











Projektowanie systemów zarządzających danymi to skomplikowane przedsięwzięcie. Gdy projekty rosną z małych skryptów do platform o poziomie przedsiębiorstwa, dokumentacja opisująca sposób przepływu informacji przez architekturę musi się rozwijać. Diagramy przepływu danych (DFD) pełnią rolę projektów architektonicznych dla tych systemów. Wizualizują przepływ danych między procesami, magazynami danych i zewnętrznymi jednostkami. Jednak diagram, który działa dla prostego aplikacji, często zawala się pod ciężarem dużego projektu. Skalowanie DFD wymaga dyscyplinowanego podejścia do hierarchii, dekompozycji i utrzymania. Ten przewodnik bada strategie niezbędne do utrzymania przejrzystości, dokładności i użyteczności dokumentacji przepływu danych w miarę wzrostu złożoności.
Przejście od małego zakresu do środowiska o dużym zasięgu wprowadza wyzwania, które nie mogą być rozwiązane poprzez po prostu dodanie więcej pudełek i strzałek. Bez strukturalnej metodyki diagramy stają się nieczytelne sieci połączeń. Powoduje to zamieszanie wśród stakeholderów, programistów i architektów. Aby zachować przejrzystość, zespoły muszą przyjąć konkretne wzorce organizacji. Przeanalizujemy mechanizmy skalowania, od poziomu kontekstu po szczegółowe rozkładanie procesów. Omówimy również sposób zarządzania magazynami danych i granicami zewnętrznymi bez utraty ogólnego obrazu.
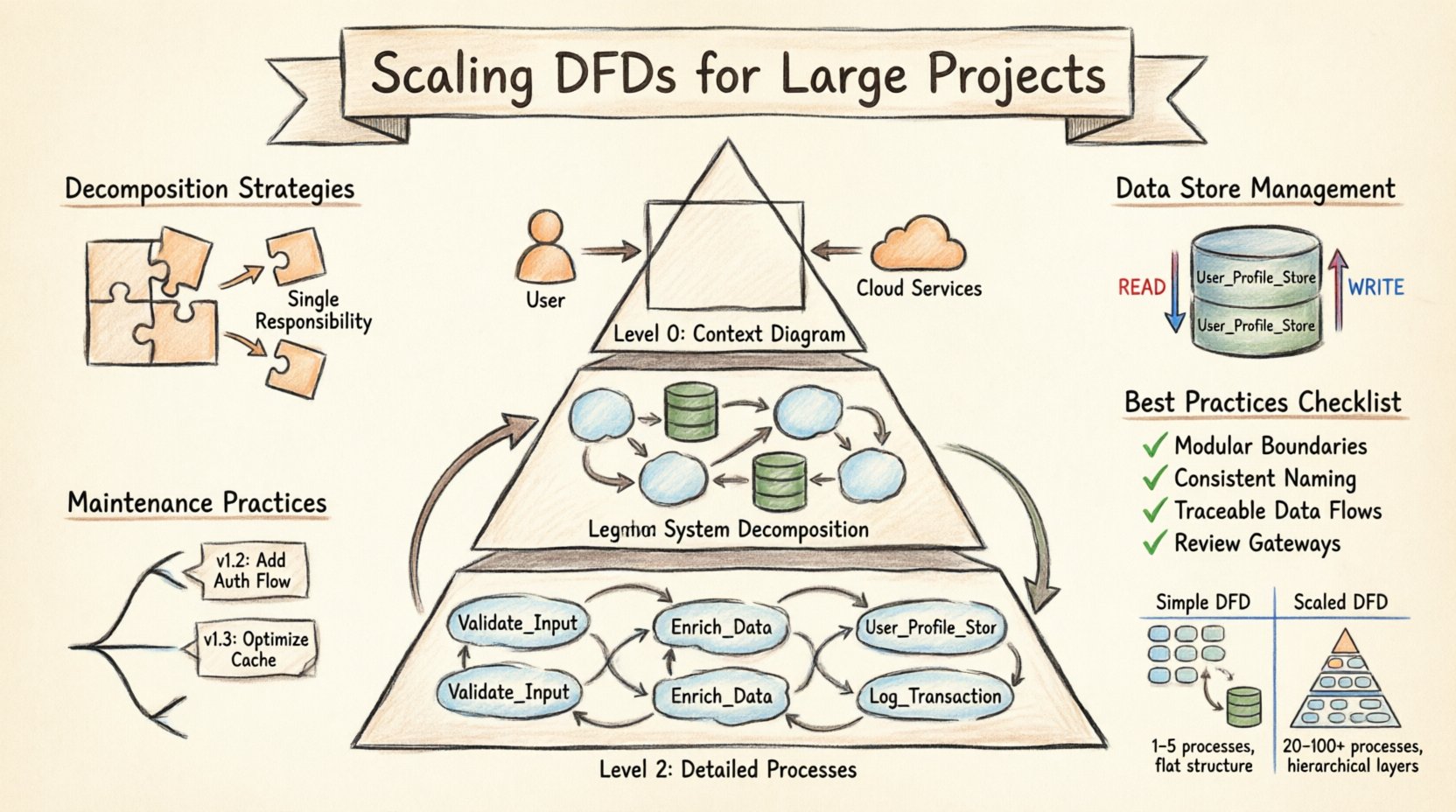
Zrozumienie hierarchii DFD 📚
Podstawą skalowania jest struktura hierarchiczna samego diagramu. Jedno, płaskie diagramy rzadko są wystarczające dla dużych systemów. Zamiast tego, podejście wielopoziomowe pozwala stakeholderom oglądać system na różnych poziomach szczegółowości. Ten sposób często nazywa się strukturą poziomu 0, poziomu 1, poziomu 2. Każdy poziom służy określonej grupie odbiorców i ma swoje zadanie.
- Poziom 0 (Diagram kontekstowy): Jest to najwyższy poziom widoku. Pokazuje cały system jako pojedynczy proces. Łączy system z jednostkami zewnętrznymi, takimi jak użytkownicy, usługi trzecich stron lub sprzęt. Celem jest zdefiniowanie granic systemu oraz głównych wejść i wyjść. Nie powinien zawierać procesów wewnętrznych ani magazynów danych.
