











Merancang arsitektur data yang kuat membutuhkan keseimbangan antara prioritas yang saling bertentangan. Integritas, kinerja, dan kemudahan pemeliharaan sering kali menarik ke arah yang berbeda. Ketika sistem beralih fokus ke operasi yang berat pada baca, aturan tradisional dalam desain skema menghadapi tekanan yang signifikan. Diagram Hubungan Entitas (ERD) menjadi lebih dari sekadar gambaran statis; ia berperan sebagai kontrak antara logika aplikasi dan mesin penyimpanan. Panduan ini mengeksplorasi perbedaan strategis antara pendekatan yang dinormalisasi dan yang tidak dinormalisasi khususnya dalam konteks beban kerja baca dengan volume tinggi.
Keputusan untuk melakukan normalisasi atau tidak normalisasi tidak bersifat biner. Ini melibatkan pemahaman tentang biaya duplikasi data terhadap biaya pengambilan data. Dalam lingkungan di mana operasi baca mendominasi log transaksi, meminimalkan kompleksitas join sering kali menjadi tujuan optimasi utama. Namun, memperkenalkan redundansi menciptakan tantangan baru terhadap konsistensi data dan operasi tulis. Kita harus menganalisis pertukaran yang terjadi untuk memilih strategi struktural yang tepat.
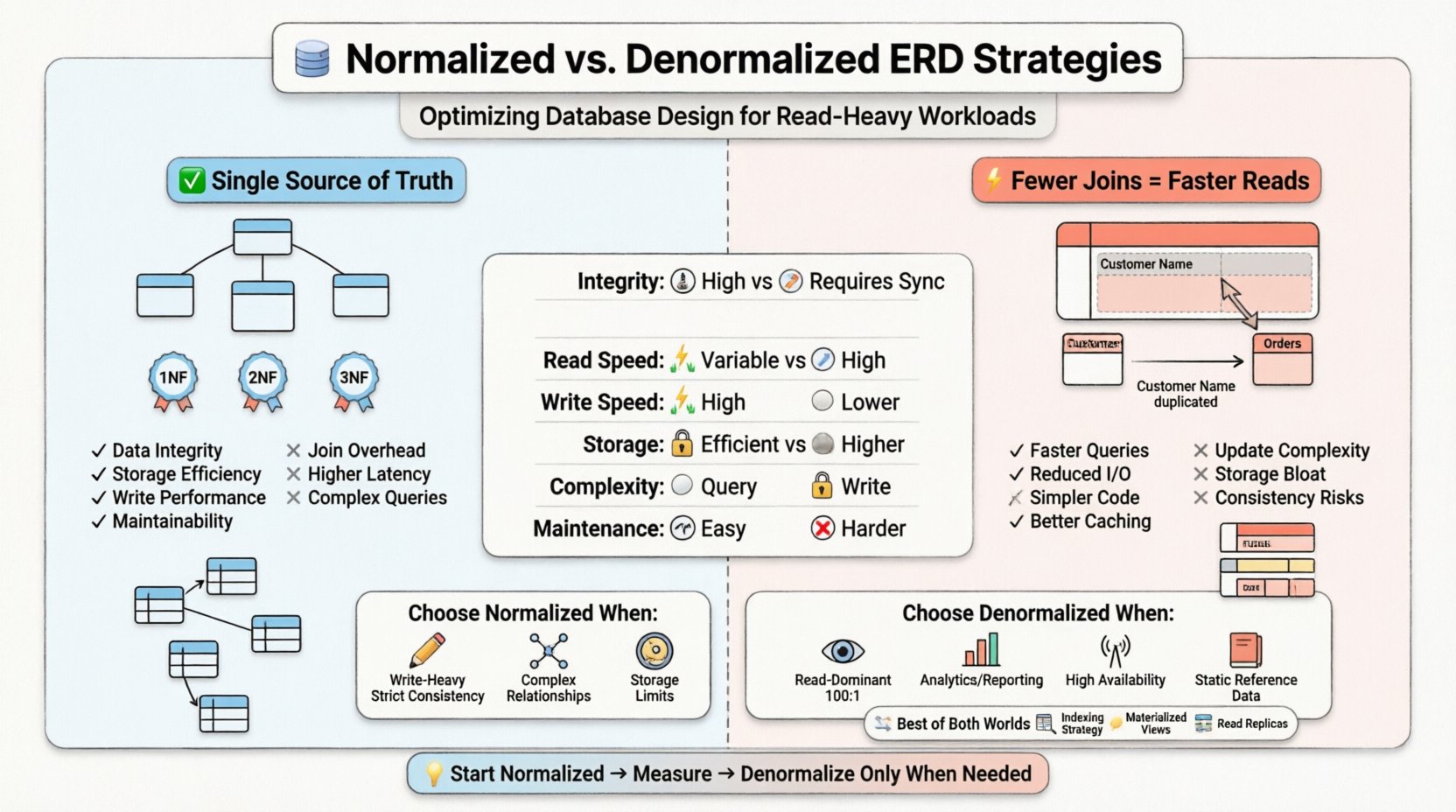
🏗️ Memahami Normalisasi dalam Desain ERD
Normalisasi adalah proses sistematis yang digunakan untuk mengurangi redundansi data dan meningkatkan integritas data. Ini mengatur atribut dan tabel dalam basis data relasional untuk meminimalkan anomali selama operasi tambah, perbarui, dan hapus. Tujuannya adalah memastikan bahwa setiap bagian data disimpan di satu tempat saja.
