











Datenflussdiagramme (DFDs) dienen als grundlegendes Werkzeug in der Systemanalyse und -gestaltung. Sie bieten eine visuelle Darstellung, wie Daten durch ein System fließen, und heben Prozesse, Datenspeicher, externe Entitäten und die Verbindungsflüsse zwischen ihnen hervor. Die Erstellung eines gültigen DFD ist jedoch nicht immer einfach. Fehler können sich während des Modellierungsprozesses einschleichen und zu logischen Widersprüchen führen, die die gesamte Systemarchitektur beeinträchtigen.
Diese Anleitung bietet einen umfassenden Ansatz zur Identifizierung und Behebung häufiger Probleme in Datenflussdiagrammen. Durch die Anwendung strukturierter Fehlerbehebungsverfahren können Analysten sicherstellen, dass ihre Modelle die Systemanforderungen und betrieblichen Gegebenheiten genau widerspiegeln.
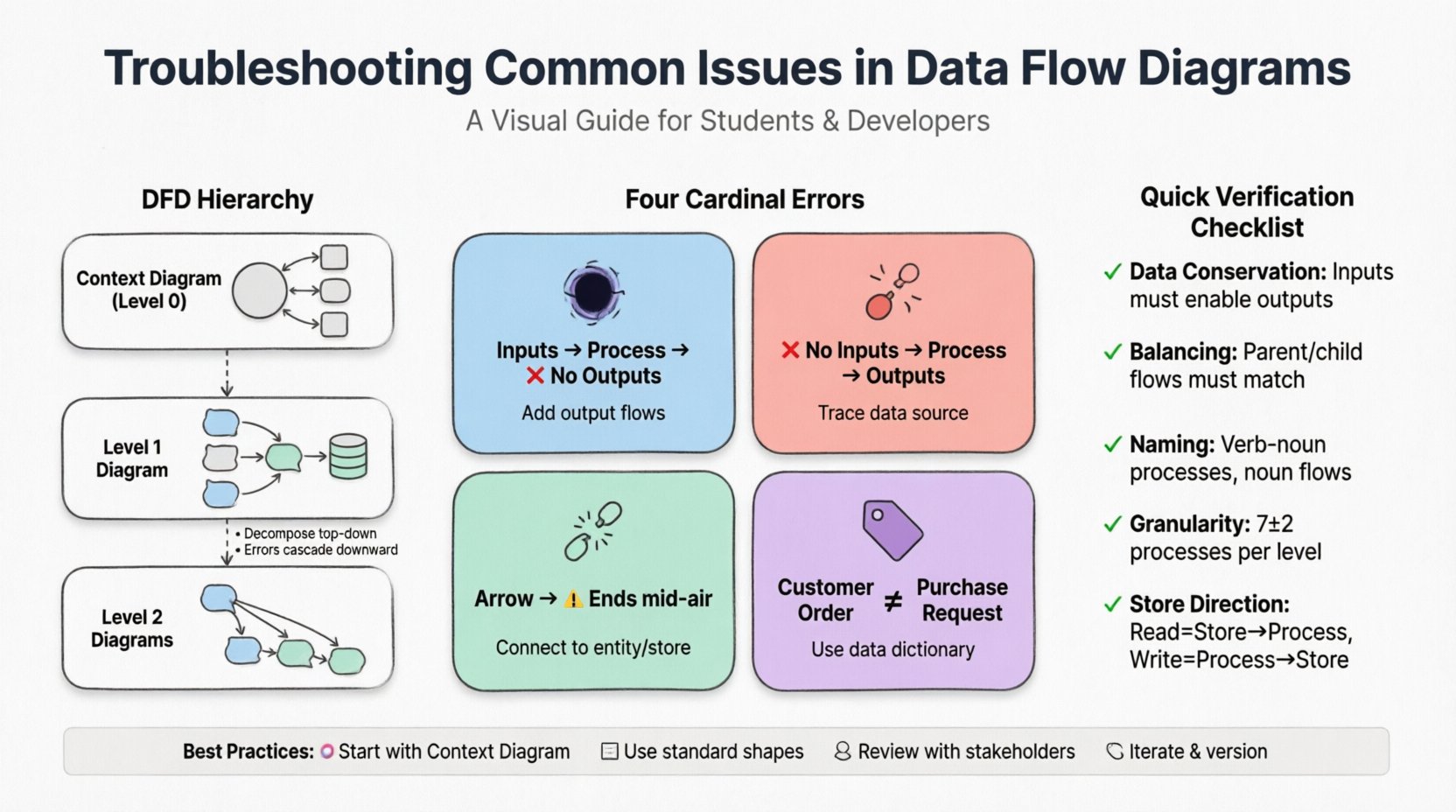
Verständnis der Hierarchie von DFDs 🏗️
Bevor spezifische Fehler behoben werden, ist es unerlässlich, die Struktur eines DFD zu verstehen. Eine vollständige Modellierungsarbeit beinhaltet typischerweise eine Hierarchie von Diagrammen:
- Kontextdiagramm (Ebene 0): Die höchste Ebene. Es zeigt das System als einen einzigen Prozess, der mit externen Entitäten interagiert. Es definiert die Systemgrenzen.
