











Thiết kế một cấu trúc dữ liệu vững chắc là nền tảng của bất kỳ hệ thống thông tin đáng tin cậy nào. Ở trung tâm của thiết kế này là sơ đồ quan hệ thực thể (ERD), một bản phác họa trực quan xác định cách các thực thể dữ liệu tương tác với nhau. Tuy nhiên, một sơ đồ đơn thuần không đảm bảo hiệu quả. Sức mạnh thực sự của ERD chỉ thể hiện khi được kết hợp với các chiến lược chuẩn hóa nghiêm ngặt. Mục tiêu là rõ ràng: đạt được lưu trữ không dư thừa. Điều này có nghĩa là loại bỏ dữ liệu trùng lặp để đảm bảo tính toàn vẹn, giảm chi phí lưu trữ và đơn giản hóa bảo trì.
Dư thừa không chỉ là vấn đề lưu trữ; đó là một lỗi logic đang chờ gây ra sự bất nhất. Khi dữ liệu được lặp lại trên nhiều hàng hoặc bảng mà không có mối quan hệ chặt chẽ, các bất thường cập nhật trở nên không thể tránh khỏi. Một thay đổi trong thuộc tính duy nhất có thể yêu cầu cập nhật ở hàng chục vị trí. Nếu bỏ sót một nơi nào đó, cơ sở dữ liệu sẽ bị hỏng. Hướng dẫn này khám phá cơ chế chuẩn hóa trong bối cảnh thiết kế ERD, tập trung vào ứng dụng thực tiễn và sự thuần khiết về cấu trúc.
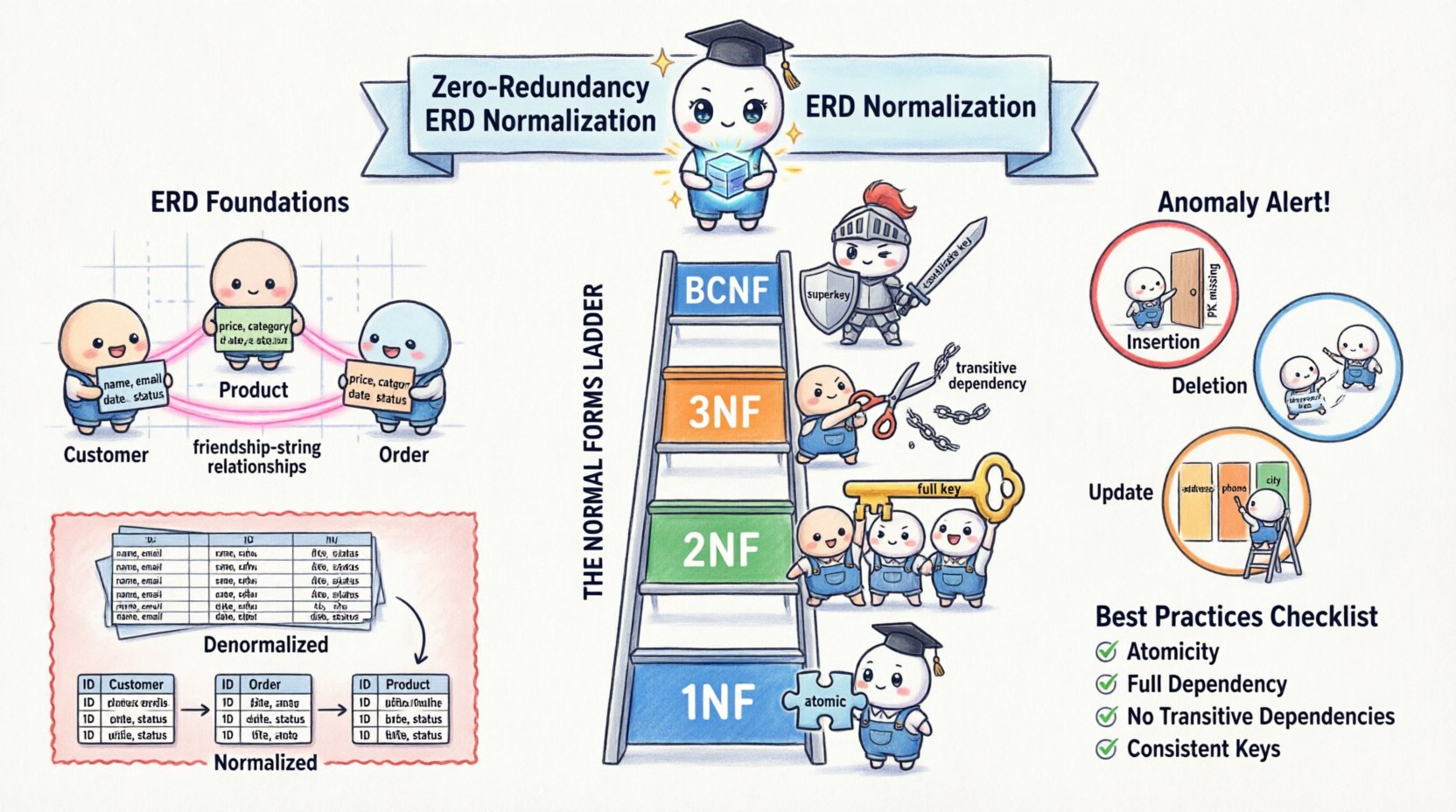
🧱 Hiểu rõ nền tảng của mô hình hóa dữ liệu
Trước khi áp dụng các quy tắc chuẩn hóa, cần phải hiểu rõ các thành phần của sơ đồ quan hệ thực thể. Một ERD bao gồm các thực thể, thuộc tính và mối quan hệ. Các thực thể đại diện cho các đối tượng hoặc khái niệm, chẳng hạn như Khách hàng hoặc Sản phẩm. Các thuộc tính là các đặc tính mô tả các thực thể này, như Tên hoặc Giá. Các mối quan hệ xác định cách các thực thể kết nối với nhau, thường thông qua khóa ngoại.
