











エンティティ関係図(ERD)は、強固なデータアーキテクチャの基盤に位置します。情報がデータベースシステム内でどのように構造化され、保存され、アクセスされるかを視覚的に示す設計図です。その重要性にもかかわらず、ERD設計を取り巻く状況はしばしばマーケティングの物語によって曇っています。ベンダーおよびコンサルタントは、図示ツールを複雑なデータモデリングの課題を即座に解決する万能薬のように宣伝することがよくあります。しかし、このアプローチは持続可能なデータ環境を構築するために必要な厳密な論理を無視しています。
持続可能なシステムを構築するためには、騒ぎに惑わされず、関係性、制約、正規化の技術的現実を理解する必要があります。このガイドでは、ERDに関する一般的な誤解を解き明かします。理論モデルと物理的実装の違いを探ります。目的は特定のツールや手法を推奨することではなく、データ整合性を支配する原則を明確にすることです。
1. 視覚的罠:ERDは単なる図にすぎないのか? 🎨
最も広く広がっている誤解の一つは、エンティティ関係図が単なる文書化の成果物にすぎないというものである。多くのチームは、図をプロジェクト終了後に作成するものとして扱い、ステークホルダーを満足させるためのものと見なしている。この見方は根本的に誤りである。ERDは絵ではなく、論理的な契約である。
ERDを視覚的な後付けとして扱うと、いくつかのリスクが生じる:
- スキーマのずれ: データベース構造が意図された設計から逸脱し、データ入力の不整合を引き起こす。
- パフォーマンスのボトルネック: クエリが失敗する。なぜなら、基盤となる構造が必要な結合を効率的にサポートしていないからである。
- データ整合性の喪失: 外部キー制約が無視され、孤立したレコードが存在することを許容する。
データベーステーブルのライフサイクルを検討してみよう。それはビジネス要件から始まり、論理モデルへと移行し、その後物理スキーマとなる。ERDはビジネス論理と技術的保存の間の橋渡しを行う。図が真実の出所でなければ、データベースは必然的に曖昧さに悩まされることになる。
効果的なデータモデリングには細部への厳密な注意が不可欠である。箱と線を描くことではない。データの取り引きのルールを定義することである。ERDのすべての線は制約を表す。すべての箱は保持しなければならないデータの単位を表す。この現実を無視すると、脆弱で保守が難しいシステムが生まれる。
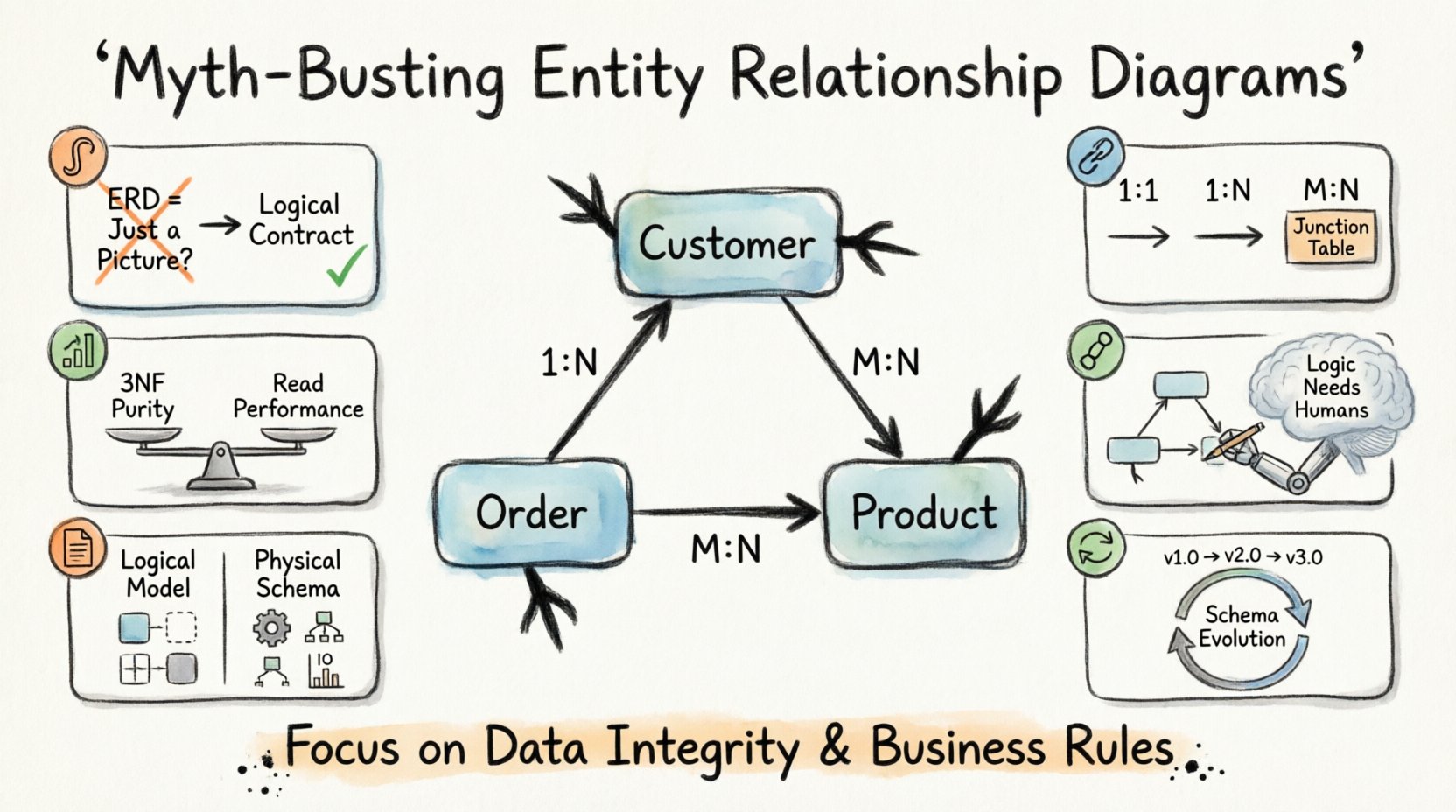
2. 極性と関係性:基礎を超えて 🔗
極性はエンティティ間の数的関係を定義する。問いはこうである:あるエンティティのインスタンスが、別のエンティティのインスタンスと何個関係を持つのか?マーケティング資料では、この関係をしばしば「1対多」や「多対多」に簡略化するが、その意味合いについては説明しない。
極性を理解することは、クエリのパフォーマンスとデータの一貫性にとって不可欠である。主な関係性は3種類ある:
- 1対1(1:1): テーブルAの各レコードは、テーブルBの正確に1つのレコードと関係する。これはしばしばセキュリティやデータの分離に使用される。
- 1対多(1:N): テーブルAの1つのレコードが、テーブルBの複数のレコードと関係する。これはトランザクションシステムで最も一般的な関係である。
