











数据建模是任何稳健数据库架构的基石。尽管理论通常在大学课程中讲授,但在生产环境中的实际应用却揭示了一个充满边缘情况、性能瓶颈和逻辑模糊性的领域。实体关系图(ERD)是这些系统的蓝图,然而当现实世界拒绝被整齐地塞进方框和线条中时,它们常常成为争议的来源。
我们与一组首席数据库管理员和数据架构师坐下来,深入分析那些在设计阶段反复困扰团队的场景。这些并非理论练习,而是当业务需求与物理存储限制发生冲突时实际出现的问题。这里的目标不是提供快速解决方案,而是深入理解其中涉及的权衡。
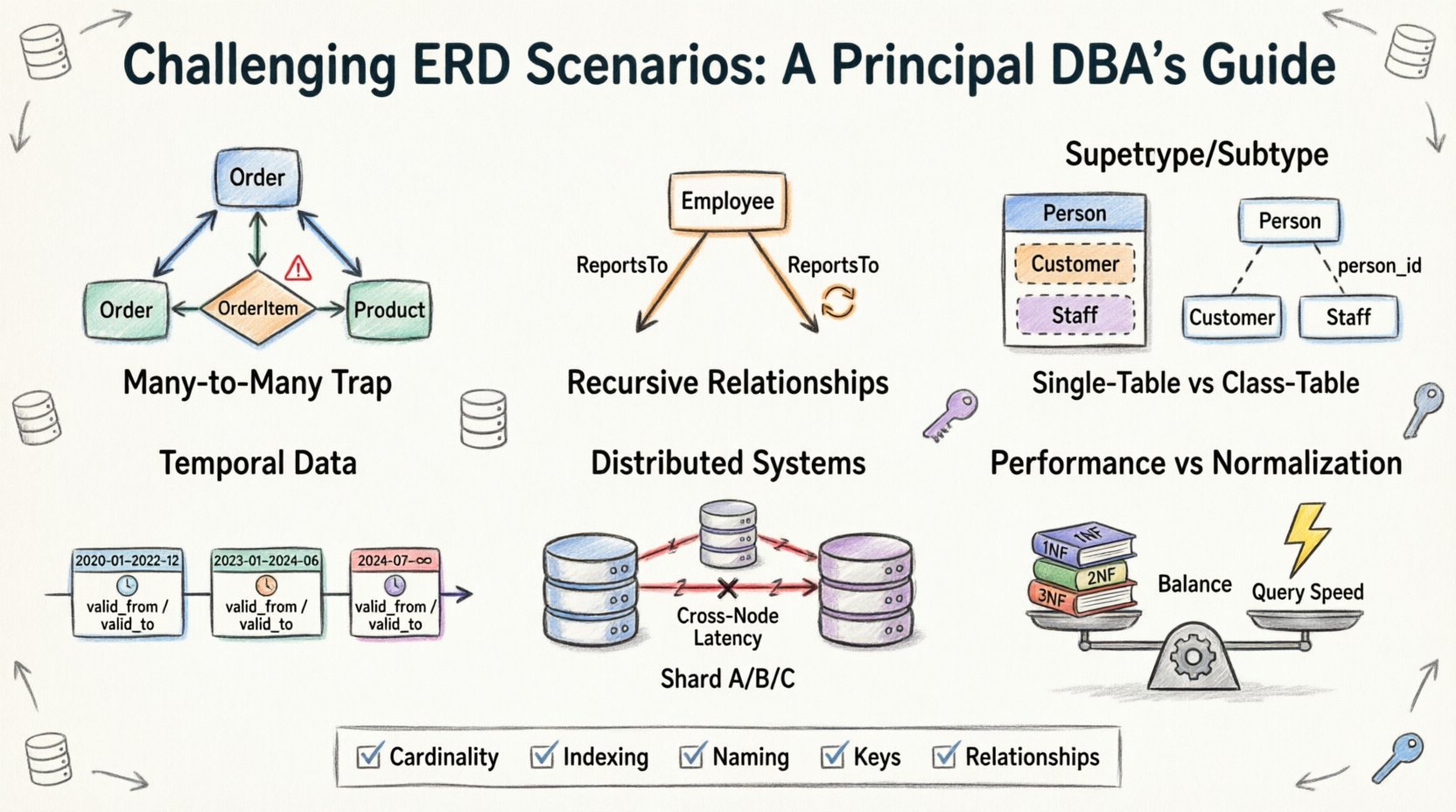
1. 多对多陷阱:超越简单的连接表 🕸️
在ERD设计中最常见的起点是多对多关系。这看起来很直观:一个学生可以选修多门课程,而一门课程也可以有多个学生。标准解决方案是使用一个桥接表或关联表。然而,当关系本身引入属性时,复杂性便随之而来。
- 问题:通常,团队会尝试将注册数据(如成绩或注册日期)存储在主学生表或课程表中,导致大量冗余或空值。
- 现实:关系本身就是一个实体。它必须拥有自己的主键以及指向父表的外键。
- 挑战:处理级联删除。如果删除一门课程,相关的注册记录会怎样?如果删除一条注册记录,学生是否也会消失?这些决策决定了数据的完整性。
在我们的讨论中,一位首席数据库管理员指出,关联表常常成为性能瓶颈。当跨此连接点查询数据时,数据库引擎必须执行一个连接操作,而随着行数增长到数百万级别,这种操作的扩展性往往很差。解决方案并不总是架构层面的;有时需要去规范化,但这会引入更新异常。
多对多关系的关键考虑因素:
- 该关系是否具有需要索引的属性?