- Poziom 1 (Rozkład systemu): Ten poziom rozdziela pojedynczy proces z poziomu 0 na główne podprocesy. Wprowadza magazyny danych i pokazuje, jak dane przepływają między głównymi obszarami funkcjonalnymi. To właśnie tutaj staje się widoczna architektura rdzeniowa. Zazwyczaj używany jest przez architektów systemów i starszych programistów.
- Poziom 2 (Szczegółowe procesy): Każdy główny proces z poziomu 1 jest rozszerzany na osobny diagram. Ten poziom szczegółowo opisuje logikę, konkretne przekształcenia danych oraz interakcje z magazynami danych. Używany jest przez osoby implementujące i testujące, które potrzebują zrozumienia szczegółów działania funkcji.
Podczas skalowania relacje między tymi poziomami muszą być utrzymywane z dużą precyzją. Każde wejście i wyjście na diagramie poziomu 0 musi być uwzględnione na poziomie 1. Każdy przepływ danych opuszczający proces poziomu 1 musi zostać wyjaśniony na odpowiadającym diagramie poziomu 2. Ta spójność zapobiega utracie informacji i zapewnia śledzenie. Jeśli przepływ danych pojawia się na diagramie niższego poziomu, ale nie na wyższym, oznacza to rozbieżność, którą należy rozwiązać.
Strategie dekompozycji dla złożoności 🔨
Dekompozycja to działanie polegające na rozkładaniu skomplikowanych procesów na mniejsze, zarządzalne elementy. W projektach o dużym zasięgu nie chodzi tylko o uproszczenie, ale o zarządzanie obciążeniem poznawczym. Proces obsługujący zbyt wiele różnych funkcji staje się węzłem przepływu rozumienia. Skuteczna dekompozycja podlega określonym zasadom, aby zapewnić użyteczność diagramu.
- Jedna funkcja na proces: Każdy balon lub prostokąt procesu powinien reprezentować pojedyncze, wyraźne przekształcenie danych. Jeśli proces obsługuje zarówno walidację danych, jak i ich przechowywanie, powinien zostać podzielony. Ta separacja jasno określa odpowiedzialność każdego składnika.
- Spójna szczegółowość: Choć poziomy różnią się szczegółowością, szczegółowość w ramach jednego poziomu powinna być spójna. Jeśli jeden proces jest bardzo szczegółowy, sąsiednie procesy nie powinny być nieprecyzyjnymi podsumowaniami. Ta równowaga zapobiega nierównościom i zamieszaniu na diagramie.
