











Диаграмма потока данных (DFD) служит фундаментальным инструментом в анализе и проектировании систем. Она предоставляет визуальное представление о том, как информация перемещается через систему. В отличие от блок-схем, которые фокусируются на потоке управления и логике, DFD акцентирует внимание на преобразовании данных. В этом руководстве подробно описываются основные компоненты, стили нотаций и структурные правила, необходимые для создания точных диаграмм.
Понимание цели диаграммы потока данных 🎯
Прежде чем выбирать символы или рисовать потоки, необходимо понимать цель диаграммы. DFD отвечает на конкретные вопросы, касающиеся перемещения данных:
- Откуда берется данные?
- Как преобразуются данные?
- Куда приходят данные?
- Какие данные хранятся для последующего использования?
Эти диаграммы выступают в качестве моста между техническими требованиями и бизнес-потребностями. Они позволяют заинтересованным сторонам проверить, что система будет корректно обрабатывать информацию, не вникая в лежащий в основе код. Визуализируя систему как последовательность процессов и потоков, аналитики могут выявить узкие места, отсутствующие данные или избыточные шаги на ранних этапах жизненного цикла разработки.
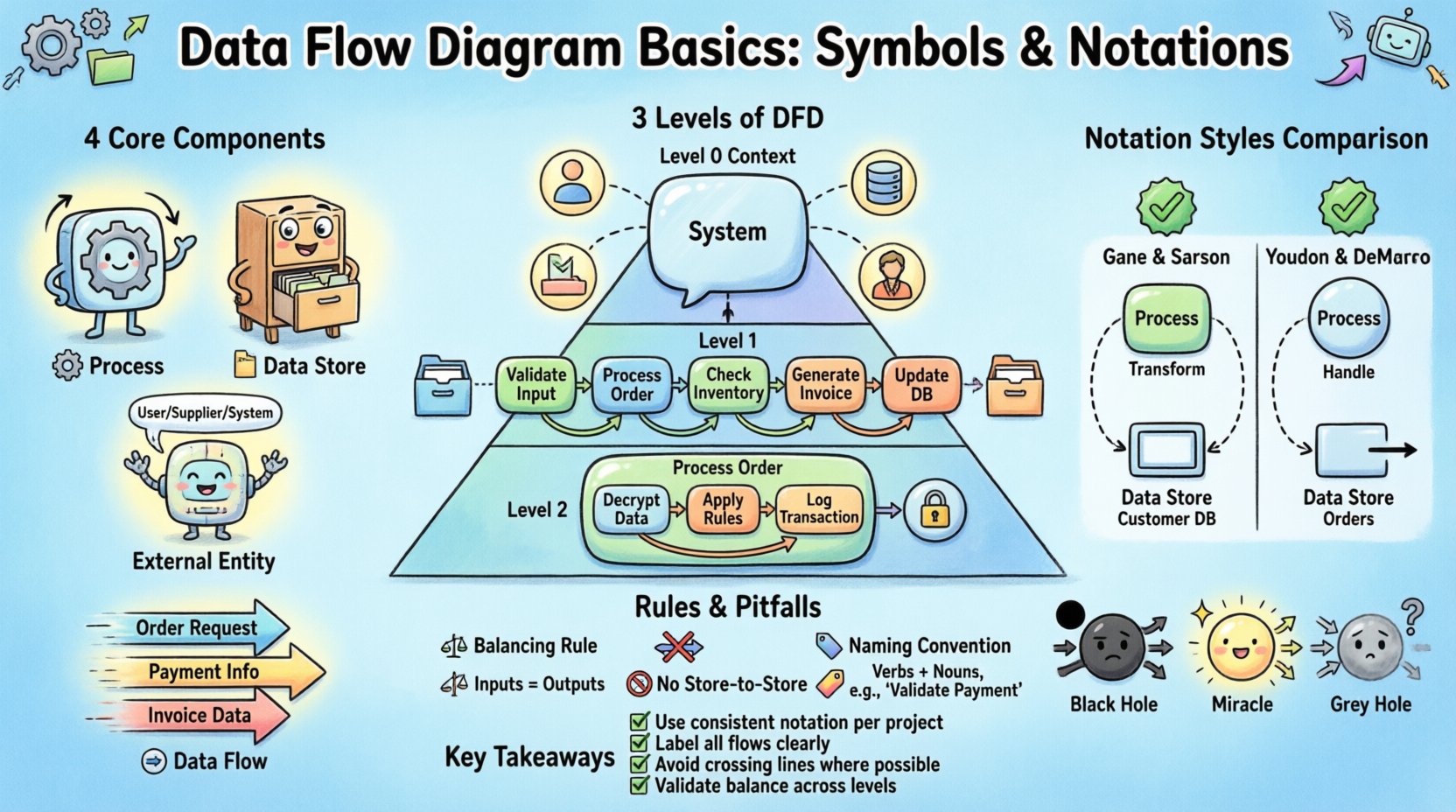
Четыре основных компонента DFD 🧩
Каждая диаграмма потока данных опирается на четыре различных элемента. Эти символы определяют поведение и взаимосвязи внутри системы. Овладение этими компонентами гарантирует, что диаграмма останется последовательной и понятной для всех членов команды.
