











データフローダイアグラム(DFD)は、システム分析と設計の基盤の一つとして依然として重要です。入門的な授業でしばしば導入されますが、複雑なソフトウェアエンジニアリング環境におけるその応用には、細やかなアプローチが求められます。このガイドでは、データフローダイアグラムの構築、分析、維持に向けた高度な技術を検討します。基本的な箱と矢印の表現を越えて、並行処理、データ整合性、アーキテクチャの整合性といった課題に取り組みます。レガシーシステムのリファクタリングを行う場合でも、新しいマイクロサービスアーキテクチャを設計する場合でも、これらの図を習得することで、コミュニケーションの明確さと実装の正確性が保証されます。
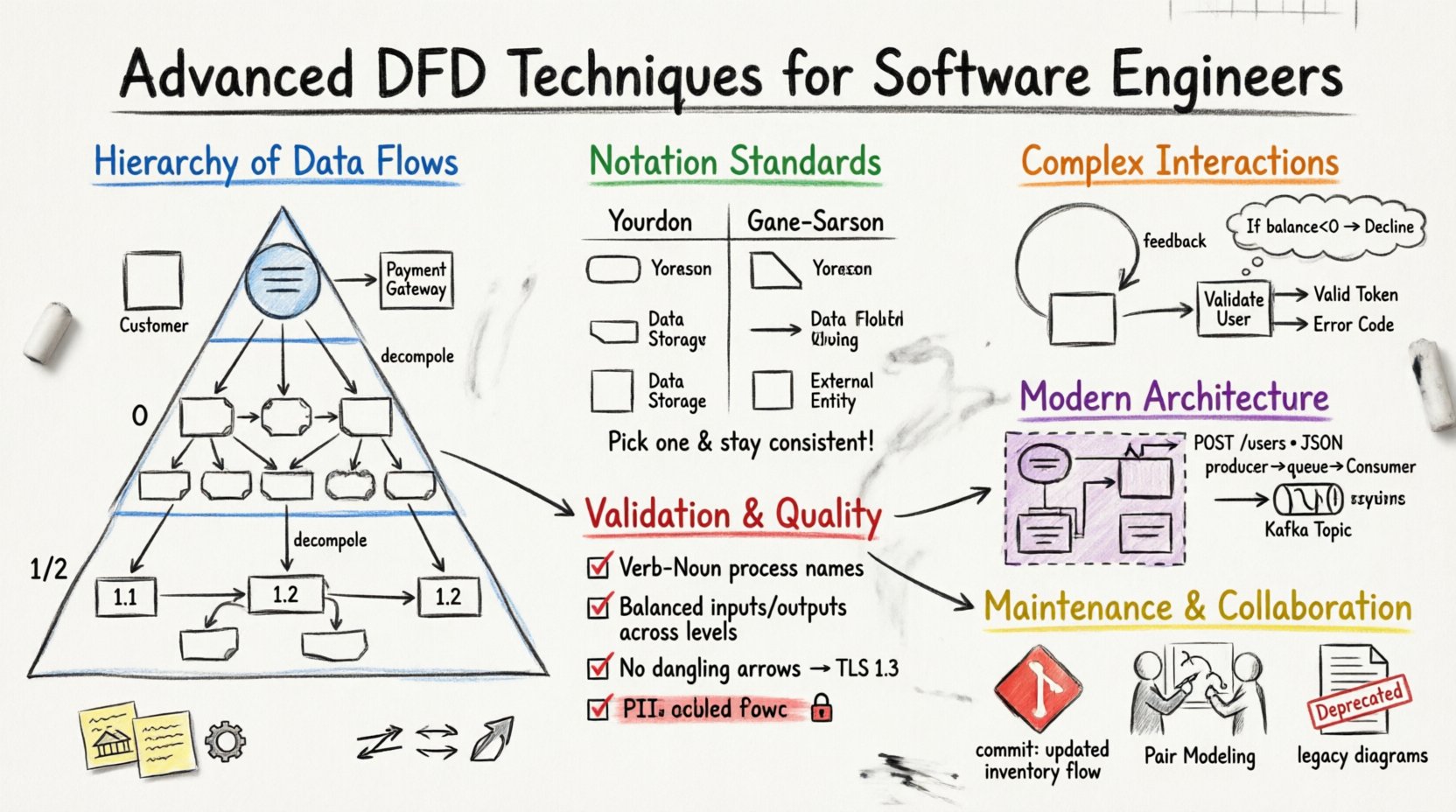
🏗️ データフローの階層構造を理解する
強固なDFD戦略は、階層的なアプローチに依存しています。システムを単一のレベルで可視化すると、重要な依存関係が隠れてしまうことがあります。システムを特定のレベルに分解することで、エンジニアは複雑さを管理し、関連する詳細に注目し続けることができます。
🌐 コンテキスト図:マクロビュー
コンテキスト図は、システムの境界を定義する役割を果たします。ソフトウェアを単一のプロセスとして表現し、それとやり取りするすべての外部エンティティを特定します。このレベルは、プロジェクトの範囲を定義する上で極めて重要です。
- 外部エンティティ:これらは境界外のユーザー、他のシステム、またはハードウェアデバイスです。例として、顧客、決済ゲートウェイ、レガシーデータベースがあります。
- データフロー:矢印は、情報がシステム内へ入ってくるか、システム外へ出るかの動きを示します。ラベルには、例えば「注文リクエスト」や「請求書データ」など、内容を明確に指定する必要があります。
- 単一プロセス:システム自体は、丸い長方形で表され、多くの場合システム名がラベルとして付けられます。
コンテキスト図を作成する際は、内部プロセスを含めないようにしましょう。目的はインターフェース契約を確立することです。あるエンティティがデータを送信するが、一度も受信しない場合、そのフローが本当に必要かどうか確認してください。同様に、外部ソースからのすべての必要な入力を把握していることを確認してください。
📉 レベル0:システム概要
「トップレベル」または「親」図とも呼ばれるレベル0では、コンテキスト図の単一プロセスを、主要なサブシステムや機能領域に拡張します。このレベルは、内部ロジックの詳細を示さずに、システムの機能を高レベルでマッピングするものです。
レベル0の主な特徴には以下が含まれます:
- 主要プロセス:通常5〜9つのプロセスです。多すぎると、より上位のグループ化が必要であることを示唆し、少なすぎると機能が欠落している可能性を示します。
- データストア:永続データが保持される場所を特定します。このレベルでは、データが保存されていること(*that*)を示すだけで、その構造がどうなっているかまでは示しません。
- フローの一貫性:コンテキスト図のすべての入力と出力が、ここに現れなければなりません。これにより、分解によってシステムの外部契約が変更されていないことを保証します。
🧩 レベル1と2:分解戦略
レベル1およびレベル2に掘り下げていくと、焦点は特定の機能やデータ操作に移ります。ここが、エンジニアリング作業のロジックが記録される場所です。
- 分解:レベル0のプロセスをサブプロセスに分解します。たとえば、「注文処理」は「在庫検証」、「支払い請求」、「領収書発行」に分かれることがあります。
- 詳細化:各プロセスには番号を付ける(例:1.0、1.1、1.2)ことで、図の間での関係を追跡できます。