- Logiczne grupowanie: Łącz procesy powiązane wizualnie lub według konwencji nazewnictwa. Pomaga to czytelnikowi zidentyfikować domeny funkcjonalne, takie jak „Uwierzytelnianie”, „Faktury” lub „Raportowanie”. Logiczne grupowanie zmniejsza potrzebę śledzenia linii na całym ekranie.
- Unikanie przenikania między poziomami: Nie wprowadzaj szczegółów na wyższym poziomie diagramu, które należą do niższego poziomu. Z kolei nie pomijaj kluczowych magazynów danych na diagramie poziomu 1, które są niezbędne do zrozumienia stanu systemu.
Podczas skalowania często napotykamy procesy, które nie mieszczą się wyraźnie w jednej kategorii. W takich przypadkach proces może wymagać podziału na równoległe strumienie lub obsługi poprzez dedykowaną warstwę interfejsu. Celem jest utrzymanie liniowego i logicznego przepływu. Jeśli proces wymaga danych z pięciu różnych źródeł i wysyła wyniki do trzech różnych miejsc docelowych, jest prawdopodobnie zbyt złożony, by mieścić się w jednym polu. Rozbicie go na kroki pośrednie jasno ujawnia sekwencję operacji.
Zarządzanie magazynami danych w skali 🗄️
Magazyny danych reprezentują stały stan systemu. W małych projektach pojedyncza baza danych może służyć całej aplikacji. W projektach o dużym zasięgu dane są rozprowadzane między wieloma systemami, schematami i usługami. Dokładne mapowanie tych magazynów na DFD ma kluczowe znaczenie dla zrozumienia integralności danych i wzorców dostępu.
- Jasne nazewnictwo: Nie oznaczaj magazynu danych po prostu jako „Baza danych”. Używaj konkretnych nazw, takich jak „Magazyn_Profilu_Użytkownika” lub „Dziennik_Transakcji”. Ta szczegółowość pomaga programistom zidentyfikować, który system przechowuje które dane.
- Przepływy odczytu vs. zapisu: Wskaż, gdzie dane są odczytywane, a gdzie zapisywane. Choć DFD tradycyjnie pokazują przepływ danych bez kierunkowości, skalowanie wymaga jasności co do zmian stanu. Używaj różnych oznaczeń lub legend, aby pokazać, czy proces aktualizuje magazyn, czy tylko go zapytuje.
- Współdzielone magazyny danych: Duże systemy często współdzielą magazyny danych między procesami. Upewnij się, że schemat odzwierciedla, które procesy mają dostęp do których magazynów. Pomaga to wykryć potencjalne problemy współbieżności lub luki bezpieczeństwa.
- Związki między magazynami danych: Jeśli dane przepływają z jednego magazynu do drugiego, pokaż to wyraźnie. Może to wskazywać na proces replikacji, zadanie ETL lub procedurę synchronizacji. Te przepływy często są pomijane, ale są kluczowe dla niezawodności systemu.
Wraz ze wzrostem liczby magazynów danych schemat może stać się zatłoczony. Aby temu zapobiec, rozważ użycie technik grupowania. Zgrupuj powiązane magazyny danych w obrębie granicy reprezentującej określony podsystem. Zmniejsza to zanieczyszczenie wizualne, zachowując przy tym połączenia logiczne. Jednak uważaj, aby nie zakryć przepływu danych między tymi grupami. Połączenia muszą być widoczne, aby cała wizja była zrozumiała.
Granice jednostek zewnętrznych 🌐
Jednostki zewnętrzne reprezentują źródła i miejsca docelowe danych poza granicami systemu. Mogą to być ludzie, inne systemy oprogramowania, starsze mainframe’y lub organy regulacyjne. W dużych projektach liczba jednostek zewnętrznych może znacznie wzrosnąć. Zarządzanie tymi granicami jest kluczowe do określenia zakresu projektu.
- Zdefiniuj jasne interfejsy: Każde połączenie między jednostką zewnętrzną a procesem reprezentuje interfejs. Dokumentuj oczekiwany format i protokół tych interakcji. Pomaga to uniknąć niejasności podczas integracji z systemami trzecimi.
- Zgrupuj podobne jednostki: Jeśli wielu użytkowników wykonuje tę samą funkcję, przedstaw ich jako jedną ogólną jednostkę (np. „Klient”) z notatką wyjaśniającą różnice w rolach. Zmniejsza to nadmiarowość bez utraty funkcjonalności.
- Skutki bezpieczeństwa: Jednostki zewnętrzne często reprezentują granice bezpieczeństwa. Dane przepływające z jednostki zewnętrznej do systemu mogą wymagać uwierzytelnienia lub szyfrowania. Schemat DFD powinien idealnie zaznaczać te wymagania bezpieczeństwa, albo w tekście, albo za pomocą legendy.
