










Diagramy relacji encji (ERD) pełnią rolę podstawowego projektu architektury bazy danych. Przekształcają abstrakcyjną logikę biznesową w strukturalne modele danych, które mogą być przetwarzane przez systemy. W tym kontekście relacja jeden do wielu stanowi najpowszechniejszy wzorzec strukturalny. Jednak powszechnie rozprzestrzenione błędy myślowe dotyczą jej implementacji, liczby relacji oraz skutków na wydajność. Zrozumienie subtelności tych połączeń jest kluczowe do tworzenia solidnych, skalowalnych modeli danych.
Wiele praktyków podejmuje modelowanie danych z z góry uformowanymi przekonaniami pochodzącymi z uproszczonych poradników lub przestarzałych praktyk. Te założenia często prowadzą do nieefektywności, problemów z integralnością danych lub trudnych cyklów utrzymania później w cyklu życia projektu. Niniejszy przewodnik analizuje powszechne mitologię dotyczące relacji jeden do wielu. Przeglądamy rzeczywistości techniczne liczby relacji, kluczy obcych oraz normalizacji, nie opierając się na konkretnych dostawcach oprogramowania.
🧐 Zrozumienie podstawowego pojęcia
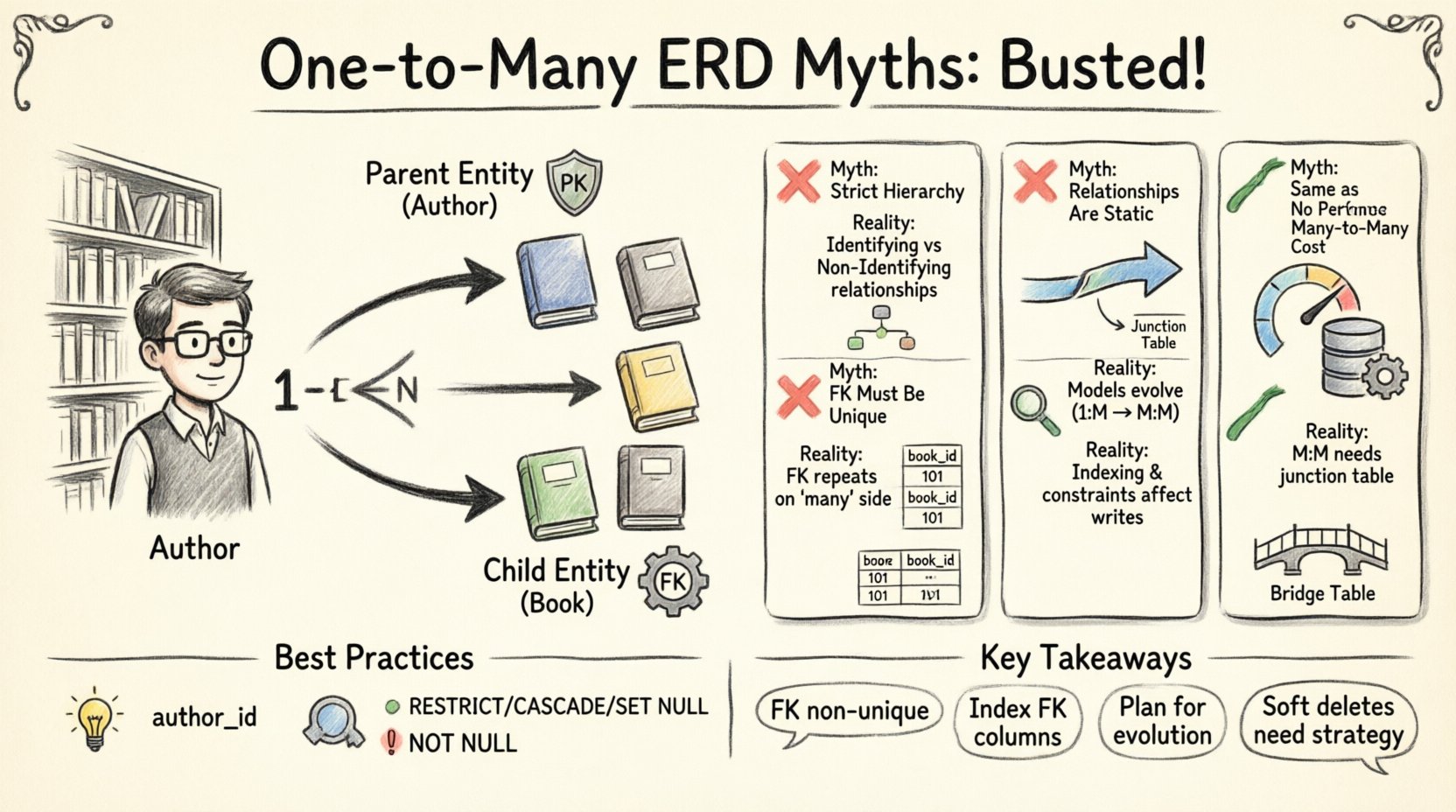
Zanim zajmiemy się błędami myślowymi, konieczne jest ustalenie jasnej definicji. W modelowaniu danych relacja opisuje sposób, w jaki wystąpienia jednej encji są powiązane z wystąpieniami innej encji. Relacjajeden do wieluoznacza, że pojedynczy rekord w pierwszej encji może być powiązany z wieloma rekordami w drugiej encji.
