










W architekturze złożonych systemów jasność jest najwyższą formą waluty.Schematy przepływu danych (DFD) stanowią fundament do wizualizacji, jak informacje poruszają się przez system. Nie pokazują logiki sterowania ani czasu, lecz przepływ danych między procesami, magazynami danych i zewnętrznymi jednostkami. Ten przewodnik bada mechanizmy, zasady i strategiczne zastosowanie DFD, aby zapewnić solidną projektowanie systemu bez zależności od konkretnych narzędzi czy oprogramowania własnościowego.
Co to jest schemat przepływu danych? 📊
Schemat przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. W przeciwieństwie do schematu blokowego, który odwzorowuje sekwencję zdarzeń lub logikę sterowania, DFD skupia się ściśle na danych wejściowych i wyjściowych. Odpowiada na pytanie:Skąd pochodzi dane, dokąd się idzie i jak jest przekształcane?
DFD są istotne w fazie zbierania wymagań. Pomagają stakeholderom wizualizować zakres projektu i identyfikować kluczowe przepływy danych. Upraszczając szczegóły implementacji, DFD pozwalają zespołom skupić się na wymaganiach funkcyjnych systemu.
Dlaczego DFD mają znaczenie
- Komunikacja: Łączą luki między zespołami technicznymi a niefachowymi stakeholderami.
- Dokumentacja: Zapewniają trwałą dokumentację logiki systemu do przyszłej konserwacji.
- Analiza: Pomagają identyfikować zatory, nadmiarowości i brakujące ścieżki danych.
- Weryfikacja: Służą jako lista kontrolna, aby upewnić się, że wszystkie wymagania dotyczące danych są spełnione.
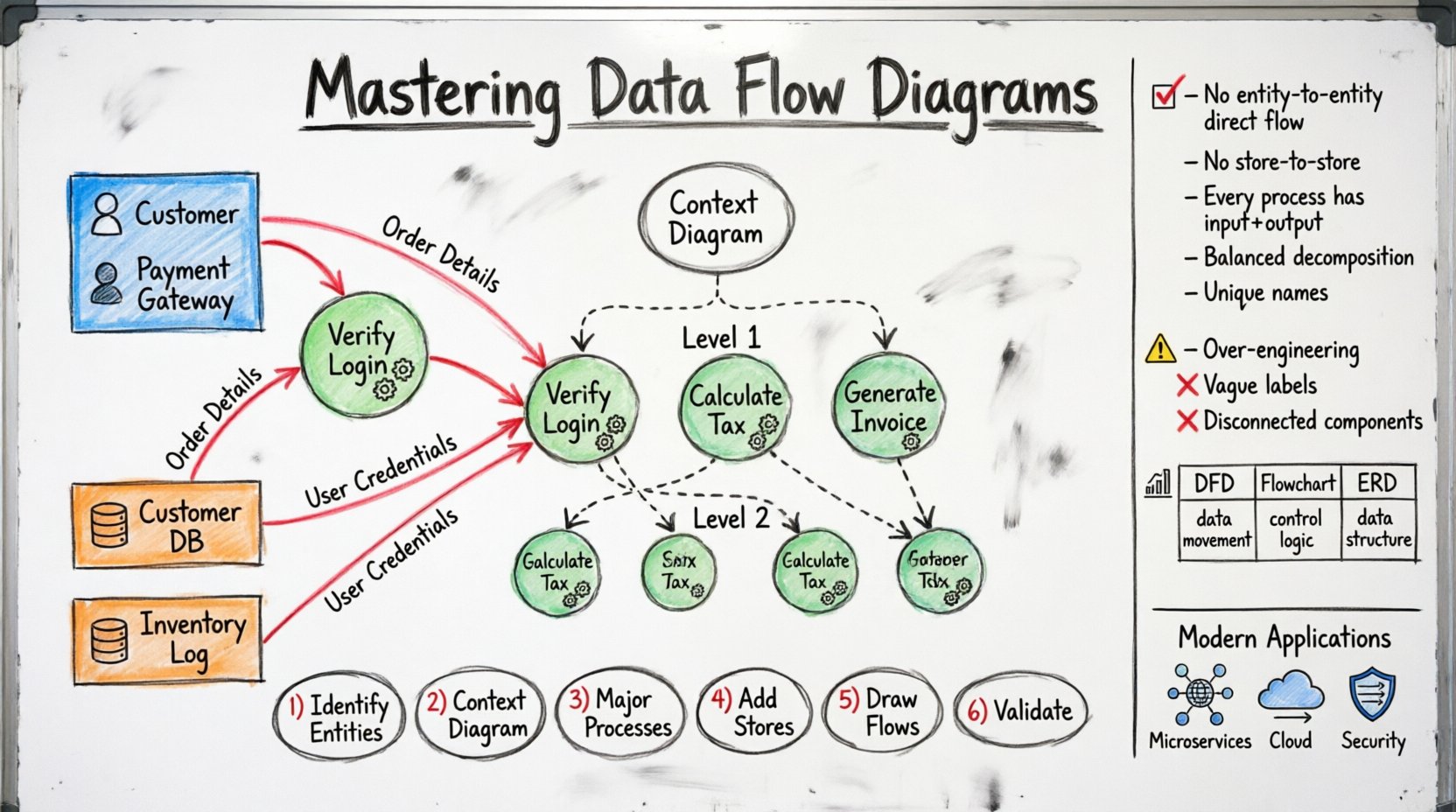
Główne składniki DFD 🧩
Każdy DFD składa się z czterech podstawowych elementów. Zrozumienie tych elementów budujących jest kluczowe dla dokładnego modelowania.
