











Die Landschaft der Datenbankarchitektur verändert sich unter den Füßen von Dateningenieuren und Systemarchitekten. Seit Jahrzehnten dient das Entitäts-Beziehungs-Diagramm (ERD) als Bauplan für Datenstrukturen und definiert, wie Informationen innerhalb komplexer Systeme fließen, miteinander verbunden sind und persistieren. Traditionell erforderte die Erstellung dieser Diagramme sorgfältige manuelle Arbeit, tiefes Fachwissen und die Bereitschaft, langwierige Iterationen durchzustehen. Heute führt die Integration künstlicher Intelligenz in Modellierungsabläufe eine neue Ära ein. Diese Entwicklung geht nicht nur um Geschwindigkeit, sondern um eine grundlegende Veränderung der Art und Weise, wie logische Datenmodelle entworfen, validiert und gepflegt werden.
Künstliche Intelligenz geht über einfache Automatisierung hinaus und wird zu einem aktiven Teilnehmer im Gestaltungsprozess. Durch die Nutzung von Natural Language Processing und Mustererkennung interpretieren diese fortschrittlichen Systeme Geschäftsanforderungen und übersetzen sie mit bemerkenswerter Genauigkeit in strukturelle Schemata. Dieser Leitfaden untersucht die Mechanismen dieses Wandels, die greifbaren Vorteile für Entwicklungsteams und die strategischen Überlegungen, die bei der Einführung dieser Technologien notwendig sind, um die Datenintegrität nicht zu gefährden.
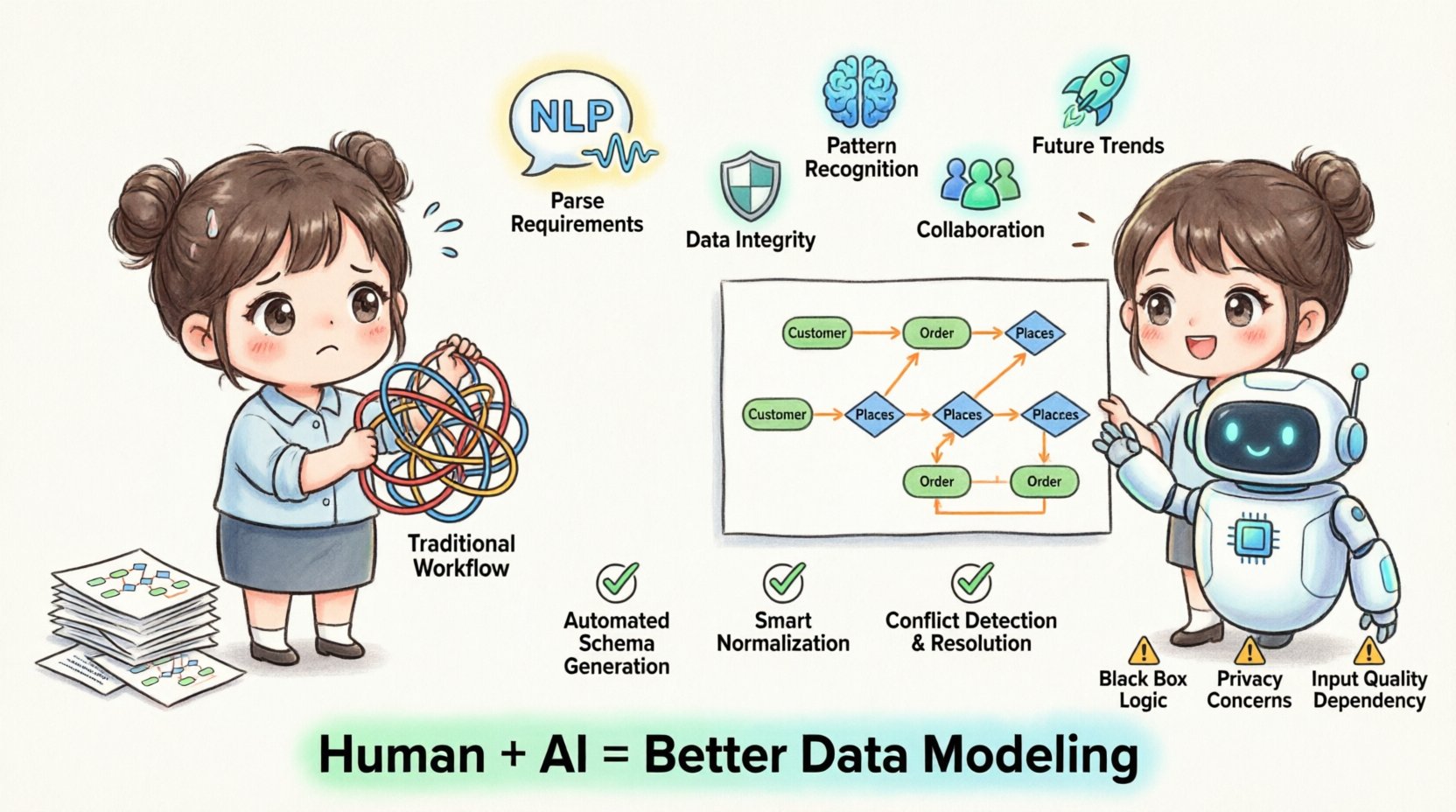
📐 Der traditionelle ERD-Ablauf und seine Grenzen
Bevor wir die Zukunft betrachten, ist es unerlässlich, die Grundlage zu verstehen. Die Erstellung eines Entitäts-Beziehungs-Diagramms war historisch gesehen ein linearer, arbeitsintensiver Prozess. Architekten sammelten Anforderungen, identifizierten Entitäten, definierten Beziehungen und normalisierten die Datenstruktur. Obwohl dies wirksam war, birgt dieser Ansatz inhärente Risiken und Ineffizienzen, die sich bei steigender Systemgröße noch verstärken.
- Hoher kognitiver Aufwand:Die Gestaltung komplexer Schemata erfordert, riesige Mengen an relationaler Logik im Gedächtnis zu behalten. Dies erhöht die Wahrscheinlichkeit von Übersehen.
- Fragmentierung der Versionskontrolle:Diagrammdateien werden oft zu isolierten Artefakten, die vom eigentlichen Quellcode oder den Datenbankdefinitionen getrennt sind.