Rozważmy system biblioteczny. Jedna encjaAutoramoże być powiązana z wieloma encjamiKsiążkaEncje. Z kolei konkretnaKsiążkajest zazwyczaj napisana przez konkretnegoAutora (w uproszczonym modelu). To klasyczna relacja jeden do wielu. Encja po stroniejedennazywa się często rodzicem, podczas gdy encja po stroniewielenazywa się dzieckiem.
- Encja rodzicielska: Encja przechowująca unikalny klucz (klucz podstawowy).
- Encja potomna: Encja przechowująca odniesienie do rodzica (klucz obcy).
- Liczba relacji: Granica liczbową relacji (np. 1 do N).
Notacja wizualna różni się w zależności od standardów, takich jak Chen, Crow’s Foot lub UML. Niezależnie od użytego symbolu, podstawowa logika matematyczna pozostaje niezmienna. Integralność tej relacji decyduje o tym, jak dane są przechowywane, pobierane i chronione.
❌ Mity 1: Relacja jeden do wielu zawsze oznacza ściśle hierarchiczny układ
Powszechnym założeniem jest, że relacje jeden do wielu ściśle wyznaczają hierarchię rodzic-dziecko, w której rodzic kontroluje istnienie dziecka. Choć jest to prawdziwe w niektórych konkretnych zasadach biznesowych, nie jest to uniwersalne prawo projektowania baz danych.
🔍 Prawda o zależności istnienia
Nie wszystkie rekordy potomne zależą od rodzica w celu swojego istnienia. W terminologii baz danych nazywa się to zależność istnienia. Jeśli rekord potomny może istnieć bez rodzica, relacja jest nieidentyfikująca. Jeśli rekord potomny nie może istnieć bez rodzica, to jest identyfikująca.
- Nieidentyfikująca: A Klient może istnieć bez Zamówienia. Tabela Klienta istnieje samodzielnie. Tabela Zamówienia odwołuje się do Klienta.
- Identyfikująca: A Pozycja zamówienia nie może istnieć bez Zamówienia. Tabela Pozycji zamówienia może współdzielić identyfikator Zamówienia jako część klucza podstawowego.
Zakładanie ściślej hierarchicznej struktury tam, gdzie jej nie ma, może prowadzić do niepotrzebnych ograniczeń. Na przykład wymuszanie CASCADE DELETEna relacji niezależnej może niechcący usunąć poprawne dane. Zawsze sprawdzaj zasadę biznesową przed stosowaniem ściślego ograniczenia integralności referencyjnej.
❌ Mity 2: Klucze obce muszą być unikalne
Pomyłki często pojawiają się w kwestii ograniczenia unikalności kolumny klucza obcego. Klucz obcy w relacji jeden do wielu został specjalnie zaprojektowany tak, aby był nieunikalnypo stronie wielu.
🔍 Prawda o ograniczeniach liczności
Klucz podstawowy tabeli rodzica jest unikalny. Klucz obcy w tabeli potomnej odwołuje się do tego klucza podstawowego. Ponieważ jeden rodzic łączy się z wieloma dziećmi, wartość klucza obcego musi się powtarzać. Jeśli klucz obcy byłby unikalny, relacja stałaby się jedno do jednego.
| Aspekt | Jeden do jednego | Jeden do wielu |
|---|---|---|
| Unikalność klucza obcego | Unikalny | Nieunikalny |
| Strategia indeksowania | Często unikalny indeks | Standardowy indeks |
| Zmieszanie danych | Niski | Wyższy (zgodnie z projektem) |
Zapewnienie, że klucz obcy nie jest unikalny, jest kluczowe. Jeśli system wymusza unikalność po stronie dziecka, ogranicza model do jednego połączenia, co niszczy zaplanowaną strukturę danych. Jest to powszechny błąd konfiguracji w narzędziach automatycznego modelowania.