Chuẩn hóa là quá trình tổ chức các thuộc tính này nhằm giảm thiểu dư thừa và phụ thuộc. Nó bao gồm việc chia các bảng lớn thành các bảng nhỏ hơn, có liên kết logic với nhau và xác định các mối quan hệ giữa chúng. Mục tiêu là tách biệt dữ liệu sao cho mỗi sự kiện chỉ được lưu trữ ở một vị trí duy nhất.
Hãy xem sự khác biệt giữa cách tiếp cận không chuẩn hóa và cách tiếp cận chuẩn hóa. Trong quan điểm không chuẩn hóa, một bảng duy nhất có thể lưu trữ toàn bộ thông tin về một đơn hàng, bao gồm địa chỉ và số điện thoại của khách hàng mỗi khi đặt hàng. Nếu khách hàng chuyển chỗ, bạn phải cập nhật từng bản ghi đơn hàng. Trong quan điểm chuẩn hóa, địa chỉ khách hàng được lưu trong một bảng Khách hàng riêng biệt. Bảng Đơn hàng chỉ lưu tham chiếu đến ID Khách hàng. Sự tách biệt này chính là cốt lõi của việc không dư thừa.
📉 Những rủi ro từ dữ liệu không được chuẩn hóa
Tại sao việc không dư thừa lại quan trọng đến vậy? Câu trả lời nằm ở các loại bất thường xảy ra khi bỏ qua chuẩn hóa. Những bất thường này đe dọa đến độ tin cậy của toàn bộ hệ thống.
- Bất thường chèn dữ liệu:Bạn không thể thêm dữ liệu cho một thực thể mà không thêm dữ liệu cho thực thể khác. Ví dụ, nếu một nhân viên mới chưa được gán vào dự án nào, bạn có thể không thể ghi nhận sự tồn tại của họ nếu bảng yêu cầu ID dự án.
- Bất thường xóa dữ liệu:Việc xóa dữ liệu cho một thực thể có thể vô tình xóa dữ liệu cho thực thể khác. Nếu bạn xóa đơn hàng cuối cùng của một khách hàng, bạn có thể mất hoàn toàn thông tin liên hệ của khách hàng đó.