- Stare systemy: Duże projekty często współpracują ze starymi systemami. Te jednostki mogą mieć sztywne formaty danych. Dokładnie zmapuj te interakcje, aby upewnić się, że nowy system poprawnie obsługuje dane bez naruszania istniejących przepływów pracy.
Podczas skalowania łatwo jest zignorować małe jednostki zewnętrzne. Jednak nawet małe wejścia mogą mieć istotne skutki w dalszej części systemu. Zmiana sposobu, w jaki mała jednostka przesyła dane, może się rozprzestrzenić na cały system. Dlatego wszystkie jednostki muszą być uwzględnione na diagramie kontekstowym i śledzone na poziomach dekompozycji.
Utrzymanie i kontrola wersji 🔄
Schemat DFD to dokument żywy. W dużych projektach wymagania często się zmieniają. Dodawane są procesy, łączone są magazyny danych, a interfejsy zewnętrzne są wycofywane. Bez solidnej strategii utrzymania schemat szybko się wygrywa, co prowadzi do rozbieżności między dokumentacją a kodem.
- Wersjonowanie: Przypisz numery wersji do schematów. Pozwala to zespołom śledzić zmiany w czasie. Jeśli zgłoszony zostanie błąd, możesz odnieść się do konkretnej wersji schematu, która była obowiązująca w momencie pisania kodu.
- Dzienniki zmian: Utrzymuj osobisty dziennik opisujący zmiany między wersjami. Zawieraj datę, autora oraz powód zmiany. To zapewnia kontekst dla przyszłych programistów, którzy mogą nie pamiętać, dlaczego podjęto daną decyzję.
- Cykle przeglądu: Zaprojektuj regularne przeglądy schematów DFD. Powinny one pokrywać się z głównymi cyklami wydania. Podczas przeglądów sprawdź, czy schematy odpowiadają bieżącej implementacji. Natychmiast je uaktualnij, jeśli zostaną znalezione rozbieżności.
- Kontrola dostępu: Upewnij się, że tylko uprawniony personel może modyfikować schematy. Niekontrolowane zmiany mogą prowadzić do konfliktów i zamieszania. Używaj systemu, który śledzi, kto dokonał zmian i kiedy.
Utrzymanie często jest pomijane na rzecz rozwoju. Jednak przestarzałe schematy są bardziej niebezpieczne niż brak schematów. Tworzą fałszywe poczucie bezpieczeństwa. Zespoły mogą polegać na dokumentacji, która nie odzwierciedla rzeczywistości. Traktując schemat DFD jak kod, podlegający tym samym procesom kontroli wersji i przeglądów, zespoły mogą zapewnić jego poprawność.
Porównanie: skalowane vs. proste schematy DFD 📊
Zrozumienie różnic między prostym schematem DFD a skalowanym DFD pomaga zespołom przygotować się na przejście. Poniższa tabela przedstawia kluczowe różnice pod względem struktury, złożoności i zarządzania.
| Cecha | Prosty DFD | Skalowany DFD |
|---|---|---|
| Liczba procesów | 1 do 5 | 20 do 100+ |
| Poziomy | 1 (Płaski) | 3 do 5 (Hierarchiczny) |
| Używane narzędzia | Ołówek i papier | Specjalistyczny oprogramowanie do rysowania schematów |
| Kontrola wersji | Ręczna | Systemy automatyczne |
| Częstotliwość przeglądu | W momencie dostarczenia | Na każdy sprint/wydanie |
| Szczegóły magazynu danych | Ogólne | Szczegółowe i nazwane |
| Zewnętrzne jednostki | Minimalne | Kompleksowe i kategoryzowane |
Najlepsze praktyki dotyczące jakości dokumentacji ✅
Aby zapewnić, że DFD pozostaje wartościowym aktywem, stosuj te najlepsze praktyki. Te wytyczne skupiają się na przejrzystości, spójności i użyteczności.
- Spójne zasady nazewnictwa: Używaj standardowego formatu do nadawania nazw procesom, przepływom danych i magazynom. Na przykład używaj „czasownik-przysłówek” dla procesów (np. „Oblicz podatek”). Dzięki temu schemat staje się czytelny i łatwy do wyszukiwania.
- Minimalizuj przecięcia linii: Ułóż schemat w taki sposób, aby zmniejszyć liczbę przecięć linii. Poprawia to płynność wizualną i zmniejsza wysiłek poznawczy potrzebny do śledzenia ścieżek danych.