❌ Mity 3: Relacje są stałe
Wielu projektantów zakłada, że po zdefiniowaniu relacji jeden do wielu na schemacie, pozostaje ona niezmieniona. Modele danych jednak muszą ewoluować wraz z działalnością biznesową. Założenia o statycznych relacjach ignorują dynamiczny charakter danych.
🔍 Prawda o ewolucji modelu
Wymagania biznesowe się zmieniają. Produkt może początkowo należeć do jednej kategorii, ale później firma rozszerza się, aby umożliwić wiele kategorii na produkt. To zmienia model z jedno-do-wielu na wiele-do-wielu.
- Ryzyko refaktoryzacji:Zmiana typu relacji często wymaga skryptów migracji danych.
- Zgodność wsteczna:Stare raporty mogą polegać na pierwotnej strukturze.
- Wersjonowanie:Zachowanie historii zmian schematu jest kluczowe dla długoterminowej stabilności.
Projektanci powinni przewidywać przyszły wzrost. Choć obecnie relacja jeden do wielu jest standardem, schemat powinien zapewniać elastyczność. Używanie kluczy zastępczych (ID z automatycznym inkrementowaniem) zamiast kluczy naturalnych (np. adresów e-mail) jako kluczy obcych często ułatwia te przejścia.
❌ Mity 4: Klucze obce nie mają kosztu wydajności
Istnieje przekonanie, że dodawanie ograniczeń klucza obcego ma wyłącznie charakter logiczny i ma zaniedbywalny wpływ na wydajność. W rzeczywistości każde ograniczenie wymaga od silnika bazy danych przeprowadzenia sprawdzeń podczas operacji zapisu.
🔍 Prawda o wydajności operacji zapisu
Podczas wstawiania rekordu do tabeli potomnej baza danych musi zweryfikować istnienie odwoływanego rekordu nadrzędnego. Obejmuje to operację wyszukiwania. W systemach o wysokim przepływie danych ta operacja dodaje opóźnienie.
- Nadmiar indeksów:Kolumny klucza obcego powinny być indeksowane, aby przyspieszyć proces weryfikacji.
- Blokowanie:Sprawdzanie integralności referencyjnej może wymagać blokowania tabeli nadrzędnej.
- Operacje przepływowe: Jeśli
USUWANIE PRZEPUSTOWEjest włączone, usunięcie rodzica wywołuje wiele usunięć dzieci, co może być intensywne pod względem zasobów.
W przypadku scenariuszy dużego wchłaniania danych niektórzy architekci tymczasowo wyłączają ograniczenia kluczy obcych, aby poprawić przepustowość. Jednak może to prowadzić do uszkodzenia danych. Zależność między integralnością a szybkością musi być rozważona w kontekście konkretnego przypadku użycia.
❌ Mity 5: Jedno do wielu to to samo co wiele do wielu
Praktycy czasem mylą wizualne przedstawienie jedno do wielu z wielu do wielu. Choć wyglądają podobnie na diagramach najwyższego poziomu, ich implementacja znacznie się różni.
🔍 Prawda o tabelach pośrednich
Prawdziwa relacja wiele do wielu wymaga tabeli pośredniej, często nazywanej tabelą połączeniową lub mostową. Relacja jedno do wielu jej nie wymaga.
- Jedno do wielu: Bezpośrednie połączenie poprzez klucz obcy w tabeli potomnej.
- Wiele do wielu: Wymaga nowej tabeli zawierającej klucze obce do obu encji.
Próba zaimplementowania logiki wiele do wielu przy użyciu pojedynczej kolumny klucza obcego spowoduje duplikację lub utratę danych. Na przykład, jeśli spróbujesz połączyć Studenta z wieloma Kursami, używając tylko id_kursu w tabeli Studenta, student może zapisywać się tylko na jeden kurs. Aby umożliwić wiele zapisów, potrzebujesz tabeli Zapis tabeli.
🛠️ Najlepsze praktyki implementacji
Przestrzeganie najlepszych praktyk zapewnia, że relacje jedno do wielu pozostają stabilne. Te wytyczne skupiają się na strukturze, nazewnictwie i integralności.
📝 Zasady nazewnictwa
Spójne nazewnictwo zmniejsza niepewność. Klucze obce powinny jasno wskazywać relację. Kolumna o nazwie id_autora jest bardziej jasna niż id_autora.
