










複雑なシステムのアーキテクチャにおいて、明確さは最も価値ある通貨である。データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを可視化するための基盤となる。DFDは制御論理やタイミングを示すものではなく、プロセス、データ保管所、外部エントリとの間のデータの流れに焦点を当てる。このガイドは、特定のツールや独自ソフトウェアに依存せずに、堅牢なシステム設計を確保するために、DFDのメカニズム、ルール、戦略的応用を検討する。
データフローダイアグラムとは何か? 📊
データフローダイアグラムとは、情報システム内を通過するデータの流れを図式化したものである。フローチャートがイベントの順序や制御論理をマッピングするのに対し、DFDはデータの入力と出力にのみ焦点を当てる。この問いに答える:データはどこから来て、どこへ向かうのか、そしてどのように変換されるのか?
DFDは要件収集段階において不可欠である。ステークホルダーがプロジェクトの範囲を可視化し、重要なデータストリームを特定するのを助ける。実装の詳細を抽象化することで、DFDはチームがシステムの機能要件に集中できるようにする。
DFDが重要な理由
- コミュニケーション: 技術チームと非技術的ステークホルダーの間の溝を埋める。
- ドキュメント化: 将来の保守のためのシステム論理の持続可能な記録を提供する。
- 分析: ボトルネック、重複、欠落しているデータ経路を特定するのを助ける。
- 検証: すべてのデータ要件が満たされているかを確認するためのチェックリストとして機能する。
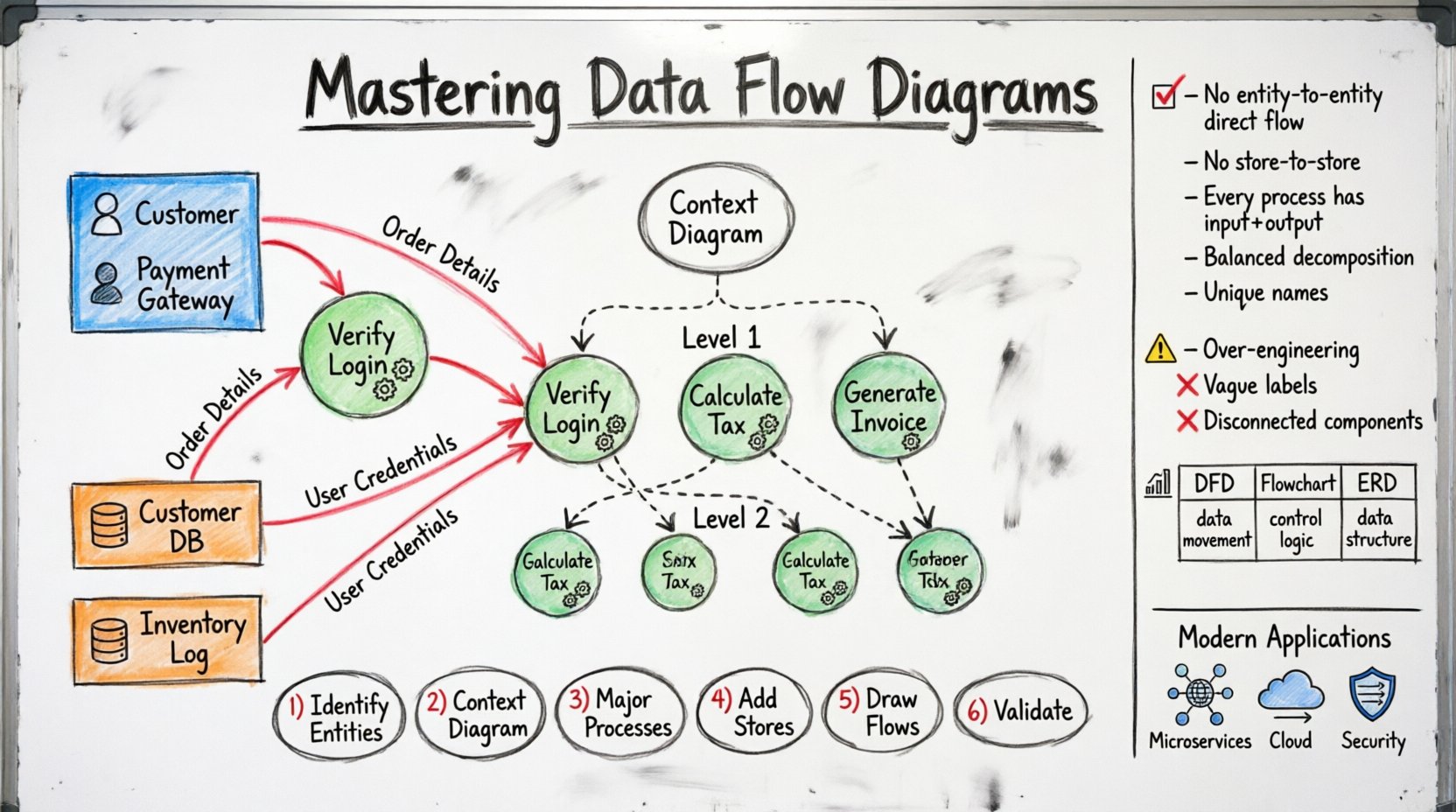
DFDの核心的構成要素 🧩
すべてのDFDは4つの主要な要素で構成される。これらの構成要素を理解することは、正確なモデリングにとって不可欠である。
1. 外部エントリ(情報の発信元および到着先) 🚦
外部エントリは、モデル化されているシステムとやり取りする人々、組織、または他のシステムを表す。データの発信元または到着先ではあるが、システム境界の外にある。
- 例:顧客、仕入先、決済ゲートウェイ、規制機関。
- 表記法:通常、長方形または正方形で表される。
2. プロセス(変換装置) 🔄
プロセスは入力データを出力データに変換する。計算を実行したり、記録を更新したり、情報を検証したりする。プロセスには少なくとも1つの入力と1つの出力が必要である。
- 例:「税金を計算する」、「ログインを検証する」、「請求書を生成する」。
- 表記法: 通常、円または角が丸い長方形です。
3. データストア(リポジトリ) 🗂️
データストアは、後で使用するためのデータを保持します。データベース、ファイル、またはシステム内の物理的なストレージ場所を表します。
- 例:顧客データベース、在庫ログ、設定ファイル。
- 記法:通常、開口部のある長方形または平行線です。
4. データフロー(接続線) 🛣️
データフローは、エンティティ、プロセス、ストア間でのデータの移動を示します。すべての矢印には、転送中のデータを説明するラベルが必要です。
- 方向:フローは方向性を持ちます。データは1つのコンポーネントから別のコンポーネントへ移動します。
- ラベル付け:具体的でなければならない(たとえば、「データ」ではなく「注文詳細」など)。
