











किसी भी विश्वसनीय सूचना प्रणाली के लिए एक टिकाऊ डेटा संरचना डिज़ाइन करना आधार है। इस डिज़ाइन के केंद्र में एंटिटी रिलेशनशिप डायग्राम (ERD) है, जो डेटा एंटिटीज़ के बीच अंतरक्रिया को परिभाषित करने वाला एक दृश्य नक्शा है। हालांकि, एक डायग्राम के अकेले द्वारा दक्षता की गारंटी नहीं दी जा सकती है। एक ERD की वास्तविक शक्ति तब प्रकट होती है जब इसे कठोर नॉर्मलाइजेशन रणनीतियों के साथ जोड़ा जाता है। उद्देश्य स्पष्ट है: शून्य-अतिरिक्त संग्रहण प्राप्त करें। इसका अर्थ है डुप्लीकेट डेटा को हटाना ताकि अखंडता सुनिश्चित हो, स्टोरेज लागत कम हो और रखरखाव सरल हो।
अतिरिक्तता केवल स्टोरेज की समस्या नहीं है; यह एक तर्क दोष है जो असंगतियों के कारण बनने के लिए तैयार है। जब डेटा एक ही संबंध के बिना कई पंक्तियों या तालिकाओं में दोहराया जाता है, तो अपडेट अनोमालीज़ अनिवार्य हो जाती हैं। एक एकल विशेषता में परिवर्तन करने के लिए दर्जनों स्थानों पर अपडेट करने की आवश्यकता हो सकती है। यदि एक को भूल गया, तो डेटाबेस क्षतिग्रस्त हो जाता है। यह मार्गदर्शिका ERD डिज़ाइन के संदर्भ में नॉर्मलाइजेशन के तकनीकी पहलुओं का अध्ययन करती है, जिसमें व्यावहारिक अनुप्रयोग और संरचनात्मक शुद्धता पर ध्यान केंद्रित किया गया है।
🧱 डेटा मॉडलिंग की नींव समझना
नॉर्मलाइजेशन नियमों को लागू करने से पहले, एंटिटी रिलेशनशिप डायग्राम के घटकों को समझना आवश्यक है। एक ERD में एंटिटीज़, विशेषताएं और संबंध शामिल होते हैं। एंटिटीज़ वस्तुओं या अवधारणाओं का प्रतिनिधित्व करती हैं, जैसे कि एक ग्राहक या एक उत्पाद। विशेषताएं इन एंटिटीज़ का वर्णन करने वाली गुणवत्ताएं हैं, जैसे नाम या कीमत। संबंध यह निर्धारित करते हैं कि एंटिटीज़ कैसे जुड़ती हैं, जो अक्सर विदेशी कुंजियों के माध्यम से होता है।
नॉर्मलाइजेशन इन विशेषताओं को व्यवस्थित करने की प्रक्रिया है ताकि अतिरिक्तता और निर्भरता को न्यूनतम किया जा सके। इसमें बड़ी तालिकाओं को छोटी, तार्किक रूप से जुड़ी तालिकाओं में विभाजित करना और उनके बीच संबंधों को परिभाषित करना शामिल है। लक्ष्य यह है कि डेटा को इस तरह अलग किया जाए कि प्रत्येक तथ्य केवल एक ही स्थान पर संग्रहित हो।
