











ソフトウェアアーキテクチャを設計するには正確さが求められます。システムが規模と複雑性を増すと、データの動きを理解することが不可欠になります。データフローダイアグラム(DFD)は、システム内の情報の流れを可視化するための視覚的言語です。単なる図面ではなく、論理と相互作用のための設計図です。複数のサービス、データベース、外部インターフェースを含む複雑な環境では、明確さが最も重要な目標です。
このガイドでは、正確な図を構築するための手法を詳述します。構造的要素、詳細の階層、可読性を損なわずに複雑さを管理するための戦略を網羅しています。これらの原則に従うことで、チームはすべての関係者がデータの移動や変換に関するシステムの挙動を理解できることを保証できます。
🧱 基礎の理解
データフローダイアグラムは、データの流れを表現する構造化された手法です。フローチャートが制御の流れや判断ポイントを示すのに対し、DFDはデータに焦点を当てます。データがシステムに入力される方法、処理される方法、保存される場所、そして出力される方法を描写します。この違いは、システムアナリストや開発者にとって極めて重要です。
複雑なシステムでは、データの量が非常に多くなります。その経路はしばしば非線形です。明確な地図がなければ、仮定が実装の誤りを招きます。適切に構築されたDFDは、唯一の真実の源となります。ビジネスアナリスト、エンジニア、QAスペシャリストの期待を一致させます。
- データに注目する:タイミングや論理の分岐ではなく、情報を追跡する。
- プロセス中心:図をデータの変換を中心に構成する。
- 外部コンテキスト:システムの境界内にあるものと外にあるものを明確に定義する。
分散ネットワークやマイクロサービスのような複雑なアーキテクチャを構築する際には、図は並行処理や状態を扱えるようにしなければなりません。単に線形の経路を示すのではなく、データが存在し、移動するエコシステムを描くべきです。
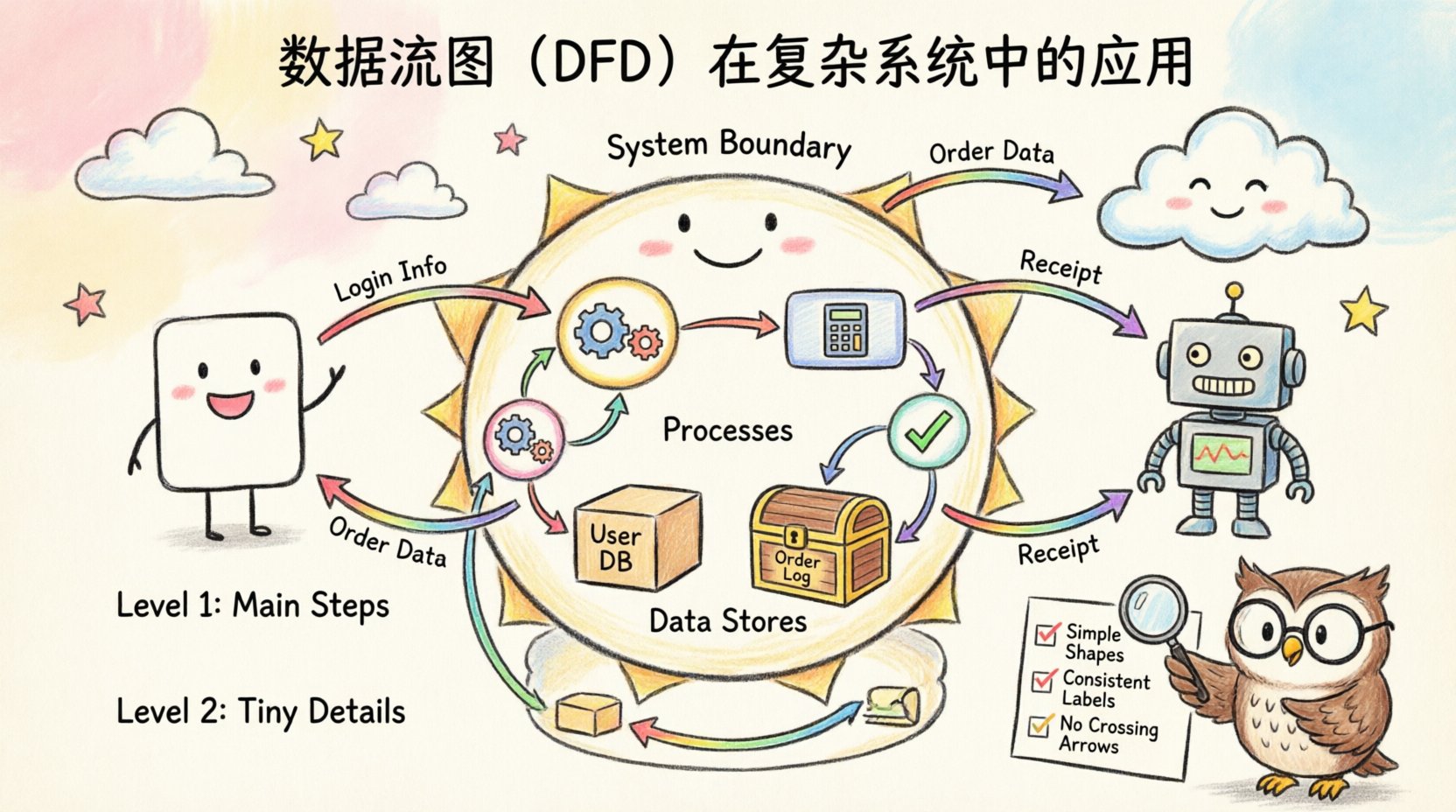
🔍 DFDの構造
プロフェッショナルな図を作成するには、標準的な記号を理解する必要があります。異なる表記法ではバリエーションがありますが、業界全体で共通する核心的な要素は一貫しています。これらの標準的な要素を使用することで、文書を確認する誰もが正しく解釈できることが保証されます。
核心的な構成要素
- 外部エンティティ:これらはシステム外部のデータの発信元または受信先です。ユーザー、他のシステム、ハードウェアデバイスなどが該当します。通常、四角形または長方形で表現されます。
- プロセス:プロセスはデータの変換を表します。入力データを受け取り、それを変更し、出力データを生成します。複雑なシステムでは、プロセスはしばしばネストされたり、より小さなサブプロセスに分解されたりします。
- データストア:これらは後で使用するためにデータを保持するリポジトリです。データベース、ファイルシステム、あるいは一時的なメモリバッファを含みます。
- データフロー:これらはコンポーネントをつなぐ矢印です。データが移動する方向を示します。すべての矢印には、データパケットの内容を説明するラベルが必要です。
記号の可視化
| コンポーネント | 視覚的形状 | 機能 | 例 |
|---|---|---|---|
| 外部エンティティ | 長方形 | ソースまたはシンク | 顧客、決済ゲートウェイ |
| プロセス | 円または角丸長方形 | 変換 | 税額計算、ログイン検証 |
