











クラウド向けソフトウェアを開発するには、考え方の転換が必要です。従来のモノリシックアーキテクチャは、メモリやローカルファイルシステムを共有する密結合なコンポーネントに依存していました。一方、クラウドネイティブアプリケーションは、複数のネットワークやセキュリティ境界をまたがる分散環境で動作します。この複雑さを乗り越えるため、エンジニアはシステム内の情報の流れを明確に視覚化する必要があります。ここにデータフローダイアグラム(DFD)が不可欠なツールとして登場します。プロセス、ストア、外部エンティティ間のデータの流れをマッピングすることで、推測に頼ることなく、堅牢でスケーラブルかつ安全なシステムを設計できます。
本書では、DFDの原則をクラウドネイティブな文脈に特化して適用する方法を探ります。中心となる構成要素、分散システムに必要な適応、インフラが進化しても役立つ図の作成手順について検討します。マイクロサービスエコシステムやサーバーレス関数チェーンを設計する場合でも、データの動きを理解することは信頼性の高いエンジニアリングの基盤です。
🌩️ クラウドネイティブモデリングへの移行を理解する
従来のオンプレミス環境では、システムはしばしば単一の物理的境界内に存在します。データはプロセス間でローカルに流れます。一方、クラウドネイティブ環境では境界が流動的です。単一の論理的なアプリケーションが、コンテナ内で実行される数十もの独立したサービスから構成され、異なるリージョンや可用性ゾーンにわたってオーケストレーションされることがあります。ネットワーク遅延、最終的整合性、セキュリティポリシーといった要素は、モノリシック設計には存在しない変数をもたらします。
この環境向けのデータフローダイアグラムを作成する際には、以下の点を考慮する必要があります:
- ネットワーク境界:データはしばしばパブリックネットワークやセキュアなVPCを跨ぎます。各ホップは、障害や遅延の潜在的要因となります。
- 状態管理:クラウドサービスはしばしばステートレスです。プロセスはメモリに状態を保持するのではなく、外部のストアから状態を取得しなければなりません。
- 非同期通信:同期呼び出し(リクエスト・レスポンス)は常に最適とは限りません。メッセージキューとイベントストリームは、コンポーネント間のデータの流れを変化させます。
- セキュリティゾーン:境界にデータが入る際には、内部プロセスに到達する前に認証と暗号化が行われなければなりません。
これらの制約を早期に可視化することで、アーキテクチャ上の負債を防ぐことができます。ネットワークセグメンテーションやステートレス要件を無視した図は、デバッグやスケーリングが困難なシステムを生み出します。目標は、データがどこへ行くかを示すだけではなく、データがどのように変換され、保存され、保護されるかを強調することです。
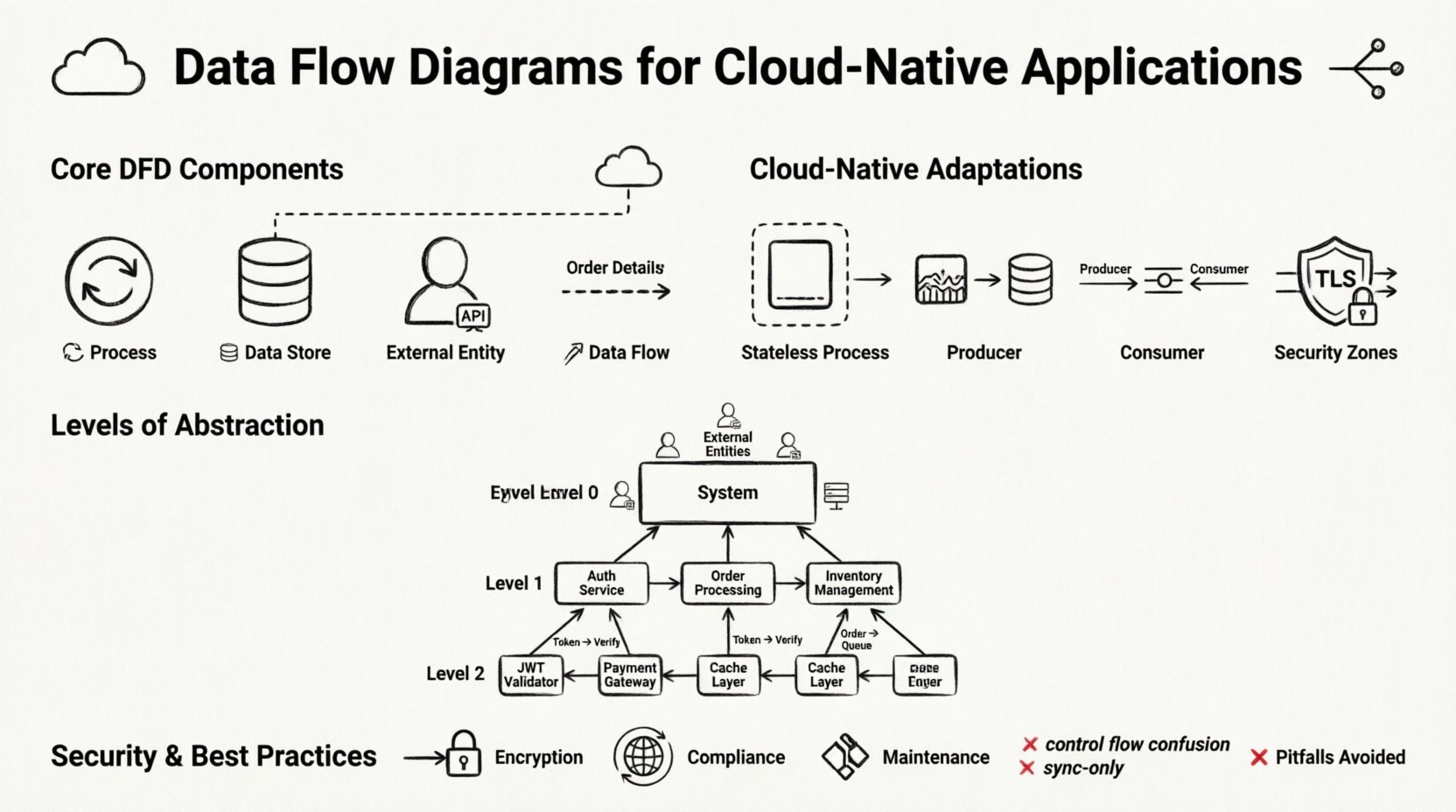
🧩 データフローダイアグラムの核心構成要素
クラウド向けにこれらの図を適応する前に、標準的な構成要素を確立する必要があります。DFDはフローチャートではありません。制御論理やタイミングを示すものではありません。データの移動を示すものです。4つの主要な要素は、分散システムにおいても一貫して保持されます。
1. プロセス 🔄
プロセスは、入力データを出力データに変換する活動を表します。クラウドネイティブな文脈では、プロセスは関数、コンテナ化されたアプリケーション、またはマイクロサービスのインスタンスであることがよくあります。プロセスの名前は、技術的な呼び名ではなく、その機能に基づいて付けることが重要です。たとえば「UserService API」ではなく、「ユーザー認証情報の検証」といった名前にするべきです。これにより、図はデータ変換ロジックに集中できます。
