











Diagramy relacji encji (ERD) stanowią fundament solidnej architektury danych. Stanowią wizualny szkic, jak informacje są strukturalnie ułożone, przechowywane i dostępne w systemie baz danych. Mimo ich kluczowego znaczenia, obszar projektowania ERD często jest zakłócony narracjami marketingowymi. Dostawcy i konsultanci często przedstawiają narzędzia do tworzenia diagramów jako złote środki, które natychmiast rozwiązują skomplikowane problemy modelowania danych. Ten podejście ignoruje rygorystyczne zasady logiczne potrzebne do budowy trwałości środowiska danych.
Aby budować systemy, które przetrwają, musimy spojrzeć poza szum. Musimy zrozumieć rzeczywistości techniczne relacji, ograniczeń i normalizacji. Ten przewodnik analizuje powszechne błędy dotyczące ERD. Przeanalizujemy różnicę między modelem teoretycznym a implementacją fizyczną. Celem nie jest promowanie konkretnego narzędzia lub metodyki, ale wyjaśnienie zasad, które decydują o integralności danych.
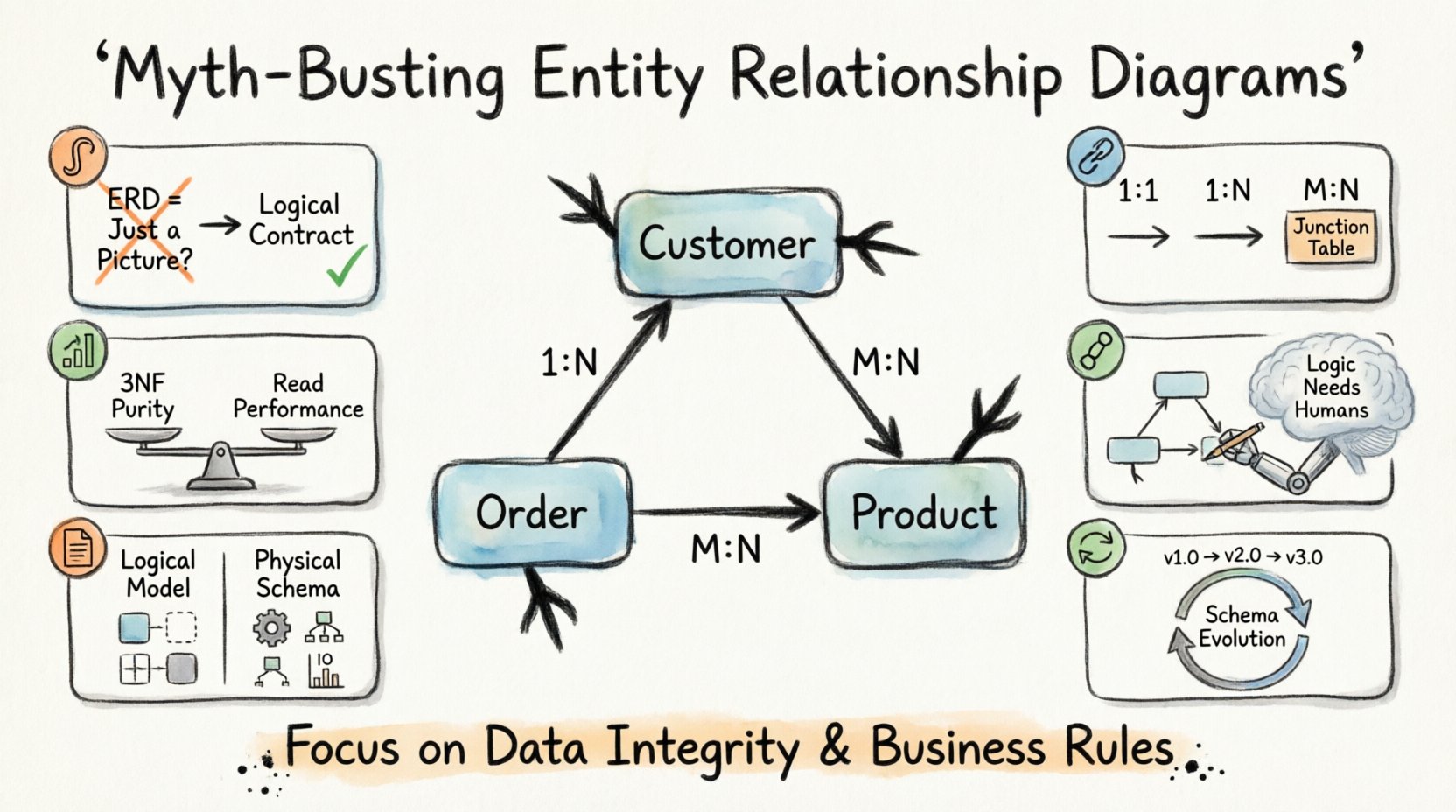
1. Pułapka wizualna: Czy ERD to po prostu diagram? 🎨
Jednym z najpowszechniejszych mitów jest sugerowanie, że diagram relacji encji to jedynie dokumentacja. Wiele zespołów traktuje diagram jako produkt końcowy projektu, coś stworzonego po napisaniu kodu, aby zadowolić stakeholderów. To podejście jest fundamentalnie błędne. Diagram ERD to kontrakt logiczny, a nie obraz.