1. Процесс (преобразование) ⚙️
Процесс представляет собой действие или функцию, которая изменяет данные. Он принимает входные данные, выполняет вычисление или преобразование и выдает выходные данные. В DFD процессы — это не сам код, а логическая функция, выполняемая в системе.
- Функция:Преобразует входные данные в выходные.
- Идентификатор:Каждый процесс должен иметь уникальное имя и номер.
- Глагол-существительное:Имена обычно следуют структуре глагол-существительное (например, Рассчитать налог, Проверить пользователя).
- Разбиение:Сложные процессы могут быть разбиты на подпроцессы на диаграммах более низкого уровня.
2. Хранилище данных (репозиторий) 📂
Хранилище данных представляет собой место, где данные находятся в состоянии покоя. Оно хранит информацию, которая в данный момент не обрабатывается, но потребуется позже. Это может быть таблица базы данных, файл или физический файловый шкаф.
- Сохранность:Данные остаются в хранилище между сессиями системы.
- Доступ: Процессы должны читать из хранилища или записывать в него.
- Направление: Хранилища данных не создают данные; они только хранят их.
- Именование: Имена должны быть множественным числом существительных (например, Заказы, Клиенты).
3. Внешняя сущность (источник/приемник) 🌐
Внешняя сущность — это человек, организация или система за пределами текущей системы. Она выступает источником данных (вход) или местом назначения данных (выход).
- Граница:Всё, что находится за пределами диаграммы, является внешней сущностью.
- Роль: Может быть пользователем, API сторонней системы, государственным органом или аппаратным устройством.
- Взаимодействие:Данные передаются между системой и сущностью.
4. Поток данных (движение) ➡️
Поток данных представляет движение информации между компонентами. Это соединение, которое объединяет диаграмму. Стрелки указывают направление данных.
- Метки:Каждая стрелка должна быть помечена названием пакета данных.
- Атомарность:Один поток данных должен передавать одну логическую единицу информации.
- Направление:Поток данных односторонний в стандартной диаграмме потоков данных.
- Логика:Данные должны проходить через процесс; они не могут передаваться напрямую между хранилищами данных.
Уровни диаграмм потоков данных 📉
Диаграммы потоков данных иерархичны. Одна система слишком сложна, чтобы отобразить её в одном виде. Поэтому диаграммы разбиваются на уровни детализации. Такой подход позволяет аналитикам управлять сложностью, сохраняя при этом целостность всей системы.
Уровень 0: Диаграмма контекста 🌍
Диаграмма контекста предоставляет наиболее высокий уровень представления системы. Она определяет границы системы и показывает, как система взаимодействует с внешними сущностями.
- Одиночный процесс: Вся система представляется как один единственный процесс.
- Входы/выходы: Показывает основные данные, входящие в систему и покидающие её.
- Область применения: Определяет границы проекта.
Уровень 1: Основные процессы 🔍
Уровень 1 расчленяет единственный процесс из диаграммы контекста на основные подпроцессы. Он показывает основные функции, составляющие систему.
- Расширение: Основной процесс делится на 3–7 основных процессов.
- Введение хранилищ: Вводятся хранилища данных, чтобы показать, где хранится информация.
