











データフローダイアグラム(DFD)を作成することは、システム分析と設計における重要なステップです。これらの視覚的表現は、データがシステム内でどのように移動するかをマッピングし、入力、出力、および保存を強調します。正確に描かれたDFDは、開発者やステークホルダーにとっての設計図として機能し、情報の論理構造と流れをすべての人が理解できるようにします。しかし、正確な図を描くには、規律と特定の基準への従いが求められます。このガイドでは、特定のソフトウェアツールに依存せずに、効果的なデータフローダイアグラムを描くための基本的な実践を説明します。
🔍 DFDの目的を理解する
メカニズムに飛び込む前に、これらの図がなぜ重要なのかを理解することが重要です。データフローダイアグラムはフローチャートではありません。制御フロー、または「もし~なら」のような決定ポイントを示すものではありません。代わりに、データそのものに焦点を当てます。次のような質問に答えます:データはどこから来るのか?どこへ行くのか?どのように変換されるのか?どこに保管されるのか?
- コミュニケーションツール: 技術チームとビジネス関係者との間の溝を埋めます。
- 分析の支援: ボトルネック、欠落しているデータ、または冗長なプロセスを特定するのに役立ちます。
- 設計の基盤: データベース設計とコードアーキテクチャの構造を提供します。
🧱 DFDの核心的な構成要素
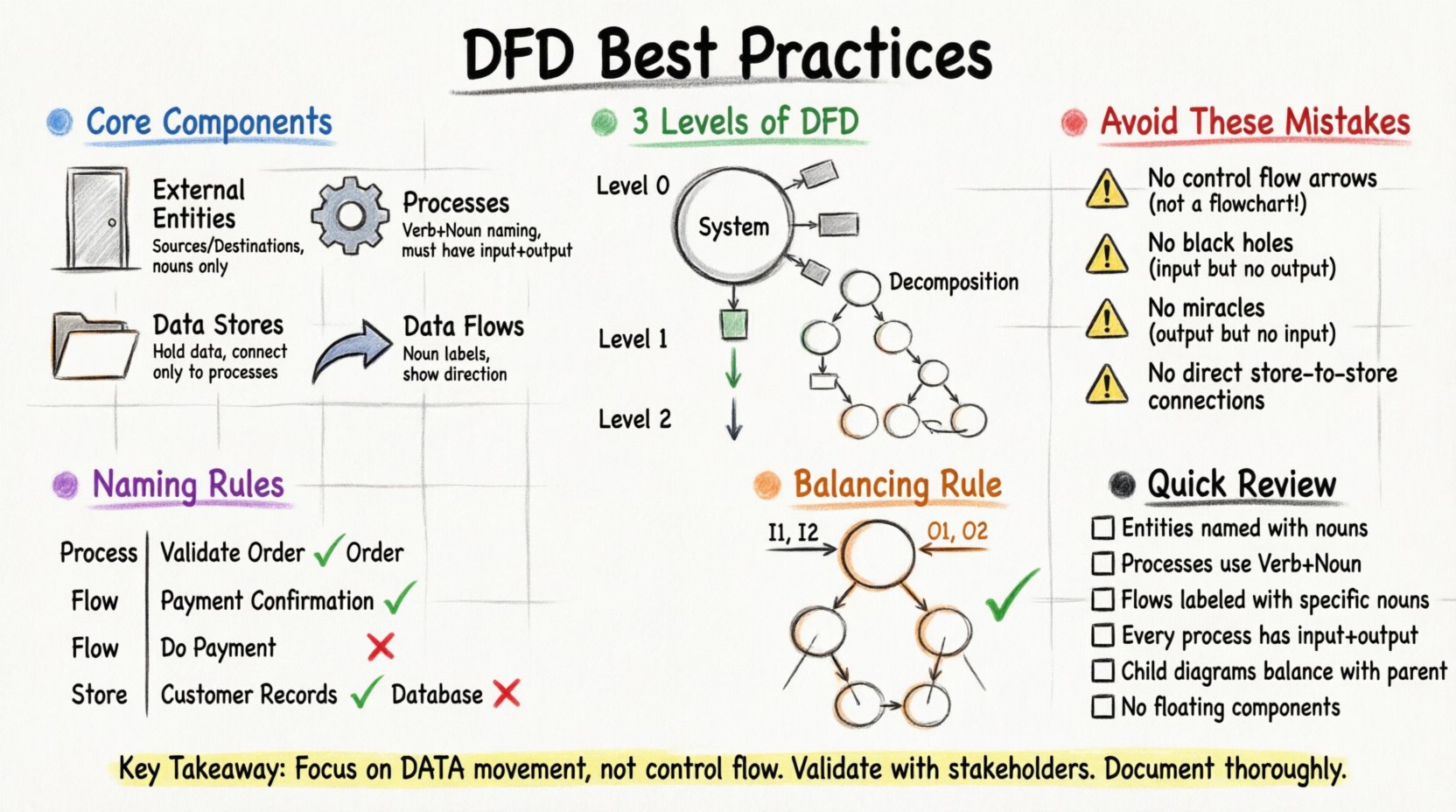
正確な図を描くためには、4つの基本的な記号を習得する必要があります。それぞれに厳密な定義があり、一貫性を保つために守らなければなりません。
1. 外部エンティティ(データの発生源および目的地) 🚪
これらは、あなたのシステムとやり取りする人々、組織、またはシステムを表します。これらはあなたの範囲の境界です。データはそれらから流入または流出します。それらはシステムそのものには含まれません。
- 例: カスタマー、ベンダー、または外部の決済ゲートウェイ。
- ルール: システム内のユーザーと外部エンティティを混同してはいけません。ここに含まれるのは、外部の発生源または受容源のみです。
2. プロセス(変換) ⚙️
プロセスはデータが変化する場所です。入力データを受け取り、それを操作し、出力データを生成します。これらはシステムの中心です。すべてのプロセスには、少なくとも1つの入力と1つの出力が必要です。
- 例: 税金を計算する、ログインを検証する、レポートを生成する。
- ルール: プロセスには動詞を使って名前を付けること。プロセスは名詞ではなく、行動です。
3. データストア(リポジトリ) 📂