Prinsip Utama Normalisasi
Ketika membuat Diagram Hubungan Entitas, arsitek biasanya mengikuti hierarki aturan yang dikenal sebagai Bentuk Normal. Setiap bentuk menangani jenis redundansi tertentu.
- Bentuk Normal Pertama (1NF):Memastikan bahwa setiap kolom berisi nilai atomik dan tidak ada kelompok berulang. Ini menetapkan struktur datar untuk baris.
- Bentuk Normal Kedua (2NF):Membangun dari 1NF dengan menghilangkan ketergantungan parsial. Atribut harus bergantung pada seluruh kunci utama, bukan hanya sebagian dari kunci tersebut.
- Bentuk Normal Ketiga (3NF):Menghilangkan ketergantungan transitif. Atribut non-kunci harus hanya bergantung pada kunci utama, bukan pada atribut non-kunci lainnya.
Dalam ERD yang sangat dinormalisasi, tabel bersifat granular. Tabel pelanggan mungkin ada secara terpisah dari tabel alamatnya, yang terhubung melalui kunci asing. Tabel pesanan merujuk ke pelanggan, dan tabel item pesanan merujuk ke pesanan. Struktur ini memastikan bahwa jika pelanggan pindah, pembaruan terjadi di satu lokasi dan akan tersebar secara otomatis.
Kelebihan Skema yang Dinormalisasi
- Integritas Data:Sumber tunggal kebenaran mengurangi risiko informasi yang saling bertentangan.
- Efisiensi Penyimpanan:Data yang lebih sedikit berulang berarti jejak basis data menjadi lebih kecil.
- Kinerja Tulis:Operasi tambah, perbarui, dan hapus umumnya lebih cepat karena lebih sedikit baris yang perlu disentuh di berbagai tabel.
- Kemudahan Pemeliharaan:Perubahan pada struktur data bersifat terlokalisasi. Menambahkan atribut baru ke entitas tertentu tidak memerlukan perubahan yang menyebar ke tabel yang tidak terkait.
Kekurangan untuk Sistem yang Berat pada Baca
Meskipun normalisasi unggul dalam lingkungan yang berat pada tulis atau campuran, ia menimbulkan hambatan untuk operasi baca. Setiap join yang diperlukan untuk menyusun catatan lengkap mewakili operasi fisik pada disk atau cache memori. Dalam beban kerja yang berat pada baca, sistem mungkin perlu mengambil data dari lima atau enam tabel berbeda untuk menampilkan satu tampilan dasbor.
- Beban Join:Pemroses kueri harus mencocokkan kunci di antara tabel. Ini menghabiskan siklus CPU dan bandwidth memori.
- Operasi I/O:Jika tabel besar, mesin penyimpanan harus melakukan banyak pencarian untuk mengambil data yang terkait.
- Latensi: Waktu kumulatif dari beberapa pencarian meningkatkan waktu respons bagi pengguna akhir.
