











データフローダイアグラム(DFD)は、システム分析および設計における基本的なツールです。情報がシステム内でどのように移動するかを視覚的に表現します。フローチャートが制御フローと論理に焦点を当てるのに対し、DFDはデータの変換に重点を置きます。このガイドでは、正確な図を構築するために必要な核心的な構成要素、表記スタイル、構造上のルールについて説明します。
DFDの目的を理解する 🎯
記号を選択したり、フローを描画する前に、図の目的を理解することが不可欠です。DFDはデータの移動に関する特定の問いに答えます:
- データはどこから始まるのか?
- データはどのように変換されるのか?
- データはどこに到達するのか?
- 将来の使用のために保存されるデータは何か?
これらの図は、技術的要件とビジネスニーズの間の橋渡しの役割を果たします。ステークホルダーは、下層のコードを理解しなくても、システムが情報を正しく処理するかどうかを検証できます。システムを一連のプロセスとフローとして可視化することで、開発ライフサイクルの初期段階でボトルネック、欠落しているデータ、または冗長なステップを特定できます。
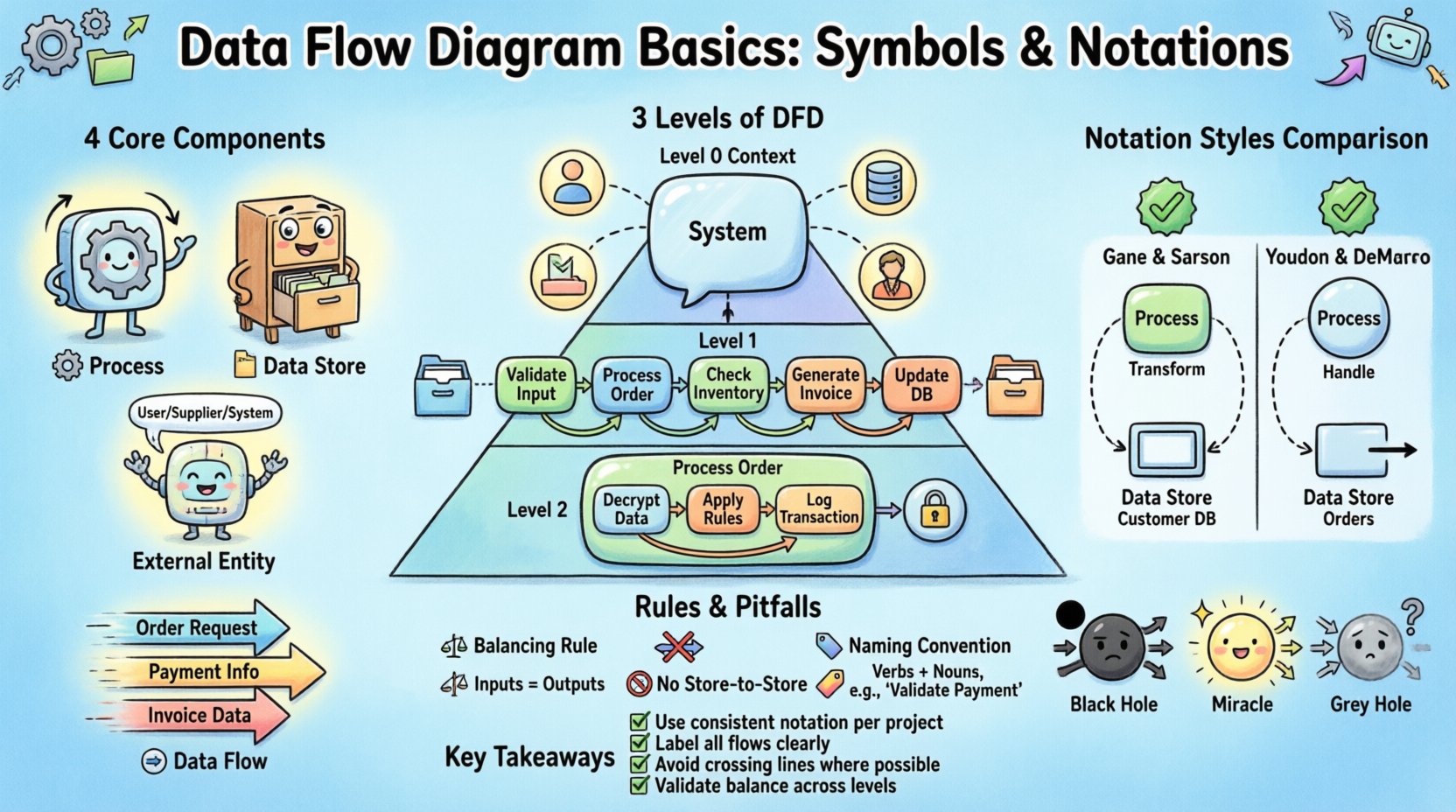
DFDの4つの核心的構成要素 🧩
すべてのデータフローダイアグラムは、4つの異なる要素に依存しています。これらの記号は、システム内の動作と関係性を定義します。これらの構成要素を習得することで、図がすべてのチームメンバーにとって一貫性があり、解釈可能であることが保証されます。
1. プロセス(変換) ⚙️
プロセスは、データを変化させるアクションまたは機能を表します。入力データを受け取り、計算または変換を実行し、出力データを生成します。DFDでは、プロセスは実際のコードではなく、実行されている論理的な機能を意味します。
- 機能:入力を出力に変換する。
- 識別子:各プロセスには、固有の名前と番号が必要である。
- 動詞+名詞:名前は通常、動詞+名詞の構造に従う(例:税金を計算する, ユーザーを検証する).
- 分解:複雑なプロセスは、低レベルの図でサブプロセスに分解できる。
2. データストア(リポジトリ) 📂
データストアは、データが静止している場所を表します。現在処理されていないが、後に必要となる情報を保持します。これはデータベースのテーブル、ファイル、または物理的なファイルボックスである可能性があります。
- 永続性:データはシステムセッションの間もストアに保持される。
- アクセス: プロセスはストアから読み取るか、ストアに書き込む必要がある。
- 方向: データストアはデータを作成しない。データを保持するだけである。
- 名前付け: 名前は複数形の名詞にするべきである(例:注文, 顧客).
3. 外部エンティティ(ソース/シンク) 🌐
外部エンティティとは、現在のシステムの境界外にある人物、組織、またはシステムを指す。これはデータのソース(入力)またはデータの宛先(出力)として機能する。
- 境界: 図の範囲外にあるものはすべて外部エンティティである。
- 役割: ヒューマンユーザー、サードパーティAPI、政府機関、またはハードウェアデバイスである可能性がある。
- インタラクション: データはシステムとエンティティの間を流れている。
