











Je komplexer Systeme werden, desto wichtiger wird die Stabilität der zugrundeliegenden Datenstrukturen für die betriebliche Zuverlässigkeit. Eine der anhaltendsten Herausforderungen, mit denen Ingenieurteams konfrontiert sind, ist die Schema-Drift. Dieses Phänomen tritt auf, wenn das Datenbankschema vom erwarteten Entwurf abweicht, was zu Inkonsistenzen, defekten Abfragen und unvorhersehbarem Anwendungsverhalten führt. Obwohl es oft als Problem der Datenbankverwaltung betrachtet wird, liegt die Ursache häufig in der Architektur und der Steuerung des Entity-Relationship-Diagramms (ERD) von Anfang an.
Ein gut strukturiertes ERD tut mehr als nur Beziehungen zu visualisieren; es fungiert als Vertrag zwischen der Anwendungslogik und der Datenspeicher-Ebene. In skalierbaren Umgebungen, in denen mehrere Dienste mit gemeinsam genutzten Daten interagieren, muss dieser Vertrag festgelegt sein, aber dennoch flexibel genug, um Wachstum zu ermöglichen. Dieser Leitfaden untersucht architektonische Muster und Methoden, die Datenmodelle stabilisieren und die Schema-Drift verhindern, bevor sie die Produktion beeinträchtigt.
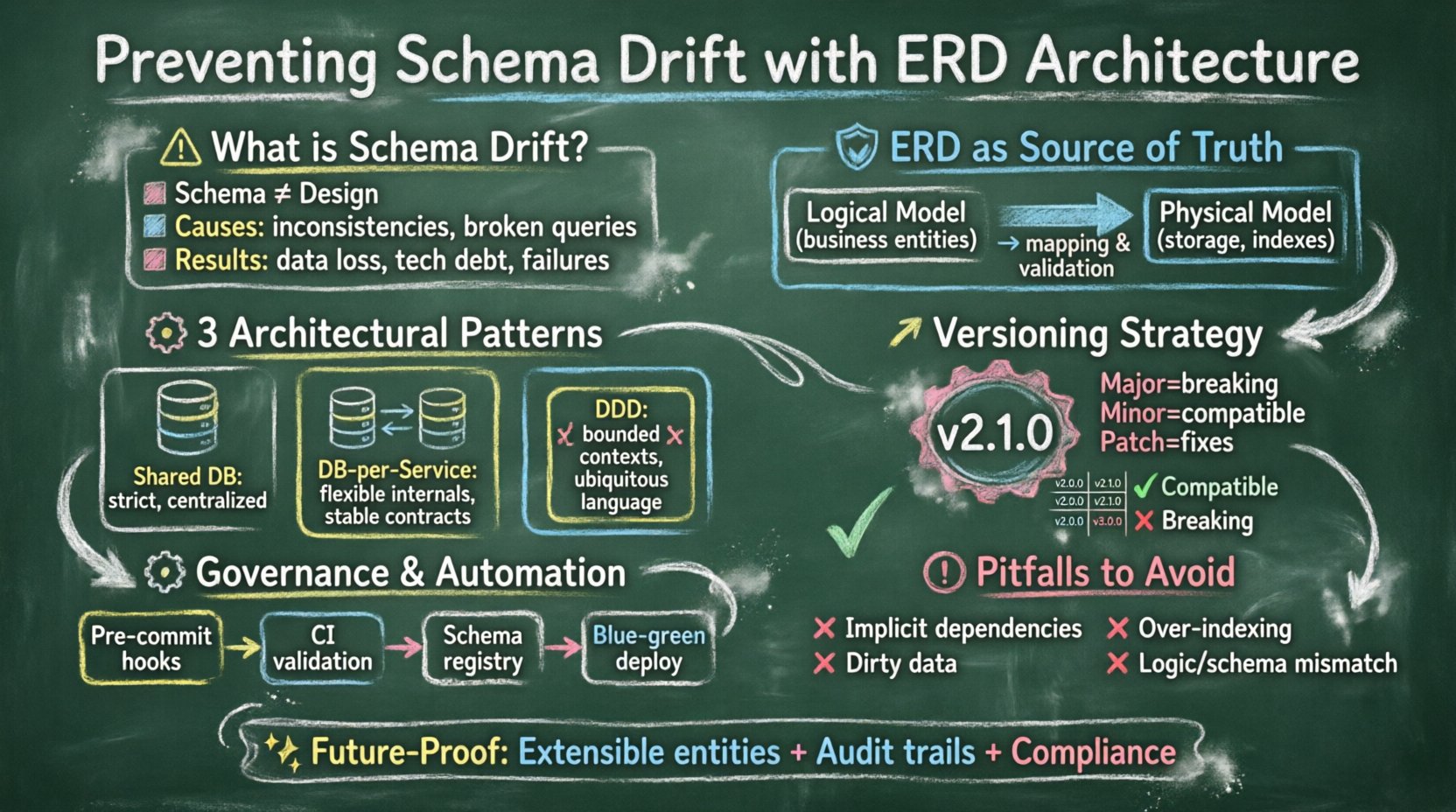
📉 Verständnis von Schema-Drift in verteilten Umgebungen
Schema-Drift ist nicht einfach nur die Vergesslichkeit, eine Tabelle zu aktualisieren. Es handelt sich um ein systemisches Problem, bei dem die physische Implementierung des Datenmodells im Laufe der Zeit von seiner logischen Definition abweicht. In monolithischen Systemen könnte dies sich als einige vergessene Spalten äußern. In verteilten, Mikrodienst-Architekturen kann es zu Rennbedingungen führen, bei denen Dienst A Daten in einem Format schreibt, das Dienst B nicht lesen kann.
Die Folgen einer ungezügelten Drift umfassen:
