











Создание диаграммы потоков данных (DFD) является критически важным этапом анализа и проектирования системы. Эти визуальные представления отображают движение данных через систему, выделяя входы, выходы и хранение. При точном построении DFD выступает в роли чертежа для разработчиков и заинтересованных сторон, обеспечивая понимание логики и потока информации всеми участниками. Однако для создания точной диаграммы требуется дисциплина и соблюдение определённых стандартов. В этом руководстве описаны основные практики по построению эффективных диаграмм потоков данных без использования специфических программных инструментов.
🔍 Понимание цели диаграммы потоков данных
Прежде чем приступать к механике, важно понимать, почему эти диаграммы имеют значение. Диаграмма потоков данных — это не блок-схема. Она не отображает поток управления или точки принятия решений, такие как «если-то». Вместо этого она строго фокусируется на самих данных. Она отвечает на вопросы: откуда приходят данные? Куда они направляются? Как они преобразуются? Где они хранятся?
- Инструмент коммуникации: Он устраняет разрыв между техническими командами и бизнес-заинтересованными сторонами.
- Средство анализа: Он помогает выявить узкие места, отсутствующие данные или избыточные процессы.
- Основа проектирования: Он обеспечивает структуру для проектирования баз данных и архитектуры кода.
🧱 Основные компоненты диаграммы потоков данных
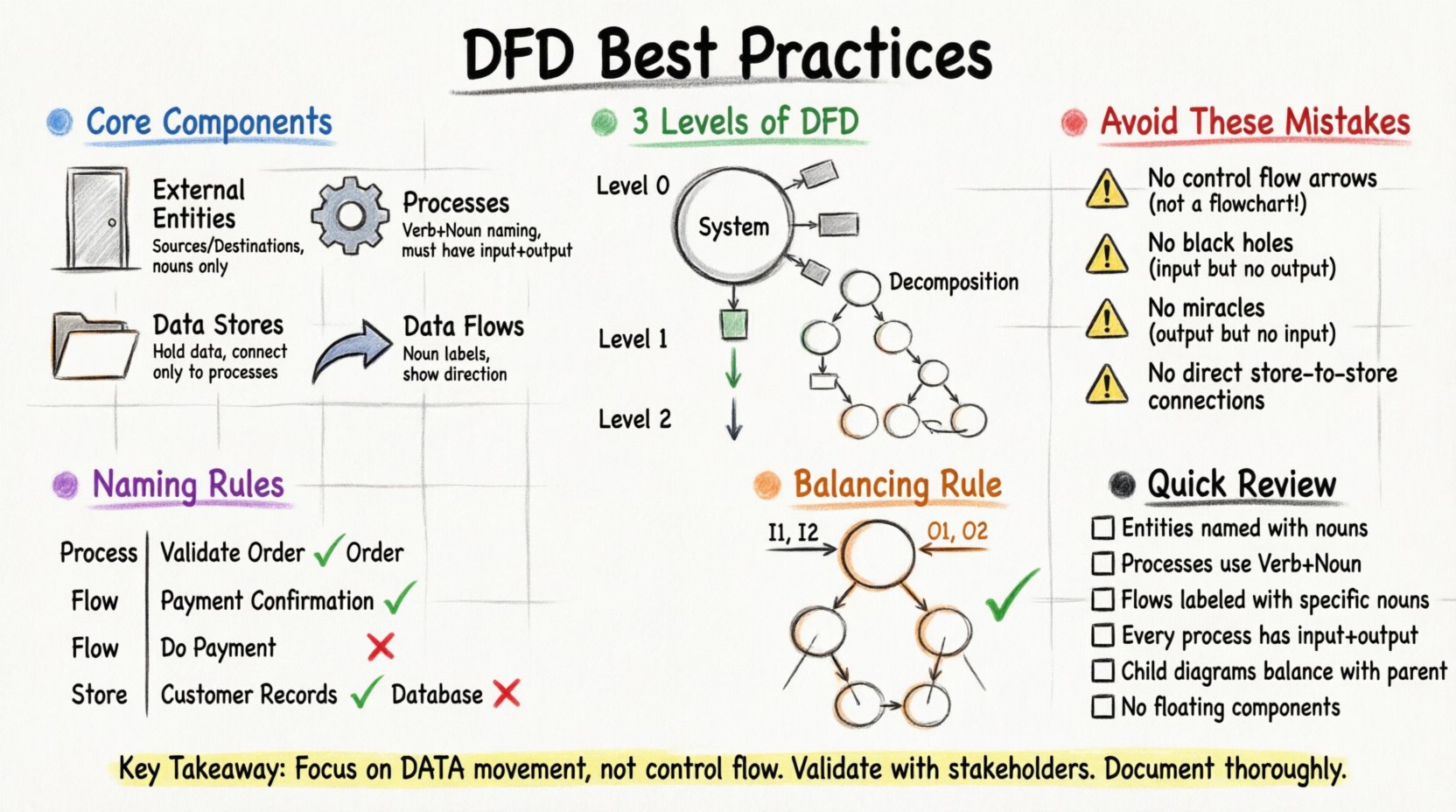
Чтобы построить точную диаграмму, необходимо освоить четыре основных символа. Каждый из них имеет строгое определение, которое необходимо соблюдать для обеспечения согласованности.