- Używaj legend i kluczy: Jeśli używasz specjalnych symboli do oznaczania zabezpieczeń, typów danych lub systemów zewnętrznych, podaj legendę. Nie zakładaj, że czytelnik zna znaczenie każdego symbolu.
- Link do specyfikacji: Gdzie to możliwe, połącz diagram z szczegółowymi dokumentami wymagań lub repozytoriami kodu. Dzięki temu powstaje most między widokiem ogólnym a szczegółami implementacji.
- Utrzymuj aktualność: Najpierw dbaj o dokładność diagramu, a potem o jego wygląd. Diagram nieco nieporządkowy, ale dokładny, jest bardziej przydatny niż wygładzony, ale przestarzały.
Integracja z inną dokumentacją 📝
Diagram przepływu danych nie istnieje samodzielnie. Jest częścią większego ekosystemu dokumentacji technicznej. Aby maksymalnie zwiększyć jego wartość, musi być zintegrowany z innymi artefaktami.
- Schemat bazy danych: Magazyny danych w DFD powinny odpowiadać bezpośrednio schematowi bazy danych. Zapewnia to, że implementacja fizyczna odpowiada projektowi logicznemu.
- Specyfikacje API: Przepływy między zewnętrznymi jednostkami a procesami często odpowiadają punktom końcowym API. Przyporządkowanie tych dokumentów pomaga zweryfikować punkty integracji.
- Polityki bezpieczeństwa: Przepływy danych zawierające poufne informacje powinny być przyporządkowane politykom bezpieczeństwa. Zapewnia to spełnienie wymagań dotyczących szyfrowania i kontroli dostępu.
- Przypadki testowe: Przypadki testowe powinny być wyprowadzone z przepływów danych. Każdy przepływ reprezentuje potencjalną ścieżkę testową. Zapewnia to kompleksowe pokrycie logiki systemu.
Typowe pułapki do uniknięcia ⚠️
Nawet z najlepszymi intencjami zespoły mogą popełniać błędy przy skalowaniu DFD. Znajomość tych pułapek pomaga uniknąć typowych pułapek.
- Zbyt duża złożoność: Nie twórz diagramu zbyt szczegółowego dla danego poziomu. Diagram poziomu 1 nie powinien zawierać logiki procesu poziomu 2. Zachowaj odpowiedni poziom abstrakcji.
- Ignorowanie przepływów sterujących: Choć DFD skupia się na danych, sygnały sterujące (takie jak „Start”, „Stop”, „Błąd”) są często potrzebne w złożonych systemach. Jasno rozróżnij je od przepływów danych.
- Zakładanie liniowości: Systemy rzadko są liniowe. Pętle, mechanizmy sprzężenia zwrotnego i zdarzenia asynchroniczne są powszechne. Dokładnie przedstawiaj je, nawet jeśli utrudnia to odczyt diagramu.
- Brak standaryzacji: Jeśli różne członkowie zespołu rysują diagramy w różnych stylach, cała dokumentacja staje się rozdrobniona. Ustal wczesny przewodnik stylu i go stosuj.
Wnioski dotyczące skalowalności 🏗️
Skalowanie diagramów przepływu danych to konieczna dyscyplina budowania odpornych, dużych systemów. Wymaga to więcej niż tylko rysowanie większej liczby pól; wymaga strukturalnego podejścia do hierarchii, dekompozycji i utrzymania. Przestrzegając strategii przedstawionych w tym poradniku, zespoły mogą tworzyć dokumentację wspierającą rozwój bez stawania się obciążeniem. Celem jest przejrzystość. Gdy diagram jest przejrzysty, system jest łatwiejszy do zrozumienia, utrzymania i rozszerzania. Ta inwestycja w dokumentację przynosi korzyści w postaci zmniejszenia błędów i szybszego włączania nowych członków zespołu.
Pamiętaj, że diagram to narzędzie komunikacji, a nie tylko artefakt techniczny. Łączy lukę między wymaganiami biznesowymi a implementacją techniczną. W miarę jak system rośnie, musi rosnąć również dokumentacja. Regularne przeglądy i ścisła kontrola wersji zapewniają, że DFD pozostaje wiarygodnym źródłem prawdy przez cały cykl życia projektu. Poprawne podejście sprawia, że skalowanie DFD staje się zarządzalnym zadaniem, a nie chaotycznym przedsięwzięciem.