Gdy diagram ERD traktowany jest jako postrzegany efekt wizualny, pojawiają się różne ryzyka:
- Odchylenie schematu: Struktura bazy danych odbiega od zaplanowanego projektu, co prowadzi do niezgodnego wprowadzania danych.
- Zatyczki wydajności: Zapytania kończą się niepowodzeniem, ponieważ podstawowa struktura nie wspiera efektywnie wymaganych połączeń.
- Utrata integralności danych: Ograniczenia kluczy obcych są ignorowane, co pozwala istnieć zaniedbanym rekordom.
Zastanów się nad cyklem życia tabeli bazy danych. Zaczyna się od wymogu biznesowego. Przechodzi do modelu logicznego. Następnie staje się schematem fizycznym. Diagram ERD łączy lukę między logiką biznesową a technicznym przechowywaniem danych. Jeśli diagram nie jest źródłem prawdy, baza danych nieuchronnie będzie cierpiała na niejasność.
Skuteczne modelowanie danych wymaga dokładnej uwagi na szczegóły. Nie chodzi o rysowanie prostokątów i linii. Chodzi o definiowanie zasad współpracy danych. Każda linia w diagramie ERD reprezentuje ograniczenie. Każdy prostokąt reprezentuje jednostkę danych, która musi zostać zachowana. Ignorowanie tej rzeczywistości prowadzi do systemów niewytrzymałości i trudnych do utrzymania.
2. Mocność i relacje: Poza podstawami 🔗
Mocność definiuje liczbową relację między encjami. Odpowiada na pytanie: Ile wystąpień jednej encji relacjonuje się z wystąpieniami innej encji? Materiały marketingowe często upraszczają to na relacje jeden do wielu lub wiele do wielu, nie wyjaśniając skutków.
Zrozumienie mocności jest kluczowe dla wydajności zapytań i spójności danych. Istnieją trzy podstawowe typy relacji:
- Jeden do jednego (1:1): Każdy rekord w Tabeli A relacjonuje się dokładnie z jednym rekordem w Tabeli B. Jest to często stosowane w celach bezpieczeństwa lub rozdzielenia danych.
- Jeden do wielu (1:N): Jeden rekord w Tabeli A relacjonuje się z wieloma rekordami w Tabeli B. Jest to najpowszechniejsza relacja w systemach transakcyjnych.
- Wiele do wielu (M:N): Wiele rekordów w Tabeli A relacjonuje się z wieloma rekordami w Tabeli B. Wymaga to fizycznej rozwiązań za pomocą tabeli pośredniej.
Powszechnym błędem jest przekonanie, że relacje jeden do jednego są zawsze lepsze dla rozdzielenia danych. Choć zapewniają izolację, mogą wprowadzać niepotrzebną złożoność. Podział danych na dwie tabele, gdy jedna wystarczy, zwiększa koszt połączeń. Może to pogorszyć wydajność podczas operacji odczytu.
Z drugiej strony, ignorowanie relacji wiele do wielu może prowadzić do powielania danych. Jeśli spróbujesz przechowywać listę wartości w jednym kolumnie bez odpowiedniej tabeli pośredniej, naruszasz zasady normalizacji. To znacznie utrudnia aktualizację i zapytania do danych.
| Typ relacji | Realizacja fizyczna | Powszechna pułapka |
|---|---|---|
| Jeden do jednego | Klucz obcy w dowolnej tabeli | Zbyt szczegółowa segmentacja danych |
| Jeden do wielu | Klucz obcy w tabeli „Wiele” | Błędy cyklicznych referencji |
| Wiele do wielu | Tabela pośrednicząca z dwoma kluczami obcymi | Brak unikalnych ograniczeń w tabeli pośredniczącej |
Podczas projektowania tych relacji musisz brać pod uwagę zasady biznesowe. Czy klient ma jedno adres czy wiele? Czy produkt należy do jednej kategorii czy wielu? Diagram musi odzwierciedlać rzeczywistość operacyjną, a nie uidealizowaną wersję jej.