データストアは、後で使用するためのデータを保持します。これらはデータベース、ファイル、あるいは物理的なファイルボックスを表します。プロセスとは異なり、データストアはデータを変更しません。単にデータを保持するだけです。
- 例: カスタマーデータベース、注文ログ、在庫リスト。
- ルール: データストアはプロセスに接続されなければなりません。プロセスがそれを処理しない限り、データがストアに突然現れたり、消えたりすることはできません。
4. データフロー(移動) 🔄
これらはコンポーネントをつなぐ矢印です。データの移動方向を示しています。すべての矢印には、どのデータが移動しているかを正確に説明するラベルが必要です。
- 例:注文詳細、支払い確認、ユーザー資格情報。
- ルール:矢印は動詞ではなく名詞でラベル付けすべきです。ラベルはフローの内容を説明します。
📉 DFDにおける抽象度のレベル
複雑なシステムは1枚のページにすべて表示することはできません。標準的な做法として、システムをレベルに分けて表現します。これを分解と呼びます。
レベル0:コンテキスト図 🌍
コンテキスト図は最も高いレベルの視点です。システム全体を1つのバブルとして表示します。この単一のプロセスをすべての外部エンティティと接続します。境界を明確に定義します。
- 注目点:入力と出力のみ。
- 詳細:最小限。内部プロセスやデータストアは含まない。
レベル1:主要プロセス 🔢
レベル1では、コンテキスト図の単一のバブルを主要なサブプロセスに分解します。ここから内部の論理が見えてきます。通常、システムの主要な機能領域を含みます。
- 注目点:主要な機能グループ。
- 詳細:主要なデータストアおよび主要プロセス間のフローを含む。
レベル2:詳細な分解 🔍
レベル2では、レベル1の特定のプロセスを分解します。特定のプロセスがレベル1の視点では理解しにくい場合に使用します。
- 注目点:特定で複雑な操作。
- 詳細:非常に細かい粒度。その特定の機能のすべてのステップを示す。
✍️ 明確さのための命名規則
命名はDFDにおいて最も一般的な混乱の原因です。明確な名前はアナリストと開発者間の誤解を防ぎます。
プロセス名
常に動詞の後に名詞を使用する。これはデータに対して行われる動作を表す。
- 良い: “ユーザー認証の検証”
- 悪い: “ログイン” または “ユーザー認証プロセス”
データフロー名
移動するデータパケットを表す特定の名詞を使用する。
- 良い: “検証済みの資格情報”
- 悪い: “ログインデータ” または “ログインする”
データストア名
データの集まりを表す名詞を使用する。
- 良い: “ユーザー アカウント”
- 悪い: “ユーザー” または “データベース”
⚖️ データのバランスと保存
DFD設計における最も重要なルールの一つがバランスです。親プロセスを子プロセスに分解する際、入力と出力は一貫性を保たなければなりません。
バランスとは何か?