एक डेनॉर्मलाइज्ड दृष्टिकोण और एक नॉर्मलाइज्ड दृष्टिकोण के बीच के अंतर पर विचार करें। एक डेनॉर्मलाइज्ड दृष्टिकोण में, एक ही तालिका में एक आदेश के बारे में सभी जानकारी हो सकती है, जिसमें ग्राहक का पता और फोन नंबर शामिल होता है, जब भी कोई आदेश दिया जाता है। यदि ग्राहक बदल जाता है, तो आपको हर एक आदेश रिकॉर्ड को अपडेट करना होगा। एक नॉर्मलाइज्ड दृष्टिकोण में, ग्राहक का पता अलग ग्राहक तालिका में मौजूद होता है। ऑर्डर तालिका केवल ग्राहक ID के संदर्भ को संग्रहित करती है। यह विभाजन शून्य-अतिरिक्तता की आत्मा है।
📉 अनॉर्मलाइज्ड डेटा के जोखिम
शून्य-अतिरिक्तता इतनी महत्वपूर्ण क्यों है? उत्तर इस बात में छुपा है कि जब नॉर्मलाइजेशन को नजरअंदाज किया जाता है तो किस प्रकार की अनोमालीज़ होती हैं। ये अनोमालीज़ पूरी प्रणाली की विश्वसनीयता को खतरे में डालती हैं।
- प्रविष्टि अनोमालीज़:आप एक एंटिटी के लिए डेटा जोड़ नहीं सकते बिना दूसरे के लिए डेटा जोड़े। उदाहरण के लिए, यदि एक नए कर्मचारी को अभी तक किसी परियोजना में नियुक्त नहीं किया गया है, तो आप उनके अस्तित्व को दर्ज नहीं कर सकते यदि तालिका को परियोजना ID की आवश्यकता हो।
- डिलीशन अनोमालीज़:एक एंटिटी के लिए डेटा को हटाने से दूसरे के लिए डेटा अनजाने में हट जा सकता है। यदि आप किसी ग्राहक के अंतिम आदेश को हटाते हैं, तो आप ग्राहक की संपर्क जानकारी पूरी तरह से खो सकते हैं।
- अपडेट अनोमालीज़:यह सबसे आम समस्या है। यदि ग्राहक का पता कई ऑर्डर रिकॉर्ड में संग्रहित है, तो पते को अपडेट करने के लिए हर एक रिकॉर्ड को खोजने और बदलने की आवश्यकता होती है। ऐसा न करने पर संघर्षपूर्ण डेटा प्राप्त होता है।
शून्य-अतिरिक्तता प्राप्त करने से इन जोखिमों को सीधे कम किया जाता है। इस बात के बारे में सुनिश्चित करके कि प्रत्येक जानकारी का एक ही घर है, प्रणाली स्वयं सुधार करने वाली बन जाती है। अपडेट एक बार होते हैं, और बदलाव संबंधों के माध्यम से तार्किक रूप से प्रसारित होता है।
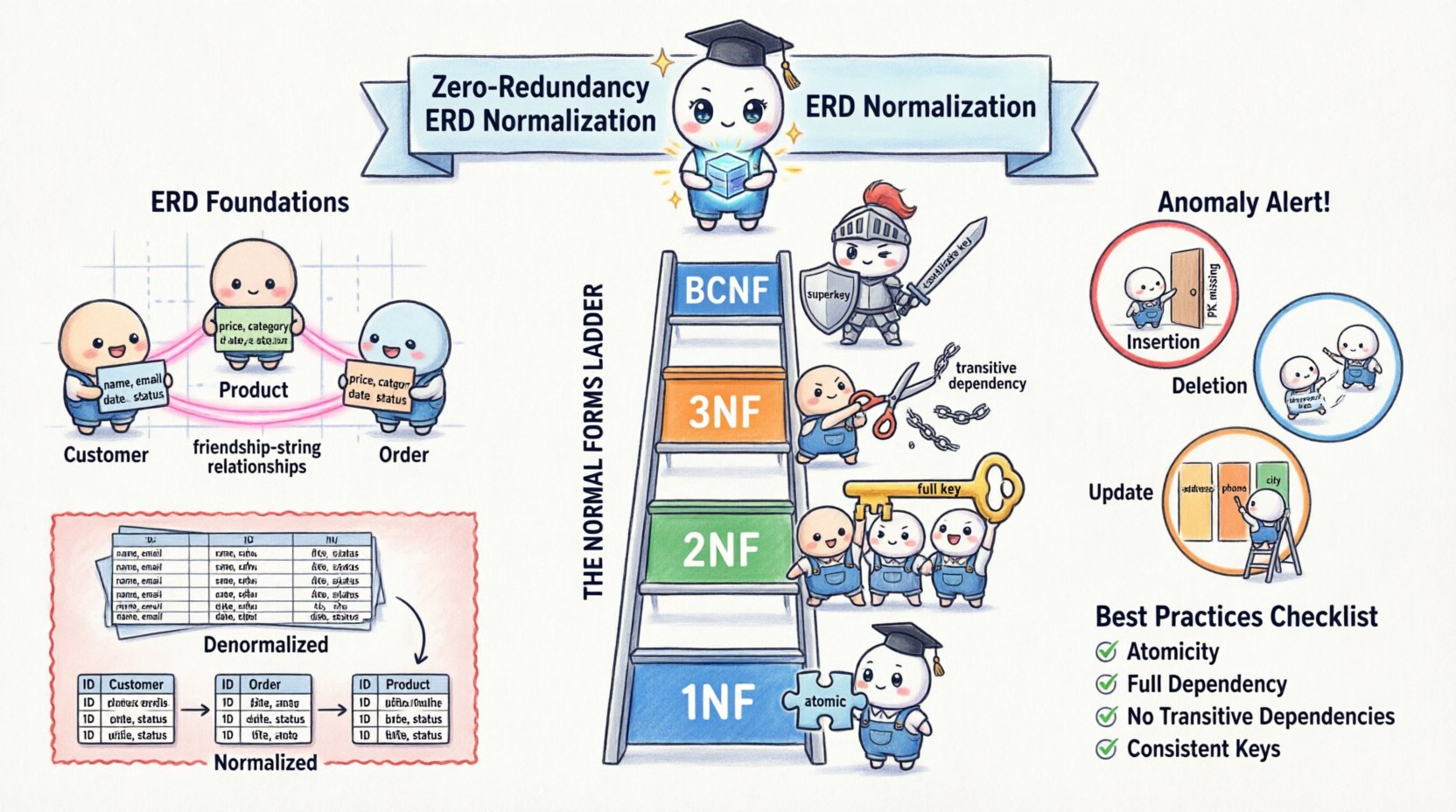
🪜 नॉर्मल फॉर्म्स तक का रास्ता
