










Entity Relationship Diagrams (ERDs) serve as the foundational blueprint for database architecture. They translate abstract business logic into structured data models that systems can process. Within this landscape, the one-to-many relationship stands as the most prevalent structural pattern. However, widespread misconceptions surround its implementation, cardinality, and performance implications. Understanding the nuances of these connections is vital for creating robust, scalable data models.
Many practitioners approach data modeling with preconceived notions derived from simplified tutorials or outdated practices. These assumptions often lead to inefficiencies, data integrity issues, or difficult maintenance cycles later in the project lifecycle. This guide dissects the common myths surrounding one-to-many relationships. We explore the technical realities of cardinality, foreign keys, and normalization without relying on specific software vendors.
🧐 Understanding the Core Concept
Before addressing misconceptions, it is essential to establish a clear definition. In data modeling, a relationship describes how instances of one entity relate to instances of another. The one-to-many relationship indicates that a single record in the first entity can be associated with multiple records in the second entity.
Consider a library system. A single Author entity can be linked to multiple Book entities. Conversely, a specific Book is typically written by a specific Author (in a simplified model). This is the classic one-to-many dynamic. The entity on the one side is often called the parent, while the entity on the many side is the child.
- Parent Entity: The entity holding the unique key (Primary Key).
- Child Entity: The entity holding the reference to the parent (Foreign Key).
- Cardinality: The numerical limit of relationships (e.g., 1 to N).
Visual notation varies across standards like Chen, Crow’s Foot, or UML. Regardless of the symbol used, the underlying mathematical logic remains constant. The integrity of this relationship dictates how data is stored, retrieved, and secured.
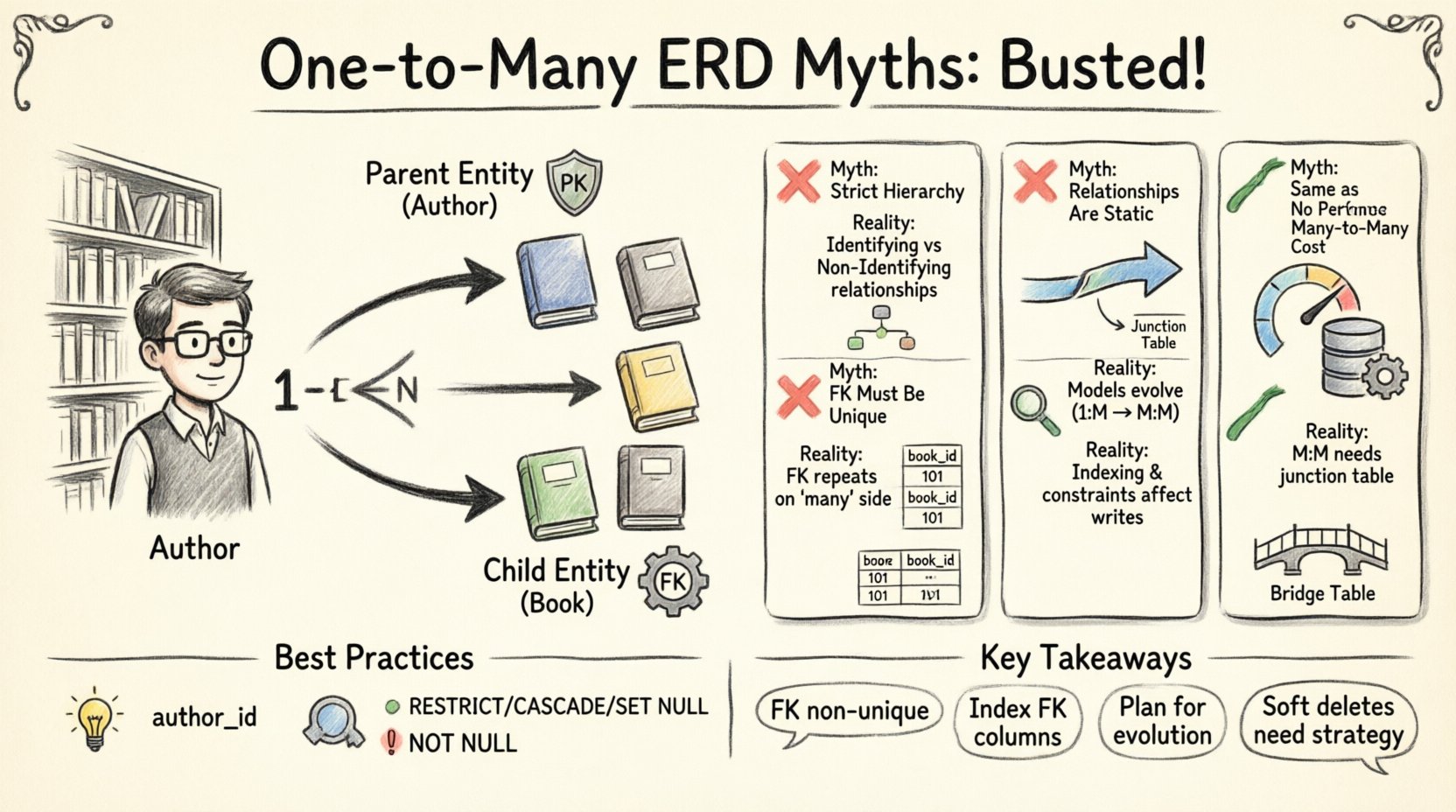
❌ Myth 1: One-to-Many Always Implies Strict Hierarchy
A common assumption is that one-to-many relationships strictly dictate a parent-child hierarchy where the parent controls the existence of the child. While this is true in some specific business rules, it is not a universal law of database design.
🔍 The Reality of Existence Dependency