- Fehler bei der manuellen Normalisierung:Die Sicherstellung der Dritten Normalform (3NF) oder der Boyce-Codd-Normalform (BCNF) erfordert ständige Aufmerksamkeit gegenüber Redundanz und Anomalien.
- Kooperationsengpässe:Mehrere Stakeholder müssen oft dasselbe Diagramm überprüfen, was zu Rücklaufschleifen führt, die die Entwicklung verlangsamen.
- Statische Dokumentation:Sobald gezeichnet, werden ERDs häufig veraltet, da sich die zugrundeliegende Anwendungslogik weiterentwickelt.
Diese Herausforderungen schaffen eine Lücke zwischen dem vorgesehenen Design und der tatsächlich umgesetzten Realität. Diese Lücke vergrößert sich weiter, wenn sich die Geschäftsanforderungen schnell ändern, was in modernen agilen Umgebungen eine häufige Situation ist.
🧠 Die Mechanismen der KI-getriebenen Modellierung
KI-getriebene ERD-Werkzeuge zeichnen nicht einfach nur Linien zwischen Kästchen. Sie basieren auf maschinellen Lernmodellen, die an umfangreichen Sammlungen von Datenbankmustern, Branchenstandards und architektonischen Best Practices trainiert wurden. Das Verständnis der zugrundeliegenden Mechanismen hilft dabei, die Zuverlässigkeit dieser Werkzeuge zu bewerten.
1. Interpretation durch Natural Language Processing (NLP)
Moderne Systeme können unstrukturierten Text, wie Produktanforderungsdokumente oder Nutzerstories, verarbeiten und Schlüsselentitäten sowie Attribute extrahieren. Die KI analysiert nicht nur Stichwörter, sondern auch semantische Bedeutung. Wenn beispielsweise in einem Dokument von „Kundenbestellungen“ die Rede ist, erkennt das System „Kunde“ und „Bestellung“ als wahrscheinliche Entitäten und leitet die Beziehung aufgrund des sprachlichen Kontexts ab.
2. Mustererkennung und generatives Design
Sobald Entitäten identifiziert sind, wendet die KI gelernte Muster an, um Beziehungen vorzuschlagen. Sie erkennt verbreitete Kardinalitäten wie ein-zu-viele oder viele-zu-viele basierend auf der semantischen Bedeutung der Begriffe. Diese generative Fähigkeit ermöglicht die schnelle Erstellung eines Entwurfschemas, das als Ausgangspunkt für menschliche Verbesserungen dient.