- Diagramm der Ebene 1: Zerlegt den Hauptprozess aus dem Kontextdiagramm in wesentliche Teilprozesse. Es zeigt die primären Datenspeicher und die wichtigsten Flüsse auf.
- Diagramme der Ebene 2: Zerlegt spezifische Prozesse aus der Ebene 1 in detailliertere Schritte.
Die Fehlerbehebung beginnt oft auf der Kontextebene und läuft nach unten ab. In Konsistenzen auf der obersten Ebene führen zu Fehlern, die sich durch alle unteren Diagramme ausbreiten.
Die vier grundlegenden Fehler 🚫
Es gibt vier spezifische Arten logischer Fehler, die häufig in DFDs auftreten. Die Identifizierung dieser erfordert eine sorgfältige Überprüfung der Daten-Eingaben und -Ausgaben für jeden Prozess.
1. Das Schwarze Loch
Ein Schwarzes Loch tritt auf, wenn ein Prozess Eingaben hat, aber keine Ausgaben. Das bedeutet, dass Daten in den Prozess eintreten und ohne jegliche Ergebnis- oder Umwandlungsaktion verschwinden. In einem realen System ist dies unmöglich. Jede Eingabe sollte eine Aktion auslösen, sei es das Speichern von Daten, das Senden einer Antwort oder das Aktualisieren eines Datensatzes.
So behebt man es:
- Verfolge jeden Datenfluss, der in den Prozess eintritt.
- Stelle sicher, ob der Prozess einen Bericht generieren, eine Datenbank aktualisieren oder eine Benachrichtigung auslösen soll.
- Falls keine Ausgabe existiert, füge die notwendigen Datenflüsse hinzu, um die Datenkonservierung zu gewährleisten.
2. Das Wunder
Das Gegenteil eines Schwarzen Lochs ist ein Wunder. Das tritt auf, wenn ein Prozess Ausgaben erzeugt, ohne Eingaben zu haben. Es deutet darauf hin, dass Daten aus dem Nichts entstehen. Dies ist ein kritischer logischer Fehler, da jeder Datenbestand irgendwo innerhalb des Systems oder von einer externen Quelle stammen muss.
So behebt man es:
- Identifiziere das produzierte Datenobjekt.
- Bestimme die Quelle dieses Datenbestands (z. B. eine Benutzereingabe, eine Sensormessung oder ein vorheriger Prozess).
- Füge den fehlenden Eingangsfluss zur Prozessblase hinzu.
3. Hängende Daten
Hängende Daten beziehen sich auf einen Fluss, der mit nichts verbunden ist. Dies könnte eine Linie sein, die mitten im Diagramm abrupt endet oder mit einem leeren Raum verbunden ist. Es deutet auf eine Unterbrechung im Datenpfad hin.
So behebt man es:
- Stelle sicher, dass jeder Pfeil eine Quelle mit einer Zielstelle verbindet.
- Überprüfen Sie, ob ein Datenspeicher oder eine externe Entität fehlt.
- Stellen Sie sicher, dass der Zielprozess tatsächlich dieses spezifische Datenelement benötigt.
4. Inkonsistente Benennung
Datenflüsse müssen auf allen Ebenen konsistent benannt werden. Wenn ein Fluss in der Diagrammstufe 1 als „Kundenbestellung“ bezeichnet ist, sollte er nicht in der Diagrammstufe 2 in „Bestellanfrage“ umbenannt werden, es sei denn, die Bedeutung hat sich grundlegend geändert. Inkonsistente Benennungen verwirren Stakeholder und Entwickler.