- 変換:すべてのプロセスは、何らかの形でデータを変更しなければなりません。データが変更されずに通過する場合は、プロセスとして表現すべきではありません。
- カプセル化:マイクロサービスでは、各プロセスはカプセル化されています。内部ロジックは隠蔽され、図において重要なのは入力と出力のインターフェースのみです。
- ステートレス性:ほとんどのクラウドプロセスは一時的です。過去の相互作用の記憶を保持しません。これはデータフロー要件に反映されなければなりません。
2. データストア 🗄️
データストアは、処理されていない間、データが一時的に保管される場所を表します。クラウドでは、リレーショナルデータベース、NoSQLドキュメントストア、オブジェクトストレージバケット、分散キャッシュなどが該当します。ファイルシステムとは異なり、クラウドデータストアはしばしばネットワーク経由でアクセスされます。
- 永続性:プロセスの障害や再起動後もデータを保持する必要がある場合は、ストアに保存しなければなりません。
- アクセスパターン: 読み込みが多いストアは、書き込みが多いストアと異なります。アーキテクチャに顕著な影響を与える場合は、図にアクセスの種類を明示する必要があります。
- セキュリティ: 敏感なデータストアには、異なるアクセス制御が必要です。この区別はセキュリティ監査において極めて重要です。
3. 外部エンティティ 👥
外部エンティティは、システム境界外のデータの発信元または受信先です。人間のユーザー、サードパーティAPI、レガシーシステム、ハードウェアデバイスなどが含まれます。クラウドネイティブな図では、外部エンティティはインターネットの端末や他のクラウドサービスを表すことがよくあります。
- 信頼できる vs. 信頼できない:既知の内部サービスからのデータと、パブリックインターネットのトラフィックとの区別を明確にします。
- トリガー: エンティティはしばしばフローの開始を担います。ユーザーのリクエストがプロセスをトリガーし、スケジュールされたジョブがデータ同期をトリガーします。
4. データフロー 📡
データフローは、コンポーネントをつなぐ矢印です。これらはデータの送信を表します。クラウド環境では、これらのフローはしばしばネットワークを通過します。矢印に付けるラベルは非常に重要です。プロトコルではなく、データパケットの内容を記述するべきです。たとえば、「HTTP POST」ではなく「注文詳細」とラベルを付けるべきです。これにより、図はプロトコルに依存せず、将来にわたっても有効な状態を保てます。
- 方向性: フローは単方向です。データが前後に移動する場合は、別々の矢印を描きます。
- 量: 高容量のデータフローは、低容量の制御フローと比較して、異なるインフラ(例:専用帯域)を必要とする場合があります。
- 暗号化: セキュリティ境界を越えるフローは、コンプライアンス要件を強調するために暗号化済みとしてマークする必要があります。
☁️ 分散システム向けのDFDの適応
標準的なDFDは、統合されたシステムを前提としています。クラウドネイティブシステムは分散型です。この文脈でDFDを有用にするには、インフラの分散性を明示的にモデル化する必要があります。これには、ネットワークトポロジーやサービス境界を表す抽象化のレイヤーを追加することが含まれます。
サービス境界