- Standardowy format:
tabela_rodzica_mnoga_id. - Spójność: Zastosuj ten wzorzec we wszystkich encjach.
- Wrażliwość na wielkość liter: Używaj tylko małych lub dużych liter, aby uniknąć problemów z wielkością liter w różnych systemach operacyjnych.
🔒 Integralność referencyjna
Wzmacnianie integralności zapobiega powstawaniu zaniedbanych rekordów. Zaniedbany rekord to wpis potomny wskazujący na rodzica, który już nie istnieje.
- PO USUNIĘCIU ZABRONIONE: Zapobiega usunięciu rodzica, jeśli istnieją jego potomkowie.
- PO USUNIĘCIU KASKADOWE: Usuwa potomków, gdy rodzic jest usunięty.
- PO USUNIĘCIU USTAW NA NULL: Wyczyści klucz obcy, jeśli rodzic zostanie usunięty.
Wybór odpowiedniej akcji zależy od krytyczności danych. W przypadku transakcji finansowych ZABRONIONE jest zwykle bezpieczniejsze. W przypadku tymczasowych dzienników KASKADOWE może być akceptowalne.
⚙️ Normalizacja i relacja jeden do wielu
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości. Relacje jeden do wielu to podstawowy mechanizm stosowany do osiągnięcia normalizacji.
📊 Druga postać normalna (2NF)
2NF wymaga, aby wszystkie atrybuty niekluczowe były całkowicie zależne od klucza głównego. Relacje jeden do wielu pomagają izolować powtarzające się grupy. Jeśli tabela zawiera listę elementów, przeniesienie tej listy do osobnej tabeli tworzy relację jeden do wielu.
- Przed: Jedna linia zawiera wiele nazw produktów.
- Po: Nazwa produktu przenosi się do nowej tabeli powiązanej identyfikatorem produktu.
Ta separacja zapewnia, że aktualizacja nazwy produktu wymaga zmiany tylko jednego wiersza, a nie wielu wierszy, w których nazwa się powtarza.
📊 Trzecia postać normalna (3NF)
3NF eliminuje zależności przechodnie. Relacje jeden do wielu pomagają zapewnić, że atrybuty niekluczowe zależą wyłącznie od klucza głównego, a nie od innych atrybutów niekluczowych.
Na przykład, jeśli tabela przechowuje EmployeeID, ID_Działu, i Nazwa_Działu, występuje zależność przechodnia (Pracownik -> Dział -> Nazwa_Działu). Podział tego na tabelę Pracownik i tabelę Dział tworzy relację jeden do wielu, która rozwiązuje zależność.
🚧 Najczęstsze pułapki do uniknięcia
Unikanie błędów w fazie projektowania oszczędza znaczną ilość czasu podczas rozwoju. Poniżej znajdują się najczęściej spotykane pułapki.
- Zbyt duża normalizacja: Tworzenie zbyt wielu tabel może skomplikować zapytania. Zrównowaguj normalizację z wydajnością zapytań.
- Brak kluczy obcych: Opieranie się na logice aplikacji w celu zapewnienia relacji jest ryzykowne. Ograniczenia bazy danych są prawdą absolutną.
- Niepoprawna nullowalność: Klucze obce zwykle powinny być
NOT NULLchyba że relacja jest opcjonalna. Klucz obcy równyNULLoznacza brak relacji, co może naruszać zasady biznesowe. - Niezgodność typów danych: Upewnij się, że typ danych klucza obcego dokładnie odpowiada typowi klucza podstawowego. Używanie
VARCHARz jednej strony iINTz drugiej strony spowoduje zerwanie połączenia.
📉 Wizualne przedstawienie w ERD
Jasność na diagramie jest równie ważna jak logika stojąca za nim. Notacja wizualna przekazuje strukturę osobom zewnętrznych, które nie piszą kodu.
👣 Notacja kłykciowa (Crow’s Foot)
To najbardziej powszechny standard. jeden strona ma pojedynczą pionową linię. wiele strona ma łapę kruka (trzy rozgałęziające się linie).
- Koło: Wskazuje na relację opcjonalną (0..N).
- Linia: Wskazuje na relację wymaganą (1..N).
Notacja Chen
Używa kształtów rombu do oznaczania relacji. Choć jest mniej powszechna w nowoczesnych narzędziach, zapewnia jasne koncepcyjne widzenie encji i ich połączeń.