- Verlust der Datenintegrität:Einschränkungen werden umgangen, was ungültige Zustände zulässt.
- Erhöhter technischer Schuldenstand:Entwickler verbringen mehr Zeit mit der Behebung von Datenproblemen als mit der Entwicklung neuer Funktionen.
- Ausfälle von Diensten:APIs fallen aus, wenn bestimmte Feldtypen oder deren Existenz erwartet werden.
- Komplexität der Migration:Nachholen wird schwieriger, je größer die Lücke wird.
Dazu ist ein architektonischer Ansatz für das ERD erforderlich, der Konsistenz sicherstellt, ohne die Agilität einzuschränken. Dazu gehören die Festlegung von Änderungsregeln, die Versionsverwaltung des Datenmodells sowie die Etablierung einer Governance rund um das Diagramm selbst.
🛡️ Die Grundlage: ERD als Quelle der Wahrheit
Der erste Schritt zur Verhinderung von Drift besteht darin, das Entity-Relationship-Diagramm von einer statischen Zeichnung zu einem lebendigen Dokument zu erheben, das die Implementierung vorantreibt. Wenn das ERD als sekundäres Artefakt behandelt wird, ist Drift unvermeidbar. Wenn es als primäre Quelle der Wahrheit betrachtet wird, unterstützt die Architektur Stabilität.
1. Logische vs. physische Trennung
Um Flexibilität zu bewahren, während Stabilität gewährleistet wird, trennen Sie das logische Datenmodell von der physischen Implementierung. Das logische ERD sollte Geschäftsentitäten und ihre Beziehungen ohne technische Einschränkungen beschreiben. Das physische ERD behandelt Indizierung, Partitionierung und spezifische Speicherarten.
Diese Trennung ermöglicht es der Geschäftslogik, sich zu entwickeln, ohne dass sofortige physische Änderungen erforderlich sind. Sie schafft eine Pufferzone, in der Änderungen gegen die Geschäftsanforderungen validiert werden können, bevor sie die Speicherebene beeinflussen.