🔗 Pendekatan Denormalisasi
Denormalisasi adalah pengenalan sengaja terhadap redundansi dalam desain basis data. Tujuannya adalah mengoptimalkan sistem untuk kinerja baca dengan mengurangi jumlah join yang diperlukan. Dalam Diagram Hubungan Entitas, hal ini muncul sebagai kolom yang menggandakan data dari tabel lain atau tabel yang lebih lebar yang mengkonsolidasikan informasi terkait.
Bagaimana Denormalisasi Bekerja
Alih-alih menyimpan kunci asing untuk mencari nama pelanggan, tabel pesanan yang tidak dinormalisasi mungkin menyimpan nama pelanggan secara langsung. Jika pelanggan mengubah nama mereka, catatan pesanan harus diperbarui atau ditandai, atau sistem menerima bahwa pesanan mencerminkan nama pada saat pembelian.
Strategi ini memindahkan kompleksitas dari jalur baca ke jalur tulis. Sistem kini harus menangani logika pembaruan salinan data yang berulang.
Manfaat untuk Beban Kerja yang Berat pada Baca
- Eksekusi Kueri yang Lebih Cepat:Lebih sedikit join berarti beban komputasi yang lebih rendah.
- I/O yang Dikurangi: Lebih banyak data diambil dalam satu pemindaian tabel daripada beberapa pencarian.
- Kueri yang Disederhanakan:Kode aplikasi membutuhkan logika yang lebih sedikit untuk menggabungkan hasil.
- Efisiensi Penyimpanan Sementara (Caching):Struktur yang lebih datar sering kali lebih mudah disimpan secara efektif dalam memori.
Risiko dan Kelemahan
Biaya utama dari denormalisasi adalah konsistensi data. Jika data sumber berubah, semua salinan yang berulang harus diperbarui secara bersamaan. Gagal melakukannya menghasilkan data yang usang.
- Anomali Pembaruan: Memperbarui nama pelanggan memerlukan pencarian dan perubahan setiap catatan pesanan yang merujuk pada pelanggan tersebut.
- Pembesaran Penyimpanan:Menggandakan data meningkatkan ukuran total basis data.
- Kompleksitas dalam Tulisan:Transaksi tulis menjadi lebih kompleks, sering kali membutuhkan lebih banyak kunci atau waktu transaksi yang lebih lama.
- Kekakuan Skema:Menambahkan bidang baru mungkin memerlukan pembaruan pada beberapa tabel, bukan hanya satu.
📈 Menganalisis Karakteristik Beban Kerja yang Berat pada Baca
Untuk memilih strategi yang tepat, seseorang harus memahami sifat khusus dari beban kerja. Sistem yang berat pada baca berbeda secara signifikan dari sistem transaksional di mana tulisan sering terjadi dan kritis.
Pola Kueri
Apakah aplikasi melakukan kueri analitik yang kompleks atau pencarian sederhana? Kueri yang kompleks yang melibatkan agregasi di banyak tabel mendapat manfaat dari denormalisasi. Pencarian sederhana berdasarkan ID mungkin berjalan cukup baik dengan normalisasi jika indeks disesuaikan dengan baik.
- Pencarian Titik: Mengambil satu catatan berdasarkan ID.
- Pertanyaan Rentang:Mengambil sekumpulan catatan dalam rentang tanggal.
- Agregasi:Menghitung total, rata-rata, atau jumlah di seluruh dataset besar.
Persyaratan Latensi
Platform perdagangan frekuensi tinggi atau dashboard real-time tidak dapat menanggung latensi yang ditimbulkan oleh join yang kompleks. Dalam skenario ini, denormalisasi sering kali menjadi keharusan daripada pilihan. Sebaliknya, jika aplikasi dapat menoleransi penundaan beberapa ratus milidetik, normalisasi mungkin sudah cukup dengan pengindeksan yang tepat.
Toleransi Konsistensi Data
Apakah konsistensi segera diperlukan? Jika sistem dapat menoleransi konsistensi akhir, denormalisasi menjadi jauh lebih aman. Salinan baca atau mekanisme pembaruan asinkron dapat menangani sinkronisasi data yang berulang tanpa memblokir operasi tulis.