4. データフロー(移動) ➡️
データフローは、コンポーネント間での情報の移動を表す。これは図を統合する接続である。矢印はデータの方向を示す。
- ラベル付け: すべての矢印には、データパケットの名前をラベル付けしなければならない。
- 原子性: 単一のデータフローは、論理的な1つの情報のみを伝えるべきである。
- 方向: 標準的なDFDでは、フローは単方向である。
- 論理: データはプロセスを経由して流れなければならない。データストアの間を直接流れることはできない。
データフローダイアグラムのレベル 📉
DFDは階層的である。単一のシステムは1つのビューで示すには複雑すぎる。そのため、図は詳細のレベルに分けて表現される。このアプローチにより、分析者は複雑さを管理しつつ、全体システムの整合性を保つことができる。
レベル0:コンテキスト図 🌍
コンテキスト図は、システムの最も高レベルの視点を提供します。システムの境界を定義し、システムが外部エントリとどのように相互作用するかを示します。
- 単一プロセス: システム全体が1つのプロセスとして表現されます。
- 入力/出力: システムに入出力される主要なデータを示します。
- 範囲: プロジェクトの境界を設定します。
レベル1:主要プロセス 🔍
レベル1では、コンテキスト図の単一プロセスを主要なサブプロセスに分解します。システムを構成する主要な機能を示します。
- 拡張: 主プロセスが3~7つの主要プロセスに分割されます。
- ストアの導入: データストアを導入して、情報が保存される場所を示します。
- 詳細レベル: 主要な論理を理解するのに十分な詳細であり、細部に囚われすぎない。
レベル2:詳細プロセス 🛠️
レベル2では、レベル1の特定のプロセスをさらに分解します。正確な論理定義を必要とする複雑な領域に使用されます。
- 粒度: 特定のワークフローまたはモジュールに焦点を当てる。
- 検証: すべてのデータフローが親プロセスとバランスしていることを確認します。
- 実装: 開発者にとって直接的な参照としてよく使用されます。
表記スタイル:比較ガイド 🔄
DFDに使用される主な表記スタイルは2つあります。論理情報は同じですが、記号の視覚的表現が異なります。特定の慣習を持つチームと協業する際には、これらの違いを理解することが重要です。
| コンポーネント | Gane & Sarson | Yourdon & DeMarco |
|---|---|---|
| プロセス | 丸角長方形 | 円またはラウンドされた長方形 |
| データストア | 開かれた長方形(2本の平行線) | 右側が開いた長方形 |
| 外部エンティティ | 長方形 | 長方形 |
| データフロー | 矢印 | 矢印 |
| コネクタ | 矢印 | 矢印 |
Gane & Sarson: この表記法はアメリカ合衆国およびヨーロッパで広く使用されています。プロセスにはラウンドされた長方形を、データストアには特定の二重線の形状を使用します。プロセスを論理のコンテナとして強調しています。
Yourdon & DeMarco: この表記法はより古くから存在し、学術的およびレガシーシステムで一般的です。プロセスには円を使用します。データストアは、一方の辺が欠けた長方形で表されます。両方の表記法は有効ですが、プロジェクト内での一貫性は必須です。