3. Kontextuelles Verständnis
Fortgeschrittene Modelle bewahren den Kontext über das gesamte Dokument oder Projekt hinweg. Wenn ein bestimmtes Attribut in einem Abschnitt als eindeutiger Bezeichner definiert ist, merkt sich das System diese Einschränkung, wenn es Fremdschlüssel in einem anderen Abschnitt generiert. Diese Konsistenz ist bei großen Projekten schwer manuell aufrechtzuerhalten.
⚙️ Schlüsselkompetenzen, die die Datenmodellierung verändern
Die Integration von KI bringt spezifische funktionale Fähigkeiten mit sich, die die Schwachstellen der traditionellen Modellierung angehen. Diese Funktionen sind darauf ausgelegt, das menschliche Denken zu ergänzen, anstatt es zu ersetzen.
- Automatisierte Schemagenerierung:Konvertieren von textuellen Spezifikationen direkt in Datenbankschemadefinitionen (DDL) und visuelle Diagramme gleichzeitig.
- Intelligente Optimierung:Das System schlägt Optimierungen für Indexstrategien basierend auf den vorgeschlagenen Abfragemustern vor.
- Konflikterkennung:KI kann potenzielle Namenskonflikte oder zirkuläre Abhängigkeiten erkennen, bevor sie in die Datenbank übernommen werden.
- Intelligente Normalisierung:Algorithmen analysieren die Struktur, um Normalisierungsschritte zu empfehlen, die Redundanz verringern, ohne die Abfrageleistung zu beeinträchtigen.
- Analyse der Migration von Veralteten Systemen: Beim Integrieren mit bestehenden Systemen kann KI alte Schemata neuen Strukturen zuordnen und brechende Änderungen identifizieren.
📊 Vergleich traditioneller vs. KI-unterstützter Arbeitsabläufe
Um die Veränderung zu veranschaulichen, betrachten Sie den folgenden Vergleich, wie Aufgaben in einer traditionellen Umgebung im Vergleich zu einer KI-integrierten Umgebung behandelt werden.
| Aufgabe | Traditioneller Arbeitsablauf | KI-unterstützter Arbeitsablauf |
|---|---|---|
| Anforderungsanalyse | Manuelle Extraktion von Entitäten aus Text | NLP-Extraktion mit Vertrauensbewertung |
| Beziehungsabgleich | Der Architekt zeichnet Linien und definiert die Kardinalität | Das System schlägt Beziehungen basierend auf der Semantik vor |
| Normalisierung | Manuelle Überprüfung anhand der 3NF-Regeln | Algorithmenbasierte Validierung und Optimierung |
| Dokumentationsaktualisierungen | Das Diagramm muss nach Änderungen neu gezeichnet werden | Echtzeit-Synchronisierung mit Schemaänderungen |
| Fehlererkennung | Wird während des Testens oder der Codeüberprüfung gefunden | Proaktive Warnungen während der Entwurfsphase |
Dieser Vergleich zeigt, dass der Hauptwert darin liegt, die Anstrengung von der Ausführung auf die Validierung zu verlagern. Die KI übernimmt die repetitiven Konstruktionsaufgaben, sodass der menschliche Experte sich auf die architektonische Strategie und die Ausrichtung der Geschäftslogik konzentrieren kann.
🛡️ Verbesserung der Datenintegrität und Konsistenz
Datenintegrität ist die Grundlage zuverlässiger Software. Inkonsistente Daten führen zu fehlerhaften Analysen, fehlgeschlagenen Transaktionen und Sicherheitslücken. KI-Tools führen eine konsistente, regelbasierte Durchsetzungsstufe ein.
Referenzielle Integritätsprüfungen
Ein häufiger Fehler bei der ERD-Entwicklung ist die Erstellung von verwaisten Datensätzen aufgrund falscher Fremdschlüsselbeschränkungen. KI-Systeme überprüfen automatisch, ob jeder Fremdschlüssel einem entsprechenden Primärschlüssel in der referenzierten Entität entspricht. Sie können auch bei Bedarf zusammengesetzte Schlüssel vorschlagen, um sicherzustellen, dass die Beziehungen robust bleiben.
Attribut-Typisierung und Beschränkungen
Die Auswahl des richtigen Datentyps ist entscheidend für Leistung und Speicherplatz. KI-Modelle analysieren die Art der in den Anforderungen beschriebenen Daten. Wenn ein Feld als „Geburtsdatum“ beschrieben wird, stellt das System sicher, dass es nicht als einfacher String modelliert wird, sondern als zeitlicher Typ mit entsprechenden Validierungsregeln.