分解の段階 📉
DFDは階層的です。複雑なシステムは1つのビューでは理解できません。複雑さを管理するために、段階的に分解します。
レベル0:コンテキスト図
コンテキスト図は最も高レベルの視点です。システム全体を1つのプロセスとして示し、外部エンティティとの相互作用を表します。システムの境界を定義します。
- 注目点:システムの範囲。
- 複雑さ:最小限。1つのプロセスノード。
レベル1:高レベルの分解
このレベルでは、コンテキスト図の単一プロセスを主要なサブプロセスに分解します。システムの主要な機能領域を明らかにします。
- 注目点:主要な機能モジュール。
- 詳細:主要なデータストアと重要なフローを示します。
レベル2:詳細な論理
レベル1のプロセスをさらに具体的なタスクに分解します。このレベルは、実装計画にしばしば使用されます。
- 注目点: 特定の論理パス。
- 詳細: 細かいデータ変換ステップ。
レベル3およびそれ以上
極めて複雑なサブシステムに使用される。ほとんどの場合、レベル2の詳細で開発チームにとって十分である。
ルールと規則 ⚖️
正確性を保つため、DFDは特定のルールに従わなければならない。これらの規則に違反すると、曖昧なシステム設計につながる可能性がある。
ルール1:外部エンティティ間には直接のデータフローがないこと
データは、外部エンティティの間を直接流れることはできない。処理または検証のために、システム(プロセス)を経由しなければならない。
ルール2:データストア間には直接のフローがないこと
データは2つのデータストアの間を直接移動することはできない。整合性を確保するために、プロセスが転送を仲介しなければならない。
ルール3:すべてのプロセスには入力と出力が必要であること
入力のないプロセスは「奇跡」(何もからデータを生成する)である。出力のないプロセスは「ブラックホール」(結果のないデータの消費)である。両方とも誤りである。
ルール4:データフローのバランス
プロセスがサブプロセスに分解されるとき、親レベルと子レベルの間で入力および出力のデータフローが一貫性を保たなければならない。
ルール5:一意の名前付け
各プロセス、エンティティ、ストアには一意の名前を付けることで、混乱を避ける。
DFDと他の図表との比較 🆚
DFDと他のモデリングツールとの間に混乱が生じることが多い。違いを理解することで、適切なツールを適切な目的に使用できる。
| 機能 | データフローダイアグラム(DFD) | フローチャート | エンティティ関係図(ERD) |
|---|---|---|---|
| 焦点 | データの移動と変換 | 制御論理と順序 | データ構造と関係 |
| 主なアクター | システムアナリスト | プログラマー | データベースデザイナー |
| 時間的側面 | なし(静的) | 高(順序が重要) | なし(静的) |
| 最も適した用途 | システム要件 | アルゴリズム設計 | データベーススキーマ |
DFDを作成するためのステップバイステップガイド 🛠️
有効なDFDを作成するには、体系的なアプローチが必要です。正確性を確保するために、以下のステップに従ってください。
ステップ1:外部エンティティを特定する
データのすべてのソースと宛先をリストアップしてください。質問:このシステムとやり取りしているのは誰ですか?外部システムの中で、データを送信しているのはどれですか?