- データストアへのアクセス:どのプロセスがどのデータストアから読み取りまたは書き込みを行うかを明確にマークしてください。外部エンティティとデータストアの間の直接的な接続を避けましょう。すべてのアクセスはプロセスを経由して行わなければなりません。
分解する際は、データフローが失われないことを確認してください。よくある誤りは、親図に存在したデータフローを子図で省略することです。これは「バランス違反」として知られています。
🔣 表記規準と記号の意味
適切な表記システムを選択することで、開発チーム全体が図を普遍的に理解できるようになります。規準はさまざまですが、業界を代表する主な二つの考え方があります。
| 機能 | ヨア・ドネル表記法 | ゲイン・サーソン表記法 |
|---|---|---|
| プロセス | 丸角長方形 | 角が切り落とされた長方形 |
| データストア | 開放された長方形 | 開放された長方形 |
| 外部エンティティ | 正方形 | 正方形 |
| データフロー | 矢印付きの線 | 矢印付きの線 |
| ラベル | 名詞句 | 名詞句 |
一貫性が最も重要です。同じ文書セット内で表記法を混在させると混乱を招きます。一つの標準を選択し、すべての図にわたってそれを遵守してください。選択は、エンジニアリング文化や既存の文書テンプレートに大きく依存します。
⚙️ 複雑なデータ相互作用の管理
現実世界のシステムはほとんど線形ではありません。ループや分岐論理、非同期イベントを含みます。これらの動的特性を静的な図で表現するには、特定の技法が必要です。
🔄 ループと反復の処理
DFDはフローチャートではありません。制御フロー(if-then-else)を明示的に示すものではありません。しかし、データループは一般的です。たとえば、「税金計算」プロセスはデータを「レート照会」ストアに送信し、結果を戻して受信するといった動作をします。
- フィードバックループ:再評価を示すために、プロセスに戻る矢印を使用してください。何のデータが更新されているかを明確にラベルで示してください。
- 反復プロセス:プロセスが条件を満たすまで繰り返される場合、その条件をプロセスの説明またはテキスト注記に記載してください。ループを制御フロー線として描くのは避けましょう。
- データ更新:更新操作を示すために、データフローがデータストアに戻る様子を表示する。
🧭 決定ポイントの表現
決定ロジックはプロセスの説明に記載すべきであり、図自体には含めない。プロセス名が「ユーザー検証」であることは、内部ロジックを含むことを意味する。プロセスを「検証」と「拒否」に分割してはならない。プロセスは原子的であるように保つ。
- 出力の区別:プロセスが内部の判断に基づいて異なるデータを送信する場合、異なるデータフローのラベルを使用する(例:「有効なトークン」対「エラーコード」)。
- 注釈:決定基準を明確にするためにテキストボックスを使用する。例えば、「残高 < 0 の場合、’却下’のフローへ」。
- 原子性:各プロセスが1つの論理的機能を実行することを確認する。複数の異なる判断を処理する場合は、別々のプロセスに分割することを検討する。
🔗 DFDの現代アーキテクチャとの統合
ソフトウェア工学は進化した。分散システム、クラウドコンピューティング、API駆動設計への移行は、データフローの見方を変える。DFDは陳腐化せずに、これらの現実を反映するよう適応しなければならない。
☁️ マイクロサービスとAPIエンドポイント
モノリシックアーキテクチャでは、プロセスはモジュールを表すことがある。マイクロサービス環境では、プロセスはしばしばサービスインスタンスを表す。データフローはAPI呼び出しとなる。
- サービス境界:単一のマイクロサービスを構成するプロセス群の周囲にボックスを描く。この境界を越えるデータフローはネットワークリクエストである。