नॉर्मलाइजेशन एक ही चरण नहीं है, बल्कि विशिष्ट चरणों के माध्यम से एक प्रगति है जिसे नॉर्मल फॉर्म्स कहा जाता है। प्रत्येक फॉर्म विशिष्ट प्रकार की अतिरिक्तता को संबोधित करती है। जबकि सैद्धांतिक मॉडल पांचवें नॉर्मल फॉर्म (5NF) तक जाते हैं, व्यावहारिक डेटाबेस डिज़ाइन आमतौर पर पहले तीन फॉर्म्स और बॉयस-कॉड नॉर्मल फॉर्म (BCNF) पर ध्यान केंद्रित करता है।
1️⃣ पहला नॉर्मल फॉर्म (1NF)
नॉर्मलाइजेशन का पहला नियम परमाणुता सुनिश्चित करना है। एक तालिका 1NF में होती है यदि इसमें कोई दोहराए गए समूह या ऐरे नहीं हैं। प्रत्येक कॉलम में एक ही मान होना चाहिए, और प्रत्येक पंक्ति अद्वितीय होनी चाहिए।
- परमाणु मान:एक फील्ड में मानों की सूची नहीं हो सकती है। “कौशल” नामक कॉलम में “जावा, एसक्यूएल, पायथन” के बजाय, आपको प्रत्येक कौशल के लिए अलग-अलग पंक्तियां बनानी चाहिए या कौशल के लिए अलग तालिका बनानी चाहिए।
- अद्वितीय पंक्तियां:प्रत्येक पंक्ति को दूसरी पंक्ति से अलग किया जा सकना चाहिए। इसके लिए आमतौर पर प्राथमिक कुंजी की आवश्यकता होती है।
ERD के संदर्भ में, इसका अर्थ है प्रत्येक विशेषता की जांच करना। यदि एक विशेषता बहु-मूल्य वाले गुण का वर्णन करती है, तो उसे निकाला जाना चाहिए। यह आधारभूत चरण है। 1NF के बिना, उच्च रूपों को प्रभावी ढंग से लागू नहीं किया जा सकता है।
2️⃣ दूसरा नॉर्मल फॉर्म (2NF)
जब एक तालिका 1NF में होती है, तो उसे 2NF के मानदंड पूरे करने चाहिए। एक तालिका 2NF में होती है यदि वह 1NF में है और सभी गैर-कुंजी विशेषताएं पूर्ण प्राथमिक कुंजी पर पूरी तरह निर्भर हैं।
यह नियम मुख्य रूप से संयुक्त कुंजी (बहुल कॉलमों से बनी कुंजी) वाली तालिकाओं को संबोधित करता है। यदि एक तालिका में संयुक्त कुंजी है, तो प्रत्येक विशेषता को पूरी कुंजी पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं।
- पूर्ण निर्भरता:यदि कोई कॉलम केवल संयुक्त कुंजी के एक हिस्से पर निर्भर है, तो उसे अलग तालिका में होना चाहिए।
- आंशिक निर्भरता: यह विशिष्ट अतिरिक्तता है जिसे 2NF अपनाता है। उदाहरण के लिए, छात्रों और कोर्सेज को जोड़ने वाली एक तालिका में, यदि “छात्र का नाम” संग्रहीत किया जाता है, तो यह केवल छात्र ID पर निर्भर करता है, कोर्स ID पर नहीं। इससे अतिरिक्तता उत्पन्न होती है।