マイクロサービスは、クラウドネイティブアプリケーションの標準的な構成要素です。各サービスは図上で明確なプロセスとして表現されるべきです。しかし、すべてのサービスを個別に描くと、図が混雑します。一般的なアプローチとして、関連するサービスを論理的なドメイン(例:「請求ドメイン」や「ユーザー管理ドメイン」)にグループ化します。これにより、高レベルのフローを把握しつつ、内部の複雑さを隠すことができます。
APIゲートウェイ
多くのクラウドネイティブアプリケーションは、APIゲートウェイまたはロードバランサーの背後に配置されています。このコンポーネントは単一のエントリポイントとして機能します。DFDでは、ゲートウェイはリクエストをルーティングするプロセスとして表現されます。認証、レート制限、プロトコル変換を処理します。ゲートウェイを単なるパイプと見なさず、データフローを積極的に変更している点に注意してください。
イベント駆動型アーキテクチャ
多くの現代的なシステムは、イベント駆動型のパターンを使用しています。プロデューサーがイベントを生成し、コンシューマーが後にそれを処理します。これにより、プロセスとデータフローの同期的な関係が解消されます。DFDでは、イベントキューまたはストリームをデータストアとして使用してこれを表現します。プロデューサーはイベントを書き込み、コンシューマーはそれを読み取ります。この分離は、システムの耐障害性にとって極めて重要です。
| コンポーネント | 従来のモノリス | クラウドネイティブな適応 |
|---|---|---|
| プロセス | メモリ内関数 | コンテナ化されたマイクロサービス / サーバーレス関数 |
| データストア | ローカルファイル / SQLデータベース | マネージドクラウドデータベース / オブジェクトストレージ |
| フロー | ローカルメモリ呼び出し | HTTP / gRPC / メッセージキュー |
| 状態 | 共有メモリ | 外部化された状態ストア |
📉 クラウドアーキテクチャにおける抽象化のレベル
複雑なシステムは複数のレベルの図が必要です。1つのビューにすべての詳細を収めようとすると混乱を招きます。標準的なDFDアプローチであるレベル0、1、2は、適切に適用すればクラウドシステムに非常に効果的です。
レベル0:コンテキスト図
コンテキスト図は、システム全体を単一のプロセスとして示します。システムとやり取りする外部エンティティを強調します。クラウドアプリケーションの場合、これは境界を定義します。『システムに入るのは何で、出て行くのは何ですか?』という問いに答えます。これは最も高レベルの視点であり、技術的な詳細を気にせずに範囲を理解したいステークホルダーにとって有用です。
- 注目点:システムの境界と外部インターフェース。
- 詳細:最小限。1つの中心プロセス。
- 使用例:プロジェクトの範囲定義と高レベルなセキュリティ計画。
レベル1:主要プロセス
レベル1では、中心プロセスを主要なサブプロセスに分割します。クラウドネイティブな文脈では、これらは通常、主要な機能領域です。たとえば、eコマースプラットフォームのレベル1図では、「注文処理」「在庫管理」「支払い処理」が別々のプロセスとして示されることがあります。このレベルでは、主要なサービスグループ間をデータがどのように移動するかが明らかになります。
- 注目点:主要な機能モジュールとそれらの相互作用。
- 詳細:各主要モジュールの入力と出力。
- 使用例:アーキテクチャのレビューとサービスの分解。
レベル2:詳細な論理