- 多対多(M:N): テーブルAの複数のレコードが、テーブルBの複数のレコードと関係する。物理的に解決するには、中間テーブルが必要である。
一般的な誤解の一つは、1対1の関係がデータ分離において常に優れているというものである。確かに分離性は得られるが、不要な複雑さをもたらす可能性がある。単一のテーブルで十分なのに2つのテーブルに分割すると、結合のオーバーヘッドが増加する。これは読み取り操作時のパフォーマンスを低下させる可能性がある。
逆に、多対多の関係を無視するとデータの重複が生じる。適切な中間テーブルがなければ、単一のカラムに値のリストを格納しようとすると、正規化ルールに違反する。これにより、データの更新やクエリが著しく難しくなる。
| 関係性の種類 | 物理的実装 | 一般的な落とし穴 |
|---|---|---|
| 1対1 | いずれかのテーブルに外部キー | データの過剰なセグメンテーション |
| 1対多 | 「多」側のテーブルにおける外部キー | 循環参照エラー |
| 多対多 | 外部キーを2つ持つ結合テーブル | 結合テーブルにおける一意制約の欠如 |
これらの関係を設計する際には、ビジネスルールを考慮しなければなりません。顧客は1つの住所を持つのか、複数の住所を持つのか?製品は1つのカテゴリに属するのか、複数のカテゴリに属するのか?図は理想化されたものではなく、運用上の現実を反映しなければなりません。
3. 正規化:3NFの神話 📊
正規化は、データの重複を減らすためにデータを整理する技術です。第三正規形(3NF)はしばしばゴールドスタンダードとされています。この神話は、すべてのデータベースが3NFまで完全に正規化されていなければ有効とは見なされないという主張をしています。しかし、これは常に正しいわけではありません。
正規化は異常を解消します。異常とは、データの挿入、更新、削除の際に発生する問題です。たとえば、注文記録すべてに顧客名を保存している場合、名前を変更するには数千行の更新が必要になります。これは更新異常です。正規化は、名前を別々の顧客テーブルに移動させることでこれを解決します。
しかし、3NFへの厳格な従いはパフォーマンスを損なうことがあります。すべての関係には結合(join)が必要です。結合は計算コストが高くなります。高トラフィックのレポートシステムでは、過度な正規化はクエリ実行を遅くする可能性があります。これがデノーマライゼーションが役立つ場面です。
デノーマライゼーションは、読み取りパフォーマンスを向上させるために意図的に冗長性を導入するものです。これはトレードオフです。書き込み速度とストレージ効率を犠牲にして、より速い読み取りを実現します。この決定は決して軽率に行ってはいけません。アクセスパターンに対する深い理解が求められます。
正規化における重要な考慮事項には以下が含まれます:
- 読み取りと書き込みのバランス:システムは読み取り中心か、書き込み中心か?
- クエリの複雑さ:必要なレポートの複雑さはどの程度か?
- ストレージコスト:冗長性は許容できるか?