- Bất thường cập nhật:Đây là vấn đề phổ biến nhất. Nếu địa chỉ khách hàng được lưu trong nhiều bản ghi đơn hàng, việc cập nhật địa chỉ đòi hỏi phải tìm và thay đổi từng bản ghi một. Việc bỏ sót sẽ dẫn đến dữ liệu mâu thuẫn.
Đạt được không dư thừa trực tiếp giảm thiểu những rủi ro này. Bằng cách đảm bảo mỗi mảnh thông tin chỉ có một nơi lưu trữ duy nhất, hệ thống trở nên tự điều chỉnh. Các thay đổi chỉ xảy ra một lần, và thay đổi được lan truyền một cách hợp lý thông qua các mối quan hệ.
🪜 Con đường dẫn đến các dạng chuẩn hóa
Chuẩn hóa không phải là một bước duy nhất mà là một quá trình tiến triển qua các giai đoạn riêng biệt gọi là Các dạng chuẩn hóa. Mỗi dạng giải quyết các loại dư thừa cụ thể. Mặc dù các mô hình lý thuyết có thể đi đến Dạng chuẩn hóa thứ Năm (5NF), thiết kế cơ sở dữ liệu thực tế thường tập trung vào ba dạng đầu tiên và Dạng chuẩn hóa Boyce-Codd (BCNF).
1️⃣ Dạng chuẩn hóa thứ nhất (1NF)
Quy tắc đầu tiên của chuẩn hóa là đảm bảo tính nguyên tử. Một bảng ở dạng 1NF nếu nó không chứa nhóm lặp lại hay mảng. Mỗi cột phải chứa một giá trị duy nhất, và mỗi hàng phải là duy nhất.
- Giá trị nguyên tử:Một trường không thể chứa danh sách các giá trị. Thay vì một cột tên là “Kỹ năng” chứa “Java, SQL, Python”, bạn nên tạo các hàng riêng biệt cho từng kỹ năng hoặc một bảng riêng cho kỹ năng.
- Các hàng duy nhất:Mỗi hàng phải phân biệt được với mọi hàng khác. Điều này thường yêu cầu có Khóa chính.
Trong bối cảnh ERD, điều này có nghĩa là kiểm tra từng thuộc tính. Nếu một thuộc tính mô tả một thuộc tính đa giá trị, nó phải được tách ra. Đây là bước nền tảng. Không có 1NF, các dạng cao hơn không thể được áp dụng hiệu quả.
2️⃣ Dạng chuẩn hóa thứ hai (2NF)
Một khi bảng đã ở dạng 1NF, nó phải đáp ứng các tiêu chí của 2NF. Một bảng ở dạng 2NF nếu nó ở dạng 1NF và tất cả các thuộc tính không khóa đều phụ thuộc hoàn toàn vào toàn bộ khóa chính.
Quy tắc này chủ yếu giải quyết các bảng có khóa hợp thành (khóa gồm nhiều cột). Nếu một bảng có khóa hợp thành, mọi thuộc tính phải phụ thuộc vào toàn bộ khóa, chứ không chỉ một phần của nó.
- Phụ thuộc hoàn toàn:Nếu một cột chỉ phụ thuộc vào một phần của khóa hợp thành, thì nó thuộc về một bảng riêng biệt.
- Phụ thuộc từng phần: Đây là loại dư thừa cụ thể mà dạng chuẩn 2NF loại bỏ. Ví dụ, trong một bảng liên kết giữa Sinh viên và Khóa học, nếu lưu trữ “Tên sinh viên”, thì nó chỉ phụ thuộc vào Mã sinh viên, chứ không phụ thuộc vào Mã khóa học. Điều này tạo ra sự dư thừa.
Giải quyết vấn đề này đòi hỏi việc chia bảng thành các bảng nhỏ hơn. Bạn tạo một bảng Sinh viên và một bảng Khóa học, với một bảng liên kết (junction table) kết nối chúng. Điều này đảm bảo rằng thông tin sinh viên không bị lặp lại cho mỗi khóa học mà họ tham gia.
3️⃣ Dạng chuẩn thứ ba (3NF)
Dạng chuẩn thứ ba xử lý các phụ thuộc bắc cầu. Một bảng ở dạng 3NF nếu nó ở dạng 2NF và không có thuộc tính không khóa nào phụ thuộc vào một thuộc tính không khóa khác.