2. Kanonische Datenmodelle
In skalierbaren Systemen müssen mehrere Dienste oft dasselbe Datenverständnis haben. Die Etablierung eines kanonischen Datenmodells stellt sicher, dass alle Dienste auf dieselben Definitionen verweisen. Das ERD definiert diese kanonischen Entitäten.
- Einzelquelle der Wahrheit: Das ERD definiert genau das Schema für kritische Entitäten wie Benutzer, Bestellung oder Lagerbestand.
- Dienstverträge:Dienste konsumieren Daten basierend auf der ERD-Definition, nicht auf ad-hoc-Abfragen.
- Standardisierte Benennung:In der ERD definierte Namenskonventionen verhindern Mehrdeutigkeiten über verschiedene Datenbankinstanzen hinweg.
🧩 Architektonische Muster für ERD-Stabilität
Verschiedene Systemarchitekturen erfordern unterschiedliche ERD-Strategien. Die folgenden Muster helfen dabei, Konsistenz aufrechtzuerhalten, während das System skaliert.
1. Das Muster der gemeinsam genutzten Datenbank
In einigen monolithischen oder eng verzahnten Systemen wird eine gemeinsam genutzte Datenbank verwendet. Hier muss das ERD äußerst streng sein. Änderungen am ERD erfordern eine Abstimmung über alle Module, die auf diese Datenbank zugreifen.
- Zentralisierte Schema-Verwaltung: Ein einziges Team ist für die ERD-Updates verantwortlich.
- Strenge Zugriffssteuerung: Nur autorisierte Skripte dürfen das Schema ändern.
- Abhängigkeitsverfolgung: Das ERD muss Abhängigkeiten zwischen Tabellen klar abbilden, um die Auswirkungen vor Änderungen zu identifizieren.
2. Das Muster der Datenbank pro Dienst
In Microservices-Architekturen besitzt jeder Dienst seine Daten. Dies reduziert die direkte Kopplung, führt aber zum Risiko inkonsistenter Datendefinitionen zwischen Diensten. Die ERD-Architektur konzentriert sich hier auf die Schnittstelle zwischen Diensten und nicht auf die interne Speicherung jedes einzelnen Dienstes.
- Interne Flexibilität: Jeder Dienst kann sein internes Schema weiterentwickeln, solange die externe Schnittstelle stabil bleibt.
- Externe Verträge: Das ERD definiert die gemeinsam genutzten Verträge. Wenn Dienst A Daten von Dienst B benötigt, definiert das ERD die erwartete Struktur.
- Event Sourcing: Das ERD kann die Ereignisse definieren, die Daten tragen, wodurch Unveränderlichkeit und Nachverfolgbarkeit gewährleistet werden.
3. Der Ansatz des domain-driven Designs (DDD)
Domain-Driven Design aligniert das Datenbankschema mit Geschäftsbereichen. Das ERD wird in begrenzte Kontexte aufgeteilt. Dies verhindert das „Gott-Tabelle“-Problem, bei dem unzusammenhängende Entitäten gezwungen werden, in einem einzigen Schema zu existieren.
- Kontextabbildung: Das ERD zeigt die Beziehungen zwischen begrenzten Kontexten auf.
- Allgegenwärtige Sprache: Die Namensgebung der Entitäten im ERD entspricht der Geschäftsterminologie.
- Kapselung: Interne Entitäten sind versteckt; es wird nur die Domänen-Grenze sichtbar gemacht.
🔄 Versionsstrategien für die Schema-Evolution
Änderungen sind unvermeidlich. Ziel ist es, sie zu managen, ohne bestehende Verbraucher zu brechen. Die Versionierung des Schemas innerhalb der ERD-Architektur ist entscheidend.
1. Semantische Versionierung für Schemas
Genau wie Software-Code verwendet semantische Versionierung, sollten auch Daten-Schemas dies tun. Eine Schema-Version kann als Hauptversion.Nebenversion.Patch bezeichnet werden.
