











データフローダイアグラム(DFD)は、システム分析および設計における基盤的なツールです。データがシステム内でどのように移動するかを視覚的に表現し、プロセス、データストア、外部エンティティ、およびそれらを結ぶフローを強調します。しかし、有効なDFDを作成することは必ずしも簡単ではありません。モデル化プロセス中に誤りが入り込み、論理的な不整合を引き起こすことがあります。これは、システム全体のアーキテクチャを損なう原因となります。
このガイドは、データフローダイアグラムに見られる一般的な問題を特定し、解決する包括的なアプローチを提供します。構造化されたトラブルシューティング手法に従うことで、アナリストはモデルがシステム要件および運用実態を正確に反映していることを確認できます。
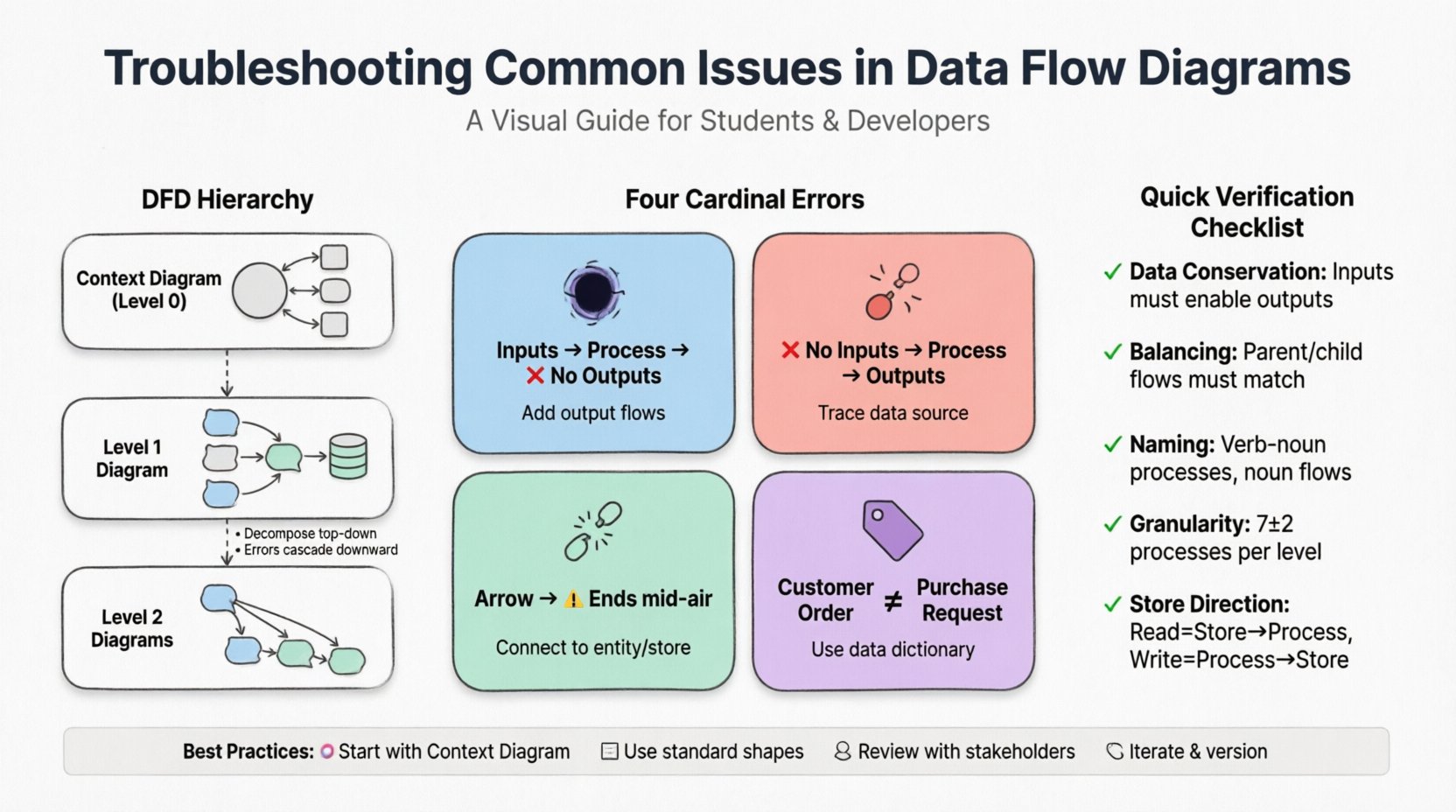
DFDの階層構造を理解する 🏗️
特定のエラーをトラブルシューティングする前に、DFDの構造を理解することが不可欠です。包括的なモデル化作業では、通常、図の階層構造が含まれます:
- コンテキスト図(レベル0): 最上位の視点です。システムを外部エンティティと相互作用する単一のプロセスとして示します。システムの境界を定義します。
- レベル1図: コンテキスト図の主要プロセスを主要なサブプロセスに分解します。主なデータストアと主要なフローを明らかにします。
- レベル2図: レベル1の特定のプロセスを、より細かいステップにさらに分解します。
トラブルシューティングは通常、コンテキストレベルから始まり、下位へと連鎖的に進みます。上位レベルでの不整合は、すべての下位レベルの図にエラーを伝搬させます。
四つの基本的な誤り 🚫
DFDに頻繁に現れる四つの特定の論理的誤りがあります。これらの誤りを特定するには、各プロセスのデータ入力と出力について注意深く検討する必要があります。
1. ブラックホール
ブラックホールとは、プロセスに入力はあるが出力がない状態を指します。これは、データがプロセスに入り、何の結果や変換も記録されずに消えてしまうことを意味します。現実のシステムでは、このような状態は不可能です。すべての入力は、データの保存、応答の送信、レコードの更新など、何らかのアクションを引き起こすべきです。
修正方法:
- プロセスに入力されるすべてのデータフローを追跡する。
- このプロセスがレポートの生成、データベースの更新、または通知の発動を意図しているかどうかを確認する。
- 出力が存在しない場合、データの保存を確保するために必要なデータフローを追加する。
2. ミラクル
ブラックホールの反対はミラクルです。これは、プロセスが入力なしに出力を生成する状態を指します。データが空から生成されていることを示唆しており、これは重大な論理的欠陥です。すべてのデータは、システム内または外部のどこかから起源を持たなければなりません。
修正方法:
- 生成されているデータ要素を特定する。
- このデータの出所を特定する(例:ユーザー入力、センサー読み取り、または以前のプロセス)。
- プロセスのバブルに欠けている入力フローを追加する。
3. ダンギングデータ
ダンギングデータとは、何にも接続されていないフローを指します。これは、図の途中で突然途切れる線、または空白の領域に接続される線のことを意味します。データパスの途切れを示しています。