Not all child records depend on the parent for their existence. In database terminology, this is known as existence dependency. If a child record can exist without a parent, the relationship is non-identifying. If the child cannot exist without the parent, it is identifying.
- Non-Identifying: A Customer can exist without an Order. The Customer table stands alone. The Order table references the Customer.
- Identifying: An Order Item cannot exist without an Order. The Order Item table might share the Order ID as part of its primary key.
Assuming strict hierarchy when none exists can lead to unnecessary constraints. For instance, enforcing a CASCADE DELETE on a non-dependent relationship might inadvertently remove valid data. Always verify the business rule before applying strict referential integrity constraints.
❌ Myth 2: Foreign Keys Must Be Unique
Confusion often arises regarding the uniqueness constraint on the foreign key column. A foreign key in a one-to-many relationship is explicitly designed to be non-unique on the many side.
🔍 The Reality of Cardinality Constraints
The primary key of the parent table is unique. The foreign key in the child table references that primary key. Since one parent connects to many children, the foreign key value must repeat. If the foreign key were unique, the relationship would become one-to-one.
| Aspect | One-to-One | One-to-Many |
|---|---|---|
| Foreign Key Uniqueness | Unique | Non-Unique |
| Indexing Strategy | Often Unique Index | Standard Index |
| Data Redundancy | Low | Higher (by design) |
Ensuring the foreign key is non-unique is critical. If a system enforces uniqueness on the child side, it limits the model to a single association, breaking the intended data structure. This is a common configuration error in automated modeling tools.
❌ Myth 3: Relationships Are Static
Many designers assume that once a one-to-many relationship is defined in the diagram, it remains immutable. Data models, however, must evolve with the business. Assumptions about static relationships ignore the dynamic nature of data.
🔍 The Reality of Model Evolution
Business requirements change. A product might initially belong to one category, but later, the business expands to allow multiple categories per product. This shifts the model from one-to-many to many-to-many.
- Refactoring Risk: Changing a relationship type often requires data migration scripts.
- Backward Compatibility: Old reports may rely on the original structure.