データフロー整合性のルール ⚖️
DFDが論理的に整合していることを保証するため、特定のルールを遵守する必要があります。これらのルールに違反すると曖昧さが生じ、システム設計の失敗につながる可能性があります。これらのルールは、データの移動と変換の仕方を規定しています。
1. バランスルール ⚖️
図を1レベルから次のレベルに分解する際、入力と出力は一貫性を保たなければなりません。これをデータフローのバランスと呼びます。
- 親プロセスに「注文データ」という入力がある場合、子図はその受信を考慮しなければなりません。注文データ.
- 新しい入力は、親図に存在しなかったものとして子図に現れてはなりません。
- 既存の出力は分解の過程で保持されなければなりません。
2. 直接的なストア間フローは禁止 🚫
データは、1つのデータストアから別のデータストアへ直接移動することはできません。データを変換または移動するためのプロセスが存在しなければなりません。
- 理由:データの移動は通常、論理処理を必要とする(例:レコードの更新、ファイルのコピー)。
- 含意:情報のすべての転送は、処理ステップを含まなければならない。
3. データフローの命名規則 🏷️
データフローのラベルは、説明的で単数である必要がある。
- 単一の概念: 矢印にラベルが付いている 顧客情報 は、すべての顧客データのストリームではなく、特定のデータパケットを意味する。
- 一貫性: 同じデータパケットは、すべての図で同じ名前を持つべきである。
- 制御フローを含めない: 論理(例:はい/いいえ)でフローにラベルを付けない。DFDは制御ではなくデータに焦点を当てる。
4. データストアの論理 🗄️
データストアは論理的にアクセスされなければならない。
- 読み取り/書き込み: プロセスは、ストアから読み取りを行っているか、書き込みを行っているかを示すべきである。
- 存在: データストアは、少なくとも1つのプロセスによってアクセスされなければならない。
- 隔離: データを管理するプロセスがなければ、ストアは存在できない。
一般的なDFDの誤りと落とし穴 🚨
経験豊富なアナリストですら、図を構築する際に誤りを犯すことがある。これらの一般的な誤りを認識することは、デバッグやシステム設計の検証に役立つ。
1. ブラックホールプロセス ⚫
ブラックホールとは、入力はあるが出力がないプロセスである。データを消費するが、何らの結果を生じない。
- 含意: システムは価値を提供せずにリソースを消費している。
- 修正:プロセスが生成すべきものを特定し、必要なデータフローを追加する。
2. ミラクルプロセス ✨
ミラクルプロセスはブラックホールの反対である。出力はあるが入力はない。何もないところからデータを生成する。
- 影響:システムはソースのないデータを生成している。
- 修正:データのソースを外部エンティティまたはデータストアまで遡る。
3. グレーホールプロセス 🌫️
分解の過程で、プロセスの入力と出力の量や種類が一致しない場合、グレーホールが発生する。
- 影響:データがレベル間で消失したり、一貫性なく出現したりしている。
- 修正:親レベルからのすべてのデータフローが保持されることを確認する。
4. データフローの交差 ⤵️
常に禁止されるわけではないが、データフローの交差は図の読みにくさを招くことがある。