「注文処理」というレベル1のプロセスがあると想像してください。このプロセスは「顧客注文」を受け取り、「出荷確認」を出力します。もし「注文処理」をレベル2のサブプロセスに分解する場合、これらのサブプロセスを合わせて考えても、「顧客注文」を受け取り、「出荷確認」を出力しなければなりません。
なぜこれが重要なのか?
- 一貫性: 分解中にデータが失われないことを保証します。
- トレーサビリティ: 上位レベルから下位レベルまで、すべてのデータを追跡できるようにします。
- 検証: 欠落している要件のチェックとして機能します。
バランスの確認方法
- 親プロセスのすべての入力と出力をリストアップする。
- 子プロセスのすべての入力と出力をリストアップする。
- 2つのリストを比較してください。完全に一致している必要があります。
🚫 避けるべき一般的なミス
経験豊富なアナリストですら誤りを犯します。これらの一般的な落とし穴を避けることで、図の品質が著しく向上します。
1. コントロールフローとデータフローの混同
DFDはフローチャートではありません。矢印を使ってイベントや決定の順序を示してはいけません。決定がなされた場合でも、データはその結果を処理するプロセスに流れ続けます。矢印は制御ではなく、データを表しています。
2. ブラックホールと奇跡
- ブラックホール:入力はあるが出力がないプロセス。これはデータが消えていることを意味し、論理的に不可能です。
- 奇跡:出力はあるが入力がないプロセス。これはデータがどこからともなく生成されていることを意味します。
3. 接続されていないコンポーネント
すべてのコンポーネントは、データフローを通じて少なくとも1つの他のコンポーネントに接続されている必要があります。浮遊するプロセスや接続されていないデータストアは、論理的な誤りを示しています。
4. プロセスのないデータストア
データストア同士は直接通信できません。2つのデータストアの間に常にプロセスが存在しなければなりません。これにより、データが保存または取得される前に検証または変換されることを保証します。
📋 DFDレビュー確認表
図を最終化する前に、この表を使って作業を検証してください。これにより、高い正確性が保証されます。
| チェック | 基準 | 合格/不合格 |
|---|---|---|
| エンティティの命名 | すべての外部エンティティは名詞で命名されていますか? | ⬜ |
| プロセスの命名 | すべてのプロセスは動詞+名詞で命名されていますか? | ⬜ |
| フローの命名 | すべてのデータフローは具体的な名詞でラベル付けられていますか? | ⬜ |
| 保存則 | すべてのプロセスに少なくとも1つの入力と1つの出力がありますか? | ⬜ |
| バランス調整 | 子図の入出力は親図の入出力と一致していますか? | ⬜ |
| 接続性 | 浮遊しているコンポーネントはありますか? | ⬜ |
| データストア | データストアはプロセスにのみ接続されていますか? | ⬜ |
| 外部エンティティ | 外部エンティティは他のエンティティに接続されることはありませんか? | ⬜ |
🔄 論理的DFDと物理的DFD
システムの論理的視点と物理的視点を区別することは重要です。両方とも有効ですが、それぞれ異なる目的を持っています。
論理的DFD
これはビジネス要件に焦点を当てます。システムが実際にどのように構築されているかは無視します。ビジネスが何をしているかを答えます。
- 例: 「支払い処理」はプロセスです。
- 利点: 技術が変更されても、依然として有効です。
物理的DFD