Wie behebt man es:
- Erstellen Sie ein Datenwörterbuch, um die Terminologie zu standardisieren.
- Führen Sie eine Querverweisprüfung zwischen Eltern- und Kinddiagrammen durch.
- Stellen Sie sicher, dass der Name eines Flusses, der einen Prozess betritt, mit dem Namen des Flusses übereinstimmt, der denselben Prozess verlässt (es sei denn, er wurde transformiert).
Prozessgranularität und Zerlegung 🧩
Eine der häufigsten Probleme bei DFDs ist eine falsche Zerlegung. Ein Prozesskäfig sollte weder zu groß (zu viel Logik) noch zu klein (triviale Schritte) sein.
Zu viele Prozesse
Wenn ein Diagramm der Stufe 1 mehr als sieben bis neun Prozesse hat, wird es schwierig zu lesen und zu verwalten. Dies deutet oft darauf hin, dass der Analyst verwandte Funktionen nicht zusammengefasst hat.
- Lösung: Gruppieren Sie Prozesse nach funktionalen Bereichen oder Geschäftsfähigkeiten.
- Lösung: Überlegen Sie, ob ein Prozess in zwei getrennte Prozesse aufgeteilt werden sollte, wenn er zwei unterschiedliche logische Funktionen erfüllt.
Zu wenige Prozesse
Umgekehrt ist ein Prozess, der für alles von der Benutzeranmeldung bis zur Datenbanksicherung verantwortlich ist, zu komplex. Dadurch ist es unmöglich, spezifische Algorithmen oder Schnittstellen für diesen Käfig zu entwerfen.
- Lösung: Zerlegen Sie komplexe Prozesse in Unterverfahren für Diagramme der Stufe 2.
- Lösung: Stellen Sie sicher, dass jeder Prozess einen einzigen Verb-Nomen-Namen hat (z. B. „Anmeldung überprüfen“ statt „Anmelden und Überprüfen und Speichern“).
Integrität der Datenspeicher 🗄️
Datenspeicher stellen die Speicherorte dar, an denen Daten für zukünftige Verwendung gespeichert werden. Fehler hier können zu Datenverlust oder -korruption führen.
Fehlende Datenspeicher
Es ist häufig, einen Datenspeicher zu vergessen, wenn ein Prozess Informationen für die spätere Abrufung speichern muss. Zum Beispiel muss eine Funktion „Bestellung verarbeiten“ die Bestelldetails an einer Stelle speichern, bevor die Transaktion abgeschlossen ist.
- Überprüfen: Suchen Sie nach Prozessen, die den Zustand ändern, ohne eine entsprechende Verbindung zu einem Datenspeicher zu haben.
Falsche Richtung des Datenflusses
Pfeile, die Datenspeicher verbinden, müssen die richtige Richtung der Datenbewegung anzeigen. Ein Fluss von einem Datenspeicher zu einem Prozess bedeutet Datenlesen. Ein Fluss von einem Prozess zu einem Datenspeicher bedeutet Daten schreiben. Die Verwechslung dieser kann zu logischen Fehlern bei der Datenbankgestaltung führen.
- Prüfen:Stellen Sie sicher, dass Leseoperationen von Store zu Prozess gehen.
- Prüfen:Stellen Sie sicher, dass Schreiboperationen von Prozess zu Store gehen.
Verifizierungs- und Validierungstechniken 🧐
Sobald das Diagramm gezeichnet ist, muss es den tatsächlichen Geschäftsanforderungen gegenüber validiert werden. Mehrere Techniken helfen, die Genauigkeit zu gewährleisten.
1. Die Regel der Datenkonservierung
Diese Regel besagt, dass die Eingaben und Ausgaben eines Prozesses ausreichend sein müssen, um die beschriebene Funktion auszuführen. Wenn ein Prozess als „Steuer berechnen“ gekennzeichnet ist, müssen die Eingaben den steuerbaren Betrag und die Steuersatz enthalten, und die Ausgabe muss der berechnete Steuerbetrag sein.