📋 Tabel Perbandingan Strategis
Tabel berikut merangkum perbedaan utama antara dua pendekatan tersebut dalam konteks desain basis data.
| Fitur | Skema Normalisasi | Skema Denormalisasi |
|---|---|---|
| Integritas Data | Tinggi (Sumber kebenaran tunggal) | Lebih Rendah (Membutuhkan logika sinkronisasi) |
| Kinerja Baca | Bervariasi (Terbatas pada join) | Tinggi (Lebih sedikit join) |
| Kinerja Tulis | Tinggi (Redundansi minimal) | Lebih Rendah (Memperbarui beberapa baris) |
| Penggunaan Penyimpanan | Efisien | Lebih Tinggi (Data berulang) |
| Kompleksitas | Kompleksitas Kueri Tinggi | Kompleksitas Tulis Tinggi |
| Kemudahan Pemeliharaan | Mudah untuk Perubahan Skema | Lebih Sulit untuk Perubahan Skema |
🧭 Kerangka Keputusan untuk Arsitek
Memilih jalur yang tepat memerlukan evaluasi terhadap kebutuhan bisnis terhadap keterbatasan teknis. Kerangka berikut membantu memandu proses pengambilan keputusan.
Kapan Harus Memilih Normalisasi
- Intensitas Tulis: Jika operasi tulis terjadi secara sering dibandingkan dengan bacaan, normalisasi mencegah anomali pembaruan.
- Konsistensi Ketat: Sistem keuangan atau catatan medis sering kali membutuhkan kepatuhan ACID yang ketat di mana redundansi tidak dapat diterima.
- Hubungan yang Kompleks: Ketika entitas memiliki hubungan banyak-ke-banyak yang sering berubah, normalisasi menangani pemetaan secara bersih.
- Keterbatasan Penyimpanan: Jika ruang disk sangat berharga, meminimalkan redundansi sangat menguntungkan.
Kapan Harus Memilih Denormalisasi
- Dominasi Bacaan: Jika bacaan jauh lebih banyak daripada tulisan (misalnya, 100:1), peningkatan kinerja dari jumlah join yang lebih sedikit melebihi biaya tulisan.
- Pelaporan & Analitik: Gudang data dan mesin pelaporan sering kali melakukan denormalisasi untuk mempercepat query agregasi.
- Ketersediaan Tinggi: Sistem terdistribusi mungkin melakukan denormalisasi data agar membaca dapat dilakukan pada node lokal tanpa harus melakukan loncatan jaringan ke partisi lain.
- Data Referensi Statis: Data yang jarang berubah (misalnya, kode negara, nilai tukar mata uang) merupakan kandidat utama untuk duplikasi.
🛠️ Pendekatan Hibrida dan Optimasi
Sangat jarang diperlukan untuk memilih satu ekstrem dibandingkan yang lain. Sistem modern sering menggunakan strategi hibrida untuk menyeimbangkan manfaat dari kedua model tersebut.
Strategi Pengindeksan
Sebelum melakukan denormalisasi, pastikan skema yang dinormalisasi telah diindeks secara penuh. Indeks yang mencakup dapat memungkinkan mesin penyimpanan mengambil semua data yang diperlukan dari indeks itu sendiri, menghindari pencarian tabel. Ini kadang-kadang dapat mencapai kecepatan baca yang hampir setara dengan denormalisasi tanpa redundansi data.
- Indeks Komposit: Urutkan kolom berdasarkan bidang yang paling selektif untuk mempercepat pemindaian rentang.
- Indeks Parsial: Indeks hanya pada subset data tertentu untuk mengurangi ukuran indeks dan biaya pemeliharaan.
Tampilan yang Dibuat
Tampilan yang dibuat adalah objek basis data yang menyimpan hasil dari suatu query secara fisik. Ini memungkinkan sistem untuk mempertahankan tampilan data yang tidak normal tanpa mengubah tabel dasar. Ketika data dasar berubah, tampilan yang dibuat dapat diperbarui kembali.
- Perhitungan Awal:Aggregasi yang kompleks dihitung terlebih dahulu.
- Siklus Pembaruan:Dapat diatur untuk berjalan berdasarkan jadwal atau dipicu saat terjadi perubahan data.
- Pemisahan Baca:Kueri mengakses tampilan yang dibuat, sementara operasi tulis dikirim ke tabel dasar.
Salinan Baca
Dalam arsitektur terdistribusi, salinan baca dapat dikonfigurasi untuk menyimpan salinan data yang tidak normal. Node utama menangani operasi tulis dan mempertahankan skema yang normal. Salinan menerima pembaruan secara asinkron dan melayani lalu lintas baca dengan skema yang dioptimalkan.