| データストア | 開かれた長方形 | ストレージ | ユーザーDB、注文ログ |
| データフロー | 矢印 | 移動 | 請求データ、検索クエリ |
ラベルの整合性が最も重要です。すべての矢印はデータペイロードを明確に記述しなければなりません。”情報”や”データ”といった一般的なラベルを避けてください。代わりに”顧客ID”や”取引領収書”のように具体的な記述を心がけてください。この具体的さにより、開発フェーズでの曖昧さが軽減されます。
🌳 階層的分解
複雑なシステムは一度に一つのビューで理解することはできません。すべての詳細を1ページに描こうとすると、読めない複雑な混乱状態になります。解決策は階層的分解です。このアプローチにより、システムを扱いやすい抽象化の段階に分けていきます。
レベル0:コンテキスト図
最上位はコンテキスト図です。これはシステム全体を単一のプロセスとして示します。主要な外部エンティティと、システムに入出する高レベルのデータフローを特定します。これにより範囲境界が定義されます。この図は「システム全体として何をしているのか?」という問いに答えます。
- システムの境界を明確に特定してください。
- すべての主要な外部インタラクションをリストアップしてください。
- このレベルではデータストアを表示しないようにしてください(データはシステム内部に存在します)。
レベル1:主要プロセス
次のレベルでは、レベル0の単一プロセスを主要なサブプロセスに分解します。これによりシステムの主要な機能が明らかになります。複雑なシステムの場合、このレベルには5~9つのプロセスが含まれる可能性があります。それ以上ある場合は、システムが過度に緩く結合されているか、モジュール境界の再評価が必要かもしれません。
レベル2以下:詳細な論理
各主要プロセスに対してさらに分解が行われます。レベル2では、レベル1の特定のサブプロセスを分解します。このプロセスを、コードや論理として直接実装できるほど単純になるまで続けます。説明なしに実装できる粒度に到達することが目的です。
🛠️ ステップバイステップ構築プロセス
図の作成は厳密な作業です。論理的な整合性を保つために順序に従う必要があります。ステップを飛ばすと、設計全体に影響するエラーが発生する可能性があります。
- 範囲を定義する: システムの内部と外部にあるものを特定する。この境界は、図の作成において最も重要な決定事項である。
- 外部エンティティを特定する: データとやり取りするすべてのユーザー、システム、またはデバイスをリストアップする。ここでは内部コンポーネントを含めないでください。
- 高レベルのフローをマッピングする: エンティティとシステムをつなぐ矢印を描く。それらに交換されるデータをラベルで示す。
- プロセスを分解する: 主要なシステム機能を論理的なステップに分解する。すべての入力に対して対応する出力があることを確認する。
- データストアを追加する: データを保存する必要がある場所を特定する。すべてのストアが少なくとも1つの読み取りフローと1つの書き込みフローを持っていることを確認する。
- バランスの検証: 親プロセスの入力と出力が、その子プロセスの入力と出力と一致しているかを確認する。
整合性チェック
検証は選択肢ではない。図が正確でなければ、有用ではない。整合性を確認するためにこれらのチェックを使用する:
- ブラックホールチェック: すべてのプロセスが少なくとも1つの入力と1つの出力を備えていることを確認する。入力のないプロセスは作成を意味し、出力のないプロセスは削除を意味する。