- API契約:データフローに特定のAPIエンドポイントまたはペイロード構造(例:「POST /users」、「JSONペイロード」)をラベルとして付ける。
- 無状態性:サービスが無状態の場合、一時的なキャッシュを除き、サービス境界内にデータストアを表示してはならない。永続的なストレージは外部に置くべきである。
📨 非同期メッセージングとキュー
すべてのデータフローがリアルタイムで発生するわけではない。バックグラウンドジョブやイベント駆動型アーキテクチャはキューに依存している。
- キューをデータストアとして:メッセージキュー(例:RabbitMQ、Kafkaトピック)をデータストアの記号で表現する。これにより、データが一時的に永続化されていることが明確になる。
- プロデューサ/コンシューマ:プロデューサプロセスがキューに書き込み、コンシューマプロセスがそれを読み取る様子を表示する。フローは非同期に分離されている。
- 遅延の影響:注釈で、書き込み後にデータが即座に利用可能にならないことを明記する。これは障害発生時のシステム動作を理解する上で重要である。
🛡️ 検証と整合性チェック
図が有用であるのは、システムを正確に反映している場合のみである。検証により、モデルが数学的・論理的に整合していることを保証する。エンジニアは文書の最終化前にこれらのチェックを実施すべきである。
⚖️ データバランスの検証
図に流入するすべてのデータフローは、記録されなければならない。これがデータ保存の原則である。
- 入力/出力の一致:親図から入力されるすべてのデータが、子図に存在することを確認する。入力は消失してはならない。
- 出力の完全性:上位レベルで定義されたすべての出力は、下位レベルにも存在しなければならない。子プロセスが新しい出力を生成する場合、それは新たな要件として正当化されるか、内部的な副作用であると説明されなければならない。
- ストアの整合性:データストアはレベル間で整合性を保たなければならない。レベル1で作成されたストアは、レベル0にも存在しなければならない。
🏷️ 名前付けの規則
明確な名前付けは曖昧さを防ぐ。不適切なラベルは技術文書における誤解の最も一般的な原因である。
- 動詞+名詞形式:プロセスは動詞と名詞の組み合わせで命名すべきである(例:「税金を計算する」、「プロフィールを更新する」)。単なる名詞(例:「税金」)や目的語のない動詞句(例:「計算中」)は避ける。
- データフローのラベル:具体的な名詞(例:「請求書ID」、「ユーザーのセッション」)を使用する。「データ」や「情報」のような曖昧な語は避ける。
- エンティティ名:外部エンティティの名称は一貫性を持たなければならない。「顧客」は、同じ図のセット内で「クライアント」や「ユーザー」として切り替えてはならない。
🔄 メンテナンスとドキュメントのライフサイクル
DFDは静的な資産ではない。ソフトウェアの変更に応じて進化しなければならない。古くなった図は、何も図がないよりも悪い。なぜなら、誤った理解を生むからである。
📦 図のバージョン管理
図をコードと同様に扱う。ソースコードのリポジトリと一緒に、バージョン管理システムに保存する。
- コミットメッセージ:図のコミットにおける変更を記録する。「決済ゲートウェイプロセスを追加」、「在庫フローを更新」など。
- ビジュアル差分比較:図の視覚的比較が可能なツールを使用し、意図しない構造的変更を発見する。
- リンク:図を変更を引き起こした特定のプルリクエストやチケットにリンクする。これによりトレーサビリティが確保される。
🤝 コラボレーション戦略
ドキュメント作成はチームの努力である。DFDの維持を一人のアーキテクトに依存すると、ボトルネックが生じ、情報が陳腐化する。
- ペアモデリング:設計段階で2人のエンジニアが一緒に図を描く。これにより、早期に誤りを発見できる。
