











Projektowanie modeli danych dla nowoczesnej infrastruktury wymaga podstawowej zmiany podejścia. Tradycyjne diagramy relacji encji (ERD) dobrze sprawdzały się w architekturach monolitycznych, gdzie pojedynczy egzemplarz bazy danych zarządzał wszystkimi transakcjami. Jednak w miarę jak systemy ewoluują w kierunku środowisk rozproszonych, zasady integralności danych i mapowania relacji ulegają istotnej zmianie. Niniejszy przewodnik omawia zaawansowane wzorce diagramów ERD dostosowane specjalnie do złożonych systemów transakcji rozproszonych. Przeanalizujemy, jak modelować spójność, zarządzać stanem między usługami oraz wizualizować zależności bez odwoływania się do konkretnych produktów oprogramowania.
W kontekście rozproszonym granica między własnością danych staje się płynna. Encja może istnieć w wielu magazynach logicznych, co wymaga jasnego określenia sposobu utrzymania relacji. Niniejszy dokument przedstawia strukturalny sposób modelowania tych złożoności.
🧠 Wpływ architektury rozproszonej na modelowanie danych
Zanim przejdziemy do konkretnych wzorców, konieczne jest zrozumienie ograniczeń wynikających z granic sieciowych. W architekturze monolitycznej ograniczenie klucza obcego gwarantuje integralność referencyjną. W systemie rozproszonym opóźnienia sieciowe i potencjalne podziały sieci oznaczają, że natychmiastowa spójność jest często niemożliwa lub niezwykle kosztowna.
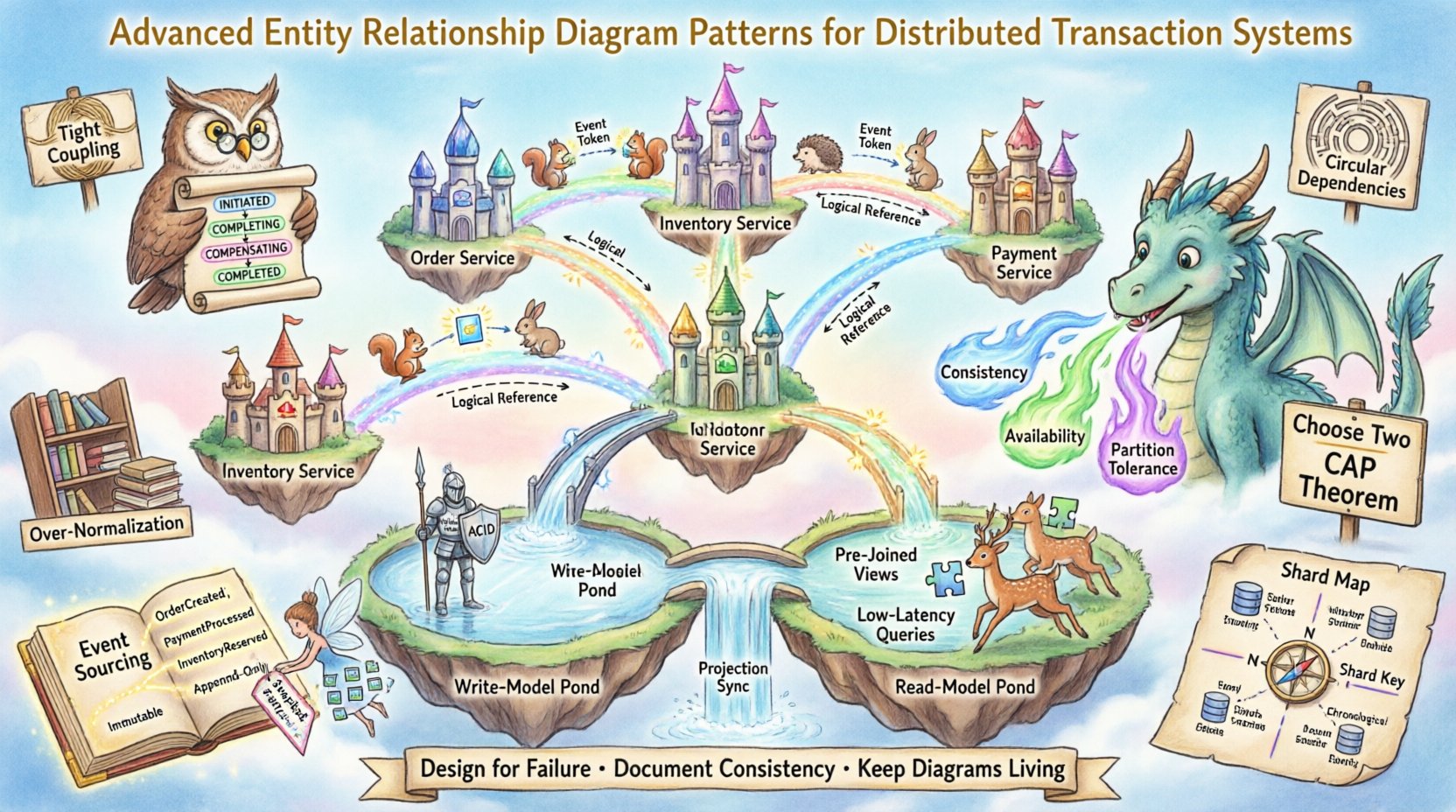
- Podziały sieciowe: Twierdzenie CAP mówi, że w przypadku podziału sieci musisz wybrać między Spójnością a Dostępną.