- 该关系是当前的还是历史的?(例如,当前注册与过去注册是否不同?)
- 如果父记录被删除,系统将如何处理孤立记录?
2. 递归关系:自引用层次结构 🌳
层次化数据无处不在。想想组织架构图、物料清单,或论坛中的评论线程。建模这类数据需要一张表引用自身。虽然概念上很简单,但在关系模式中实现时,会带来关于深度和遍历的特定挑战。
结构问题:
你创建一张表,包含一个主键和一个外键列,该列指向同一张表的主键。这通常被称为“父级ID”列。根节点的父级为null。
性能问题:
标准SQL查询在处理深层层次结构时会遇到困难。如果你需要获取一位经理及其所有直接和间接下属,简单的JOIN操作是不够的。你需要使用递归公用表表达式(CTEs)或遍历层级的存储过程。这可能带来巨大的计算开销。
完整性问题:
循环引用是无声的杀手。如果员工A管理员工B,而员工B又管理员工A,你就形成了一个循环。数据库必须阻止这种情况,或者应用程序逻辑必须检测到它。在大型系统中,循环可能导致报告工具陷入无限循环。
- 深度限制:大多数系统会限制层次结构的深度(例如,32层),以防止遍历时发生栈溢出错误。
- 路径聚合:计算子树的总成本或数量需要递归逻辑,这在标准查询计划中难以优化。
3. 超类型与子类型建模:继承困境 🧬
在面向对象编程中,继承是标准做法。而在关系型数据库中,这是一种影响存储和检索的设计选择。问题是:你是将车辆建模为一张表,还是将其拆分为车辆、汽车和卡车三张表?
选项A:单表继承
所有子类型的属性都位于一个表中。未使用的属性使用空值。
- 优点:查询简单,查找任何车辆都不需要连接操作。
- 缺点:表膨胀,难以强制执行子类型特定的约束,存在大量可为空的列。
选项B:类表继承
超类型(Vehicle)使用一个表,子类型(Car、Truck)使用独立的表,通过主键关联。
- 优点:结构清晰,无空值,每个子类型可严格约束。
- 缺点:查询需要连接多个表,可能影响读取性能。
我们的首席数据库管理员指出,选择通常取决于查询模式。如果你频繁查询特定子类型,类表方法更优;如果你频繁对所有子类型进行聚合,单表方法更胜一筹。ERD必须清晰反映这一决策,以避免未来开发人员产生混淆。
4. 时间数据:追踪随时间的变化 ⏳
业务规则会变化。客户搬家、价格更新、合同到期。仅存储“当前”状态通常不足以满足审计或报告需求。这促使了时间表或缓慢变化维度(SCD)的设计。
复杂性:
不是更新行,而是插入一条带有有效起始和结束日期的新行,旧行被标记为非活跃状态。这使得历史数据的存储需求翻倍,并使“当前视图”查询变得复杂。
查询挑战:
选择某个时间点的数据需要基于日期范围进行过滤。如果遗漏了日期范围逻辑,可能会返回记录的错误版本。这通常是金融应用中数据完整性问题出现的地方。
- 快照设计:存储某个时间点的状态。需要定期的批处理任务来写入快照。
- 事务日志设计:捕获每一次变更。写入量高,检索逻辑复杂。
- 周期性设计:存储有效时间段。能很好地处理时间间隔的空缺,但需要仔细管理边界。
5. 分布式系统:分片与关系 🔗
当单个数据库无法容纳数据时,分片就变得必要。这正是ERD设计面临最严重物理限制的地方。跨越分片边界的关联操作代价高昂。
连接问题:
如果表A按用户ID分片,且表B与表A相关联,则表B必须按相同的用户ID分片,以避免分布式连接。如果表B按其他方式分片,则必须将查询路由到多个分片,聚合结果并在本地连接。