2. Die Regel der Prozessdekomposition
Eingaben und Ausgaben auf Ebene 1 müssen mit den aggregierten Eingaben und Ausgaben der untergeordneten Prozesse auf Ebene 2 übereinstimmen. Wenn das Diagramm auf Ebene 1 eine Eingabe „Kunden-ID“ zeigt, die in die „Auftrag verarbeiten“-Blase eingeht, muss das Diagramm auf Ebene 2 zeigen, dass die „Kunden-ID“ in mindestens einen der untergeordneten Prozesse eingeht.
3. Ausgleichsprüfung
Stellen Sie sicher, dass die Datenflüsse, die in einen übergeordneten Prozess eintreten, identisch sind mit den Datenflüssen, die in die Sammlung der untergeordneten Prozesse eintreten. Dies gewährleistet die Integrität der Hierarchie.
Häufige Fehlerbehebungs-Checkliste 📋
Verwenden Sie die folgende Tabelle, um Ihre Diagramme systematisch zu überprüfen.
| Problemart | Beschreibung | Auswirkung | Maßnahme zur Behebung |
|---|---|---|---|
| Schwarzes Loch | Prozess hat Eingaben, aber keine Ausgaben | Datenverlust; unterbrochener Ablauf | Fügen Sie Ausgabeströme hinzu oder definieren Sie die Prozessfunktion neu |
| Wunder | Prozess hat Ausgaben, aber keine Eingaben | Ungültige Datengenerierung | Verfolgen Sie die Datenquelle und fügen Sie Eingabeströme hinzu |
| Hängender Fluss | Pfeil ist mit nichts verbunden | Unterbrochener Datenpfad | Verbinden Sie mit der entsprechenden Entität, einem Prozess oder Speicher |
| Namenskonventionen unklar | Daten mit unterschiedlichen Namen benannt | Verwirrung für Entwickler | Standardisieren Sie die Terminologie im Datenwörterbuch |
| Ungleichgewichtige Zerlegung | Kind-Eingaben/Ausgaben unterscheiden sich von Eltern | Logiklücken in der Hierarchie | Passen Sie die Flüsse an den übergeordneten Prozess an |
Namenskonventionen und Klarheit 🏷️
Klare Benennung ist entscheidend für die Kommunikation mit Stakeholdern. Prozessnamen sollten Verben gefolgt von Substantiven sein (z. B. „Bestand aktualisieren“). Namensbezeichnungen für Datenflüsse sollten Substantive sein (z. B. „Bestandsbericht“).
Beim Beheben von Namensproblemen:
- Vermeiden Sie Abkürzungen:Verwenden Sie vollständige Wörter, es sei denn, die Abkürzung ist innerhalb der Organisation allgemein verständlich.
- Seien Sie präzise: „Daten“ ist zu ungenau. Verwenden Sie „Kundenadresse“ oder „Zahlungsprotokoll“.
- Konsistente Zeitform:Halten Sie Prozessnamen in der Gegenwart (z. B. „Bericht generieren“, nicht „Bericht generiert“).
Integration mit anderen Modellen 🔄
Datenflussdiagramme existieren nicht isoliert. Sie müssen oft mit anderen Modellierungstechniken abgestimmt werden.
Entitäts-Beziehungs-Diagramme (ERD)
DFD-Datenbestände sollten mit den Tabellen übereinstimmen, die in einem ERD definiert sind. Wenn ein DFD einen Datenbestand „Kundeninfo“ zeigt, aber das ERD „Benutzer“ und „Kontaktdaten“ enthält, muss das DFD angepasst werden, um die physische Datenbankstruktur widerzuspiegeln.
Zustandsübergangsdiagramme
DFDs konzentrieren sich auf die Datenbewegung, während Zustandsdiagramme sich auf Systemzustände konzentrieren. Stellen Sie sicher, dass die Prozesse im DFD die in dem Zustandsdiagramm identifizierten Zustandsänderungen korrekt auslösen.
Pflege des Diagramms im Laufe der Zeit 📅
Systeme entwickeln sich weiter. Ein DFD, der in der Anforderungsphase erstellt wurde, kann nach der Implementierungsphase veraltet sein. Die Pflege erfordert eine Versionskontrollstrategie.
- Versionsverwaltung:Kennzeichnen Sie jedes Diagramm mit einer Versionsnummer und einem Datum.
- Änderungsprotokolle:Dokumentieren Sie, warum eine Änderung vorgenommen wurde (z. B. „Aktualisiert, um neuen Zahlungsgateway widerzuspiegeln“).