レベル2では、特定のサブプロセスにまで掘り下げます。ここでは、技術的な実装の詳細が重要になります。たとえば、「支払い処理」プロセスは、「カード検証」「アカウント請求」「領収書更新」などを示すように拡張されることがあります。このレベルは、特定のサービスを実装する開発者が使用します。
- 焦点:特定サービスの内部論理。
- 詳細:特定のデータ変換およびローカルデータストア。
- 使用ケース:開発実装およびテストシナリオ。
🔒 データマッピングにおけるセキュリティとコンプライアンス
クラウドネイティブ開発においてセキュリティは後回しのものではなく、設計上の要件である。データフローダイアグラムは、セキュリティリスクを特定する優れたツールである。データの経路を追跡することで、機密情報が漏洩する可能性がある場所や、不適切に保存されている場所を特定できる。
機密データの特定
すべてのデータフローが同等ではない。個人識別情報(PII)、財務記録、健康データはより厳格な取り扱いが求められる。図面で機密データを含むフローをマークする。これにより、このデータにアクセスするすべてのプロセスがコンプライアンスの観点から見直されることが保証される。
- 転送中の暗号化:ネットワーク境界を越えるフローはすべて暗号化(TLS/SSL)する必要がある。これらのフローを明確にマークする。
- 静止状態での暗号化:機密情報を保持するデータストアはすべて暗号化しなければならない。データストアのラベルにこれを示す。
- アクセス制御:どのプロセスが特定のデータストアの読み取りまたは書き込みを許可されているかを特定する。これにより、ロールベースアクセス制御(RBAC)の設定が容易になる。
コンプライアンス境界
異なる地域には異なるデータ主権法がある。データが特定の地理的境界内に留まる必要がある場合がある。DFDはこれらの制約を可視化するのに役立つ。地域Aのプロセスがデータを地域Bに送信する場合、このフローは法的レビューの対象としてマークすべきである。これにより、GDPRやCCPAなどの規制の誤っての違反を防ぐことができる。
⚠️ 一般的な落とし穴とその回避方法
クラウドシステム用のDFDを作成するのは難しい。チームがよく犯す一般的な誤りは、古いパターンを新しい環境に適用しようとすることが原因である。これらの落とし穴を避けることで、図面が正確かつ有用な状態を保てる。
1. 制御フローとデータフローの混同
DFDは制御論理を示してはならない。『もし○○なら、それならば△△』という意味の矢印を描いてはならない。論理は決定ポイントや外部の注記で示すが、矢印はデータの移動に集中させるべきである。クラウドシステムでは制御論理がしばしばオーケストレーションプラットフォームで処理されるため、DFDはペイロードに焦点を当てるべきである。
2. 非同期フローの無視
クラウドシステムはほとんど100%同期的ではない。ジョブはバックグラウンドで実行される。同期的なリクエスト・レスポンスのフローだけを描くと、図面は不完全になる。常にバックグラウンドジョブやイベントストリームを、データストアへの入出力としてデータフローとして含めるべきである。
3. 特定のツールに過剰に最適化する
特定のツールやプラットフォームの機能に基づいて図面を設計してはならない。特定のデータベースやメッセージブローカーを選択すると、技術の切り替え時に図面が陳腐化する可能性がある。物理的な実装ではなく、データの論理的フローに注目すべきである。
4. エラー発生時のフローの無視