1. Jednostki zewnętrzne (źródło i cel) 🚦
Jednostki zewnętrzne reprezentują osoby, organizacje lub inne systemy, które interagują z modelowanym systemem. Są źródłem lub miejscem docelowym danych, ale znajdują się poza granicami systemu.
- Przykłady:Klienci, dostawcy, bramki płatności, organy regulacyjne.
- Oznaczenia: Zazwyczaj przedstawiane jako prostokąty lub kwadraty.
2. Procesy (przekształtniki) 🔄
Procesy przekształcają dane wejściowe w dane wyjściowe. Wykonują obliczenia, aktualizują rekordy lub weryfikują informacje. Proces musi mieć co najmniej jedno wejście i jedno wyjście.
- Przykłady: „Oblicz podatek”, „Weryfikuj logowanie”, „Wygeneruj fakturę”.
- Oznaczenia: Zazwyczaj okręgi lub zaokrąglone prostokąty.
3. Magazyny danych (repozytoria) 🗂️
Magazyny danych przechowują dane do późniejszego użycia. Odpowiadają bazom danych, plikom lub fizycznym lokalizacjom przechowywania w obrębie systemu.
- Przykłady:Baza danych klientów, dziennik inwentarzowy, plik konfiguracji.
- Oznaczenia: Zazwyczaj otwarte prostokąty lub równoległe linie.
4. Przepływy danych (połączenia) 🛣️
Przepływy danych wskazują ruch danych między jednostkami, procesami i magazynami. Każdy strzałka musi mieć etykietę opisującą przesyłane dane.
- Kierunek: Przepływy są kierunkowe. Dane przemieszczają się z jednego komponentu do drugiego.
- Etykietowanie: Muszą być konkretne (np. „Szczegóły zamówienia” zamiast tylko „Dane”).
Poziomy rozkładu 📉
Diagramy przepływu danych są hierarchiczne. Złożone systemy nie mogą być zrozumiałe w jednym widoku. Rozkładamy je na poziomy, aby zarządzać złożonością.