- Własność danych: Usługi muszą posiadać własne dane, aby uniknąć silnego powiązania. Ogranicza to bezpośrednie relacje kluczy obcych przez granice usług.
- Granice transakcji: Transakcje globalne obejmujące wiele baz danych są zazwyczaj niepolecane z powodu ryzyka wydajności i niezawodności.
Podczas tworzenia diagramu ERD w tym środowisku, diagram musi odzwierciedlać relacje logiczne, a nie tylko ograniczenia fizyczne. Wizualna reprezentacja musi przekazywać, gdzie znajdują się dane i jak są zsynchronizowane.
🔗 Zarządzanie integralnością referencyjną bez kluczy obcych
W systemie transakcji rozproszonej fizyczne klucze obce są często nieobecne. Zamiast tego relacje logiczne są wymuszane przez logikę aplikacji lub zdarzenia asynchroniczne. Diagram ERD musi jasno odzwierciedlać te relacje logiczne.
1. Odwołania do identyfikatorów logicznych
Zamiast ograniczenia klucza fizycznego modele używają unikalnych identyfikatorów. Podczas rysowania diagramu należy wskazać, że relacja jest połączeniem logicznym.
- Użyj linii przerywanych do przedstawienia zależności logicznych.
- Oznacz relację jako „Odwołanie”, a nie „Ograniczenie”.
- Określ typ danych identyfikatora, aby zapewnić bezpieczeństwo typów w schemacie.
2. Miękkie odwoływanie
Twarda usunięcie jest ryzykowne w systemach rozproszonych. Powszechnym wzorcem jest oznaczanie rekordów jako usuniętych zamiast ich usuwania. Diagram ERD powinien zawierać pole statusu.
- Uwzględnij pole
is_activelubstatuskolumnę. - Zarejestruj cykl życia encji w notatkach do diagramu.
- Ujednolit, jak są obsługiwane zaniedbane rekordy podczas zdarzenia usunięcia.
3. Modelowanie spójności ostatecznej
Gdy dane są replikowane między usługami, spójność nie jest natychmiastowa. Diagram ERD powinien wizualizować opóźnienie replikacji.
- Zaznacz encje, które są kopiami tylko do odczytu.
- Rozróżnij „Źródło prawdy” i „Wersję tymczasową”.
- Wskazuje mechanizm używany do synchronizacji zmian (np. przechwytywanie zmian danych).
⚡ Modelowanie wzorca Saga
Wzorzec Saga jest fundamentem transakcji rozproszonych. Zarządza długotrwałymi operacjami, dzieląc transakcję na sekwencję lokalnych transakcji. Każda lokalna transakcja aktualizuje dane w określonym serwisie i uruchamia następny krok.
1. Reprezentacja maszyn stanów
Ponieważ Saga opiera się na stanie, ERD musi jawnie modelować przejścia stanów procesu.
- Utwórz encję
SagaInstanceencji. - Zdefiniuj stany takie jak
INICJOWANY,KOŃCZONY,KOMPENSOWANY, orazZAKOŃCZONY. - Połącz instancję Saga z konkretnymi encjami biznesowymi, które wpływają.
2. Transakcje kompensacyjne
Jeśli krok nie powiedzie się, Saga musi cofnąć poprzednie kroki. Diagram powinien pokazywać relacje odwrotne.