これは実装に焦点を当てます。システムはどのように構築されているかを答えます。具体的なハードウェア、ソフトウェアモジュール、または手作業を含みます。
- 例: 「クレジットカードAPIを実行する」または「レーザープリンタで領収書を印刷する」。
- 利点: 開発者やエンジニアを直接ガイドします。
🤝 ステークホルダーとの関与
DFDはコミュニケーションツールです。ステークホルダーが理解できない、または彼らの現実を反映していない場合は無意味です。
- ウォークスルー: ステークホルダーに図を段階的に説明するセッションをスケジュールする。
- フィードバックループ: ステークホルダーが欠落しているデータフローまたは誤ったプロセス名を指摘できるようにする。
- 検証: 図がビジネスの運営方法に関するステークホルダーのメンタルモデルと一致していることを確認する。
ステークホルダーが図を検証すると、ある種の契約のようになる。システム設計がビジネスニーズを満たしていることを確認できる。これにより、開発サイクルの後半で再作業が必要になるリスクが低下する。
🛠️ 時間の経過に伴う図の維持管理
システムは進化する。要件も変化する。昨日正確だったDFDが今日には古くなっている可能性がある。ドキュメントの価値を保つためには、常に維持管理を行う必要がある。
- バージョン管理: DFDの異なるバージョンの記録を残し、時間の経過に伴う変更を追跡する。
- 更新のトリガー: DFDを更新する必要があるタイミングのルールを定める(例:新しい機能要請、プロセス変更)。
- 中央リポジトリ: 図をチーム全員がアクセス可能な場所に保存する。
🔎 深掘り:複雑なデータフローの扱い方
時折、データフローは複雑になる。複数の情報を持ち、条件によって変化する場合もある。図をごちゃごちゃにせずに扱う方法を以下に示す。
データのグループ化
すべてのデータフィールドに対して矢印を引くべきではない。関連するデータを論理的なパケットにまとめる。
- 例: 「名前」「住所」「電話番号」を別々に矢印で描くのではなく、一つの矢印を「顧客情報」として描く。
条件付きフロー
DFDは通常、意思決定ロジックを示さないが、時折データは特定の条件下でのみ流れることもある。矢印にラベルを付けることでこれを示すことができる。
- 例: 「承認済み注文」とラベル付けして、「却下された注文」と区別する。
📝 ドキュメント作成のベストプラクティス
図は物語の一部にすぎない。明確さを確保するためには、コンポーネントの定義をドキュメント化しなければならない。
- 用語集: 図で使用されるすべての用語について用語集を作成する(例:「検証済みユーザー」とは何か?)。
- プロセス仕様: 複雑なプロセスについては、関与するロジックの簡単な説明を記述する。
- データ辞書:データストアおよびデータフローの構造を定義する。
文書化は図をサポートする。視覚的記号が伝えることのできない必要な文脈を提供する。これがないと、図は解釈の余地を残す。
🎯 主なポイントの要約
正確なデータフローダイアグラムは一貫性、明確性、ルールへの厳格な従順に基づいている。ここに示された実践を守ることで、システム論理を効果的に伝える図を構築できる。
- データに注目する:制御フローではなく、データの移動に注目する。
- 一貫した命名を使用する:プロセスには動詞、データには名詞を使用する。
- 慎重に分解する:レベル間のバランスを保つ。
- 関係者と検証する:モデルが現実を反映していることを確認する。
- 徹底的に文書化する:視覚的表現と共に文脈を提供する。
正確なDFDを描くために時間を投資することは、開発エラーの削減と明確なコミュニケーションに繋がる。あらゆるシステム分析プロジェクトの強固な基盤を築く。