Standardisierte Namenskonventionen
Inkonsistente Namenskonventionen erzeugen Verwirrung. „user_id“, „UserId“ und „UserID“ könnten alle auf dasselbe Konzept verweisen und die Verknüpfungen erschweren. KI-Tools setzen eine globale Namensstrategie durch und stellen sicher, dass alle generierten Entitäten automatisch den Codierungsstandards des Projekts entsprechen.
🤝 Einfluss auf die Teamzusammenarbeit
Die Entwicklung von ERD-Tools verändert auch die Art der Zusammenarbeit innerhalb von Teams. Wenn Diagramme dynamisch sind und aus gemeinsam genutzten Anforderungen generiert werden, sinkt die Barriere zwischen Business-Analysten, Entwicklern und Datenarchitekten.
- Einzelne Quelle der Wahrheit: Wenn das Diagramm mit den Quell-Anforderungen verknüpft ist, können Stakeholder das Modell anhand des ursprünglichen Textes überprüfen.
- Echtzeit-Zusammenarbeit:Cloud-basierte Modellierungsplattformen ermöglichen es mehreren Benutzern, gemeinsam zu sehen und Änderungsvorschläge zu machen, ohne dass ihre Arbeit überschrieben wird.
- Geringere Mehrdeutigkeit:Visuelle Ausgaben, die von KI generiert werden, reduzieren die Mehrdeutigkeit von textlichen Beschreibungen. Ein Diagramm ist oft klarer als ein Absatz Text.
- Schnellerer Einarbeitungsprozess:Neue Teammitglieder können die Systemarchitektur schneller verstehen, indem sie die von der KI generierten Karten und Beziehungsflüsse überprüfen.
⚠️ Grenzen und ethische Überlegungen
Trotz der Fortschritte sind KI-gestützte Werkzeuge kein Allheilmittel. Die reine Abhängigkeit von automatisierten Systemen ohne menschliche Überwachung birgt spezifische Risiken, die bewusst managen werden müssen.
1. Das Schwarze-Box-Problem
KI-Modelle sind oft undurchsichtig. Wenn das System eine bestimmte Beziehung vorschlägt, muss der Architekt verstehenwarum. Ohne Erklärbarkeit ist es schwierig, den Entscheidungen des Modells in kritischen Systemen zu vertrauen.
2. Kontextuelle Feinheiten
KI kann Schwierigkeiten haben, sehr spezifische Geschäftsregeln zu berücksichtigen, die in allgemeinen Datenmustern nicht üblich sind. Zum Beispiel könnte eine einzigartige Vorschrift zur regulatorischen Compliance übersehen werden, wenn sie nicht in den Trainingsdaten enthalten ist.
3. Datenschutz und Sicherheit
Beim Einsatz von cloud-basierten KI-Modellierungswerkzeugen enthält die verarbeitete Metadaten sensible Informationen über die Struktur des Systems. Es ist entscheidend sicherzustellen, dass Datenschutzrichtlinien eingehalten werden und dass proprietäre Logik nicht externen Modellen preisgegeben wird.
4. Abhängigkeit von der Eingabedatenqualität
Die Ausgabe eines KI-Modells ist nur so gut wie die Eingabe. Wenn das Anforderungsdokument unklar oder widersprüchlich ist, wird das generierte ERD diese Mängel widerspiegeln. Eine menschliche Überprüfung bleibt ein notwendiger Schritt.
🔮 Zukünftige Trends im intelligenten Datenmodellieren
Blickt man in die Zukunft, zeigt sich, dass die Entwicklung von KI im Bereich der ERD-Erstellung auf eine tiefere Integration in den Entwicklungslebenszyklus zusteuert. Die folgenden Trends werden wahrscheinlich die nächste Generation von Werkzeugen prägen.
- Prädiktive Schema-Evolution: Werkzeuge werden Nutzungsmuster analysieren, um zukünftige Skalierungsanforderungen vorherzusagen und proaktiv Partitionierungs- oder Sharding-Strategien vorschlagen.
- Selbstheilende Datenbanken:Integrierte Systeme werden Schema-Drift erkennen und automatisch Rollback- oder Migrations-Skripte vorschlagen.
- Abfragebewusstes Modellieren:KI wird das ERD basierend auf den spezifischen Abfragen optimieren, die die Anwendung ausführt, anstatt nur auf die geschäftlichen Anforderungen.