Nói một cách đơn giản, các thuộc tính không nên phụ thuộc vào các thuộc tính khác không thuộc khóa chính. Điều này thường xảy ra khi một cột mô tả một cột khác thay vì mô tả chính bản ghi.
- Phụ thuộc bắc cầu: Nếu A xác định B, và B xác định C, thì A xác định C. Nếu B không phải là khóa, thì C sẽ được lưu trữ một cách dư thừa.
- Ví dụ: Trong một bảng Nhân viên, nếu bạn lưu trữ “Tên phòng ban” và “Trưởng phòng”, thì Trưởng phòng phụ thuộc vào Tên phòng ban. Nếu tên phòng ban thay đổi, cột Trưởng phòng có thể trở nên không nhất quán nếu không được quản lý cẩn thận.
Để khắc phục điều này, hãy di chuyển thông tin phòng ban sang một bảng Phòng ban riêng biệt. Bảng Nhân viên sau đó chỉ lưu mã Phòng ban. Điều này tách biệt dữ liệu phòng ban, đảm bảo rằng nếu một phòng ban được đổi tên, bạn chỉ cần cập nhật ở một nơi.
4️⃣ Dạng chuẩn Boyce-Codd (BCNF)
BCNF là phiên bản nghiêm ngặt hơn của 3NF. Nó áp dụng khi có nhiều khóa khả dụng hoặc khi một thuộc tính không khóa xác định một thuộc tính không khóa khác theo một cách cụ thể. Một bảng ở dạng BCNF nếu với mọi phụ thuộc hàm X → Y, thì X là siêu khóa.
Dạng này xử lý các tình huống phức tạp mà 3NF vẫn có thể cho phép các bất thường. Nó đảm bảo rằng mọi yếu tố xác định đều là khóa khả dụng. Mặc dù không phải lúc nào cũng cần thiết cho mọi lược đồ, nhưng hướng tới BCNF mang lại mức độ toàn vẹn cấu trúc cao nhất cho việc loại bỏ hoàn toàn dư thừa.
🛠️ Xử lý các bất thường: Một cái nhìn so sánh
Hiểu được tác động của chuẩn hóa đòi hỏi một cái nhìn rõ ràng về cách các bất thường thể hiện ra. Bảng dưới đây nêu bật sự khác biệt giữa trạng thái đã chuẩn hóa và chưa chuẩn hóa liên quan đến các vấn đề dữ liệu phổ biến.
| Loại bất thường | Trạng thái chưa chuẩn hóa | Trạng thái đã chuẩn hóa (không dư thừa) |
|---|---|---|
| Cập nhật | Yêu cầu thay đổi dữ liệu ở nhiều hàng. Nguy cơ cao về sự không nhất quán. | Chỉ yêu cầu thay đổi dữ liệu ở một hàng. Tính nhất quán được đảm bảo tự động. |
| Chèn dữ liệu | Có thể yêu cầu dữ liệu giả để đáp ứng các ràng buộc khóa ngoại. | Các thực thể mới có thể được thêm vào độc lập mà không cần dữ liệu liên quan. |
| Xóa | Việc xóa một bản ghi có thể xóa đi dữ liệu thiết yếu về một thực thể khác. | Việc xóa một bản ghi chỉ ảnh hưởng đến thực thể cụ thể đó, bảo toàn các thực thể khác. |
| Bộ nhớ lưu trữ | Tiêu thụ bộ nhớ cao do các chuỗi và giá trị bị lặp lại. | Sử dụng bộ nhớ tối thiểu; các giá trị được tham chiếu thông qua ID. |
Như đã thấy, phương pháp chuẩn hóa giảm đáng kể gánh nặng vận hành trong quản lý dữ liệu. Chi phí là truy vấn phức tạp hơn một chút, do cần thực hiện các phép nối để truy xuất thông tin đầy đủ. Tuy nhiên, sự đánh đổi này lại có lợi cho tính toàn vẹn và khả năng bảo trì lâu dài.
🛠️ Các chiến lược triển khai
Triển khai các chiến lược này trong giai đoạn thiết kế sơ đồ ERD là điều rất quan trọng. Việc ngăn ngừa sự trùng lặp dữ liệu dễ hơn rất nhiều so với việc sửa chữa sau khi dữ liệu đã được điền đầy. Dưới đây là các bước hành động cụ thể dành cho các nhà thiết kế.