参照完整性:
外键约束在跨分布式节点时难以强制执行。许多系统在分片环境中禁用外键以保持可用性。这将完整性保障的负担转移到了应用层,而应用层容易出现竞争条件。
分布式ERD的关键要点:
- 避免跨越多个分片的多对多关系。
- 对数据进行反规范化,以减少跨节点连接的需求。
- 根据最频繁的查询模式来设计分区键(分片键),而不仅仅是主键。
6. 性能与规范化之间的权衡 ⚖️
规范化(1NF、2NF、3NF)被作为数据完整性的黄金标准教授。然而,在高吞吐量系统中,严格的规范化可能会严重影响性能。ERD必须在这两者之间取得平衡。
何时进行反规范化:
- 读取密集型工作负载: 如果读取数据的频率远高于写入,添加冗余列可以避免连接操作。
- 报表需求:在规范化数据上进行聚合需要复杂的连接操作,这会拖慢仪表板的响应速度。
- 写入密集型工作负载: 有时,将数据分开存储可以减少更新时的锁争用。
我们的小组强调,不存在所谓的“完美”模式。它始终是一种折衷。ERD应记录反规范化发生的位置及其原因,以便未来的维护者理解冗余是故意为之,而非错误。
建模模式对比 📊
为了辅助决策,以下是所讨论建模模式的总结及其典型应用场景。
| 模式 | 最佳使用场景 | 主要风险 | 复杂度 |
|---|---|---|---|
| 单表模式 | 简单的层级结构,种类较少 | 空字段,模式膨胀 | 低 |
| 类表模式 | 严格的子类型,具有明显属性差异 | 连接开销 | 中等 |
| 递归模式 | 组织架构图、分类 | 遍历深度、循环 | 高 |
| 关联实体 | 带属性的多对多 | 连接性能 | 中 |
| 时间性 | 审计、历史追踪 | 查询复杂度 | 高 |
| 分布式分片 | 海量规模、横向扩展 | 引用完整性 | 非常高 |
ERD审查清单 ✅
在最终确定实体关系图之前,请使用此清单来发现常见的陷阱。在设计阶段发现问题,总比在生产环境中发现要好。
- 基数:你是否明确定义了一对一、一对多和多对多的关系?最小/最大约束(0..1, 1..*)是否明确?
- 数据类型:列类型是否适合预期的数据大小?(例如,ID使用Integer还是Varchar)。
- 可空性:外键是否可为空?如果是,逻辑是否能优雅地处理孤立引用?
- 索引策略:ERD是否指明了哪些列需要索引以提升性能?外键通常会被索引以加快连接操作。
- 命名规范:表名和列名是否一致?避免使用日后可能产生歧义的缩写。
- 业务规则:约束条件(例如,“一个用户不能有两个活跃的订阅”)是否以逻辑检查或数据库约束的形式体现?
- 可扩展性: 模式能否在不需完整迁移的情况下容纳新属性?(例如,在适当情况下使用EAV模式或JSON列)。
数据建模的最终思考 🧠
设计实体关系图不仅仅是画方框和线条。它关乎理解数据的流动、硬件的限制以及业务的需求。这里讨论的场景代表了理论与实践交汇处的摩擦点。
通过预见这些挑战——递归深度、分布式连接、时间历史记录以及继承的权衡——你可以构建出更具韧性的模式。精心设计的ERD能够减少技术债务,避免日后需要付出高昂代价的重构。这是对整个系统稳定性的一项投资。
请记住,最好的模式是能够随着数据一起演进的模式。文档至关重要。确保每一次对标准范式的偏离都有充分的理由并被记录下来。正是这种透明性,将稳健的数据库架构与脆弱的架构区分开来。