ワークロードを分析せずに3NFに盲目的に従うことは、遅いアプリケーションを生み出す原因になります。目標は、データの整合性とパフォーマンス要件のバランスを取ることです。場合によっては、完璧に正規化されたスキーマよりも、慎重にデノーマライズされたビューの方が適切な解決策となることがあります。
4. ツール依存:自動化と論理の対比 🤖
現代のツールは、自動スキーマ生成やリバースエンジニアリングなどの機能を提供しています。ベンダーはこれらの機能を時間の節約になると宣伝しています。ここでの神話は、ツールがデザイナーを置き換えることができるというものですが、図示ツールは線を引くことはできても、ビジネスの文脈を理解することはできません。
自動生成は、技術的には正しいが論理的に誤ったスキーマを生みがちです。コードの検査に基づいてテーブルを作成する可能性があり、ビジネス要件に基づくものではありません。明示的にコード化されていない隠れた関係を見逃す可能性もあります。
人的な監視は不可欠です。データモデラーは、出力結果が組織の実際のニーズに合致しているかを検証しなければなりません。自動化できない重要なタスクには以下が含まれます:
- ビジネスルールの定義:どの属性が必須かを決定すること。
- エッジケースの処理:null値やソフトデリートの処理方法を決定すること。
- 将来の成長に最適化すること: データの拡張がどのように進むかを予測すること。
ツールは支援役であり、設計者ではない。図の作成を支援するが、論理は人間の頭脳に存在する。自動化にのみ頼ると、硬直的で適応が難しいシステムになってしまう。ツールはワークフローを支援すべきであり、それを支配すべきではない。
5. 物理的実装のギャップ 📝
論理モデルと物理モデルの間には明確な違いがある。論理モデルはエンティティと関係を概念的に記述する。物理モデルはデータ型、インデックス、制約を定義する。
多くのチームは、論理モデルが物理データベースに直接対応すると仮定している。これはほとんど稀なケースである。異なるデータベースシステムにはそれぞれ異なる機能がある。あるシステムでうまく機能する関係が、別のシステムでは性能が劣る場合がある。
例えば、データ型は異なる。論理モデルで「Text」と定義されたフィールドは、物理データベースでは「VARCHAR(255)」または「TEXT」となる必要がある場合がある。インデックス戦略も異なる。あるシステムでクエリを高速化するインデックスは、別のシステムでは書き込みを遅くする可能性がある。
設計から実装へ移行する際には、特定のテクノロジー・スタックに合わせて調整する必要がある。以下の調整を検討するべきである:
- データ型: 選択したデータ型がストレージエンジンと一致していることを確認する。
- インデックス: 頻繁にクエリされるカラムに対してインデックスを追加する。
- パーティショニング: 大きなテーブルを分割して、より良い管理を検討する。
- 制約: アプリケーションレベルのチェックとデータベースレベルの制約のどちらを選ぶかを決定する。
これらの違いを無視すると、設計と現実とのギャップが生じる。システムは動作するかもしれないが、最適化されていない。設計が負荷に耐えうるかを確認するためには、物理的実装の徹底的なレビューが必要である。
6. メンテナンスと進化 🔄
