











एक पुराने सिस्टम को माइक्रोसर्विसेज आर्किटेक्चर में आधुनिक बनाना तकनीकी और संगठनात्मक चुनौतियों से भरा यात्रा है। जबकि बहुत से टीमें कोड रिफैक्टरिंग और कंटेनराइजेशन पर बहुत ध्यान केंद्रित करती हैं, एक महत्वपूर्ण बाधा अक्सर डेटा परत में होती है। विशेष रूप से, पारंपरिक एंटिटी रिलेशनशिप डायग्राम (ERD) मॉडल को वितरित प्रणालियों में स्थानांतरित करते समय एक गंभीर बाधा बन सकता है। 📉
जब आप एक मोनोलिथिक एप्लिकेशन का डिज़ाइन करते हैं, तो आपका डेटा मॉडल केंद्रीकृत होता है। एक ERD एकल स्रोत सच्चाई का प्रतिनिधित्व करता है, जिसमें विदेशी कुंजियों द्वारा जुड़े नॉर्मलाइज्ड तालिकाएं होती हैं। यह दृष्टिकोण एक ही डेटाबेस इंस्टेंस के लिए अच्छा काम करता है। हालांकि, माइक्रोसर्विसेज को स्वायत्तता की आवश्यकता होती है। जब आप एक वितरित आर्किटेक्चर पर मोनोलिथिक ERD संरचना को लागू करते हैं, तो आप एक कठोर जुड़ाव बनाते हैं जो अपनी प्रणाली को तोड़ने के लाभ को निष्क्रिय कर देता है। 🚧
यह गाइड यह समझने में मदद करता है कि क्यों पारंपरिक ERD विचारधारा माइक्रोसर्विसेज के अपनाने में बाधा डालती है और आपके डेटा मॉडलिंग रणनीतियों के संक्रमण के लिए एक व्यावहारिक मार्गदर्शिका प्रदान करता है। हम वितरित डेटा प्रबंधन, संगतता मॉडल और डोमेन-ड्रिवन डिज़ाइन सिद्धांतों के साथ मेल खाने वाली दृश्यीकरण तकनीकों पर चर्चा करेंगे। 🗺️
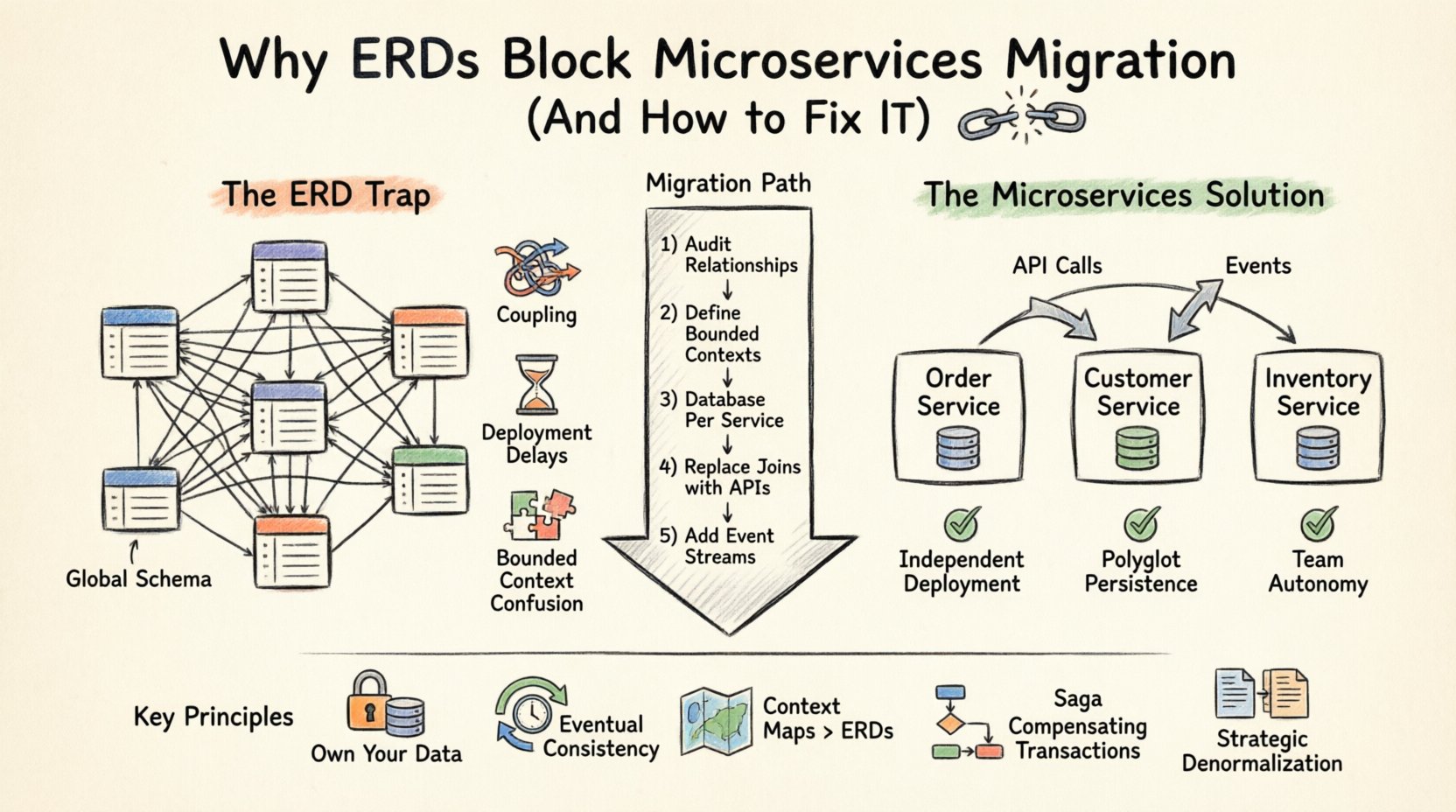
वितरित प्रणालियों में ERD फंदे को समझना 🧩
एक एंटिटी रिलेशनशिप डायग्राम डेटाबेस की तार्किक संरचना का दृश्य प्रतिनिधित्व है। यह एंटिटी (तालिकाएं), गुण (कॉलम), और संबंध (विदेशी कुंजियां) को परिभाषित करता है। मोनोलिथिक पर्यावरण में, इस केंद्रीकरण को एक ताकत माना जाता है। यह ACID लेनदेन के माध्यम से डेटा अखंडता सुनिश्चित करता है और पूरे एप्लिकेशन में प्रश्न पूछने को सरल बनाता है।
हालांकि, माइक्रोसर्विसेज आर्किटेक्चर के सिद्धांत पर बना हैसेवा स्वतंत्रता। प्रत्येक सेवा को अपने डेटा का मालिक होना चाहिए और इसे केवल एक API के माध्यम से प्रदर्शित करना चाहिए। जब आप एक साझा ERD को बनाए रखते हैं जो कई सेवाओं को छूता है, तो आप मालिकता की सीमा का उल्लंघन करते हैं। इससे निम्नलिखित समस्याएं उत्पन्न होती हैं:
- वैश्विक स्कीमा निर्भरता: यदि सेवा A को सेवा B से डेटाबेस स्तर पर सीधे डेटा जोड़ने की आवश्यकता है, तो वे अब स्वतंत्र नहीं हैं। सेवा B के स्कीमा में कोई बदलाव सेवा A को तोड़ देता है।