成功したパスは描きやすい。失敗したパスは難しくても必要である。クラウド環境ではサービスの障害が頻繁に発生する。エラー情報がログに記録される場所、またはリトライメカニズムが発動される場所を明示する。これにより、堅牢なモニタリングおよびアラートシステムの設計が可能になる。
🔄 時間の経過に伴う図面の維持管理
図面は正確でなければ意味がない。クラウドネイティブアプリケーションは急速に変化する。新しいサービスが追加され、古いサービスは廃止され、データモデルも進化する。図面が実行中のシステムと一致しなければ、誤解を招く文書になってしまう。以下に、図面を維持する方法を示す。
- バージョン管理:図をコードとして扱う。アプリケーションコードと一緒に、バージョン管理システムに保存する。これにより、履歴と追跡可能性が保証される。
- レビューのサイクル:コードレビューのプロセスに図の更新を含める。開発者がデータフローを変更した場合、図は同じコミットまたはプルリクエストで更新されるべきである。
- 自動生成:可能な限り、コードやインフラストラクチャ-as-コードの定義から図を自動生成する。これにより、ドキュメントと現実のギャップが縮まる。
- ステークホルダーの整合:非技術的なステークホルダーと図を定期的にレビューする。これにより、対象の聴衆に適切な抽象度が保たれる。
📋 DFDを他のアーキテクチャビューと比較する
DFDをSequence DiagramやSystem Architecture Diagramなどの他の図と混同することはよくある。違いを理解することで、適切なツールを選択できる。
| 図の種類 | 主な焦点 | 最も適している用途 |
|---|---|---|
| データフローダイアグラム | データの移動と変換 | システム設計、セキュリティ監査、データマッピング |
| シーケンス図 | オブジェクト間の時間ベースの相互作用 | API統合、コールチェーンのデバッグ |
| システムアーキテクチャ | インフラストラクチャとデプロイメント | DevOps、スケーリング、ハードウェア要件 |
| エンティティ関係図 | データ構造と関係性 | データベース設計、スキーマ計画 |
DFDはこれらのビューを補完する。アーキテクチャ図はサーバーの配置を示すが、DFDは情報がそれらの間をどのように移動するかを示す。シーケンス図は呼び出しの順序を示すが、DFDはペイロードを示す。これらを併用することで、システムの包括的な把握が可能になる。
🚀 クラウドモデリングの将来のトレンド
クラウド技術が進化するにつれて、モデリングの要件も変化している。サーバーレスコンピューティングやエッジコンピューティングの台頭により、新たな課題が生じている。データフローはより分散化している。プロセスはユーザーに近い場所で実行されている。この変化により、DFDはエッジノードや一時的なコンピューティングリソースを考慮する必要がある。
さらに、ワークフローへの人工知能の統合により複雑性が増す。AIモデルはデータを消費し、洞察を生み出す。これらのプロセスはしばしば大規模なデータセットと専用のハードウェアを必要とする。将来のDFDは、こうしたコンピューティング負荷の高いプロセスとそれらを供給するデータパイプラインを表現する必要がある。基本的な原則は変わらないが、詳細度と範囲は拡大するだろう。
データフローダイアグラムの基本を守りながらクラウドの現実に適応することで、エンジニアリングチームは透明性があり、安全でスケーラブルなシステムを構築できる。データを可視化することは単なるドキュメント作成の作業ではない。設計プロセスにおける重要なステップであり、生産環境に到達する前にエラーを防ぐことができる。