- Skalakan Baca:Mendistribusikan beban ke berbagai node.
- Kedekatan Geografis:Menempatkan data lebih dekat ke pengguna.
- Konsistensi Akhir:Menerima sedikit penundaan dalam penyebaran data.
⚠️ Kesalahan Umum dalam Desain Skema
Bahkan dengan strategi yang jelas, kesalahan implementasi dapat merusak kinerja. Arsitek harus tetap waspada terhadap kesalahan-kesalahan umum.
Normalisasi Berlebihan
Membuat terlalu banyak tabel untuk satu konsep dapat menyebabkan join yang berlebihan. Meskipun 3NF adalah standar, mengikuti aturan ini secara buta dalam sistem yang banyak membaca dapat menurunkan kinerja. Terkadang, pelanggaran terkendali terhadap 3NF diperlukan.
Denormalisasi yang Tidak Konsisten
Denormalisasi hanya sebagian aplikasi sementara bagian lain tetap dinormalisasi menciptakan sistem yang terfragmentasi. Ketidakkonsistenan ini membuat sulit bagi pengembang untuk memprediksi karakteristik kinerja.
Mengabaikan Volume Data
Skema yang berfungsi untuk dataset kecil dapat gagal saat volume meningkat. Denormalisasi meningkatkan kebutuhan penyimpanan secara linier terhadap jumlah catatan. Jika data tumbuh secara eksponensial, biaya penyimpanan dan beban pemeliharaan redundansi dapat menjadi tidak terkelola.
Kompleksitas Logika Pembaruan
Mengimplementasikan logika untuk menjaga data yang berulang tetap sinkron tidaklah mudah. Seringkali membutuhkan trigger, transaksi tingkat aplikasi, atau antrian pesan. Jika logika ini gagal, kerusakan data akan terjadi secara diam-diam.
🔍 Pertimbangan Implementasi
Saat beralih dari desain ke implementasi, detail teknis tertentu harus ditangani untuk memastikan keberhasilan.
Manajemen Transaksi
Pembaruan yang tidak normal sering melibatkan beberapa baris. Ini harus dibungkus dalam satu transaksi untuk memastikan atomisitas. Jika sistem mengalami kegagalan di tengah proses, data harus dikembalikan agar tidak terjadi ketidakkonsistenan.
Lapisan Penyimpanan Sementara
Bahkan dengan denormalisasi, penyimpanan sementara data yang sering diakses di memori dapat mengurangi beban basis data lebih lanjut. Cache harus dibatalkan atau diperbarui ketika data dasar berubah.
Pemantauan dan Metrik
Pemantauan terus-menerus sangat penting. Lacak waktu eksekusi kueri, persaingan kunci, dan pertumbuhan penyimpanan. Jika latensi tulis meningkat tajam, hal ini dapat menunjukkan bahwa logika pembaruan denormalisasi terlalu berat.
📝 Pertimbangan Akhir untuk Arsitek
Pilihan antara strategi ERD yang dinormalisasi dan yang tidak dinormalisasi merupakan keputusan arsitektur mendasar. Keputusan ini menentukan bagaimana data mengalir melalui sistem dan bagaimana mesin penyimpanan berinteraksi dengan aplikasi. Tidak ada jawaban yang benar satu-satunya yang berlaku untuk setiap skenario.
- Ukur Terlebih Dahulu: Jangan mengoptimalkan berdasarkan asumsi. Profil beban kerja saat ini untuk mengidentifikasi hambatan.
- Mulai Sederhana: Mulailah dengan desain yang dinormalisasi. Denormalisasi hanya dilakukan ketika metrik kinerja menunjukkan adanya kebutuhan.
- Dokumentasikan Keputusan: Catat dengan jelas mengapa redundansi diperkenalkan. Pemelihara masa depan perlu memahami pertukaran yang terjadi.
- Rencanakan untuk Evolusi: Desain skema harus berkembang. Suatu strategi yang berfungsi hari ini mungkin perlu disesuaikan seiring perubahan pola data.
Dengan memahami mekanisme join, biaya redundansi, dan tuntutan khusus dari beban kerja yang berat membaca, arsitek dapat merancang sistem yang tangguh dan berkinerja tinggi. Tujuannya bukan mengikuti aturan kaku, tetapi menerapkan alat yang paling tepat untuk lingkungan data tertentu.