- लेनदेन सीमाएं:बहुत से डेटाबेसों के बीच ACID लेनदेन जटिल और प्रदर्शन-भारी होते हैं। वितरित लेनदेन अक्सर लॉक प्रतिस्पर्धा और लेटेंसी में वृद्धि के कारण बनते हैं।
- डेप्लॉयमेंट का जुड़ाव: यदि आपका डेटा मॉडल साझा है, तो आप सेवाओं को स्वतंत्र रूप से डेप्लॉय नहीं कर सकते। आपको टीमों के बीच स्कीमा बदलावों को निर्देशित करना होगा, जिससे रिलीज चक्र धीमा हो जाता है।
- सीमित संदर्भ भ्रम: अलग-अलग सेवाएं एक ही एंटिटी के बारे में अलग-अलग तरीके से व्याख्या कर सकती हैं। एक ERD एकल परिभाषा के लिए बाध्य करता है, जो डोमेन-विशिष्ट बातों को नजरअंदाज करता है।
जुड़ाव समस्या: विदेशी कुंजियां और जॉइन्स 🔗
माइग्रेशन के दौरान सबसे आम गलतियों में से एक यह है कि एप्लिकेशन कोड को विभाजित करते समय मौजूदा डेटाबेस स्कीमा को बरकरार रखने की कोशिश करना। इससे एक बनता हैसाझा डेटाबेस विपरीत पैटर्न। इस परिदृश्य में, बहुत सी सेवाएं एक ही डेटाबेस इंस्टेंस से जुड़ती हैं और संबंधों को बनाए रखने के लिए विदेशी कुंजियों पर निर्भर रहती हैं।
हालांकि इसे एक वैध ERD संरचना लगती है, यह एक छिपा हुआ मोनोलिथ है। यहां बताया गया है कि इस दृष्टिकोण का माइक्रोसर्विसेज संदर्भ में असफल होने का कारण क्या है:
- नेटवर्क लेटेंसी: भले ही डेटाबेस नेटवर्क के स्थानीय हो, क्रॉस-सर्विस प्रश्न नेटवर्क हॉप्स को जोड़ते हैं जो स्थानीय प्रश्नों की तुलना में प्रदर्शन को खराब करते हैं।
- एकल विफलता का बिंदु: यदि डेटाबेस गिर जाता है, तो हर सेवा गिर जाती है। माइक्रोसर्विसेज अलगाव के माध्यम से लचीलापन के लक्ष्य को प्राप्त करने का प्रयास करते हैं।
- सुरक्षा जोखिम: एक सेवा जिसे अन्य डेटा के सीधे एक्सेस की अनुमति नहीं होनी चाहिए, फिर भी डेटाबेस कनेक्शन स्ट्रिंग के माध्यम से उसे एक्सेस कर सकती है। APIs एक नियंत्रित इंटरफेस प्रदान करते हैं; सीधे DB एक्सेस के लिए नहीं।
- तकनीक बंधन: सभी सेवाओं को एक ही डेटाबेस तकनीक का उपयोग करना होगा। माइक्रोसर्विसेज पॉलीग्लॉट पर्सिस्टेंस की अनुमति देते हैं, जहां अलग-अलग सेवाएं अपनी विशिष्ट आवश्यकताओं के लिए सबसे उपयुक्त डेटा स्टोर का उपयोग करती हैं।
इस समस्या को ठीक करने के लिए, आपको सेवा सीमाओं के पार SQL जॉइन्स से दूर जाने की आवश्यकता है। इसके बजाय, आपको API संयोजन या घटना-आधारित डेटा समन्वय का उपयोग करना चाहिए। 🔄