- Versioning: Maintaining a history of schema changes is essential for long-term stability.
Designers should anticipate future growth. While a one-to-many relationship is standard now, the schema should allow for flexibility. Using surrogate keys (auto-incrementing IDs) rather than natural keys (like email addresses) as foreign keys often simplifies these transitions.
❌ Myth 4: Foreign Keys Have No Performance Cost
There is a belief that adding foreign key constraints is purely for logic and has negligible performance impact. In reality, every constraint requires the database engine to perform checks during write operations.
🔍 The Reality of Write Performance
When inserting a record into the child table, the database must verify that the referenced parent record exists. This involves a lookup operation. In high-throughput systems, this lookup adds latency.
- Index Overhead: Foreign key columns should be indexed to speed up the verification process.
- Locking: Referential integrity checks may require locks on the parent table.
- Cascading Operations: If
CASCADE DELETEis enabled, deleting a parent triggers multiple child deletions, which can be resource-intensive.
For massive data ingestion scenarios, some architects temporarily disable foreign key constraints to improve throughput. However, this risks data corruption. The trade-off between integrity and speed must be calculated based on the specific use case.
❌ Myth 5: One-to-Many is the Same as Many-to-Many
Practitioners sometimes confuse the visual representation of one-to-many with many-to-many. While they look similar in high-level diagrams, the implementation differs significantly.
🔍 The Reality of Junction Tables
A true many-to-many relationship requires an intermediate table, often called a junction or bridge table. A one-to-many relationship does not.
- One-to-Many: Direct link via a foreign key in the child table.
- Many-to-Many: Requires a new table containing foreign keys to both entities.
Attempting to implement many-to-many logic using a single foreign key column will result in data duplication or loss. For example, if you try to link a Student to multiple Courses using only a course_id in the Student table, a student can only enroll in one course. To allow multiple enrollments, you need an Enrollment table.
🛠️ Best Practices for Implementation
Adhering to best practices ensures that the one-to-many relationships remain robust. These guidelines focus on structure, naming, and integrity.
📝 Naming Conventions
Consistent naming reduces ambiguity. Foreign keys should clearly indicate the relationship. A column named author_id is more explicit than auth_id.
- Standard Format:
parent_table_singular_id. - Consistency: Apply this pattern across all entities.
- Case Sensitivity: Stick to lowercase or uppercase to avoid case-sensitivity issues in different operating systems.
🔒 Referential Integrity
Enforcing integrity prevents orphaned records. An orphaned record is a child entry pointing to a parent that no longer exists.
- ON DELETE RESTRICT: Prevents deletion of the parent if children exist.
- ON DELETE CASCADE: Deletes children when the parent is removed.
- ON DELETE SET NULL: Clears the foreign key if the parent is removed.
Choosing the right action depends on data criticality. For financial transactions, RESTRICT is usually safer. For temporary logs, CASCADE might be acceptable.
⚙️ Normalization and One-to-Many
Normalization is the process of organizing data to reduce redundancy. One-to-many relationships are the primary mechanism used to achieve normalization.
📊 Second Normal Form (2NF)
2NF requires that all non-key attributes are fully dependent on the primary key. One-to-many relationships help isolate repeating groups. If a table contains a list of items, moving that list to a separate table creates a one-to-many link.
- Before: A single row contains multiple product names.
- After: The product name moves to a new table linked by a product ID.
This separation ensures that updating a product name only requires changing one row, rather than updating multiple rows where the name is repeated.
📊 Third Normal Form (3NF)
3NF eliminates transitive dependencies. One-to-many relationships help ensure that non-key attributes depend only on the primary key, not on other non-key attributes.
For example, if a table stores EmployeeID, DepartmentID, and DepartmentName, there is a transitive dependency (Employee -> Department -> DepartmentName). Splitting this into an Employee table and a Department table creates a one-to-many relationship that resolves the dependency.