- Überprüfungszyklen: Planen Sie regelmäßige Überprüfungen mit den Geschäftssachverständigen, um sicherzustellen, dass das Diagramm weiterhin der Geschäftswirklichkeit entspricht.
Tools im Vergleich zur manuellen Überprüfung 🖥️
Obwohl Modellierungstools existieren, um die Erstellung von DFDs zu unterstützen, sind sie nicht fehlerfrei. Automatisierte Werkzeuge können auf Syntaxfehler (wie lose Enden) prüfen, können aber kein Geschäftslogik überprüfen. Ein menschlicher Analyst muss das Diagramm überprüfen, um sicherzustellen, dass es im Kontext der Geschäftsprozesse sinnvoll ist.
Wenn Sie generische Modellierungssoftware verwenden:
- Nutzen Sie die integrierten Überprüfungsfeatures, um grundlegende Verbindungen zu prüfen.
- Verlassen Sie sich nicht darauf, dass die Software Ihre Prozesse benennt; verwenden Sie menschliche Urteilsfähigkeit.
- Exportieren Sie Diagramme in PDF-Formate für die Überprüfung durch Stakeholder, bei denen die Bearbeitung deaktiviert ist, um versehentliche Änderungen zu verhindern.
Fallstudie: Fehlerbehebung eines Einzelhandelssystems 🛒
Betrachten Sie eine Situation, in der ein DFD eines Einzelhandelssystems während der Benutzerakzeptanztests fehlgeschlagen ist.
Das Problem
Benutzer berichteten, dass die Lagerbestände sich nicht aktualisierten, wenn Verkäufe getätigt wurden. Das Level-1-Diagramm zeigte einen Prozess „Verkauf bearbeiten“, der „Verkaufsdetails“ als Eingabe erhielt.
Die Diagnose
Bei einer genauen Überprüfung der Level-2-Zerlegung wurde die „Verkauf bearbeiten“-Blase in „Gesamtbetrag berechnen“ und „Transaktion erfassen“ aufgeteilt. Allerdings fehlte der Datenfluss, der „Transaktion erfassen“ mit dem „Lagerbestand“ verband. Dies war ein klassischer Black Hole auf der Lagerseite, obwohl der Prozess selbst eine Ausgabe hatte.
Die Lösung
Analysten fügten den Datenfluss „Lageraktualisierung“ vom Prozess „Transaktion erfassen“ zum „Lagerbestand“ hinzu. Das System wurde erneut getestet, und die Lagerbestände wurden korrekt aktualisiert.
Best Practices für Analysten 👨💻
Um zukünftige Fehlerbehebungsarbeiten zu minimieren, übernehmen Sie diese Praktiken von Anfang an:
- Beginnen Sie klein:Beginnen Sie mit einem klaren Kontextdiagramm, bevor Sie zerlegen.
- Verwenden Sie Vorlagen:Verwenden Sie standardisierte Formen für Prozesse (abgerundete Rechtecke) und Datenbestände (offene Rechtecke), um Verwirrung zu vermeiden.
- Engagieren Sie Stakeholder:Gehen Sie das Diagramm gemeinsam mit den Geschäftsanwendern durch. Wenn sie den Ablauf verstehen, ist es wahrscheinlich korrekt.
- Iterieren:Erwarten Sie, Diagramme mehrfach neu zu zeichnen. Der erste Entwurf ist selten die endgültige Version.
Fazit zur Systemintegrität ✅
Die Fehlerbehebung von Datenflussdiagrammen ist eine entscheidende Fähigkeit, um die Systemzuverlässigkeit zu gewährleisten. Durch das Verständnis der vier grundlegenden Fehler, die Einhaltung der Namenskonventionen und die Überprüfung anhand von Geschäftsregeln können Analysten robuste Modelle erstellen. Diese Modelle dienen als Bauplan für Entwickler und stellen sicher, dass die endgültige Software wie vorgesehen funktioniert.
Regelmäßige Überprüfungen und die Einhaltung der Datenkonservierungsregeln verhindern logische Lücken. Denken Sie daran, dass ein DFD ebenso ein Kommunikationsinstrument wie ein technisches Dokument ist. Klarheit für den Leser ist genauso wichtig wie Genauigkeit für die Maschine.