सेवा प्रति डेटाबेस: स्वर्ण नियम 🏦
माइक्रोसर्विसेज डेटा आर्किटेक्चर के लिए आधारभूत पैटर्न हैसेवा प्रति डेटाबेस. प्रत्येक सेवा अपने स्वयं के डेटाबेस स्कीमा का मालिक है। किसी अन्य सेवा को इस डेटाबेस को सीधे एक्सेस करने की अनुमति नहीं है। संचार सेवा के सार्वजनिक API के माध्यम से ही होता है।
इस परिवर्तन के लिए आपके डेटा को देखने के तरीके में एक मूलभूत परिवर्तन की आवश्यकता होती है। अब आप पूरे सिस्टम के लिए एक विशाल ERD नहीं बना सकते। इसके बजाय, आप प्रत्येक सेवा के लिए एक छोटे ERD बनाते हैं, बहुत सारे। 📄
| पहलू | एकल घटक ERD | माइक्रोसर्विसेज मॉडल |
|---|---|---|
| स्कीमा परिसर | वैश्विक / एकीकृत | स्थानीय / सेवा-विशिष्ट |
| संबंध | विदेशी कुंजियाँ | API कॉल / घटनाएँ |
| सुसंगतता | मजबूत (ACID) | अंततः (BASE) |
| डेप्लॉयमेंट | जुड़ा हुआ | स्वतंत्र |
साझा लेनदेन के बिना सुसंगतता प्रबंधित करना 🤝
जब आप डेटाबेस को अलग करते हैं, तो आपको एक ही समय में सेवा A और सेवा B दोनों को अपडेट करने वाले एकल लेनदेन को चलाने की क्षमता खो देते हैं। एकल घटक में, आप डेटाबेस लेनदेन का उपयोग करके खाता A से खाता B में पैसे ले जा सकते हैं। माइक्रोसर्विसेज में, इन खातों को अलग-अलग सेवाओं में हो सकता है।
चूंकि आप वितरित प्रणालियों के पार तुरंत सुसंगतता की गारंटी नहीं दे सकते, इसलिए आपको अपनाना होगाअंततः सुसंगतता. इसका अर्थ है कि प्रणाली समय के साथ एक सुसंगत स्थिति तक पहुंचेगी, लेकिन यह जरूरी नहीं है कि उपयोगकर्ता बटन दबाते ही ठीक उसी क्षण हो।
सैगा का कार्यान्वयन
बहुत सेवाओं के आसपास फैले जटिल वर्कफ्लो को संभालने के लिए, उपयोग करेंसैगा पैटर्न. एक सैगा स्थानीय लेनदेन का एक क्रम है जहां प्रत्येक लेनदेन एकल सेवा के भीतर डेटाबेस को अपडेट करता है। यदि कोई चरण विफल होता है, तो सैगा पिछले चरणों द्वारा किए गए परिवर्तनों को वापस लेने के लिए संतोषजनक लेनदेन चलाती है।
- कोरियोग्राफी: सेवाएं घटनाएं उत्पन्न करती हैं जो अन्य सेवाओं में क्रियाएं शुरू करती हैं। कोई केंद्रीय समन्वयक नहीं है।
- ओर्केस्ट्रेशन: एक केंद्रीय समन्वयक सेवा कार्यप्रवाह का प्रबंधन करती है और अन्य सेवाओं को बताती है कि क्या करना है।
इस दृष्टिकोण से साझा लॉक या वितरित लेनदेन की आवश्यकता के बिना डेटा अखंडता सुनिश्चित होती है। इससे कार्यान्वयन में जटिलता बढ़ती है लेकिन सिस्टम के स्वास्थ्य को बनाए रखने के लिए यह आवश्यक है। 🛡️