- Zarejestruj działanie kompensacyjne dla każdego kroku.
- Upewnij się, że tabela
SagaLogzapisuje historię wszystkich kroków. - Wizualizuj ścieżkę cofnięcia jako osobną linię relacji.
3. Wyzwalacze zdarzeń
Saga są często wyzwalane zdarzeniami. ERD musi pokazywać, jak zdarzenia wywołują zmiany stanu.
- Uwzględnij
Dziennik zdarzeńtabela. - Przypisz zdarzenia do określonych przejść stanów Saga.
- Wskazuje, które usługi zużywają które zdarzenia.
📊 Porównanie wzorców spójności
Zrozumienie kompromisów między różnymi modelami spójności jest kluczowe dla poprawnego projektowania ERD. Poniższa tabela przedstawia cechy typowych wzorców.
| Wzorzec | Poziom spójności | Złożoność ERD | Najlepsze zastosowanie |
|---|---|---|---|
| Zaawansowane zatwierdzanie w dwóch fazach | Silna | Niska | Koordynacja wewnętrznych usług |
| Orkiestracja Saga | Ostateczna | Wysoka | Długotrwałe procesy biznesowe |
| Choreografia Saga | Ostateczna | Średnia | Słabo powiązane mikrousługi |
| Model odczytu CQRS | Ostateczna | Średnia | Wysokie obciążenia odczytu |
| Źródło zdarzeń | Silna (na agregat) | Wysoka | Ślady audytu i odtwarzanie stanu |
🔄 Separacja odpowiedzialności polegająca na rozdzielaniu poleceń i zapytań (CQRS)
CQRS rozdziela modele odczytu i zapisu. Oznacza to, że ERD dla strony zapisu będzie znacznie różnić się od ERD dla strony odczytu.
1. Projektowanie modelu zapisu
Model zapisu skupia się na integralności danych i zasadach biznesowych.
- Normalizuj dane, aby zmniejszyć nadmiarowość.
- Wymuszaj surowe zasady walidacji podczas tworzenia.
- Utrzymuj schemat sztywny, aby zapobiec błędom logicznym.
2. Projektowanie modelu odczytu
Model odczytu skupia się na wydajności i szybkości zapytań.
- Dekomponuj dane, aby uniknąć łączeń.
- Dołącz pola z wcześniej połączonymi danymi dla typowych zapytań.
- Strukturyzuj tabele na podstawie wymagań interfejsu użytkownika, a nie logiki.
3. Mechanizm synchronizacji
ERD musi pokazywać, jak model zapisu aktualizuje model odczytu.
- Użyj jednostek projektowania, aby odwzorować przepływ.
- Zarejestruj opóźnienie między dostępnością zapisu a odczytem.
- Zawrzyj proces reconciliacji dla rozbieżności danych.
🗂️ Fragmentacja i klucze partycji
Skalowanie często wymaga fragmentacji danych na wielu węzłach. ERD musi odzwierciedlać sposób dystrybucji danych, aby zapewnić skuteczne zapytania.
1. Identyfikacja klucza fragmentacji
Klucz fragmentacji określa, który węzeł przechowuje dane.
- Jasno zaznacz klucz fragmentacji w definicji jednostki.
- Upewnij się, że klucz jest często używany w zapytaniach.
- Unikaj kluczy prowadzących do nieregularnej dystrybucji danych.
2. Relacje między fragmentami
Relacje obejmujące wiele fragmentów są kosztowne. ERD powinien je wyróżnić.
- Użyj specjalnej notacji dla połączeń między fragmentami.
- Zminimalizuj liczbę relacji przekraczających granice fragmentów.
- Rozważ dekompozycję, aby uniknąć łączeń między fragmentami.
3. Indeksy globalne vs. lokalne
Strategie indeksowania różnią się w zależności od modelu shardowania.
- Indeksy lokalne są wydajne dla zapytań dotyczących pojedynczego shardu.
- Indeksy globalne wymagają skanowania wszystkich shardów, co wpływa na wydajność.
- Zarejestruj, które indeksy są lokalne, a które globalne.
📜 Źródło zdarzeń i stan niezmienialny
Źródło zdarzeń przechowuje stan jednostki jako sekwencję zdarzeń. To zmienia sposób, w jaki ERD reprezentuje samą jednostkę.