Poziom 0: Diagram kontekstowy
Diagram kontekstowy to najwyższy poziom widoku. Pokazuje cały system jako pojedynczy proces oraz jego interakcje z jednostkami zewnętrznymi. Określa granice systemu.
- Skupienie: Zakres systemu.
- Złożoność: Minimalna. Jeden węzeł procesu.
Poziom 1: Rozkład na wysokim poziomie
Ten poziom rozkłada pojedynczy proces z diagramu kontekstowego na główne podprocesy. Ujawnia główne obszary funkcjonalne systemu.
- Skupienie:Główne moduły funkcjonalne.
- Szczegóły: Pokazuje główne magazyny danych i kluczowe przepływy.
Poziom 2: Szczegółowa logika
Dalszy rozkład procesów poziomu 1 na konkretne zadania. Ten poziom często wykorzystuje się do planowania wdrożenia.
- Skupienie: Specyficzne ścieżki logiki.
- Szczegóły:Krok po kroku przekształcanie danych.
Poziom 3 i wyżej
Używane dla bardzo złożonych podsystemów. W większości przypadków poziom 2 zapewnia wystarczającą szczegółowość dla zespołów programistycznych.
Zasady i konwencje ⚖️
Aby zachować dokładność, DFD muszą przestrzegać określonych zasad. Naruszenie tych konwencji może prowadzić do niejasnych projektów systemów.
Zasada 1: Brak bezpośredniego przepływu danych między jednostkami
Dane nie mogą przepływać bezpośrednio z jednej jednostki zewnętrznej do drugiej. Muszą przejść przez system (proces), aby zostać przetworzone lub zwalidowane.
Zasada 2: Brak bezpośredniego przepływu między magazynami
Dane nie mogą przemieszczać się bezpośrednio między dwoma magazynami danych. Przepływ musi być pośredniczony przez proces, aby zapewnić integralność.
Zasada 3: Każdy proces wymaga wejścia i wyjścia
Proces bez wejścia to „czud” (tworzenie danych z niczego). Proces bez wyjścia to „czarna dziura” (pochłanianie danych bez rezultatu). Oba są błędami.
Zasada 4: Zrównoważenie przepływu danych
Gdy proces jest rozkładany na podprocesy, przepływy danych wejściowych i wyjściowych muszą pozostawać spójne między poziomem rodzicem a poziomem dziecka.
Zasada 5: Unikalne nazewnictwo
Każdy proces, jednostka i magazyn powinien mieć unikalną nazwę, aby uniknąć nieporozumień.
DFD w porównaniu z innymi diagramami 🆚
Często pojawia się zamieszanie między DFD a innymi narzędziami modelowania. Zrozumienie różnicy zapewnia, że odpowiednie narzędzie jest używane do odpowiedniego zadania.
| Cecha | Diagram przepływu danych (DFD) | Schemat blokowy | Diagram relacji encji (ERD) |
|---|---|---|---|
| Skupienie | Ruch danych i ich przekształcanie | Logika sterowania i sekwencja | Struktura danych i relacje |
| Główny aktor | Analityk systemu | Programista | Projektant bazy danych |
| Aspekt czasu | Brak (stały) | Wysoki (kolejność ma znaczenie) | Brak (stały) |
| Najlepiej używane do | Wymagania systemowe | Projektowanie algorytmu | Schemat bazy danych |
Poradnik krok po kroku tworzenia diagramu przepływu danych 🛠️
Tworzenie poprawnego DFD wymaga systematycznego podejścia. Postępuj zgodnie z tymi krokami, aby zapewnić dokładność.
Krok 1: Zidentyfikuj jednostki zewnętrzne
Wypisz wszystkie źródła i miejsca docelowe danych. Zadaj pytanie: Kto współdziała z tym systemem? Jakie zewnętrzne systemy wysyłają do niego dane?
Krok 2: Zdefiniuj diagram kontekstowy
Narysuj system jako jedną bańkę. Połącz jednostki zewnętrzne strzałkami oznaczonymi etykietami. To ustala granice systemu.