- Уровень детализации: Достаточно деталей, чтобы понять основную логику, не запутываясь в мелочах.
Уровень 2: Подробные процессы 🛠️
Уровень 2 дополнительно расчленяет конкретные процессы уровня 1. Используется для сложных областей, требующих точного определения логики.
- Детализация: Сосредоточен на конкретных рабочих процессах или модулях.
- Валидация: Обеспечивает, чтобы все потоки данных были сбалансированы с родительским процессом.
- Реализация: Часто используется как прямая ссылка для разработчиков.
Стили нотации: руководство по сравнению 🔄
Существуют два основных стиля нотации, используемых для диаграмм потоков данных. Хотя они передают одну и ту же логическую информацию, визуальное представление символов различается. Понимание этих различий критически важно при взаимодействии с командами, использующими определённые традиции.
| Компонент | Гейн и Сарсон | Юрдон и ДеМарко |
|---|---|---|
| Процесс | Округлённый прямоугольник | Круг или закруглённый прямоугольник |
| Хранилище данных | Открытый прямоугольник (2 параллельные линии) | Прямоугольник с открытой правой стороной |
| Внешняя сущность | Прямоугольник | Прямоугольник |
| Поток данных | Стрелка | Стрелка |
| Соединитель | Стрелка | Стрелка |
Гейн и Сарсон: Этот стиль обозначения широко используется в США и Европе. Он использует закруглённый прямоугольник для обозначения процессов и специальную двойную линию для хранилищ данных. Он акцентирует внимание на процессе как на контейнере для логики.
Юрдон и Демарко: Этот стиль обозначения появился раньше и широко используется в академических и устаревших системах. Он использует круги для обозначения процессов. Хранилище данных изображается прямоугольником с отсутствующей стороной. Оба стиля обозначений являются допустимыми, но согласованность в рамках проекта обязательна.
Правила целостности потока данных ⚖️
Чтобы обеспечить логическую корректность диаграммы потока данных, необходимо соблюдать определённые правила. Нарушение этих правил создаёт неоднозначность и может привести к сбоям в проектировании системы. Эти правила регулируют движение и преобразование данных.
1. Правило балансировки ⚖️
При декомпозиции диаграммы с одного уровня на следующий входы и выходы должны оставаться согласованными. Это называется балансировкой потока данных.
- Если родительский процесс имеет входной поток Данные заказа, то дочерняя диаграмма должна учитывать получение Данные заказа.
- Новые входы не могут появляться на дочерней диаграмме, если их не было на родительской.
- Существующие выходы должны сохраняться при декомпозиции.
2. Нет прямого потока данных от хранилища к хранилищу 🚫
Данные не могут перемещаться напрямую из одного хранилища данных в другое. Должен существовать процесс, который преобразует или перемещает данные.
- Причина: Перемещение данных обычно требует логики (например, обновление записи, копирование файла).
- Последствия: Каждый перенос информации должен включать этап обработки.
3. Правила именования потоков данных 🏷️
Метки на потоках данных должны быть описательными и единственного числа.
- Одна концепция: Стрелка, помеченнаяИнформация о клиенте означает конкретный пакет данных, а не поток всей информации о клиентах.
- Согласованность: Один и тот же пакет данных должен иметь одно и то же имя на всех диаграммах.
- Нет потока управления: Не помечайте потоки логикой (например, Да/Нет). ДФД фокусируются на данных, а не на управлении.
4. Логика хранилища данных 🗄️
Хранилища данных должны быть доступны логически.
- Чтение/Запись: Процесс должен указывать, производит ли он чтение из хранилища или запись в него.
- Существование: Хранилище данных должно быть доступно по крайней мере одним процессом.
- Изоляция: Хранилище не может существовать без процесса, управляющего его данными.
Распространённые ошибки и ловушки в ДФД 🚨
Даже опытные аналитики могут допускать ошибки при построении диаграмм. Признание этих распространённых ошибок помогает в отладке и проверке проектов систем.
1. Процесс-чёрная дыра ⚫
Чёрная дыра — это процесс, имеющий вход, но не имеющий выхода. Он потребляет данные, не выдавая никакого результата.
- Последствия: Система потребляет ресурсы, не принося при этом никакой пользы.