इसे दूर करने के लिए तालिका को विभाजित करना आवश्यक है। आप एक छात्र तालिका और एक कोर्स तालिका बनाते हैं, जिन्हें एक जंक्शन तालिका जोड़ती है। इससे यह सुनिश्चित होता है कि प्रत्येक कोर्स के लिए छात्र विवरण की दोहराव नहीं होता है।
3️⃣ तृतीय सामान्य रूप (3NF)
तृतीय सामान्य रूप अनुक्रमिक निर्भरता के साथ निपटता है। एक तालिका 3NF में होती है यदि यह 2NF में है और कोई भी गैर-की विशेषता दूसरी गैर-की विशेषता पर निर्भर नहीं है।
सरल शब्दों में, विशेषताओं को मुख्य कुंजी का हिस्सा नहीं होने वाली अन्य विशेषताओं पर निर्भर नहीं होना चाहिए। यह तब होता है जब एक कॉलम एक अन्य कॉलम का वर्णन करता है, बल्कि पंक्ति के स्वयं का नहीं।
- अनुक्रमिक निर्भरता: यदि A, B को निर्धारित करता है, और B, C को निर्धारित करता है, तो A, C को निर्धारित करता है। यदि B एक कुंजी नहीं है, तो C को अतिरिक्त रूप से संग्रहीत किया जाता है।
- उदाहरण: एक कर्मचारी तालिका में, यदि आप “विभाग का नाम” और “विभाग प्रबंधक” संग्रहीत करते हैं, तो प्रबंधक विभाग के नाम पर निर्भर करता है। यदि विभाग का नाम बदलता है, तो प्रबंधक कॉलम तब असंगत हो सकता है यदि ध्यान से प्रबंधित नहीं किया गया।
इसे ठीक करने के लिए, विभाग की जानकारी को अलग विभाग तालिका में स्थानांतरित करें। तब कर्मचारी तालिका केवल एक विभाग ID रखती है। इससे विभाग के डेटा को अलग किया जाता है, जिससे यह सुनिश्चित होता है कि यदि किसी विभाग का नाम बदला जाता है, तो आप उसे एक ही स्थान पर अपडेट करते हैं।
4️⃣ बॉयस-कॉड सामान्य रूप (BCNF)
BCNF, 3NF का कठोर रूप है। यह तब लागू होता है जब कई उम्मीदवार कुंजियाँ हों या जब एक गैर-की विशेषता दूसरी गैर-की विशेषता को एक विशिष्ट तरीके से निर्धारित करे। एक तालिका BCNF में होती है यदि प्रत्येक कार्यात्मक निर्भरता X → Y के लिए, X एक सुपरकी है।
इस रूप का उपयोग जटिल परिदृश्यों के साथ किया जाता है जहाँ 3NF अभी भी अनोमालियों की अनुमति दे सकता है। यह सुनिश्चित करता है कि प्रत्येक निर्धारक एक उम्मीदवार कुंजी है। हालांकि प्रत्येक स्कीमा के लिए यह आवश्यक नहीं है, लेकिन BCNF की ओर बढ़ने से शून्य अतिरिक्तता के लिए उच्चतम संरचनात्मक अखंडता प्राप्त होती है।
🛠️ अनोमालियों का प्रबंधन: एक तुलनात्मक दृष्टिकोण