Krok 3: Zidentyfikuj główne procesy
Podziel bańkę kontekstową na główne obszary funkcjonalne. Jakie są główne zadania, które system wykonuje?
Krok 4: Dodaj magazyny danych
Zidentyfikuj, gdzie są przechowywane dane. Upewnij się, że każdy magazyn jest połączony z co najmniej jednym procesem.
Krok 5: Narysuj przepływy danych
Połącz komponenty strzałkami. Oznacz każdą strzałkę konkretnymi danymi, które się przemieszczają.
Krok 6: Weryfikuj i zrównowaguj
Sprawdź obecność czarnych dziur, milionów i zrównoważenia. Upewnij się, że dane nie giną ani nie pojawiają się magicznie.
Typowe pułapki do uniknięcia 🚫
Nawet doświadczeni inżynierowie mogą popełniać błędy. Znajomość typowych błędów zapobiega ponownej pracy w przyszłości.
- Zbyt duża złożoność: Próba modelowania każdego szczegółu na poziomie 0. Zachowaj poziom ogólny.
- Pomyłki związane z przepływem sterowania: Włączanie przycisków, menu lub działań użytkownika. DFD śledzi dane, a nie zdarzenia interfejsu użytkownika.
- Brak pętli zwrotu informacji Zapominanie, że dane często powracają do procesu w celu weryfikacji.
- Nieprecyzyjne etykiety: Używanie terminów takich jak „Info” lub „Dane”. Bądź precyzyjny: „Dane logowania użytkownika” lub „Raport sprzedaży”.
- Rozłączone komponenty: Pozostawianie procesu lub magazynu bez żadnego przepływu. Wszystko musi być połączone.
Schematy przepływu danych w nowoczesnych kontekstach inżynieryjnych 🚀
Choć podstawowe zasady pozostają niezmienione, zastosowanie schematów przepływu danych ewoluowało wraz z nowoczesnymi architekturami.
Architektura mikroserwisów
W systemach rozproszonych schematy przepływu danych są kluczowe do mapowania interakcji interfejsów API. Pomagają wizualizować sposób komunikacji między usługami bez silnego powiązania. Każda usługa staje się węzłem procesu, a punkty końcowe interfejsów API stają się przepływami danych.
Integracja z chmurą
Podczas integracji z chmurą lub interfejsami API firm trzecich, schematy przepływu danych wyjaśniają lokalizację danych. Pomagają określić, które dane opuszczają sieć wewnętrzną i gdzie są przechowywane.
Analiza bezpieczeństwa
Schematy przepływu danych są doskonałe do identyfikowania ryzyk bezpieczeństwa. Śledząc przepływy danych, zespoły mogą wykryć miejsca, w których dane poufne (takie jak hasła) mogą zostać ujawnione lub przesłane bez szyfrowania.
Najlepsze praktyki dla przejrzystości ✅
Aby zapewnić skuteczność Twoich schematów, przestrzegaj tych zaleceń stylistycznych.
- Spójność: Używaj tej samej stylizacji notacji przez cały dokument.
- Kodowanie kolorowe: Używaj kolorów, aby odróżnić różne typy przepływów (np. wewnętrzne vs. zewnętrzne).
- Przestrzeń biała: Nie zatłaczaj schematu. Używaj odstępów, aby poprawić czytelność.
- Wersjonowanie: Śledź wersje schematów. Systemy się zmieniają, a schematy muszą się z nimi rozwijać.
- Sesje przeglądu: Przejrzyj schematy wspólnie z zaangażowanymi stronami. Niejasności często pojawiają się podczas dyskusji.
Obsługa złożonej logiki 🔀
Czasem logika jest zbyt złożona, by mogła być przedstawiona w standardowym schemacie przepływu danych. Oto jak obsłużyć przypadki graniczne.