3. Normalizacja: Mity 3NF 📊
Normalizacja to technika używana do organizowania danych w celu zmniejszenia nadmiarowości. Trzecia postać normalna (3NF) często uznawana jest za złoty standard. Mito sugeruje, że każda baza danych musi być w pełni znormalizowana do 3NF, aby była uznawana za poprawną. To nie zawsze prawda.
Normalizacja eliminuje anomalie. Są to problemy występujące podczas wstawiania, aktualizacji lub usuwania danych. Na przykład, jeśli przechowujesz imię klienta w każdym rekordzie zamówienia, zmiana imienia wymaga aktualizacji tysięcy wierszy. Jest to anomalia aktualizacji. Normalizacja rozwiązuje to, przenosząc imię do osobnej tabeli klientów.
Jednak ścisłe przestrzeganie 3NF może negatywnie wpływać na wydajność. Każda relacja wymaga połączenia (join). Połączenia są obliczeniowo kosztowne. W systemach raportujących o wysokim obciążeniu nadmierna normalizacja może spowolnić wykonywanie zapytań. To właśnie tutaj pojawia się denormalizacja.
Denormalizacja to celowe wprowadzanie nadmiarowości w celu poprawy wydajności odczytu. Jest to kompromis. Ofiarowujesz szybkość zapisu i efektywność pamięci na rzecz szybszego odczytu. Decyzja ta nigdy nie powinna być podejmowana lekceważąco. Wymaga głębokiego zrozumienia wzorców dostępu.
Kluczowe kwestie dotyczące normalizacji to:
- Równowaga odczytów i zapisów:Czy system jest ciężki w odczytach czy w zapisach?
- Złożoność zapytań:Jak skomplikowane są wymagane raporty?
- Koszty przechowywania:Czy nadmiarowość jest opłacalna?
Ślepe przestrzeganie 3NF bez analizy obciążenia to recepta na powolną aplikację. Celem jest zrównoważenie integralności danych z wymaganiami wydajności. Czasem starannie denormalizowany widok jest lepszym rozwiązaniem niż idealnie znormalizowana struktura.
4. Zależność od narzędzi: Automatyzacja wobec logiki 🤖
Nowoczesne narzędzia oferują funkcje takie jak generowanie schematu automatyczne i inżynieria wsteczna. Producenty reklamują te możliwości jako oszczędzające czas. Mito polega na tym, że narzędzie może zastąpić projektanta. Narzędzie do tworzenia diagramów może rysować linie, ale nie rozumie kontekstu biznesowego.
Automatyczne generowanie często tworzy schematy technicznie poprawne, ale logicznie błędne. Może tworzyć tabele na podstawie analizy kodu zamiast wymagań biznesowych. Może pominąć ukryte relacje, które nie są jawnie zakodowane.
Kontrola ludzka jest niezbędna. Modeler danych musi zweryfikować wynik wobec rzeczywistych potrzeb organizacji. Kluczowe zadania, które nie mogą być automatyzowane, to:
- Definiowanie reguł biznesowych:Określanie, które atrybuty są wymagane.
- Obsługa przypadków brzegowych:Decydowanie, jak obsługiwać wartości null lub miękkie usuwanie.
- Optymalizacja pod kątem przyszłego rozwoju: Przewidywanie, jak dane będą się rozszerzać.
Narzędzia są pomocą, a nie architektami. Ułatwiają tworzenie schematu, ale logika znajduje się w umyśle człowieka. Zależność wyłącznie od automatyzacji prowadzi do systemów sztywnych i trudnych do dostosowania. Narzędzie powinno wspierać przepływ pracy, a nie go dyktować.
5. Przepaść między projektowaniem a wdrożeniem fizycznym 📝
Istnieje istotna różnica między modelem logicznym a modelem fizycznym. Model logiczny opisuje encje i relacje koncepcyjnie. Model fizyczny definiuje typy danych, indeksy i ograniczenia.
Wiele zespołów zakłada, że model logiczny bezpośrednio przekłada się na bazę danych fizyczną. Zazwyczaj nie jest to prawdą. Różne systemy baz danych mają różne możliwości. Relacja, która działa dobrze w jednym systemie, może źle działać w innym.
Na przykład typy danych się różnią. Pole zdefiniowane jako „Tekst” w modelu logicznym może wymagać postaci „VARCHAR(255)” lub „TEXT” w bazie danych fizycznej. Strategie indeksowania również się różnią. Indeks, który przyspiesza zapytania w jednym systemie, może spowolnić zapisy w innym.