- Hauptversion:Breaking Changes (z. B. Entfernen einer Spalte, Ändern eines Typs).
- Minor: Rückwärtskompatible Ergänzungen (z. B. Hinzufügen einer spalten mit NULL-Werten).
- Patch:Interne Korrekturen oder Optimierungen, die die API nicht beeinflussen.
2. Regeln für Rückwärtskompatibilität
Um eine Abweichung zu vermeiden, halten Sie sich an strenge Regeln bezüglich der Entwicklung des Schemas. Die folgende Tabelle zeigt sichere im Vergleich zu unsicheren Änderungen auf.
| Aktion | Kompatibilität | Anforderung |
|---|---|---|
| Neue Spalte hinzufügen | Rückwärtskompatibel | Muss anfangs NULL-Werte zulassen |
| Neue Tabelle hinzufügen | Rückwärtskompatibel | Stellen Sie sicher, dass anfangs keine Fremdschlüsselabhängigkeiten bestehen |
| Spalte entfernen | Breaking Change | Zuerst veralten lassen, später entfernen |
| Datentyp ändern | Breaking Change | Erfordert einen vollständigen Migrationsplan |
| Fremdschlüssel hinzufügen | Bedingt | Stellen Sie sicher, dass die vorhandenen Daten die Einschränkung erfüllen |
3. Dual-Write-Muster
Wenn eine Schemaänderung erforderlich ist, vermeiden Sie einen sofortigen Wechsel. Implementieren Sie ein Dual-Write-Verfahren, bei dem Daten gleichzeitig in das alte und das neue Struktur geschrieben werden. Im Laufe der Zeit wird der Datenverkehr auf die neue Struktur umgeleitet. Das ERD sollte während dieses Übergangs beide Versionen dokumentieren.
- Lesepfad:Lesen Sie weiterhin aus dem stabilen Schema.
- Schreibpfad:Schreiben Sie gleichzeitig in beide Schemata.
- Validierung: Überwachen der Datenkonsistenz zwischen den beiden Schemata.
- Umschaltphase: Sobald die Überprüfung abgeschlossen ist, die Schreibvorgänge im alten Schema beenden.
⚙️ Migration-Management und Governance
Selbst mit Versionsverwaltung sind Migrationen notwendig. Die Architektur muss sichere, rückgängig machbare und automatisierte Migrationen unterstützen.
1. Migrationsskripte als Code
Migrationen sollten zusammen mit dem Anwendungscode versioniert werden. Das ERD dient als Zielzustand für diese Skripte. Jede Migration-Datei sollte auf die spezifische ERD-Version verweisen, die sie implementiert.
- Idempotenz: Skripte sollten sicher mehrfach ausgeführt werden können.
- Rückgängigmachbarkeit: Jeder Upgrade muss über ein entsprechendes Downgrade-Skript verfügen.
- Atomarität: Änderungen sollten, wo möglich, transaktional sein, um partielle Aktualisierungen zu verhindern.
2. Schema-Registrierung
Implementieren Sie eine Schema-Registrierung, um den Zustand des ERD über Umgebungen hinweg zu verfolgen. Dadurch wird sichergestellt, dass die Entwicklungs-, Staging- und Produktionsumgebungen synchronisiert sind.
- Umgebungsparität: Verhindert Abweichungen zwischen Entwicklung und Produktion.
- Genehmigungsabläufe: Schema-Änderungen erfordern eine Überprüfung, bevor sie weitergeleitet werden.
- Validierung: Automatisierte Prüfungen stellen sicher, dass das bereitgestellte Schema mit dem registrierten ERD übereinstimmt.
3. Dokumentation als Code
Die Dokumentation sollte direkt aus dem ERD generiert werden. Dadurch wird sichergestellt, dass Diagramme und Textbeschreibungen synchron bleiben. Manuelle Dokumentation wird oft schnell veraltet.
- Automatisierte Generierung: Werkzeuge können Dokumentation aus der ERD-Datei generieren.