1. Внешние сущности (источники и назначения) 🚪
Они представляют людей, организации или системы, взаимодействующие с вашей системой. Это границы вашего охвата. Данные поступают от них или направляются к ним. Они не являются частью самой системы.
- Пример: Клиент, поставщик или внешний платежный шлюз.
- Правило: Не путайте пользователя внутри системы с внешней сущностью. Здесь должны быть только внешние источники или приёмники.
2. Процессы (преобразования) ⚙️
Процессы — это места, где происходят изменения данных. Они принимают входные данные, преобразуют их и выдают выходные данные. Это сердце системы. Каждый процесс должен иметь хотя бы один вход и один выход.
- Пример: Рассчитать налог, проверить вход, сгенерировать отчёт.
- Правило: Обозначайте процессы глаголами. Процесс — это действие, а не существительное.
3. Хранилища данных (репозитории) 📂
Хранилища данных хранят данные для последующего использования. Они представляют базы данных, файлы или даже физические файловые шкафы. В отличие от процессов, хранилища данных не изменяют данные — они просто хранят их.
- Пример: База данных клиентов, журнал заказов, список запасов.
- Правило: Хранилища данных должны быть подключены к процессам. Данные не могут просто появиться или исчезнуть из хранилища без процесса, который их обрабатывает.
4. Потоки данных (движение) 🔄
Это стрелки, соединяющие компоненты. Они показывают направление движения данных. Каждая стрелка должна иметь метку, описывающую точно, какие данные перемещаются.
- Пример:Сведения об заказе, подтверждение оплаты, учетные данные пользователя.
- Правило:Стрелки должны быть помечены существительными, а не глаголами. Метка описывает содержимое потока.
📉 Уровни абстракции в диаграммах потоков данных
Сложные системы нельзя показать на одной странице. Принято разбивать систему на уровни. Это называется декомпозицией.
Уровень 0: Диаграмма контекста 🌍
Диаграмма контекста — это самый высокий уровень представления. Она показывает всю систему как один элемент. Она соединяет этот единственный процесс со всеми внешними сущностями. Четко определяет границы системы.
- Фокус:Только входы и выходы.
- Детали:Минимальные. Нет внутренних процессов или хранилищ данных.
Уровень 1: Основные процессы 🔢
Уровень 1 разбивает единственный элемент диаграммы контекста на основные подпроцессы. Именно здесь начинает проявляться внутренняя логика. Обычно он содержит основные функциональные области системы.
- Фокус:Основные функциональные группы.
- Детали:Включает основные хранилища данных и потоки между основными процессами.
Уровень 2: Подробный разбор 🔍
Уровень 2 разбивает один конкретный процесс с уровня 1. Используется, когда конкретный процесс слишком сложен для понимания на уровне 1.
- Фокус:Конкретные, сложные операции.
- Детали:Высокая детализация. Показывает каждый шаг конкретной функции.
✍️ Правила именования для ясности
Именование — наиболее распространенная причина путаницы в диаграммах потоков данных. Четкие имена предотвращают недопонимание между аналитиками и разработчиками.