- グレイホールチェック: 出力データが入力データから論理的に導出されていることを確認する。プロセスが「検索クエリ」のみを受け取って「注文確認」を出力する場合、データフローは不可能である。
- データストアチェック: 2つのデータストアの間に直接のフローが存在しないことを確認する。データは保存される前に、プロセスを経て変換または検証されなければならない。
- エンティティチェック: 外部エンティティが他の外部エンティティに直接接続されていないことを確認する。すべての通信はシステム境界を通過しなければならない。
🏗️ モダンなアーキテクチャにおける複雑さの対処
現代のシステムは、マイクロサービス、クラウドインフラ、非同期メッセージングを頻繁に利用する。これらの環境は、従来の図では捉えきれない複雑さをもたらす。標準的なDFDは同期データに注目するが、現実のシステムはキューとイベントに依存することが多い。
非同期フローの取り扱い
イベント駆動型アーキテクチャでは、データフローが常に即時であるとは限らない。メッセージはキューに格納され、後に処理されることがある。この状況を図示する際は、キューのストレージ機能を明確に示す必要がある。キューをデータストアとして扱う。これにより、プロセスがプロデューサーから分離されていることが明確になる。
- メッセージの種類に特定のラベルを使用する。
- フローが同期(ブロッキング)か非同期(ノンブロッキング)かを明示する。
- リトライメカニズムは図自体ではなく、プロセスの説明に記録する。
セキュリティ上の考慮事項
データフローダイアグラムはセキュリティ境界も反映すべきである。複雑なシステムでは、データが信頼ゾーンを越えることがよくある。DFDは暗号化キーを明示的にマッピングしないが、データがセキュアな領域から出る場所を示すべきである。
- ファイアウォールやパブリックネットワークを横切るデータフローをマークする。
- 個人識別情報(PII)など、機密性の高いデータタイプを特定する。
- プロセスレベルでの認証要件をメモする。
並行処理と状態
DFDは通常、時間を示さない。しかし並行システムでは、レースコンディションのリスクがある。複数のプロセスが同時に同じデータストアにアクセスすると、競合が発生する可能性がある。図では共有リソースを強調すべきである。これにより、チームがデータに対してロックメカニズムやバージョン管理を実装するよう注意を喚起する。
⚠️ 避けるべき一般的な落とし穴
経験豊富なアーキテクトですらミスを犯す。一般的な誤りを認識することで、プロジェクトライフサイクルの後半での再作業を防げる。
- 詳細が多すぎる:フロー内のすべての変数を表示しようとすると、図が読みにくくなる。可能な限りデータを集約する。特定のフィールドが重要でない限り、「ユーザー情報」を表示し、「名前、姓、メールアドレス、住所」といった詳細を示さない。
- 制御フローの漏洩:「エラーの場合」や「ループ」などの論理矢印を描いてはならない。DFDは制御を示すものではなく、データを示すものである。決定がデータパスを変更する場合、その決定によって生じる異なるデータフローを表示する。
- 命名の不整合:全体を通して同じ用語を使用する。ある場所でプロセスが「合計計算」と呼ばれている場合、別の場所で「金額合計」と呼んではならない。これにより開発者が混乱し、曖昧さが残る。