ERD के बिना डेटा का दृश्यीकरण: संदर्भ मानचित्र 🗺️
यदि आप पारंपरिक ERD को छोड़ देते हैं, तो आप अपनी डेटा संरचना को दृश्यीकृत करने के लिए क्या उपयोग करते हैं? उत्तर इसमें छिपा हैडोमेन-ड्रिवन डिज़ाइन (DDD) संदर्भ मानचित्र. जबकि एक ERD तालिकाओं और कॉलम पर ध्यान केंद्रित करता है, एक संदर्भ मानचित्र सीमित संदर्भों और संबंधों पर ध्यान केंद्रित करता है।
तालिकाओं के बीच रेखाएं खींचने के बजाय, आप सेवाओं के बीच रेखाएं खींचते हैं। आप उनके बीच डेटा के प्रवाह को परिभाषित करते हैं:
- ग्राहक-आपूर्तिकर्ता: एक सेवा दूसरी सेवा को डेटा प्रदान करती है। प्रदाता संविदा को परिभाषित करता है।
- अनुसरणकारी: उपभोक्ता सेवा को प्रदाता के मॉडल के अनुसार अनुकूलित करना होगा।
- खुला होस्ट सेवा: एक सेवा खुले प्रोटोकॉल के माध्यम से अपने डेटा को प्रदर्शित करती है।
- अलग-अलग रास्ते: दोनों सेवाएं अपने मॉडल को स्वतंत्र रूप से विकसित करती हैं।
इस दृश्यीकरण में बदलाव से टीमों को समझने में मदद मिलती हैक्यों डेटा की प्रतिलिपि बनाई जाती है। एक मोनोलिथ में, प्रतिलिपि बुरी होती है। माइक्रोसर्विसेज में, प्रतिलिपि अक्सर सेवाओं को अलग करने के लिए एक विशेषता होती है। उदाहरण के लिए, आदेश सेवा आदेश देखे जाने पर हर बार नेटवर्क कॉल करने से बचने के लिए ग्राहक का नाम का एक स्नैपशॉट स्टोर कर सकती है। इस व्यापार करने के लिए प्रदर्शन के लिए स्वीकार्य है।
माइग्रेशन के चरण: ERD से वितरित डेटा में स्थानांतरण 🚀
केंद्रीकृत ERD से वितरित डेटा मॉडल में स्थानांतरण एक बार की घटना नहीं है। यह एक चरणबद्ध प्रक्रिया है। यहां माइग्रेशन को प्रबंधित करने के लिए एक सिफारिश की गई विधि दी गई है।
चरण 1: मौजूदा डेटा संबंधों का ऑडिट करें
किसी भी चीज़ को विभाजित करने से पहले, अपने वर्तमान ERD में प्रत्येक संबंध को दस्तावेज़ करें। यह पहचानें कि कौन सी तालिकाएं पढ़ने में अधिक भारी हैं, कौन सी लेखन में अधिक भारी हैं, और कौन सी तालिकाएं अक्सर एक साथ जुड़ी हैं। इस विश्लेषण से आपको तत्वों को तार्किक सेवा सीमाओं में समूहित करने में मदद मिलती है। 📊
चरण 2: सीमित संदर्भों को परिभाषित करें
व्यावसायिक क्षेत्रों के आधार पर संस्थाओं का समूह बनाएं, तकनीकी निर्भरता के बजाय। उदाहरण के लिए, एक उत्पाद कैटलॉग एक से अलग है इन्वेंट्री प्रबंधन प्रणाली, भले ही दोनों के पास उत्पादID फ़ील्ड हो। सुनिश्चित करें कि सीमाएं टीम संरचनाओं के साथ मेल खाती हों (काउन्वे का नियम)।