修正方法:
- すべての矢印が、発信元から受信先へと接続されていることを確認する。
- データストアまたは外部エンティティが欠落していないか確認してください。
- 宛先プロセスが実際にこの特定のデータ要素を必要としているか確認してください。
4. 名前付けの不整合
データフローはすべてのレベルで一貫したラベル付けが必要です。レベル1の図で「カスタマーオーダー」とラベル付けされたフローが、レベル2の図で「購入依頼」と再命名されるべきではありません。これは意味が根本的に変わった場合を除きます。名前付けの不整合はステークホルダーおよび開発者を混乱させます。
修正方法:
- 用語の標準化のためにデータ辞書を作成する。
- 親図と子図の間でクロスリファレンスチェックを行う。
- プロセスに入力するフローの名前と、同じプロセスから出力するフローの名前が一致していることを確認する(変換された場合を除く)。
プロセスの粒度と分解 🧩
DFDにおける最も一般的な問題の一つは、不適切な分解です。プロセスバブルは大きすぎても(論理が多すぎる)、小さすぎても(単純なステップ)いけません。
プロセスが多すぎる
レベル1の図に7~9個以上のプロセスがあると、読みやすく管理しにくくなります。これは、アナリストが関連する機能をまとめていないことを示していることが多いです。
- 解決策:プロセスを機能領域またはビジネス能力ごとにグループ化する。
- 解決策:プロセスが2つの異なる論理的機能を処理している場合、2つの別々のプロセスに分割すべきかどうか検討する。
プロセスが少なすぎる
逆に、プロセスがユーザーのログインからデータベースのバックアップまですべてを処理している場合は、複雑すぎると言えます。これでは、そのバブル用に特定のアルゴリズムやインターフェースを設計することが不可能になります。
- 解決策:複雑なプロセスを、レベル2の図用にサブプロセスに分解する。
- 解決策:各プロセスが単一の動詞+名詞の名前を持つことを確認する(例:「ログイン検証」ではなく「ログインと検証と保存」など)。
データストアの整合性 🗄️
データストアは、将来の使用のためにデータを保存するリポジトリを表します。ここでのエラーは、データの損失や破損を引き起こす可能性があります。
データストアの欠落
プロセスが後で取得するために情報を保存する必要があるときに、データストアを追加することを忘れることはよくあります。たとえば、「注文処理」機能は取引が完了する前に注文詳細をどこかに保存しなければなりません。
- 確認:対応するデータストアの接続がない状態の変更を行うプロセスを探してください。
データフローの方向が誤っている
データストアを接続する矢印は、データ移動の正しい方向を示す必要があります。データストアからプロセスへのフローはデータの読み取りを意味します。プロセスからデータストアへのフローはデータの書き込みを意味します。これらを混同すると、データベース設計における論理エラーを引き起こす可能性があります。
- 確認:読み取り操作がストアからプロセスへ向かうことを確認する。
- 確認:書き込み操作がプロセスからストアへ向かうことを確認する。
検証と検証技術 🧐