1. Xác định các phụ thuộc chức năng sớm
Trước khi vẽ các đường nối giữa các thực thể, hãy liệt kê các thuộc tính và xác định cái nào quyết định cái nào. Nếu bạn biết rằng Thuộc tính A quyết định Thuộc tính B, thì bạn sẽ biết chúng có khả năng cao nên nằm trong cùng một thực thể, trừ khi A không phải là khóa.
- Xác định tất cả các mối quan hệ.
- Hỏi: “Thuộc tính này có phụ thuộc vào toàn bộ khóa không?”
- Hỏi: “Thuộc tính này có phụ thuộc vào một thuộc tính không khóa khác không?”
2. Tách biệt các thực thể dựa trên vòng đời
Các thực thể có tần suất cập nhật khác nhau thường nên được tách biệt. Nếu một bảng tham chiếu tĩnh (ví dụ như danh sách các quốc gia) được gộp chung với một bảng giao dịch (ví dụ như đơn hàng), dữ liệu tĩnh sẽ tạo ra sự trùng lặp không cần thiết trong bảng giao dịch.
3. Sử dụng khóa giả
Thay vì sử dụng dữ liệu tự nhiên làm khóa chính, hãy cân nhắc sử dụng khóa giả (một định danh duy nhất do hệ thống tạo ra). Điều này ngăn ngừa các vấn đề xảy ra khi chính khóa thay đổi theo thời gian, điều đó sẽ làm hỏng các mối quan hệ trong hệ thống đã được chuẩn hóa.
4. Xác minh bằng dữ liệu kiểm thử
Trước khi hoàn tất sơ đồ ERD, hãy thử điền dữ liệu mẫu vào nó. Hãy thử tạo ra các hiện tượng bất thường được mô tả trước đó. Nếu bạn có thể chèn một khách hàng mà không cần đơn hàng, và xóa một đơn hàng mà không làm mất khách hàng, thì thiết kế của bạn có khả năng là hợp lý.
⚖️ Cân bằng hiệu suất và độ thuần khiết
Đạt được không có trùng lặp dữ liệu không có nghĩa là tối đa hóa số lượng bảng. Chuẩn hóa quá mức có thể dẫn đến suy giảm hiệu suất. Khi một truy vấn yêu cầu dữ liệu từ mười bảng khác nhau, hệ thống phải thực hiện mười phép nối. Điều này có thể làm chậm đáng kể các thao tác đọc.
Khi nào nên không chuẩn hóa
Có những lý do hợp lý để chủ ý đưa lại sự trùng lặp dữ liệu. Điều này thường được gọi là không chuẩn hóa.
- Hệ thống trọng tải đọc cao: Trong các kho dữ liệu hoặc công cụ báo cáo, tốc độ đọc được ưu tiên hơn so với tính nhất quán khi ghi. Các cột đã được tính toán trước có thể giảm độ phức tạp của phép nối.
- Các bản chụp lịch sử: Nếu bạn cần biết địa chỉ của khách hàng là gì vào thời điểm đặt hàng, bạn không thể dựa vào địa chỉ hiện tại trong bảng Khách hàng. Bạn phải lưu địa chỉ đó trong bảng Đơn hàng.
- Tối ưu hiệu suất: Nếu các truy vấn liên tục chậm do các phép nối, việc thêm một cột trùng lặp được cập nhật thông qua trigger hoặc logic ứng dụng có thể là cần thiết.
Điều then chốt là sự chủ ý. Đừng chấp nhận sự trùng lặp như một mặc định. Chỉ chấp nhận nó khi có lợi ích hiệu suất đo lường được, vượt trội hơn chi phí bảo trì.
🔄 Xem xét và duy trì lược đồ của bạn
Chuẩn hóa không phải là một công việc một lần. Yêu cầu kinh doanh thay đổi, và dữ liệu ngày càng tăng. Một lược đồ đã được chuẩn hóa cách đây năm năm có thể cần điều chỉnh ngày nay.