- レビュー・サイクル:標準的なコードレビュー過程にDFDのレビューを含める。コードが変更された場合、図は更新するか、同期されていないことを明記するべきである。
- 動的な文書:古い図をアーカイブしないようにする。代わりに、リポジトリ内で「非推奨」または「レガシー」とマークする。これにより履歴は保持されつつ、現在のビューは混雑しない。
🧠 高度な実装に関する考慮事項
視覚的な表現を超えて、基盤となるデータ構造と論理がフローを決定する。エンジニアはデータの物理的制約を考慮しなければならない。
📏 データ量とスループット
DFDは論理的なフローを記述するものであり、パフォーマンスではない。しかし、大量のデータフローは設計に影響を与える。
- 大量データフロー: フローが大きなファイルやログを含む場合、ラベルでそれを示す。これにより、異なる送信メカニズムを使用する決定を促す可能性がある。
- 圧縮: 送信前にデータが圧縮されているかどうかを明記する。これは受信側の処理負荷に影響する。
- エンコーディング: フローがプラットフォームの境界を越える場合(例:UTF-8対ASCII)、文字エンコーディングを明記する。
🔒 セキュリティとアクセス制御
セキュリティは後から考えるものではない。データフローに明確に可視化されなければならない。
- 暗号化: 暗号化が必要なフローをマークする。例として「暗号化ストリーム」や「TLS 1.3」といったラベルを使用する。
- 個人情報(PII)の取り扱い: 個人識別情報(PII)を含むフローを強調する。これにより、設計段階でコンプライアンス要件を満たすことが保証される。
- 認証: 認証情報が渡される場所を示す。平文のパスワードを含むフローを避ける。代わりに「認証トークン」とラベルを付ける。
📝 図の品質チェックリスト
データフロー図のセットを最終化する前に、この検証チェックリストを確認する。
- すべての外部エンティティが明確に定義されているか?
- すべてのデータフローに説明的なラベルが付けられているか?
- すべてのプロセスが動詞+名詞構造で命名されているか?
- 見やすさのために再ルーティング可能な交差する線は存在するか?
- 親図のすべての入力が子図に表示されているか?
- データストアがプロセスから適切に分離されているか?
- 図はコンテキスト図とバランスが取れていますか?
- 宛先のない矢印(終端のないフロー)はありますか?
- 文書群全体で表記が一貫していますか?
- 機密性の高いフローにセキュリティ制約が記載されていますか?
これらの高度な技術を遵守することで、ソフトウェアエンジニアは開発の信頼できる設計図として機能する文書を生成できます。DFDは抽象的な要件と具体的な実装の間のギャップを埋めます。ステークホルダー間のコミュニケーションを促進し、論理の曖昧さを軽減し、テストの基準を提供します。厳格な管理と徹底的な更新がなされれば、これらはエンジニアリングの武器庫において強力なツールのままです。
🚀 システムモデリングに関する最終的な考察
データフローダイアグラムの価値は、複雑さを簡素化する能力にあります。構文や実装の詳細といったノイズを排除し、価値の流れに注目します。ソフトウェアエンジニアにとって、この注目は不可欠です。設計上の欠陥を早期に発見でき、新規メンバーのオンボーディングが明確になり、システムアーキテクチャに対する共有されたメンタルモデルが得られます。モデリングのプロセスにコミットしてください。努力を要しますが、システムの明確さに対する投資のリターンは非常に大きいです。
図は手段であり、目的ではないことを思い出してください。図はコードを支援するものであり、逆ではないのです。図を簡潔で正確かつアクセスしやすい状態に保ちましょう。システムが進化するにつれて、図もそれに合わせて進化させるべきです。この動的なアプローチにより、文書が静的な負担ではなく、生き生きとした資産のまま保たれます。