- 明確性:可能な限り、接続子を使って線を交差部分の周りに迂回させる。
- レイアウト:線の交差を最小限に抑えるために、プロセスやストアを配置する。
データフロー図とデータ辞書 📚
DFDは単独では成り立たない。図を流れるデータの正確な構造を定義するためには、データ辞書が必要である。データ辞書は、システムで使用されるデータ要素に関する情報を蓄積したリポジトリである。
- 定義:各データ要素のデータ型、長さ、フォーマットを指定する。
- 関係:DFDの記号を特定のデータベースフィールドにリンクする。
- 一貫性:DFDの矢印のラベルが辞書内の定義と一致することを保証する。
データ辞書がなければ、DFDは高レベルの抽象化に留まる。それがあることで、図はデータベース設計およびアプリケーション論理のためのブループリントとなる。この統合により、視覚モデルが技術的実装に正確に変換されることを保証する。
保守のためのベストプラクティス 🛡️
システムは時間とともに進化する。要件やアーキテクチャの変更を反映するために、DFDは維持されなければならない。
- バージョン管理:変更を管理するために、図のバージョンを追跡する。
- 変更の影響:プロセスが変更された場合、すべての接続されたフローとストアを確認する。
- レビュー・サイクル:ステークホルダーとの定期的なレビューを行い、図が現実と一致していることを確認する。
- ドキュメント化:複雑な論理を説明するメモを図に付記する。
システムモデリングの結論 🏁
データフローダイアグラムを作成することは、細部への注意と構造的ルールの遵守を要する厳格な活動である。正しい記号を使用し、バランスルールに従うことで、分析担当者はシステム動作の明確な地図を作成できる。Gane & SarsonとYourdon & DeMarcoの表記法の違いは柔軟性を提供するが、一貫性が最優先である。ブラックホールやミラクルといった一般的な誤りを避けることで、論理的な整合性が保たれる。データ辞書と併用することで、DFDはシステム要件を定義し、開発を指導する強力なツールとなる。
DFDの価値は、非技術的ステークホルダーに複雑なデータ移動を伝える能力にある。システムを理解しやすい構成要素に簡素化することで、プロジェクトライフサイクル全体におけるより良い意思決定を促進する。新しいアプリケーションの設計であれ、既存のシステムの分析であれ、DFDの原則はシステム分析の安定した基盤を提供する。
主なポイントの要約 ✅
- 基本要素:プロセス、データストア、外部エンティティ、データフローは、すべての図の基礎を成す。
- 階層:複雑さと詳細を管理するために、レベル0、1、2を使用する。
- 表記法:一つの標準(Gane & SarsonまたはYourdon & DeMarco)を選択し、それを一貫して使用する。
- 整合性:親図と子図の間ですべてのフローがバランスしていることを確認する。
- 論理:ミラクルやブラックホールのようなデータフローの誤りを避ける。
- ドキュメント化:常にDFDの要素をデータ辞書にリンクする。
これらの原則を適用することで、結果として得られるドキュメントが正確で、保守可能であり、開発チーム全体にとって有用であることが保証される。適切に構築されたDFDは曖昧さを低減し、技術的実行をビジネス目標と一致させる。