図が描かれた後は、実際のビジネス要件に基づいて検証されなければなりません。いくつかの技術が正確性を確保するのを助けます。
1. データ保存則
この規則は、プロセスの入力と出力が、記述された機能を実行するのに十分でなければならないと述べています。プロセスが「税金を計算する」とラベル付けされている場合、入力には課税対象額と税率が含まれ、出力には計算された税額が含まれなければなりません。
2. プロセス分解則
レベル1の入力と出力は、レベル2の子プロセスの集約された入力と出力と一致しなければなりません。レベル1の図で「注文処理」のバブルに入力として「顧客ID」が入っている場合、レベル2の子図では「顧客ID」が少なくとも1つの子プロセスに入力されていることを示さなければなりません。
3. バランスチェック
親プロセスに入力されるデータフローが、子プロセスの集合に入力されるデータフローと同一であることを確認する。これにより階層の整合性が保たれる。
一般的なトラブルシューティングチェックリスト 📋
以下の表を使って、図を体系的に確認する。
| 問題の種類 | 説明 | 影響 | 是正ステップ |
|---|---|---|---|
| ブラックホール | プロセスに入力はあるが、出力がない | データ損失;ワークフローの破綻 | 出力フローを追加するか、プロセス機能を再定義する |
| ミラクル | プロセスに出力はあるが、入力がない | 無効なデータの生成 | データの元を追跡し、入力フローを追加する |
| ドロップンフロー | 矢印が何にも接続されていない | データパスの破損 | 適切なエンティティ、プロセス、またはストアに接続する |
| 名前付けの不整合 | 同じデータが異なる名前で呼ばれている | 開発者による混乱 | データ辞書内の用語を統一する |
| バランスの取れていない分解 | 子要素の入出力が親要素と異なる | 階層における論理的な穴 | フローを親プロセスに合わせて調整する |
命名規則と明確さ 🏷️
明確な命名はステークホルダーとのコミュニケーションにとって不可欠です。プロセス名は動詞の後に名詞を付ける(例:「在庫を更新する」)ようにします。データフロー名は名詞にする(例:「在庫レポート」)ようにします。
命名に関する問題をトラブルシューティングする際は:
- 略語を避ける:組織内で普遍的に理解されている略語でない限り、略語を使わず、完全な単語を使用する。
- 具体的にする:「データ」はあまりに漠然としている。代わりに「顧客住所」や「支払い記録」を使用する。
- 時制の一貫性:プロセス名は現在形で統一する(「レポートを生成する」、ではなく「レポートを生成した」ではない)。
他のモデルとの統合 🔄
データフローダイアグラムは孤立して存在するものではない。しばしば他のモデリング手法と整合させる必要がある。
エンティティ関係図(ERD)
DFDのデータストアは、ERDで定義されたテーブルと一致するべきである。DFDに「顧客情報」というデータストアがあるが、ERDには「ユーザー」と「連絡先詳細」がある場合、DFDは物理的なデータベース構造を反映するように調整が必要である。
状態遷移図
DFDはデータの移動に注目するが、状態図はシステムの状態に注目する。DFD内のプロセスが、状態図で特定された状態変化を正しく引き起こしていることを確認する。