चरण 3: सेवा प्रति डेटाबेस कार्यान्वयन
प्रत्येक सेवा के लिए एक नया डेटाबेस इंस्टेंस बनाएं। मोनोलिथिक डेटाबेस से संबंधित डेटा को स्थानांतरित करें। आपको तुरंत सब कुछ स्थानांतरित करने की आवश्यकता नहीं है। सेवा के कार्य करने के लिए आवश्यक मुख्य डेटा से शुरुआत करें। 🏗️
चरण 4: जॉइन को API कॉल्स से बदलें
अपने क्वेरी को पुनर्गठित करें। इसके बजाय JOIN ऑर्डर्स, ग्राहकों, आपका कोड को ग्राहक API विवरण प्राप्त करने के लिए कॉल करना चाहिए। इससे लेटेंसी आ सकती है, इसलिए उपयुक्त स्थितियों में कैशिंग रणनीतियों या अनार्मलाइज़ेशन को ध्यान में रखें।
चरण 5: इवेंट स्ट्रीम्स का परिचय
रियल-टाइम अपडेट के लिए, इवेंट बस का कार्यान्वयन करें। जब किसी सेवा में कोई एंटिटी बदलती है, तो एक इवेंट प्रकाशित करें। अन्य सेवाएं इन इवेंट्स को सब्सक्राइब कर सकती हैं ताकि डेटा की अपनी स्थानीय प्रतियों को अपडेट कर सकें। इससे सीधे निर्भरता के बिना अंततः संगतता सुनिश्चित होती है।
माइग्रेशन के दौरान आम गलतियां ⚠️
योजना के साथ भी, टीमें आमतौर पर संक्रमण के दौरान फंस जाती हैं। इन आम समस्याओं के बारे में जागरूक रहें।
- जल्दी से विभाजन: डेटा फ्लो को समझने से पहले सेवाओं को न विभाजित करें। बहुत जल्दी विभाजन करने से आप तैयार होने से पहले वितरित जटिलता का सामना कर सकते हैं।
- डेटा स्वामित्व को नजरअंदाज करना: यदि कई टीमें एक ही डेटा एंटिटी के स्वामित्व का दावा करती हैं, तो तनाव उत्पन्न होगा। प्रत्येक सेवा को स्पष्ट स्वामित्व निर्धारित करें।
- अत्यधिक नॉर्मलाइज़ेशन: वितरित प्रणाली में, एक पृष्ठ को रेंडर करने के लिए आवश्यक API कॉल्स की संख्या को कम करने के लिए अनार्मलाइज़ेशन को अक्सर प्राथमिकता दी जाती है।
- नेटवर्क पर निर्भरता: कभी भी नेटवर्क को पूर्ण मानने की गलती न करें। सेवा-सेवा संचार के लिए टाइमआउट, पुनर्प्रयास और सर्किट ब्रेकर को कार्यान्वित करें।
संगठनात्मक संरेखण 🤝
डेटा आर्किटेक्चर केवल तकनीकी नहीं है; यह संगठनात्मक है। वितरित डेटा मॉडल के लिए टीमों को अलग तरीके से संचार करने की आवश्यकता होती है। मोनोलिथ में, डेवलपर्स एक साझा व्हाइटबोर्ड (डेटाबेस) के ऊपर बातचीत करते हैं। माइक्रोसर्विसेज में, वे API कॉन्ट्रैक्ट के ऊपर बातचीत करते हैं।