- Lebende Dokumente: Dokumentationsaktualisierungen sind Teil des Code-Review-Prozesses.
- Kontextbezogene Notizen: Fügen Sie geschäftliche Logik-Notizen direkt in die ERD-Metadaten ein.
📝 Automatisierung und CI/CD-Integration
Menschliches Versagen ist eine Hauptursache für Schema-Drift. Automatisierung reduziert dieses Risiko, indem Regeln während der Bereitstellungspipeline durchgesetzt werden.
1. Pre-Commit-Hooks
Implementieren Sie Hooks, die Schemaänderungen überprüfen, bevor sie in das Repository committet werden. Diese Hooks prüfen auf brechende Änderungen im Vergleich zur aktuellen ERD-Definition.
- Linting: Setzen Sie Namenskonventionen und Strukturregeln durch.
- Validierung: Stellen Sie sicher, dass neue Einschränkungen nicht mit bestehenden Daten konflikten.
- Überprüfung: Fordern Sie manuelle Genehmigung für hochriskante Änderungen an.
2. Kontinuierliche Integrationsprüfungen
Führen Sie während des CI-Prozesses eine Schema-Validierung an einer Testdatenbank durch. Dadurch werden Probleme vor der Bereitstellung erkannt.
- Sandbox-Umgebungen: Bereitstellen in einer temporären Umgebung, um Migrationen zu testen.
- Integrationstests: Führen Sie Abfragen aus, die auf dem Schema basieren, um die Funktionalität zu gewährleisten.
- Leistungsprüfungen: Stellen Sie sicher, dass neue Indizes die Schreibleistung nicht verschlechtern.
3. Blue-Green-Bereitstellungen für Daten
Ähnlich wie bei Anwendungs-Bereitstellungen verwenden Sie Blue-Green-Strategien für Daten. Halten Sie zwei Versionen des Schemas parallel, bis die neue Version stabil ist.
- Null-Downtime: Benutzer werden von Schema-Änderungen nicht beeinflusst.
- Sofortiges Zurücksetzen: Falls Probleme auftreten, wechseln Sie zurück zur vorherigen Schema-Version.
- Daten-Synchronisation: Stellen Sie sicher, dass die Daten während des Übergangs zwischen beiden Versionen konsistent sind.
🚨 Häufige Fallen, die vermieden werden sollten
Selbst mit einer soliden Architektur geraten Teams oft in Fallen, die die Drift erneut einführen. Das Bewusstsein für diese Fallen ist für langfristige Stabilität unerlässlich.
1. Implizite Abhängigkeiten
Code beruht oft auf Datenstrukturen, die nicht explizit in der ERD definiert sind. Festcodierte Spaltennamen oder Annahmen über die Datenanwesenheit führen zu stillen Fehlern.
- Explizite Typisierung: Verwenden Sie starke Typisierung in allen Datenzugriffsschichten.
- Schnittstellenverträge: Definieren Sie klare Schnittstellen für den Datenzugriff.
- Refactoring: Überprüfen Sie den Code regelmäßig auf implizite Annahmen.
2. Ignorieren der Datenqualität
Ein Schema kann perfekt sein, aber wenn die eintretenden Daten verschmutzt sind, versagt das System. Das ERD sollte Einschränkungen enthalten, die die Datenqualität sicherstellen.
- Prüfbeschränkungen: Überprüfen Sie Werte auf Datenbankebene.
- Eindeutigkeitsbeschränkungen: Verhindern Sie doppelte Einträge.
- Nicht-Null-Beschränkungen: Stellen Sie sicher, dass erforderliche Felder immer ausgefüllt sind.
3. Überindizierung
Das Hinzufügen von Indizes zur Verbesserung der Leseleistung verlangsamt oft das Schreiben. Dies kann zu Schemaänderungen führen, die den Schreibpfad stören.
- Messung zuerst: Überwachen Sie die Abfrageleistung, bevor Sie Indizes hinzufügen.