Имена процессов
Всегда используйте глагол, за которым следует существительное. Это описывает действие, выполняемое над данными.
- Хорошо: «Проверка входа пользователя»
- Плохо: «Вход» или «Процесс входа пользователя»
Имена потоков данных
Используйте конкретное существительное, обозначающее передаваемый пакет данных.
- Хорошо: «Проверенные учетные данные»
- Плохо: «Данные входа» или «Выполнить вход»
Имена хранилищ данных
Используйте существительное, обозначающее совокупность данных.
- Хорошо: «Учетные записи пользователей»
- Плохо: «Пользователи» или «База данных»
⚖️ Балансировка и сохранение данных
Одно из наиболее важных правил при проектировании диаграмм потоков данных — балансировка. При разбиении родительского процесса на дочерние процессы входы и выходы должны оставаться согласованными.
Что такое балансировка?
Представьте, что у вас есть процесс первого уровня под названием «Обработка заказа». Этот процесс получает «Заказ клиента» и выдает «Подтверждение отправки». Если вы разбиваете «Обработку заказа» на подпроцессы второго уровня, то в совокупности эти подпроцессы должны по-прежнему получать «Заказ клиента» и выдавать «Подтверждение отправки».
Почему это важно?
- Согласованность: Обеспечивает, что данные не теряются при разбиении.
- Следуемость: Позволяет отслеживать каждый элемент данных от верхнего уровня до нижнего.
- Проверка: Выступает в качестве проверки на отсутствие требований.
Как проверить балансировку
- Перечислите все входы и выходы родительского процесса.
- Перечислите все входы и выходы дочерних процессов.
- Сравните два списка. Они должны точно совпадать.
🚫 Распространенные ошибки, которые следует избегать
Даже опытные аналитики допускают ошибки. Избегая этих распространенных ловушек, вы значительно улучшите качество своих диаграмм.
1. Смешивание потока управления с потоком данных
DFD — это не диаграмма потоков. Не используйте стрелки для отображения последовательности событий или решений. Если принято решение, данные по-прежнему поступают в процесс, который обрабатывает результат. Стрелка обозначает данные, а не управление.
2. Чёрные дыры и чудеса
- Чёрная дыра: Процесс, имеющий входы, но не имеющий выходов. Это означает, что данные исчезают, что логически невозможно.
- Чудо: Процесс, имеющий выходы, но не имеющий входов. Это означает, что данные появляются из ниоткуда.
3. Несоединённые компоненты
Каждый компонент должен быть подключён хотя бы к одному другому компоненту через поток данных. Плавающий процесс или отключённый хранилище данных указывает на логическую ошибку.
4. Хранилища данных без процессов
Хранилища данных не могут напрямую взаимодействовать друг с другом. Между двумя хранилищами данных всегда должен быть процесс. Это гарантирует, что данные проверяются или преобразуются до их хранения или извлечения.
📋 Чек-лист проверки DFD
Используйте эту таблицу для проверки своей работы перед окончательным завершением диаграммы. Это гарантирует высокий уровень точности.
| Проверка | Критерии | Сдано/Не сдано |
|---|---|---|
| Именование сущностей | Все внешние сущности названы существительными? | ⬜ |
| Именование процессов | Все процессы названы по шаблону глагол + существительное? | ⬜ |
| Именование потоков | Все потоки данных помечены конкретными существительными? | ⬜ |
| Сохранение | Каждый процесс имеет хотя бы один вход и один выход? | ⬜ |
| Сбалансированность | Соответствуют ли дочерние диаграммы входам/выходам родительских? | ⬜ |
| Связность | Есть ли плавающие компоненты? | ⬜ |
| Хранилища данных | Хранилища данных подключены только к процессам? | ⬜ |
| Внешние сущности | Внешние сущности никогда не подключаются к другим сущностям? | ⬜ |
🔄 Логические и физические СДФ
Важно различать логический и физический взгляд на систему. Оба валидны, но служат разным целям.
Логическая СДФ
Она фокусируется на бизнес-требованиях. Она игнорирует, как система на самом деле построена. Она отвечает на вопрос «Что делает бизнес?»