Przy przechodzeniu od projektowania do wdrożenia należy dostosować się do konkretnej technologii. Rozważ następujące dostosowania:
- Typy danych: Upewnij się, że wybrane typy danych odpowiadają silnikowi przechowywania.
- Indeksy: Dodaj indeksy dla często zapytywanych kolumn.
- Partycjonowanie: Rozważ podział dużych tabel dla lepszej obsługi.
- Ograniczenia: Zdecyduj między sprawdzaniem na poziomie aplikacji a ograniczeniami na poziomie bazy danych.
Ignorowanie tych różnic prowadzi do rozłączenia między projektem a rzeczywistością. System może działać, ale nie będzie zoptymalizowany. Konieczna jest szczegółowa analiza wdrożenia fizycznego, aby upewnić się, że projekt wytrzyma obciążenie.
6. Konserwacja i ewolucja 🔄
Innym ważnym mitem jest to, że projekt bazy danych jest statyczny. Po zatwierdzeniu ERD jest on niezmienny. W rzeczywistości wymagania biznesowe się zmieniają. Dodawane są nowe funkcje. Zmieniają się przepisy. Model danych musi się rozwijać razem z nimi.
Refaktoryzacja bazy danych jest trudna. Zmiana typu kolumny lub relacji może uszkodzić istniejące aplikacje. Dlatego projekt musi być wystarczająco elastyczny, aby dopasować się do zmian bez konieczności pełnego ponownego budowania. Strategie utrzymywalności obejmują:
- Wersjonowanie: Śledź zmiany schematu w czasie.
- Skrypty migracji: Automatyzuj wdrażanie zmian.
- Dokumentacja: Zachowaj schemat aktualny równolegle z kodem.
Dokumentacja często jest pomijana, aż jest już za późno. Gdy programista opuszcza projekt, wiedza o strukturze danych ginie. Aktualny ERD stanowi podstawowy punkt odniesienia dla nowych członków zespołu. Zmniejsza ona krzywą nauki i zapobiega błędom.
Ewolucja wymaga dyscypliny. Każda zmiana musi być oceniona pod kątem wpływu na istniejące dane. W miarę możliwości należy zachować zgodność wsteczną. Zapewnia to, że aplikacje oparte na bazie danych nie ulegną niespodziewanemu awarii.
7. Podsumowanie najczęstszych mitów wobec rzeczywistości
Aby podsumować najważniejsze punkty, możemy sklasyfikować najczęściej występujące błędy. Ta tabela stanowi szybką orientację do rozróżniania między twierdzeniami marketingowymi a faktami technicznymi.
| Mity | Rzeczywistość |
|---|---|
| Diagramy ER to tylko ładne obrazki | Diagramy ER to techniczne umowy definiujące zasady danych |
| Więcej tabel oznacza lepszy projekt | Złożoność zmniejsza wydajność; kluczowe jest zrównoważenie |
| Normalizacja to zawsze cel | Denormalizacja poprawia szybkość odczytu w konkretnych przypadkach |
| Narzędzia mogą automatyzować projektowanie | Narzędzia pomagają, ale logika wymaga nadzoru człowieka |
| Modele logiczne równają się schematom fizycznym | Realizacja fizyczna wymaga określonych optymalizacji |
| Projekt jest stały | Schematy muszą ewoluować wraz z potrzebami biznesu |
Ostateczne rozważania nad modelowaniem danych 🧭
Tworzenie niezawodnego systemu baz danych wymaga jasnego zrozumienia podstawowych zasad. Diagramy relacji encji to potężne narzędzia, gdy są używane poprawnie. Stanowią wspólne języki między uczestnikami biznesowymi a zespołami technicznymi.
Jednak nie są one czarodziejstwem. Nie rozwiązują samodzielnie problemów danych. Wartość pochodzi z rygorystycznego stosowania logiki w fazie projektowania. Musimy odrzucić przekonanie, że narzędzia programistyczne mogą zastąpić myślenie krytyczne. Musimy również zaakceptować, że normalizacja nie jest rozwiązaniem uniwersalnym.
Sukces w projektowaniu baz danych zależy od przejrzystości, precyzji i elastyczności. Oddzielając hiperboli marketingowe od rzeczywistości technicznej, możesz tworzyć systemy wytrzymałe i skalowalne. Skup się na integralności danych i zasadach biznesowych. Niech diagram będzie przewodnikiem, a nie celem.
Gdy podejdziesz do modelowania danych z tymi zasadami w głowie, wyniki mówią same za siebie. System będzie łatwiejszy do utrzymania. Zapytania będą działać szybciej. Dane pozostaną dokładne. To jest prawdziwa wartość dobrze skonstruowanego diagramu relacji encji.