











La conception architecturale a toujours reposé sur des représentations visuelles pour communiquer des systèmes complexes. Parmi celles-ci, les diagrammes de flux de données (DFD) restent une pierre angulaire pour comprendre comment les informations circulent dans un système. À mesure que la technologie évolue, le rôle de ces diagrammes passe d’une documentation statique à des artefacts dynamiques et vivants qui guident le développement, la sécurité et la conformité. Ce guide explore l’évolution des DFD dans le contexte de la conception des systèmes contemporains.
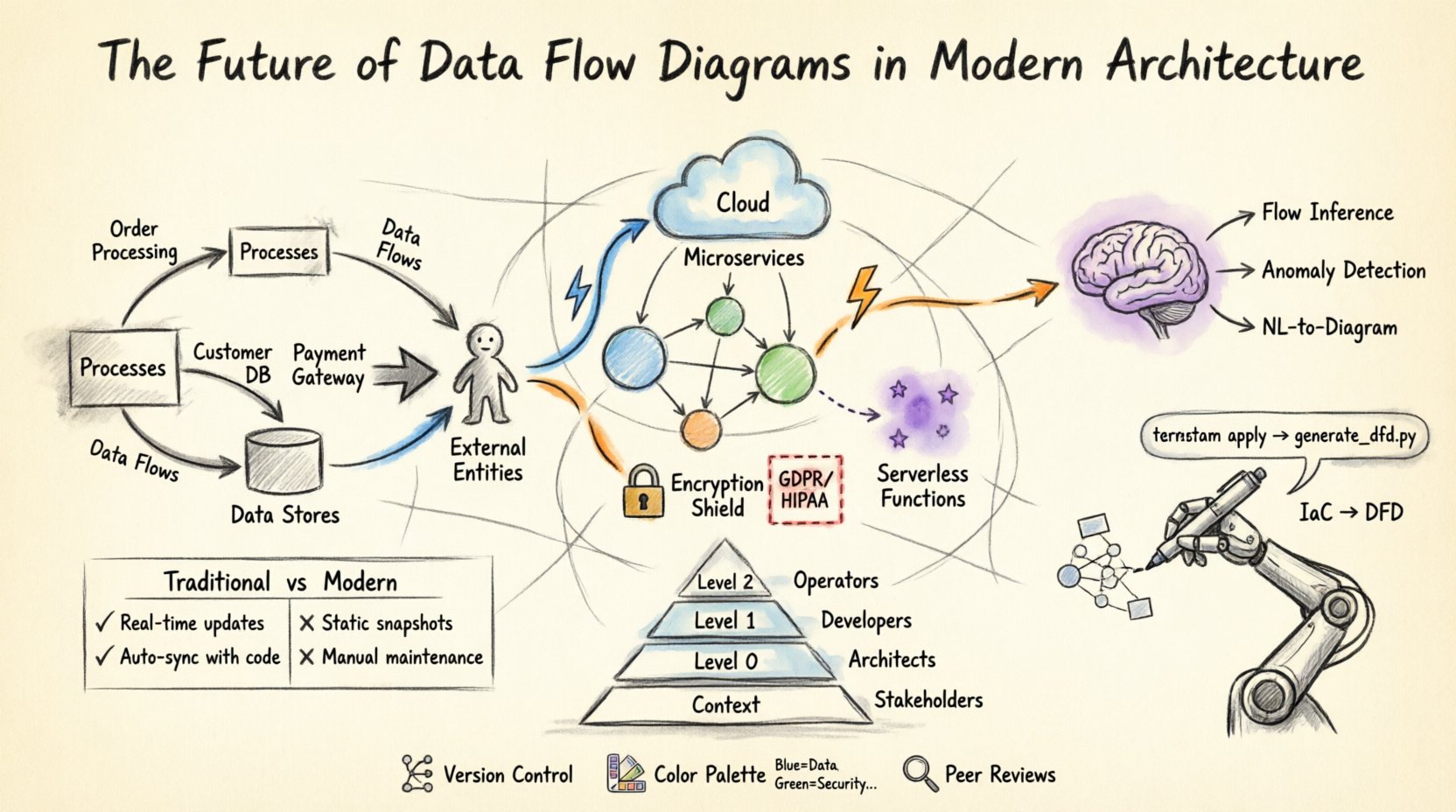
Fondements de la visualisation du flux de données 📊
Avant d’examiner l’avenir, il est nécessaire de comprendre les mécanismes fondamentaux. Un diagramme de flux de données représente le déplacement des données entre les processus, les entrepôts de données et les entités externes. Il ne contrôle ni le moment du transfert des données ni la logique du processus lui-même, mais se concentre uniquement sur le flux. Cette distinction est essentielle pour les architectes qui doivent séparer la logique du mouvement.