Kiểm toán định kỳ
Lên lịch kiểm tra định kỳ sơ đồ ERD của bạn. Tìm kiếm các mẫu dữ liệu bị lặp lại. Nếu bạn phát hiện cùng một chuỗi văn bản xuất hiện trong nhiều bảng, hãy điều tra lý do. Điều này có thể là dấu hiệu của lỗi thiết kế hoặc lựa chọn không chuẩn hóa có chủ ý, cần được ghi chép lại.
Kiểm soát phiên bản cho các mô hình dữ liệu
Xem sơ đồ quan hệ thực thể (ERD) của bạn như mã nguồn. Sử dụng hệ thống kiểm soát phiên bản để theo dõi các thay đổi. Điều này cho phép bạn hoàn nguyên nếu một thay đổi gây ra sự trùng lặp hoặc làm hỏng các mối quan hệ. Ghi chép lý do cho mọi thay đổi cấu trúc lớn.
Đào tạo đội ngũ
Đảm bảo rằng mọi người tham gia nhập dữ liệu hoặc phát triển ứng dụng đều hiểu rõ các quy tắc chuẩn hóa. Nếu các nhà phát triển bỏ qua lược đồ để chèn dữ liệu trực tiếp, họ có thể tái tạo lại sự trùng lặp thông qua logic ứng dụng. Tài liệu rõ ràng về lý do tại sao lược đồ được cấu trúc theo cách này là điều cần thiết.
📝 Tóm tắt các thực hành tốt nhất
Để duy trì tiêu chuẩn cao về chất lượng dữ liệu và hiệu quả lưu trữ, tuân theo danh sách kiểm tra sau trong quá trình thiết kế của bạn.
- Tính nguyên tử: Đảm bảo mỗi cột chỉ chứa một giá trị duy nhất (1NF).
- Sự phụ thuộc đầy đủ: Đảm bảo các thuộc tính không khóa phụ thuộc vào toàn bộ khóa chính (2NF).
- Không có phụ thuộc bắc cầu: Đảm bảo các thuộc tính không khóa không phụ thuộc vào các thuộc tính không khóa khác (3NF).
- Khóa nhất quán: Đảm bảo mọi yếu tố xác định đều là khóa khả dụng (BCNF).
- Ghi chép các quyết định: Ghi lại lý do tại sao các sự trùng lặp cụ thể đã được đưa vào.
- Theo dõi sự phát triển: Quan sát các mẫu dữ liệu bị lặp lại khi cơ sở dữ liệu mở rộng.
Bằng cách tuân theo các nguyên tắc này, bạn tạo ra một hệ thống có khả năng chống chịu với sự thay đổi. Dữ liệu vẫn được giữ sạch sẽ, và logic vẫn hợp lý. Không trùng lặp không chỉ nhằm tiết kiệm dung lượng ổ đĩa; đó là xây dựng nền tảng nơi sự thật của dữ liệu được bảo toàn.
🚀 Những suy nghĩ cuối cùng về tính toàn vẹn cấu trúc
Hành trình hướng tới lưu trữ không trùng lặp là một khoản đầu tư vào sự bền vững của kiến trúc dữ liệu của bạn. Dù nó đòi hỏi sự kỷ luật trong giai đoạn thiết kế, nhưng lợi ích mang lại là giảm lỗi, chi phí bảo trì thấp hơn và niềm tin cao hơn vào hệ thống thông tin.
Khi bạn nhìn vào sơ đồ quan hệ thực thể, hãy xem nó không chỉ là một tập hợp các hình hộp và đường kẻ, mà là bản đồ của sự thật. Mỗi đường kẻ đại diện cho một mối quan hệ cần thiết. Mỗi hình hộp đại diện cho một sự kiện riêng biệt. Bằng cách chuẩn hóa hiệu quả, bạn đảm bảo bản đồ này vẫn chính xác, ngay cả khi địa hình kinh doanh của bạn thay đổi.
Tập trung vào logic, chứ không chỉ là lưu trữ. Để cấu trúc phục vụ dữ liệu, chứ không phải ngược lại. Với sự hiểu rõ về các chiến lược chuẩn hóa, bạn sẽ sẵn sàng xây dựng các hệ thống vượt qua thử thách của thời gian và khối lượng dữ liệu.