सुनिश्चित करें कि आपकी टीमें एक केंद्रीय गवर्नेंस बोर्ड से परामर्श किए बिना अपने डेटाबेस स्कीमा में बदलाव करने के लिए सशक्त हैं। यह स्वायत्तता ही स्वतंत्र डेप्लॉयमेंट की गति बनाए रखने का एकमात्र तरीका है। यदि आप एक केंद्रीय टीम लाते हैं जो सभी स्कीमा बदलावों को मंजूरी देती है, तो आप वह बॉटलनेक फिर से लाते हैं जिसे आपने हटाने की कोशिश की थी। 👥
डेटा रणनीति के लिए अंतिम विचार 🧭
एक पारंपरिक एंटिटी रिलेशनशिप डायग्राम से दूर जाना एक महत्वपूर्ण कदम है। इसके लिए मानसिकता में बदलाव की आवश्यकता होती है प्रतिबंधों के माध्यम से डेटा अखंडता से एप्लिकेशन लॉजिक और घटनाओं के माध्यम से डेटा अखंडता. एरडी एक संबंधात्मक डेटाबेस के लिए एक उपकरण है, वितरित प्रणालियों के लिए ब्लूप्रिंट नहीं है।
सेवा प्रति डेटाबेस पैटर्न को अपनाने, इवेंट-ड्राइवन आर्किटेक्चर का उपयोग करने और सीमित संदर्भों पर ध्यान केंद्रित करने से आप अपने माइग्रेशन को धीमा करने वाले कपलिंग से बच सकते हैं। लक्ष्य अपने मौजूदा डेटा मॉडल को नष्ट करना नहीं है, बल्कि उसे स्वतंत्र स्केलिंग और लचीलापन को समर्थन देने वाली संरचना में विकसित करना है।
याद रखें कि सुसंगतता एक विस्तार है। आपको हर जगह मजबूत सुसंगतता की आवश्यकता नहीं है। अपनी प्रणाली के उन हिस्सों को पहचानें जिन्हें सख्त सटीकता की आवश्यकता है और उन्हें जो अंततः सुसंगतता को सहन कर सकते हैं। यह व्यावहारिकता आपको अपने समाधान को अत्यधिक डिज़ाइन करने से बचाएगी।
अपने वर्तमान आरेखों का ऑडिट करने से शुरुआत करें। उन जॉइन्स को पहचानें जो सेवा सीमाओं को पार करते हैं। उन विशिष्ट एंटिटीज के माइग्रेशन की योजना बनाएं। छोटे कदम उठाएं। परिणामों की पुष्टि करें। और हमेशा अपने डेटा डिज़ाइन के केंद्र में व्यापार क्षेत्र को रखें। 🎯
मुख्य बातें 📝
- कपलिंग से बचने के लिए सेवाओं के बीच साझा डेटाबेस से बचें।
- सेवा के बीच डेटा के लिए SQL जॉइन्स के बजाय API संयोजन का उपयोग करें।
- उपलब्धता और पार्टीशन प्रतिरोध के लिए अंततः सुसंगतता को स्वीकार करें।
- सार्वभौमिक एरडी के बजाय संदर्भ मानचित्रों का उपयोग करके डेटा को दृश्याकृत करें।
- प्रत्येक सेवा टीम को स्पष्ट डेटा स्वामित्व निर्धारित करें।
- प्रदर्शन अनुकूलन के रूप में डेटा दोहराव की योजना बनाएं।
इन सिद्धांतों का पालन करके आप डेटा माइग्रेशन की जटिलताओं को बिना अपने एरडी के नए आर्किटेक्चर की सीमाओं को निर्धारित करने दिए बिना निर्देशित कर सकते हैं। आगे का रास्ता वितरित, विकेंद्रीकृत और स्केल के लिए डिज़ाइन किया गया है। 🚀