- Processus :Transformations qui transforment les données d’entrée en données de sortie.
- Entrepôts de données :Lieux où les informations sont conservées pour une utilisation ultérieure.
- Entités externes :Sources ou destinations de données situées en dehors de la frontière du système.
- Flux de données :Les chemins empruntés par les données entre les autres composants.
Dans les systèmes traditionnels, ces diagrammes étaient souvent créés pendant la phase de spécifications et rarement mis à jour après le déploiement. Aujourd’hui, les attentes sont différentes. Les diagrammes doivent refléter le système tel qu’il existe en production, et non pas seulement tel qu’il était prévu. Ce changement exige une réévaluation de la manière dont nous créons et entretenons ces visualisations.
Le passage aux systèmes distribués 🌐
Le passage des architectures monolithiques aux systèmes distribués a compliqué la visualisation des données. Dans un monolithe, les données circulent entre les modules au sein d’un espace de processus unique. Dans un environnement distribué, les données traversent les frontières du réseau, passent par des équilibreurs de charge, des files d’attente et des passerelles d’API.
Les DFD modernes doivent tenir compte de :
- Communication service à service :Visualiser la manière dont les microservices interagissent via REST, gRPC ou des brokers de messages.
- Flux asynchrones :Représenter les événements qui déclenchent des processus plutôt que des requêtes synchrones.
- Réplication des données :Montrer comment les données sont copiées entre les régions afin de garantir la redondance et réduire la latence.
- Intégrations tierces :Cartographier les échanges de données avec des fournisseurs ou partenaires externes.
Lors de la cartographie de ces flux, les architectes doivent distinguer les appels synchrones des événements asynchrones. Un seul diagramme échoue souvent à capturer l’ensemble du périmètre. En revanche, une approche en couches est nécessaire. Un diagramme de contexte de haut niveau montre la frontière du système, tandis que des sous-diagrammes détaillés montrent les interactions internes de clusters de services spécifiques.
Architectures natives du cloud et fonctions serverless ☁️
Le cloud computing introduit des ressources éphémères. Les fonctions serverless s’exécutent uniquement lorsqu’elles sont déclenchées et se terminent immédiatement après. Les DFD traditionnels peinent à représenter cette nature transitoire. Toutefois, les principes restent valables s’ils sont adaptés.
Les considérations clés pour les DFD basés sur le cloud incluent :
- Conception pilotée par les événements :Les flux sont souvent déclenchés par des changements d’état plutôt que par des actions utilisateur. Les diagrammes doivent montrer la source de l’événement, le déclencheur et la persistance des données résultantes.
- Traitement sans état : Les processus ne conservent pas les données. Les magasins de données deviennent des nœuds critiques dans le schéma.
- Services gérés : Les bases de données, les couches de mise en mémoire tampon et les files d’attente de messages sont souvent des services gérés. Ils doivent être clairement étiquetés comme dépendances externes ou magasins internes selon la propriété.
- Connaissance des régions : Les lois sur la souveraineté des données exigent de suivre l’emplacement des données. Les diagrammes de flux de données doivent indiquer les frontières géographiques.
Visualiser les architectures serverless exige souvent un changement de perspective, passant d’une vision centrée sur les processus à une vision centrée sur les événements. Le schéma met en évidence le déclencheur (par exemple, un fichier téléchargé) et les effets en aval (par exemple, mise à jour de la base de données, notification envoyée) plutôt que les étapes d’exécution du code.
Intégration de la sécurité et de la conformité 🔒
La sécurité n’est plus une considération secondaire. Elle est intégrée à l’architecture. Les diagrammes de flux de données constituent des outils essentiels pour les audits de sécurité. Ils révèlent où les données sensibles circulent et où elles sont stockées. Cette visibilité est essentielle pour se conformer à des réglementations telles que le RGPD, le HIPAA ou le CCPA.