🔄 Obsługa miękkich usuwań
W wielu systemach dane nigdy nie są naprawdę usuwane. Zamiast tego oznaczane są jako nieaktywne. Nazywa się to miękkim usunięciem.
🔍 Wpływ na relacje
Miękkie usuwanie komplikuje relacje jeden do wielu. Jeśli rodzic jest miękko usunięty, czy dzieci powinny pozostać połączone?
- Opcja 1: Przekaż flagę miękkiego usunięcia do wszystkich dzieci.
- Opcja 2: Zachowaj dzieci aktywnymi, ale ukryj je z zapytań.
- Opcja 3: Wymaga osobnej logiki do obsługi połączenia.
Dizajnerzy muszą to zdecydować podczas tworzenia schematu. Dodanie kolumny deleted_at z timestampem do obu tabel zapewnia spójność bez naruszania relacyjnego połączenia.
📈 Rozważania dotyczące skalowania
Wraz ze wzrostem objętości danych relacje jeden do wielu mogą stać się węzłami zawieszenia. Wymagane są odpowiednie indeksowanie i partycjonowanie.
🖥️ Strategia indeksowania
Zawsze indeksuj kolumnę klucza obcego. Bez indeksu łączenie tabel wymaga pełnego skanowania tabeli, co jest powolne.
- Indeks zgrupowany:Klucz główny zwykle jest zgrupowany.
- Indeks niezgrupowany: Klucz obcy powinien mieć dedykowany indeks.
🖥️ Partycjonowanie
Jeśli tabela z wieluJeśli tabela strony ‘wiele’ wzrośnie do miliardów wierszy, partycjonowanie według klucza obcego może poprawić szybkość zapytań. Dzięki temu powiązane dane będą fizycznie blisko siebie na nośniku danych.
📝 Podsumowanie najważniejszych wniosków
Modelowanie danych wymaga precyzji. Relacja jeden do wielu jest podstawowym elementem, ale nie jest pozbawiona złożoności. Zrozumienie różnicy między relacjami identyfikującymi a nieidentyfikującymi, zarządzanie kosztami wydajności oraz przestrzeganie zasad normalizacji pozwala architektom tworzyć systemy zarówno elastyczne, jak i niezawodne.
- Klucze obce na stronie wielupowinny być nieunikalne.
- Integralność referencyjna dodaje narzut, ale zapewnia jakość danych.
- Miękkie usuwanie wymaga starannego obsługi linków relacyjnych.
- Spójne nazewnictwo i indeksowanie są kluczowe dla utrzymania systemu.
Ignorowanie tych subtelności prowadzi do niestabilnych systemów. Przyjęcie rzeczywistości technicznej zapewnia długowieczność. Podczas projektowania kolejnej schematu ponownie przeanalizuj te założenia. Zweryfikuj liczność. Sprawdź ograniczenia. Projektuj z pewnością siebie.
🤔 Najczęściej zadawane pytania
Q: Czy relacja jeden do wielu może być dwukierunkowa?
A: W fizycznej bazie danych relacje są kierunkowe (Rodzic do Dziecka). Jednak w logice aplikacji możesz poruszać się w obu kierunkach. Silnik bazy danych zapewnia połączenie od dziecka do rodzica.
Q: Czy relacja jeden do wielu wymaga ograniczenia unikalności?
A: Nie. Kolumna klucza obcego musi umożliwiać powtarzające się wartości, aby wspierać stronę wielurelacji. Unikalna musi być klucz podstawowy po stronie rodzica.
Q: Jak obsłużyć zależności cykliczne?
A: Zależności cykliczne występują, gdy encja A ma relację z B, a B z kolei ma relację z A. Jest to powszechne w danych hierarchicznych. Użyj kluczy obcych odnoszących się do samej siebie lub upewnij się, że projekt nie tworzy nieskończonych pętli w zapytaniach.
Q: Czy relacja jeden do wielu jest wydajna w przypadku raportowania?
A: Jest wydajna w przypadku znormalizowanego przechowywania danych. Jednak raportowanie często wymaga denormalizacji. Agregowanie danych z tabeli potomnej do tabeli rodzicielskiej w celu tworzenia pulpitu raportowego może zmniejszyć złożoność zapytań.
Q: Co się stanie, jeśli usunę rodzica bez obsługi dzieci?
A: W zależności od ograniczenia system albo zablokuje usunięcie (Restrict), albo automatycznie usunie dzieci (Cascade). Jeśli nie ma ograniczenia, możesz stworzyć porzucone rekordy, które naruszą logikę aplikacji.