नॉर्मलाइजेशन के प्रभाव को समझने के लिए अनोमालियों के उद्भव के बारे में स्पष्ट दृष्टि की आवश्यकता होती है। नीचे दी गई तालिका सामान्य और अनॉर्मलाइज्ड स्थितियों के बीच आम डेटा समस्याओं के संबंध में अंतरों को चित्रित करती है।
| अनोमाली प्रकार | अनॉर्मलाइज्ड स्थिति | नॉर्मलाइज्ड स्थिति (शून्य अतिरिक्तता) |
|---|---|---|
| अद्यतन | बहुत सारी पंक्तियों में डेटा बदलने की आवश्यकता होती है। असंगति का उच्च जोखिम। | केवल एक पंक्ति में डेटा बदलने की आवश्यकता होती है। संगतता स्वचालित होती है। |
| सम्मिलन | विदेशी कुंजी प्रतिबंधों को संतुष्ट करने के लिए डमी डेटा की आवश्यकता हो सकती है। | असंबंधित डेटा के बिना नए एंटिटीज को स्वतंत्र रूप से जोड़ा जा सकता है। |
| हटाना | एक रिकॉर्ड को हटाने से दूसरी एंटिटी के बारे में महत्वपूर्ण डेटा भी हट सकता है। | एक रिकॉर्ड को हटाने से केवल विशिष्ट एंटिटी प्रभावित होती है, अन्य एंटिटीज को सुरक्षित रखती है। |
| स्टोरेज | दोहराए गए स्ट्रिंग्स और मानों के कारण उच्च स्टोरेज उपयोग। | न्यूनतम स्टोरेज उपयोग; मानों को पहचानकर्ता के माध्यम से संदर्भित किया जाता है। |
जैसा कि दिखाया गया है, सामान्यीकृत दृष्टिकोण डेटा प्रबंधन के संचालन अतिरिक्त लागत को महत्वपूर्ण रूप से कम करता है। लागत थोड़ी अधिक जटिल प्रश्न पूछने के रूप में है, क्योंकि पूरी जानकारी प्राप्त करने के लिए जॉइन की आवश्यकता होती है। हालांकि, विनिमय अखंडता और दीर्घकालिक रखरखाव के पक्ष में है।
🛠️ कार्यान्वयन के लिए रणनीतियाँ
ERD डिजाइन चरण के दौरान इन रणनीतियों को लागू करना महत्वपूर्ण है। डेटा भरे जाने के बाद इसे ठीक करने की तुलना में अतिरेक को रोकना बहुत आसान है। डिजाइनरों के लिए कार्यान्वयन योग्य चरण यहाँ दिए गए हैं।
1. कार्यात्मक निर्भरता को जल्दी पहचानें
संबंधों के बीच रेखाएँ खींचने से पहले, गुणों की सूची बनाएँ और यह तय करें कि क्या किसके निर्धारण करता है। यदि आप जानते हैं कि गुण A गुण B को निर्धारित करता है, तो आप जानते हैं कि वे एक ही एकता में स्थित होने चाहिए, जब तक कि A एक कुंजी न हो।
- सभी संबंधों को नक्शा बनाएँ।
- पूछें: “क्या इस गुण का पूर्ण कुंजी पर निर्भरता है?”
- पूछें: “क्या इस गुण का दूसरे गैर-कुंजी गुण पर निर्भरता है?”