- Исправление: Определите, что процесс должен производить, и добавьте необходимые потоки данных.
2. Чудесный процесс ✨
Чудесный процесс — это противоположность чёрной дыре. У него есть выход, но нет входа. Он создаёт данные из ничего.
- Последствие: Система генерирует данные без источника.
- Исправление: Определите источник данных, вернувшись к внешнему сущности или хранилищу данных.
3. Серая дыра процесса 🌫️
Серая дыра возникает, когда входы и выходы процесса не совпадают по объёму или типу при декомпозиции.
- Последствие: Данные исчезают или появляются несогласованно между уровнями.
- Исправление: Убедитесь, что декомпозиция сохраняет все потоки данных с родительского уровня.
4. Пересекающиеся потоки данных ⤵️
Хотя пересечение потоков данных не всегда запрещено, оно может сделать диаграмму трудной для чтения.
- Чёткость: Используйте соединители, чтобы направить линии вокруг пересечений, если это возможно.
- Размещение: Расположите процессы и хранилища так, чтобы минимизировать пересечения линий.
Диаграммы потоков данных и словарь данных 📚
DFD не может существовать самостоятельно. Для определения точной структуры данных, проходящих через диаграмму, требуется словарь данных. Словарь данных — это хранилище информации о элементах данных, используемых в системе.
- Определение: Указывает тип данных, длину и формат каждого элемента данных.
- Связь: Связывает символы DFD с конкретными полями базы данных.
- Согласованность: Обеспечивает соответствие метки на стрелке DFD определению в словаре.
Без словаря данных DFD остаётся высоким уровнем абстракции. С ним диаграмма становится чертежом для проектирования базы данных и логики приложения. Это интеграция обеспечивает точную передачу визуальной модели в техническую реализацию.
Лучшие практики для обслуживания 🛡️
Системы эволюционируют со временем. Диаграмма потоков данных должна поддерживаться для отражения изменений в требованиях или архитектуре.
- Контроль версий: Отслеживайте версии диаграмм для управления изменениями.
- Влияние изменений: Когда процесс изменяется, проверьте все подключенные потоки и хранилища.
- Циклы обзора: Проводите регулярные обзоры с заинтересованными сторонами, чтобы убедиться, что диаграмма соответствует реальности.
- Документация: Добавляйте примечания к диаграммам, поясняющие сложную логику.
Заключение по моделированию системы 🏁
Создание диаграммы потоков данных — это дисциплинированная деятельность, требующая внимания к деталям и соблюдения структурных правил. Используя правильные символы и соблюдая правила балансировки, аналитики могут создать четкую карту поведения системы. Различие между нотациями Гейна и Сарсона и Юрдона и Демарко обеспечивает гибкость, но приоритетом остается последовательность. Избегание распространенных ошибок, таких как черные дыры и чудеса, гарантирует логическую целостность. В сочетании со словарем данных диаграмма потоков данных становится мощным инструментом для определения требований к системе и руководства разработкой.
Ценность диаграммы потоков данных заключается в ее способности передавать сложные перемещения данных неспециалистам. Она упрощает систему до понятных компонентов, способствуя более качественному принятию решений на протяжении всего жизненного цикла проекта. Независимо от того, разрабатывается ли новое приложение или анализируется существующее, принципы диаграмм потоков данных обеспечивают надежную основу для анализа системы.
Краткое резюме ключевых выводов ✅
- Основные элементы: Процессы, хранилища данных, внешние сущности и потоки данных образуют основу каждой диаграммы.
- Иерархия: Используйте уровни 0, 1 и 2 для управления сложностью и детализацией.
- Нотация: Выберите один стандарт (Гейн и Сарсон или Юрдон и Демарко) и придерживайтесь его.
- Целостность: Убедитесь, что все потоки сбалансированы между родительской и дочерней диаграммами.
- Логика: Избегайте ошибок потоков данных, таких как чудеса и черные дыры.
- Документация: Всегда связывайте элементы диаграммы потоков данных со словарем данных.
Применение этих принципов гарантирует, что результатирующая документация будет точной, поддерживаемой и полезной для всей команды разработки. Хорошо построенная диаграмма потоков данных снижает неоднозначность и согласует техническую реализацию с бизнес-целями.