Przepływy warunkowe
Jeśli przepływ danych zależy od warunku, przedstaw to w etykiecie. Na przykład: „Prawidłowe logowanie” vs. „Nieprawidłowe logowanie”. Nie używaj diamentów decyzyjnych; zachowaj je jako procesy.
Procesy iteracyjne
W przypadku pętli lub powtarzających się działań użyj nazwy procesu sugerującej iterację, np. „Weryfikacja pętli”. Unikaj rysowania strzałek zamkniętych w okręgach, chyba że jest to konieczne dla jasności.
Przetwarzanie równoległe
Jeśli wiele procesów zachodzi jednocześnie, grupuj je wizualnie lub użyj odrębnych podwykresów, aby uniknąć przecięć linii.
Rola analityka 🧐
Diagram przepływu danych jest w końcu narzędziem komunikacyjnym. Analityk pełni rolę tłumacza między potrzebami biznesowymi a rzeczywistością techniczną.
- Najpierw słuchaj:Zrozum cel biznesowy przed rysowaniem.
- Iteruj:Pierwsze szkice rzadko są doskonałe. Przygotuj się na poprawki.
- Wątp w założenia:Jeśli przepływ danych wydaje się oczywisty, zweryfikuj go. Założenia prowadzą do luk.
- Dokumentuj założenia:Jeśli przepływ jest sugerowany, ale nie jest pokazany, zaznacz to w legendzie.
Przyszłe trendy w modelowaniu systemów 📈
W miarę jak systemy stają się bardziej dynamiczne, diagramy statyczne napotykają trudności. Jednak podstawowa koncepcja przepływu danych nadal jest istotna.
- Dynamiczne DFD: Niektóre nowoczesne narzędzia pozwalają na przepływy oparte na czasie, pokazując ruch danych w określonych przedziałach.
- Generowanie automatyczne:Narzędzia analizy kodu zaczynają generować DFD z istniejących baz kodu w celu dokumentacji.
- Integracja z DevOps:Diagramy coraz częściej są łączone z liniami wdrażania, aby wizualizować zależności danych w CI/CD.
Podsumowanie kluczowych wniosków 📝
Diagramy przepływu danych są niezastąpione do zrozumienia zachowania systemu. Dają jasną mapę ruchu informacji, zapewniając, że żadne dane nie są utracone ani tworzone bez powodu.
- Używaj DFD do analizy wymagań, a nie do kodowania implementacji.
- Uwielbaj cztery składniki: Istoty, Procesy, Magazyny, Przepływy.
- Postępuj zgodnie z hierarchią: Kontekst -> Poziom 0 -> Poziom 1.
- Unikaj czarnych dziur i cudów aby zachować spójność logiczną.
- Oznacz wszystko jasno aby uniknąć niejasności.
Opanowanie struktury i zasad DFD pozwala inżynierom tworzyć systemy wytrzymałe, łatwe do utrzymania i zgodne z celami biznesowymi. Wizualna język przepływu danych nadal stanowi potężny zasób w zestawie narzędzi inżynierii oprogramowania, przekraczając konkretne technologie i metodyki.
Często zadawane pytania ❓
P: Czy proces może aktualizować magazyn danych bez przepływu wyjściowego?
O: Nie. Proces musi generować jakikolwiek przepływ wyjściowy, nawet jeśli jest to komunikat potwierdzenia. Samo aktualizowanie to interakcja z magazynem, ale proces musi zwrócić kontrolę lub dane.
P: Czy powinienem uwzględniać ekranu interfejsu użytkownika?
O: Nie. Elementy interfejsu użytkownika nie są przetwarzaniem danych. Są to interfejsy umożliwiające użytkownikom wprowadzanie danych do zewnętrznych jednostek lub procesów.
P: Ile poziomów powinien mieć DFD?
O: Zazwyczaj 2 lub 3. Więcej niż 3 poziomy często wskazuje, że system jest zbyt złożony, aby skutecznie go zamodelować w jednym zestawie diagramów.