2. जीवनचक्र के आधार पर एकताओं को अलग करें
अलग-अलग अद्यतन आवृत्ति वाली एकताएँ अक्सर अलग की जानी चाहिए। यदि एक स्थिर संदर्भ सारणी (जैसे देशों की सूची) को एक लेनदेन सारणी (जैसे आदेश) के साथ मिलाया जाता है, तो स्थिर डेटा लेनदेन सारणी में अनावश्यक अतिरेक उत्पन्न करता है।
3. सुरोगत कुंजी का उपयोग करें
प्राथमिक कुंजी के रूप में प्राकृतिक डेटा के बजाय, सुरोगत कुंजी (प्रणाली द्वारा उत्पन्न एक अद्वितीय पहचानकर्ता) के उपयोग की सोचें। इससे ऐसी समस्याओं से बचा जा सकता है जहाँ कुंजी समय के साथ बदल जाती है, जो सामान्यीकृत प्रणाली में संबंधों को तोड़ देगी।
4. परीक्षण डेटा के साथ प्रमाणीकरण करें
ERD को अंतिम रूप देने से पहले, नमूना डेटा के साथ इसे भरने की कोशिश करें। पहले वर्णित विचलनों को बनाने की कोशिश करें। यदि आप बिना आदेश के एक ग्राहक को सफलतापूर्वक डाल सकते हैं, और ग्राहक को खोए बिना आदेश को हटा सकते हैं, तो आपका डिजाइन संभवतः ठीक है।
⚖️ प्रदर्शन और शुद्धता के बीच संतुलन
शून्य अतिरेक प्राप्त करना तालिकाओं की संख्या को अधिकतम करने का अर्थ नहीं है। अत्यधिक सामान्यीकरण प्रदर्शन में गिरावट का कारण बन सकता है। जब एक प्रश्न दस अलग-अलग तालिकाओं से डेटा की आवश्यकता करता है, तो प्रणाली को दस जॉइन करने की आवश्यकता होती है। इससे पढ़ने के संचालन को महत्वपूर्ण रूप से धीमा कर दिया जा सकता है।
जब असामान्यीकरण करना चाहिए
जानबूझकर अतिरेक को वापस लाने के वैध कारण हैं। इसे अक्सर असामान्यीकरण कहा जाता है।
- पढ़ने पर अधिक निर्भर प्रणालियाँ: डेटा गोदाम या रिपोर्टिंग उपकरणों में, लेखन सुसंगतता की तुलना में पढ़ने की गति को प्राथमिकता दी जाती है। पूर्व-गणना किए गए कॉलम जॉइन की जटिलता को कम कर सकते हैं।
- ऐतिहासिक स्नैपशॉट्स: यदि आपको जानना है कि एक आदेश के समय एक ग्राहक का पता क्या था, तो आप ग्राहक सारणी में वर्तमान पते पर भरोसा नहीं कर सकते। आपको पता को आदेश सारणी में संग्रहीत करना होगा।
- प्रदर्शन समायोजन: यदि प्रश्न जॉइन के कारण निरंतर धीमे हैं, तो ट्रिगर या एप्लिकेशन तर्क के माध्यम से अपडेट किए जाने वाले अतिरिक्त कॉलम को जोड़ना आवश्यक हो सकता है।
मुख्य बात इरादा है। अतिरेक को डिफ़ॉल्ट के रूप में स्वीकार न करें। यह केवल तभी स्वीकार करें जब मरम्मत लागत की तुलना में मापे गए प्रदर्शन लाभ हो।
🔄 अपने स्कीमा की समीक्षा और रखरखाव करें
सामान्यीकरण एक बार का कार्य नहीं है। व्यावसायिक आवश्यकताएँ बदलती हैं, और डेटा बढ़ता है। पांच साल पहले सामान्यीकृत एक स्कीमा आज समायोजित करने की आवश्यकता हो सकती है।
नियमित ऑडिट
अपने ERD की नियमित समीक्षा के लिए योजना बनाएँ। दोहराए गए डेटा के पैटर्न की तलाश करें। यदि आप एक ही पाठ डेटा कई तालिकाओं में देखते हैं, तो जांचें कि क्यों। यह डिजाइन की कमी का संकेत हो सकता है या एक जानबूझकर असामान्यीकरण चयन हो सकता है जिसका दस्तावेजीकरण की आवश्यकता होती है।