もう一つの大きな誤解は、データベース設計は静的であるというものだ。ERDが承認されれば、それ以上変更されないという考えである。実際には、ビジネス要件は変化する。新しい機能が追加される。規制も進化する。データモデルはそれらに合わせて進化しなければならない。
データベースのリファクタリングは難しい。カラムの型や関係を変更すると、既存のアプリケーションが壊れる可能性がある。したがって、完全な再構築を必要とせずに変更に対応できるだけの柔軟性を持つ設計が必要である。保守性を高めるための戦略には以下のようなものがある:
- バージョン管理: 時間の経過とともにスキーマの変更を追跡する。
- マイグレーションスクリプト: 変更のデプロイを自動化する。
- ドキュメント: 図をコードと並行して最新の状態に保つ。
ドキュメントはしばしば後回しにされ、遅すぎると気づく。開発者がプロジェクトを離れるとき、データ構造に関する知識が失われる。最新のERDは、新規メンバーにとっての主要な参照資料となる。これにより学習コストが低下し、誤りを防ぐことができる。
進化には規律が必要である。すべての変更は、既存データへの影響を評価しなければならない。可能な限り後方互換性を維持すべきである。これにより、データベースに依存するアプリケーションが予期せぬ破綻を起こさないことが保証される。
7. 一般的な誤解と現実の要約
主なポイントを要約するために、最も頻繁に見られる誤解を分類できる。この表は、マーケティング上の主張と技術的事実の区別を素早く行うための参考となる。
| 誤解 | 現実 |
|---|---|
| ERDはただの美しい図にすぎない | ERDはデータルールを定義する技術的契約である |
| テーブルが多いほど良い設計になる | 複雑さはパフォーマンスを低下させる。バランスが鍵である |
| 正規化は常に目標である | 非正規化は特定の状況で読み取り速度を向上させる |
| ツールは設計を自動化できる | ツールは支援するが、論理的思考には人的監視が必要である |
| 論理モデルは物理スキーマに等しい | 物理的実装には特定の最適化が必要である |
| 設計は永続的である | スキーマはビジネスニーズに合わせて進化しなければならない |
データモデリングに関する最終的な考察 🧭
信頼性の高いデータベースシステムを構築するには、基盤となる原則を明確に理解することが必要である。正しく使用されたエンティティ関係図は強力なツールである。これらはビジネス関係者と技術チームの間で共有される言語を提供する。
しかし、それらは魔法ではない。独自にデータ問題を解決するわけではない。価値は設計段階での論理の厳密な適用から生まれる。ソフトウェアツールが批判的思考を代替できるという考えを拒否しなければならない。また、正規化が万能の解決策ではないことを受け入れなければならない。
データベース設計の成功は明確さ、正確さ、および柔軟性にかかっている。マーケティングの誇張を技術的現実から分離することで、堅牢でスケーラブルなシステムを構築できる。データの整合性とビジネスルールに注目する。図は目的地ではなく、ガイドとして機能させるべきである。
これらの原則を意識してデータモデリングに取り組むと、結果は自明である。システムは保守しやすくなる。クエリはより速く実行される。データは正確なまま保たれる。これが、適切に構築されたエンティティ関係図の真の価値である。