ステップ2:コンテキスト図を定義する
システムを1つのバブルとして描きます。外部エンティティをラベル付きの矢印で接続します。これにより境界が設定されます。
ステップ3:主要なプロセスを特定する
コンテキストバブルを主要な機能領域に分割します。システムが行う主な仕事は何ですか?
ステップ4:データストアを追加する
データが保存される場所を特定します。すべてのストアが少なくとも1つのプロセスに接続されていることを確認してください。
ステップ5:データフローを描く
コンポーネントを矢印で接続します。すべての矢印に、移動している具体的なデータをラベル付けしてください。
ステップ6:検証とバランス調整
ブラックホール、ミラクル、バランスの確認を行います。データが消失したり、魔法のように生成されたりしないようにしてください。
避けたい一般的な落とし穴 🚫
経験豊富なエンジニアでもミスを犯すことがあります。一般的なミスに気づくことで、後で再作業を防げます。
- 過剰設計:レベル0ですべての詳細をモデル化しようとする。高レベルのまま保つこと。
- 制御フローの混乱:ボタンやメニュー、ユーザー操作を含めてしまう。DFDはデータの流れを追跡するものであり、UIイベントではない。
- フィードバックループの欠落: データが検証のためにプロセスに戻るという点を忘れないこと。
- 曖昧なラベル: 「Info」や「Data」などの用語を使用しない。具体的に記述する:「ユーザー資格情報」や「売上レポート」など。
- 接続されていないコンポーネント: フローのないプロセスやストアを残さない。すべての要素は接続されている必要がある。
現代のエンジニアリング文脈におけるDFD 🚀
コアとなる原則は変わらないものの、DFDの適用は現代のアーキテクチャとともに進化している。
マイクロサービスアーキテクチャ
分散システムでは、DFDはAPIの相互作用をマッピングするために不可欠である。サービス間の通信が密結合にならないように可視化するのに役立つ。各サービスはプロセスノードとなり、APIエンドポイントはデータフローとなる。
クラウド統合
クラウドストレージやサードパーティAPIと統合する際、DFDはデータの所在を明確にする。どのデータが内部ネットワークから出るか、どこに保存されるかを判断するのに役立つ。
セキュリティ分析
DFDはセキュリティリスクを特定するのに非常に効果的である。データフローを追跡することで、機密データ(パスワードなど)が露出するか、暗号化されていない状態で送信される可能性がある場所を特定できる。
明確性のためのベストプラクティス ✅
図が効果的であることを確実にするため、以下のスタイルガイドに従う。
- 一貫性:ドキュメント全体で同じ表記スタイルを使用する。
- 色分け:異なる種類のフロー(例:内部 vs. 外部)を区別するために色を使用する。
- 余白:図を詰め込まない。読みやすさを高めるために余白を活用する。
- バージョン管理:図のバージョンを管理する。システムは変化するため、図もそれに合わせて進化しなければならない。
- レビュー会議:ステークホルダーと一緒に図を確認する。曖昧な点は議論の中でしばしば明らかになる。
複雑な論理の扱い 🔀
ときには、論理が標準的なDFDでは扱いきれないほど複雑になることがある。ここではエッジケースの対処方法を説明する。