- データストアの欠落:図をきれいに見せるためにストレージを省略することがある。決してこれをしてはならない。データが永続化される場合は、必ずストアされるべきである。一時的なデータであれば、それはストアではない。
- 境界の重複:システム境界が明確であることを確認する。外部エンティティがプロセスクラウド内に表示されないようにする。
🔄 図の最新化
図は特定の時点におけるシステムのスナップショットである。システムが進化するにつれて、図は古くなりがちである。アジャイル環境では、これが常に課題となる。図は常に最新のドキュメントとして維持されなければならない。
開発との統合
コードが変更されたら図を更新する。新しいAPIエンドポイントが追加されたら、DFDは新しいデータフローを反映すべきである。データベーススキーマが変更されたら、データストアの表現も更新すべきである。これにより、ドキュメントがコードベースの現実と一致することを保証する。
- 図の所有権を、システムアーキテクトやリードエンジニアなどの特定の役割に割り当てる。
- スプリント計画や設計レビューの際に図を確認する。
- 図のファイルをコードリポジトリと併せてバージョン管理する。
ドキュメントの標準
視覚的な図にテキストを併記する。図は「何が」を示すが、テキストは「どのように」そして「なぜ」を説明する。複雑な記号には凡例を含める。すべての人がラベルを同じように解釈できるように、用語集を追加する。
🤝 コラボレーションとコミュニケーション
DFDの主な価値はコミュニケーションである。技術者と非技術者との間のギャップを埋める。ビジネスアナリストは図を使って要件を検証できる。開発者は統合ポイントを理解するために使用する。QAチームはテストケースを設計するために使用する。
- ビジネス関係者向け:レベル0およびレベル1の図に注目する。これらは技術的なごちゃごちゃを除いて、高レベルの価値と主要な入出力を示す。
- 開発者向け:レベル2およびそれ以上の図を提供してください。これらは実装に必要な特定のデータ変換を示します。
- 運用担当者向け:データストアおよびセキュリティ境界を強調してください。彼らはデータがどこに存在するか、どのように保護されているかを把握する必要があります。
📝 最良の実践方法の要約
データフローダイアグラムを作成する成功は、規律と標準への従順さに依存します。図を芸術的に見せることが目的ではなく、正確で機能的なものにすることが目的です。高品質を維持するための核心的なポイントを以下に示します。
- 簡潔さ:論理を伝えるために必要な最小限の記号を使用してください。
- 一貫性:一貫した命名規則および表記規則を維持してください。
- 完全性:すべてのデータフローが発信元と受信先を持っていることを確認してください。
- 明確さ:可能な限り線の交差を避けてください。複雑さを管理するために接続子を使用してください。
- 検証:図を実際のシステム動作と照らし合わせて定期的にレビューしてください。
データフローダイアグラムを任意の成果物ではなく、重要な成果物として扱うことで、チームはリスクを低減し、効率を向上させます。明確な文書化への投資は、保守、デバッグ、将来の拡張フェーズにおいて大きな利益をもたらします。明確な地図があることで、関係するすべての人がシステムアーキテクチャの旅を容易に進めることができます。
最終的な目的は、複雑さを解明することです。データフローが明確になると、システム設計はより強固になります。ステークホルダーはアーキテクチャに自信を持ちます。要件から実装への道のりがスムーズになります。この明確さこそが、信頼性の高いソフトウェア工学の基盤です。