डेटा मॉडल्स के लिए संस्करण नियंत्रण
अपने एरडी को कोड की तरह लें। बदलावों को ट्रैक करने के लिए संस्करण नियंत्रण प्रणालियों का उपयोग करें। यह आपको वापस लौटने की अनुमति देता है यदि कोई बदलाव अतिरेक या संबंधों को तोड़ता है। प्रत्येक महत्वपूर्ण संरचनात्मक बदलाव के कारणों को दस्तावेज़ीकृत करें।
टीम का प्रशिक्षण
सुनिश्चित करें कि डेटा एंट्री या एप्लिकेशन विकास में शामिल हर व्यक्ति को नॉर्मलाइजेशन नियमों की समझ हो। यदि विकासकर्ता स्कीमा को बायपास करके डेटा सीधे डालते हैं, तो वे एप्लिकेशन लॉजिक के माध्यम से फिर से अतिरेक ला सकते हैं। स्कीमा को इस तरह से कैसे संरचित किया गया है, इसके कारणों के स्पष्ट दस्तावेज़ीकरण आवश्यक है।
📝 बेस्ट प्रैक्टिसेज का सारांश
डेटा गुणवत्ता और स्टोरेज दक्षता के उच्च मानक को बनाए रखने के लिए, डिज़ाइन प्रक्रिया के दौरान निम्नलिखित चेकलिस्ट का पालन करें।
- परमाणुता: सुनिश्चित करें कि प्रत्येक कॉलम में एक ही मान हो (1NF)।
- पूर्ण निर्भरता: सुनिश्चित करें कि गैर-की विशेषताएं पूर्ण प्राथमिक की पर निर्भर हों (2NF)।
- कोई अंतरित निर्भरता नहीं: सुनिश्चित करें कि गैर-की विशेषताएं अन्य गैर-की विशेषताओं पर निर्भर न हों (3NF)।
- संगत कीज़: सुनिश्चित करें कि प्रत्येक निर्धारक एक उम्मीदवार की हो (BCNF)।
- निर्णयों को दस्तावेज़ीकृत करें: दर्ज करें कि विशिष्ट अतिरेक क्यों लागू किए गए थे।
- वृद्धि का निरीक्षण करें: डेटाबेस के बढ़ने के साथ दोहराए जा रहे डेटा के पैटर्न का ध्यान रखें।
इन सिद्धांतों का पालन करने से आप एक ऐसी प्रणाली बनाते हैं जो बदलाव के प्रति लचीली होती है। डेटा साफ रहता है, और तर्क स्थिर रहता है। शून्य अतिरेक केवल डिस्क स्पेस बचाने के बारे में नहीं है; यह एक ऐसी नींव बनाने के बारे में है जहां डेटा सत्य को बनाए रखा जाता है।
🚀 संरचनात्मक अखंडता पर अंतिम विचार
शून्य अतिरेक स्टोरेज की ओर बढ़ने की यात्रा आपकी डेटा आर्किटेक्चर की लंबाई के लिए एक निवेश है। जब तक डिज़ाइन चरण में अनुशासन की आवश्यकता होती है, लाभ घटे त्रुटियों, कम रखरखाव लागत और सूचना प्रणाली में अधिक विश्वास में दिया जाता है।
जब आप एक एंटिटी रिलेशनशिप डायग्राम को देखते हैं, तो इसे केवल बॉक्स और लाइनों के संग्रह के रूप में न देखें, बल्कि सच्चाई के एक नक्शे के रूप में देखें। प्रत्येक लाइन आवश्यकता के संबंध का प्रतिनिधित्व करती है। प्रत्येक बॉक्स एक अलग तथ्य का प्रतिनिधित्व करता है। प्रभावी रूप से नॉर्मलाइज़ करके, आप सुनिश्चित करते हैं कि यह नक्शा सही रहता है, भले ही आपके व्यवसाय का मैदान बदलता रहे।
तर्क पर ध्यान केंद्रित करें, केवल स्टोरेज पर नहीं। संरचना को डेटा की सेवा करने दें, न कि इसके विपरीत। नॉर्मलाइज़ेशन रणनीतियों की स्पष्ट समझ के साथ, आप समय और डेटा आयतन के परीक्षण को सहन करने वाली प्रणालियां बनाने के लिए तैयार हैं।