条件付きフロー
データフローが条件に依存する場合は、ラベルにその条件を記述する。たとえば「有効なログイン」対「無効なログイン」など。判断のダイアモンドを使用せず、プロセスとして扱い続けること。
反復プロセス
ループや繰り返しのアクションの場合、”ループ検証”のように反復を示すプロセス名を使用してください。明確さのために必要でない限り、円形の矢印を描かないでください。
並列処理
複数のプロセスが同時に発生する場合は、視覚的にグループ化するか、異なるサブダイアグラムを使用して線が交差するのを避けてください。
アナリストの役割 🧐
データフローダイアグラムは最終的にコミュニケーションツールです。アナリストはビジネスニーズと技術的現実の間の翻訳者として機能します。
- まず聞くこと:描く前に、ビジネス目標を理解してください。
- 反復する:初稿はほとんど完璧ではありません。修正を想定してください。
- 仮定を疑う:データフローが自明に思える場合でも、確認してください。仮定はギャップを生じます。
- 仮定を文書化する:流れが示されていないが示唆されている場合は、凡例に記録してください。
システムモデリングの将来のトレンド 📈
システムがより動的になると、静的図は課題に直面します。しかし、データフローの基本的な概念は依然として関連性を持ちます。
- 動的DFD:一部の現代的なツールでは、特定の期間におけるデータの移動を示す時間ベースのフローを許可しています。
- 自動生成:コード分析ツールは、ドキュメント作成の目的で、既存のコードベースからDFDを生成し始めています。
- DevOpsとの統合:図は、CI/CDにおけるデータ依存関係を可視化するために、デプロイメントパイプラインとますます連携されています。
主なポイントの要約 📝
データフローダイアグラムは、システムの挙動を理解するために不可欠です。情報の移動を明確な地図として提供し、データが原因なく失われたり生成されたりすることを防ぎます。
- DFDを要件分析に使用する実装コード作成ではなく。
- 4つの構成要素を尊重する:エンティティ、プロセス、ストア、フロー。
- 階層に従う:コンテキスト → レベル0 → レベル1。
- ブラックホールやミラクルを避ける論理的一貫性を保つために。
- すべてを明確にラベル付けする曖昧さを避けるために。
DFDの構造と規則を習得することで、エンジニアは堅牢で保守性が高く、ビジネス目標と整合したシステムを構築できる。データフローの視覚的言語は、特定の技術や手法を越えて、ソフトウェア工学のツールキットにおいて強力な資産のままである。
よくある質問 ❓
Q:プロセスが出力フローなしでデータストアを更新することは可能ですか?
A:いいえ。プロセスは、確認メッセージであっても何らかの出力を生成しなければなりません。更新自体がストアとのやり取りであるとはいえ、プロセスは制御またはデータを戻す必要があります。
Q:ユーザーインターフェースの画面を含めるべきですか?
A:いいえ。UI要素はデータプロセスではありません。ユーザーが外部エンティティやプロセスにデータを入力するためのインターフェースです。
Q:DFDには何段階のレベルを設けるべきですか?
A:通常は2段階または3段階です。3段階を超えると、システムが一度の図セットで効果的にモデル化するには複雑すぎる可能性があります。