1. Magazyn zdarzeń
Główna jednostka staje się dziennikiem zdarzeń.
- Utwórz tabelę
EventStreamtabelę. - Przechowuj metadane takie jak
event_id,timestamp, orazaggregate_id. - Upewnij się, że ładunek jest przechowywany jako dane strukturalne.
2. Agregaty
Agregaty to jednostki główne, które wywołują zdarzenia.
- Powiąż identyfikator agregatu z strumieniem zdarzeń.
- Nie przechowuj bieżącego stanu jako kolumny.
- Odtwórz stan przez ponowne odtworzenie zdarzeń z dziennika.
3. Zrzuty stanu
Aby zoptymalizować wydajność, można przechowywać zrzuty bieżącego stanu.
- Utwórz tabelę
Snapshottabelę. - Powiąż zrzut z identyfikatorem agregatu.
- Zarejestruj numer wersji dla zrzutu.
🛡️ Powszechne pułapki i wzorce niepożądane
Nawet przy zaawansowanych wzorach mogą występować błędy. Rozpoznawanie wzorców niepożądanych pomaga utrzymać zdrowie systemu.
- Zbyt silna zależność:Unikaj bezpośredniego odwoływania się do encji z innych usług. Używaj identyfikatorów zamiast tego.
- Zależności cykliczne:Upewnij się, że encja A nie zależy od encji B, jeśli encja B zależy od encji A.
- Zbyt duża normalizacja:W systemach o dużym obciążeniu odczytu, nadmierna normalizacja prowadzi do pogorszenia wydajności.
- Ignorowanie stref czasowych:Systemy rozproszone działają globalnie. Przechowuj znaczniki czasu w formacie UTC.
- Brak idempotentności:Upewnij się, że operacje mogą być ponownie wykonywane bez skutków ubocznych.
🔄 Ewolucja schematu i wersjonowanie
Systemy rozproszone ewoluują szybciej niż monolity. ERD musi wspierać zmiany schematu bez niszczenia istniejących usług.
1. Zgodność wsteczna
Zmiany w schemacie nie mogą naruszać klientów.
- Dodawaj tylko pola, nigdy nie usuwaj ani nie zmieniaj nazw istniejących pól od razu.
- Stopniowo wycofuj pola w czasie.
- Wersjonuj kontrakty interfejsu API razem ze schematem.
2. Strategie migracji
Obsługa migracji danych w środowisku produkcyjnym wymaga ostrożności.
- Używaj wzorców rozszerzania i zwężania podczas wdrażania.
- Upewnij się, że stary schemat pozostaje czytelny podczas przejścia.
- Zarejestruj plan cofnięcia migracji w przypadku niepowodzenia.
🖼️ Wizualizacja zależności między usługami
Standardowy ERD pokazuje tabele w jednej bazie danych. ERD rozproszony musi pokazywać usługi.
1. Granice usług
Grupuj tabele według usługi, która je obsługuje.
- Używaj odrębnych kontenerów dla każdej usługi.
- Oznacz kontener nazwą usługi.
- Pokaż przepływ danych między kontenerami za pomocą strzałek.
2. Przepływ danych
Wskazuje, jak dane poruszają się między usługami.
- Użyj linii ciągłych do wywołań synchronicznych.
- Użyj linii przerywanych do zdarzeń asynchronicznych.
- Oznacz kierunek przepływu danych.
3. Punkty integracji
Zidentyfikuj miejsca, w których usługi się wzajemnie oddziałują.
- Wyróżnij bramy interfejsów API na diagramie.
- Zaznacz brokery komunikatów jako pośredników.
- Zarejestruj protokół używany do każdej integracji.
🏁 Ostateczne rozważania dla projektantów systemów
Projektowanie dla transakcji rozproszonych to ćwiczenie w zarządzaniu złożonością. ERD to narzędzie do przekazywania tej złożoności zespołowi. Nie powinno ono pokazywać tylko tabel; powinno pokazywać logikę systemu.
- Skup się na relacjach logicznych zamiast na ograniczeniach fizycznych.
- Zarejestruj gwarancje spójności dla każdej relacji.
- Zaplanuj scenariusze awarii w modelu danych.
- Utrzymuj diagram aktualny wraz z rozwojem systemu.
Śledząc te wzorce, tworzysz projekt wspierający wysoką dostępność i integralność danych. Diagram staje się żyjącym dokumentem, który kieruje rozwojem i utrzymaniem systemu.