- Überprüfen Sie regelmäßig: Entfernen Sie nicht verwendete Indizes, um die Belastung zu reduzieren.
- Ausgewogenheit: Finden Sie die richtige Balance zwischen Lese- und Schreibleistung.
4. Trennung der Logik von der Schemastruktur
Die Anwendung von Geschäftslogik in der Anwendungsschicht, die eigentlich in der Datenbank liegen sollte, führt zu Inkonsistenzen. Das ERD sollte zeigen, wo die Logik liegt.
- Datenbankbeschränkungen: Verschieben Sie Logik in Trigger oder gespeicherte Prozeduren, wenn angebracht.
- Validierung: Stellen Sie sicher, dass die Anwendungslogik Datenbankregeln nicht umgeht.
- Klarheit: Dokumentieren Sie in den ERD-Notizen, wo die Logik liegt.
🔮 Zukunftsorientierte Gestaltung des Datenmodells
Skalierbare Systeme müssen für die Zukunft gerüstet sein. Die ERD-Architektur sollte Wachstum und Veränderungen vorwegnehmen.
1. Erweiterbarkeit
Gestalten Sie Entitäten so, dass sie erweiterbar sind. Verwenden Sie flexible Datentypen oder JSON-Spalten für Attribute, die variieren können, während die Kernstruktur stabil bleibt.
- Attributgruppen:Speichern Sie variable Attribute in einer strukturierten Karte.
- Tags und Bezeichnungen:Verwenden Sie Schlüssel-Wert-Paare für dynamische Metadaten.
- Versionsfelder:Fügen Sie Versionsnummern in Entitäten ein, um Änderungen nachzuverfolgen.
2. Audit-Verläufe
Jede Änderung an den Daten sollte nachvollziehbar sein. Der ERD sollte Audit-Tabellen enthalten, um zu protokollieren, wer was und wann geändert hat.
- Verlaufstabellen:Führen Sie einen Verlauf der Änderungen an Datensätzen.
- Änderungsprotokolle:Protokollieren Sie Schema-Änderungen getrennt von Datenänderungen.
- Zugriffsprotokolle:Verfolgen Sie, wer sensible Daten abfragt.
3. Compliance und Sicherheit
Datenmodelle müssen regulatorischen Anforderungen entsprechen. Der ERD sollte definieren, wo sensible Daten gespeichert werden und wie sie geschützt werden.
- Verschlüsselung:Markieren Sie Felder, die verschlüsselt werden müssen.
- Aufbewahrungsrichtlinien:Definieren Sie, wie lange Daten im Schema aufbewahrt werden.
- Zugriffssteuerung:Definieren Sie Rollen, die auf bestimmte Entitäten zugreifen dürfen.
🏁 Letzte Überlegungen zur architektonischen Integrität
Das Verhindern von Schema-Drift geht nicht darum, Änderungen einzuschränken; es geht darum, sie diszipliniert zu managen. Indem man das Entity-Relationship-Diagramm als zentrales architektonisches Artefakt behandelt, können Teams Systeme bauen, die sowohl robust als auch anpassungsfähig sind. Der Schlüssel liegt in der Trennung von Anliegen, strenger Versionsverwaltung und automatisierter Governance.
Wenn der ERD respektiert wird, wird das Datenmodell zu einer stabilen Grundlage, auf der skalierbare Anwendungen aufgebaut werden können. Dies verringert die kognitive Belastung für Entwickler, minimiert betriebliche Risiken und stellt sicher, dass das System auch bei Wachstum wartbar bleibt. Die Architektur des Diagramms bestimmt die Stabilität der Daten und damit indirekt die Stabilität des Geschäfts.
Die Einführung dieser Muster erfordert eine anfängliche Investition in Prozesse und Werkzeuge. Doch der langfristige Nutzen ist ein System, das sich reibungslos entwickelt, ohne ständig die Last von defekten Datenverträgen zu tragen. Priorisieren Sie die Integrität des Datenmodells, und das System wird folgen.