Les diagrammes de flux de données efficaces axés sur la sécurité incluent :
- Points de chiffrement : Indiquer où les données sont chiffrées en transit et au repos.
- Zones d’authentification : Montrer où la vérification de l’identité de l’utilisateur a lieu avant l’accès aux données.
- Chemins de suppression : Cartographier la manière dont les données sont supprimées pour répondre aux exigences du droit à l’oubli.
- Listes de contrôle d’accès : Indiquer quelles entités ont des autorisations de lecture/écriture sur des magasins de données spécifiques.
En intégrant des attributs de sécurité dans le schéma, les architectes peuvent identifier les vulnérabilités tôt. Par exemple, si un schéma montre des données sensibles circulant par un canal non chiffré vers une entité externe, cela signale un risque avant que le code ne soit écrit. Cette approche proactive réduit le coût de correction des problèmes de sécurité plus tard dans le cycle de développement.
Automatisation et infrastructure comme code 🤖
L’un des plus grands défis liés aux diagrammes de flux de données est leur maintenance. Lorsque le code change, le schéma devient souvent obsolète. Pour résoudre ce problème, l’industrie évolue vers l’automatisation. L’infrastructure comme code (IaC) permet de définir les ressources dans des fichiers texte. De nouvelles approches lient directement ces définitions à la visualisation.
La génération automatisée des diagrammes de flux de données offre plusieurs avantages :
- Source unique de vérité : Le schéma est dérivé de la configuration, et non d’un dessin manuel.
- Mises à jour en temps réel : Les modifications dans le dépôt de code déclenchent des mises à jour du schéma.
- Consistance : Les erreurs humaines dans le tracé des connexions sont éliminées.
- Intégration avec CI/CD : Les schémas peuvent faire partie du pipeline de déploiement pour garantir la conformité de l’architecture.
Cette automatisation ne remplace pas la revue humaine. Les architectes doivent encore interpréter la complexité et s’assurer que le flux a un sens logique. Toutefois, la tâche mécanique de dessiner des boîtes et des flèches est assurée par le système. Cela permet aux architectes de se concentrer sur les décisions de conception plutôt que sur la maintenance de la documentation.
Intelligence artificielle et modélisation dynamique 🧠
L’intelligence artificielle (IA) commence à influencer la manière dont les diagrammes sont créés et analysés. Les modèles d’IA peuvent analyser les journaux et le trafic réseau pour suggérer des flux de données. Cela est particulièrement utile pour les systèmes hérités dont la documentation est absente ou inexacte.
Les applications potentielles de l’IA incluent :
- Inférence de flux : Analyser les données de capture de paquets pour reconstruire les chemins des données.
- Détection d’anomalies : Identifier les flux inattendus qui s’écartent de l’architecture standard.
- Moteurs de recommandation : Suggérer des optimisations basées sur les goulets d’étranglement des flux.
- Langage naturel vers diagramme : Convertir les exigences architecturales rédigées en texte en modèles visuels.
Cette technologie réduit la friction entre le développement et la documentation. Si le comportement du système est connu, le diagramme peut être généré automatiquement. Cela déplace l’accent de la création vers la validation. L’architecte vérifie la sortie de l’IA par rapport aux exigences métiers plutôt que de relier manuellement les lignes.
Meilleures pratiques pour les DFD modernes ✅
Pour garantir que les diagrammes restent utiles, des normes spécifiques doivent être suivies. Le respect de ces pratiques assure clarté et durabilité.
- Limitez la complexité : Maintenez les diagrammes à un niveau gérable. Utilisez la décomposition pour diviser les grands systèmes en parties plus petites et compréhensibles.
- Nommage cohérent : Utilisez des conventions de nommage standard pour les processus et les magasins de données. L’ambiguïté conduit à des interprétations erronées.
- Contrôle de version : Traitez les diagrammes comme du code. Stockez-les dans des systèmes de contrôle de version pour suivre les modifications au fil du temps.
- Codage par couleur : Utilisez la couleur pour indiquer les niveaux de sécurité, la propriété ou la sensibilité des données.
- Revue régulière : Programmez des revues périodiques pour garantir que le diagramme correspond à l’état actuel du système.