- Mehrmusterunterstützung:Da NoSQL- und Graph-Datenbanken immer häufiger werden, wird die KI bei der Gestaltung hybrider Modelle unterstützen, die gleichzeitig relationale, Dokumenten- und Graph-Strukturen unterstützen.
- Integration mit DevOps:ERD-Änderungen werden CI/CD-Pipelines auslösen, um sicherzustellen, dass Datenbank-Migrationen gemeinsam mit dem Anwendungscode getestet und bereitgestellt werden.
📋 Best Practices für die Einführung
Organisationen, die diese Technologien einführen möchten, sollten einen strukturierten Ansatz verfolgen, um Erfolg zu gewährleisten. Die Integration sollte schrittweise erfolgen und sich auf die Verbesserung bestehender Prozesse konzentrieren, anstatt sie zu stören.
Beginnen Sie mit Pilotprojekten
Migrieren Sie die gesamte Unternehmensarchitektur nicht auf einmal. Wählen Sie ein nicht-kritisches Projekt aus, um die Fähigkeiten der KI-Modellierungswerkzeuge zu testen. Messen Sie die Einsparung an Zeit und die Qualität der Ergebnisse.
Mensch im Schleifenprozess beibehalten
Etablieren Sie eine Governance-Richtlinie, die eine menschliche Genehmigung für alle Schema-Änderungen erfordert. Die KI liefert den Entwurf; der Architekt liefert die Entscheidung.
Schwerpunkt auf Daten-Governance legen
Stellen Sie sicher, dass das KI-Tool mit dem Daten-Governance-Rahmenwerk der Organisation übereinstimmt. Namenskonventionen, Sicherheitsklassifizierungen und Aufbewahrungsrichtlinien müssen innerhalb des Tools konfiguriert werden.
Das Team schulen
Bieten Sie Schulungen zur Interaktion mit der KI an. Die Teammitglieder sollten verstehen, wie sie das System effektiv ansprechen und die von ihm vorgeschlagenen Lösungen interpretieren können.
Auf Abweichungen überwachen
Führen Sie regelmäßig Audits der generierten Diagramme im Vergleich zur tatsächlich bereitgestellten Datenbank durch. Dadurch wird sichergestellt, dass die KI im Laufe der Zeit mit der Realität des Systems übereinstimmt.
🎯 Strategischer Nutzen für moderne Entwicklung
Die Verschiebung hin zu KI-getriebener ERD-Erstellung stellt einen strategischen Vorteil für Organisationen dar. Durch die Reduzierung der Zeit, die für routinemäßige Modellierungsaufgaben aufgewendet wird, können Teams sich auf Innovation konzentrieren. Die Fähigkeit, Datenstrukturen schnell zu prototypisieren, ermöglicht schnellere Experimente und Iterationen.
Darüber hinaus reduziert die durch diese Werkzeuge eingeführte Konsistenz technische Schulden. Schemata, die mit KI-Einhaltung von Standards generiert werden, sind einfacher zu pflegen und zu erweitern. Diese Haltbarkeit ist entscheidend in einer Ära, in der Daten die primäre Ressource der meisten digitalen Unternehmen sind.
Mit der Reife der Technologie könnte die Unterscheidung zwischen „Designer“ und „Bauer“ verschwimmen. Die Grenze zwischen konzeptueller Modellierung und physischer Implementierung wird zunehmend durchlässig. Diese Konvergenz verspricht ein agileres und reaktionsschnelleres Software-Entwicklungslebenszyklus.
🌐 Schlussfolgerung
Die Entwicklung der Entitäts-Beziehungs-Diagramme durch KI ist eine bedeutende Entwicklung im Bereich der Dateningenieurwissenschaft. Sie verlagert die Disziplin von der manuellen Zeichnung hin zu intelligentem Design. Obwohl Herausforderungen im Bereich Vertrauen, Kontext und Governance bestehen, sind die potenziellen Vorteile für Effizienz, Genauigkeit und Skalierbarkeit erheblich.
Für Architekten und Entwickler bedeutet der Weg vorwärts die Akzeptanz dieser Werkzeuge als leistungsstarke Assistenten. Durch die Kombination menschlicher Expertise mit maschinellem Intellekt können Teams robuste Datenarchitekturen schaffen, die der Zeit standhalten. Die Zukunft der Datenmodellierung geht nicht darum, den menschlichen Geist zu ersetzen, sondern darum, ihn mit Werkzeugen zu stärken, die die Komplexität der modernen Datenlandschaft verstehen.