🚧 Common Pitfalls to Avoid
Avoiding errors during the design phase saves significant time during development. The following pitfalls are frequently encountered.
- Over-Normalization: Creating too many tables can make queries complex. Balance normalization with query performance.
- Missing Foreign Keys: Relying on application logic to enforce relationships is risky. Database constraints are the source of truth.
- Incorrect Nullability: Foreign keys should usually be
NOT NULLunless the relationship is optional. ANULLforeign key implies no relationship, which might violate business rules. - Data Types Mismatch: Ensure the data type of the foreign key matches the primary key exactly. Using
VARCHARon one side andINTon the other will break the link.
📉 Visual Representation in ERD
Clarity in the diagram is as important as the logic behind it. The visual notation communicates the structure to stakeholders who may not write code.
👣 Crow’s Foot Notation
This is the most common standard. The one side has a single vertical line. The many side has a crow’s foot (three branching lines).
- Circle: Indicates an optional relationship (0..N).
- Line: Indicates a mandatory relationship (1..N).
📐 Chen Notation
Uses diamond shapes for relationships. While less common in modern tools, it provides a clear conceptual view of the entities and their connections.
🔄 Handling Soft Deletes
In many systems, data is never truly deleted. Instead, it is marked as inactive. This is known as a soft delete.
🔍 The Impact on Relationships
Soft deletes complicate one-to-many relationships. If a parent is soft-deleted, should the children remain linked?
- Option 1: Cascade the soft delete flag to all children.
- Option 2: Keep children active but hide them from queries.
- Option 3: Require a separate logic to handle the link.
Designers must decide this during the schema creation. Adding a deleted_at timestamp column to both tables ensures consistency without breaking the relational link.
📈 Scaling Considerations
As data volume grows, one-to-many relationships can become bottlenecks. Proper indexing and partitioning are necessary.
🖥️ Indexing Strategy
Always index the foreign key column. Without an index, joining the tables requires a full table scan, which is slow.
- Clustered Index: The primary key is usually clustered.
- Non-Clustered Index: The foreign key should have a dedicated index.
🖥️ Partitioning
If the many side table grows into billions of rows, partitioning by the foreign key can improve query speed. This keeps related data physically close on the storage medium.
📝 Summary of Key Takeaways
Data modeling requires precision. The one-to-many relationship is a fundamental building block, but it is not without complexity. By understanding the distinction between identifying and non-identifying relationships, managing performance costs, and adhering to normalization principles, architects can build systems that are both flexible and reliable.
- Foreign keys on the many side should be non-unique.
- Referential integrity adds overhead but ensures data quality.
- Soft deletes require careful handling of relationship links.
- Consistent naming and indexing are crucial for maintenance.
Ignoring these nuances leads to fragile systems. Embracing the technical realities ensures longevity. As you design your next schema, revisit these assumptions. Verify the cardinality. Check the constraints. Build with confidence.
🤔 Frequently Asked Questions
Q: Can a one-to-many relationship be bidirectional?
A: In a physical database, relationships are directional (Parent to Child). However, in application logic, you can traverse the relationship in both directions. The database engine enforces the link from the child back to the parent.
Q: Does a one-to-many relationship require a unique constraint?
A: No. The foreign key column must allow duplicate values to support the many side of the relationship. The primary key on the parent side is what must be unique.
Q: How do I handle circular dependencies?
A: Circular dependencies occur when Entity A relates to B, and B relates back to A. This is common in hierarchical data. Use self-referencing foreign keys or ensure the design does not create infinite loops in queries.
Q: Is a one-to-many relationship efficient for reporting?
A: It is efficient for normalized storage. However, reporting often requires denormalization. Aggregating data from the child table into the parent table for reporting dashboards can reduce query complexity.
Q: What happens if I delete a parent without handling children?
A: Depending on the constraint, the system will either block the deletion (Restrict) or delete the children automatically (Cascade). If no constraint exists, you may create orphaned records that break application logic.