitos regulatorios. El ERD debe definir dónde se almacenan los datos sensibles y cómo se protegen.
- Cifrado:Marque los campos que requieren cifrado.
- Políticas de retención:Defina durante cuánto tiempo se mantiene la data en el esquema.
- Control de acceso:Defina roles que puedan acceder a entidades específicas.
🏁 Reflexiones finales sobre la integridad arquitectónica
Evitar el desplazamiento del esquema no consiste en restringir el cambio; se trata de gestionarlo con disciplina. Al tratar el Diagrama de Relaciones de Entidades como un artefacto arquitectónico central, los equipos pueden construir sistemas que sean tanto robustos como adaptables. La clave está en la separación de responsabilidades, la versiones estrictas y la gobernanza automatizada.
Cuando se respeta el ERD, el modelo de datos se convierte en una base estable sobre la cual se pueden construir aplicaciones escalables. Esto reduce la carga cognitiva sobre los desarrolladores, minimiza los riesgos operativos y garantiza que el sistema permanezca mantenible a medida que crece. La arquitectura del diagrama determina la estabilidad de los datos, y a su vez, la estabilidad del negocio.
Adoptar estos patrones requiere una inversión inicial en procesos y herramientas. Sin embargo, el retorno a largo plazo es un sistema que evoluciona con elegancia sin la carga constante de corregir contratos de datos rotos. Priorice la integridad del modelo de datos, y el sistema seguirá.