- Пример: «Обработать оплату» — это процесс.
- Преимущество: Она остается актуальной даже при изменении технологии.
Физическая СДФ
Она фокусируется на реализации. Она отвечает на вопрос «Как построена система?» Включает конкретное оборудование, программные модули или ручные задачи.
- Пример: «Запустить API кредитной карты» или «Распечатать чек на лазерном принтере».
- Преимущество: Она напрямую направляет разработчиков и инженеров.
🤝 Вовлечение заинтересованных сторон
СДФ — это инструмент коммуникации. Она бесполезна, если заинтересованные стороны не понимают её или если она не отражает их реальность.
- Обходы: Планируйте сессии, в ходе которых вы пошагово проводите заинтересованные стороны через диаграмму.
- Петли обратной связи: Позвольте заинтересованным сторонам указать на отсутствующие потоки данных или неверные названия процессов.
- Валидация: Убедитесь, что диаграмма соответствует их мысленной модели того, как работает бизнес.
Когда заинтересованные стороны подтверждают диаграмму, она становится своего рода договором. Это подтверждает, что архитектура системы соответствует потребностям бизнеса. Это снижает риск повторной работы на более поздних этапах разработки.
🛠️ Обслуживание диаграмм с течением времени
Системы развиваются. Требования меняются. Диаграмма потоков данных, которая была точной вчера, может быть устаревшей сегодня. Чтобы сохранить ценность вашей документации, вы должны поддерживать её в актуальном состоянии.
- Контроль версий: Ведите записи о различных версиях диаграммы потоков данных, чтобы отслеживать изменения с течением времени.
- Триггеры обновления: Установите правила, когда диаграмма потоков данных должна обновляться (например, при запросе новой функции, изменении процесса).
- Централизованный репозиторий: Храните диаграммы в месте, доступном для всей команды.
🔎 Глубокое погружение: обработка сложных потоков данных
Иногда потоки данных бывают сложными. Они могут переносить несколько частей информации или изменяться в зависимости от условий. Вот как с этим справляться, не загромождая диаграмму.
Группировка данных
Не рисуйте стрелку для каждого отдельного поля данных. Группируйте связанные данные в логический пакет.
- Пример: Вместо того чтобы рисовать отдельные стрелки для «Имени», «Адреса» и «Телефона», нарисуйте одну стрелку с надписью «Информация о клиенте».
Условные потоки
Хотя диаграммы потоков данных обычно не показывают логику принятия решений, иногда данные передаются только при определённых условиях. Вы можете пометить стрелку, чтобы указать на это.
- Пример: Обозначьте стрелку как «Одобрённый заказ», чтобы отличить её от «Отклонённого заказа».
📝 Лучшие практики документирования
Диаграмма — это лишь часть истории. Вам необходимо документировать определения компонентов, чтобы обеспечить ясность.
- Словарь: Создайте словарь для всех терминов, используемых на диаграмме (например, что определяет «Проверенного пользователя»?).
- Описания процессов: Для сложных процессов напишите краткое описание логики, вовлечённой в них.
- Словарь данных: Определите структуру хранилищ данных и потоков.
Документация поддерживает диаграмму. Она обеспечивает необходимый контекст, который визуальные символы не могут передать. Без нее диаграмма подвержена интерпретации.
🎯 Основные выводы
Точные диаграммы потоков данных строятся на последовательности, ясности и строгом соблюдении правил. Следуя практикам, описанным здесь, вы сможете создавать диаграммы, эффективно передающие логику системы.
- Сосредоточьтесь на данных: Сохраняйте фокус на перемещении данных, а не на потоке управления.
- Используйте единообразные имена:Глаголы для процессов, существительные для данных.
- Тщательно декомпозируйте: Поддерживайте баланс между уровнями.
- Проверьте с заинтересованными сторонами: Убедитесь, что модель отражает реальность.
- Детально документируйте: Предоставьте контекст вместе с визуальными элементами.
Вложение времени в создание точных диаграмм потоков данных окупается меньшим количеством ошибок при разработке и более четкой коммуникацией. Это закладывает прочную основу для любого проекта анализа системы.