図の時間経過に伴う維持管理 📅
システムは進化する。要件段階で作成されたDFDは、実装段階後に古くなりうる。維持管理にはバージョン管理戦略が必要である。
- バージョン管理:各図にバージョン番号と日付をラベル付ける。
- 変更履歴:変更の理由を記録する(例:「新しい決済ゲートウェイを反映するために更新」)。
- レビュー周期: ビジネス関係者との定期的なレビューをスケジュールして、図がビジネスの現実と一致していることを確認する。
ツール対手動レビュー 🖥️
DFD作成を支援するモデリングツールは存在するが、万能ではない。自動化ツールは文法エラー(たとえば、端が切れた線)をチェックできるが、ビジネス論理を検証することはできない。人間のアナリストが図を確認し、ビジネス運用の文脈で意味があるかどうかを確認する必要がある。
汎用的なモデリングソフトウェアを使用する際は:
- 組み込みの検証機能を活用して、基本的な接続性を確認する。
- ソフトウェアにプロセスの名前を任せず、人間の判断を用いる。
- 編集を無効にした状態でステークホルダーのレビュー用に図をPDF形式でエクスポートする。
事例研究:小売システムのトラブルシューティング 🛒
ユーザー受入テスト中に小売システムのDFDが失敗した状況を考えてみよう。
問題点
ユーザーは、売上が行われた際に在庫レベルが更新されないという報告をした。レベル1の図では、「売上処理」というプロセスが「売上詳細」を入力として受け取っていると表示されていた。
診断
レベル2の分解を詳細に確認したところ、「売上処理」のバブルが「合計計算」と「取引記録」に分割されていた。しかし、「取引記録」から「在庫ストア」へのデータフローが欠落していた。プロセス自体は出力を持っていたにもかかわらず、在庫側に典型的なブラックホールが存在していた。
解決策
アナリストは、「取引記録」プロセスから「在庫ストア」へのデータフロー「在庫更新」を追加した。システムを再テストしたところ、在庫レベルが正しく更新された。
アナリストのためのベストプラクティス 👨💻
将来のトラブルシューティング作業を最小限に抑えるため、初期段階から以下の実践を採用しよう:
- 小さなステップから始める:分解する前に、明確なコンテキスト図から始めること。
- テンプレートを使用する:プロセス(丸角長方形)とデータストア(開口長方形)に標準的な形状を採用し、混乱を避ける。
- ステークホルダーと連携する:ビジネスユーザーと一緒に図を確認する。流れが理解できていれば、おそらく正しい。
- 繰り返し作成する:図を何度も書き直すことを想定する。初稿はほとんどが最終版ではない。
システム整合性に関する結論 ✅
データフローダイアグラムのトラブルシューティングは、システムの信頼性を確保するための重要なスキルである。4つの基本的な誤りを理解し、命名の一貫性を保ち、ビジネスルールに基づいて検証することで、アナリストは堅牢なモデルを作成できる。これらのモデルは開発者のための設計図となり、最終的なソフトウェアが意図した通りに動作することを保証する。
定期的なレビューとデータ保存則の遵守により、論理的な穴を防ぐことができる。DFDは技術文書であると同時に、コミュニケーションツールでもあることを忘れないでほしい。読者の理解のしやすさは、機械の正確さと同じくらい重要である。