Niveaux d’abstraction 📉
Tous les parties prenantes n’ont pas besoin du même niveau de détail. Un CTO a besoin d’une vue d’ensemble, tandis qu’un développeur a besoin de détails précis. Une approche en couches répond à ce besoin.
| Niveau | Description | Public cible |
|---|---|---|
| Diagramme de contexte | Montre le système comme un seul processus et son interaction avec des entités externes. | Intervenants, gestion |
| Diagramme de niveau 0 | Divise le système en sous-processus majeurs ou en domaines fonctionnels. | Architectes système, gestionnaires de produits |
| Diagramme de niveau 1 | Détaille la logique interne de sous-processus spécifiques. | Développeurs, ingénieurs QA |
| Diagramme de niveau 2 | Approfondit des transformations spécifiques des données ou des algorithmes. | Ingénieurs spécialisés |
Utiliser cette hiérarchie évite le surcroît d’information. Elle permet à différentes équipes de se concentrer sur les détails pertinents pour leur rôle sans se perdre dans le contexte global du système.
Défis liés à la mise en œuvre ⚠️
Malgré les avantages, la mise en œuvre des pratiques modernes de DFD comporte des obstacles. Comprendre ces défis aide les équipes à planifier en conséquence.
- Environnements dynamiques : Dans les environnements conteneurisés, les adresses IP et les points de terminaison changent fréquemment. Les diagrammes statiques peuvent rapidement devenir obsolètes.
- Complexité des microservices : Des centaines de services peuvent rendre un seul diagramme illisible. Une agrégation et un filtrage sont nécessaires.
- Limites des outils : Beaucoup d’outils de diagrammation sont conçus pour la documentation statique, et non pour une intégration dynamique.
- Résistance culturelle : Les équipes peuvent considérer la documentation comme une contrainte plutôt qu’une valeur ajoutée. La direction doit insister sur les bénéfices à long terme.
Comparaison des approches traditionnelles et modernes 🆚
Comprendre les différences entre les pratiques héritées et les exigences modernes clarifie la voie à suivre.
| Fonctionnalité | DFD traditionnel | DFD moderne |
|---|---|---|
| Méthode de création | Dessin manuel à la main ou à l’aide de logiciels basiques. | Génération automatisée ou modèle hybride. |
| Cycle de vie | Créé une fois, mis à jour rarement. | Mises à jour continues liées au code. |
| Focus | Décomposition fonctionnelle. | Déplacement des données et contexte de sécurité. |
| Intégration | Document isolé. | Intégré au CI/CD et à la surveillance. |
| Évolutivité | Peine avec les grands systèmes. | Conçu pour les systèmes distribués. |
Collaboration et partage des connaissances 🤝
Les diagrammes de flux de données sont des outils de communication. Ils combler le fossé entre les exigences métiers et la mise en œuvre technique. Dans les équipes modernes, ces diagrammes facilitent la collaboration entre les disciplines.
Une collaboration efficace implique :
- Définitions partagées : Toutes les équipes s’accordent sur ce qu’un processus ou un stockage de données représente.
- Formats accessibles : Les diagrammes doivent être consultables par les parties prenantes non techniques.
- Modèles interactifs : Clic sur un composant pour révéler plus de détails ou la documentation associée.
- Boucles de retour : Les développeurs et les testeurs doivent pouvoir suggérer des corrections au diagramme.
Lorsque tout le monde utilise la même langue visuelle, les malentendus diminuent. L’intégration des nouveaux membres d’équipe devient plus rapide car l’architecture est documentée visuellement. Cela réduit la dépendance aux connaissances tribales.
Tendances futures en matière de modélisation des données 🚀
À l’avenir, plusieurs tendances façonneront l’utilisation des diagrammes de flux de données.
- Visualisation en temps réel : Diagrammes qui se mettent à jour au fur et à mesure que les données circulent dans le système en temps réel.
- Intégration avec une base de données de graphes : Utilisation de bases de données graphes pour stocker l’architecture elle-même, permettant des requêtes complexes sur les relations entre les données.
- Expériences immersives : Utilisation de la réalité virtuelle ou augmentée pour explorer l’architecture du système dans un espace en 3D.
- Web sémantique : Liaison des diagrammes aux graphes de connaissance pour un meilleur contexte et un raisonnement amélioré.
Ces tendances suggèrent que le diagramme devient de moins en moins une image statique et de plus en plus une interface interactive. La frontière entre le modèle et le système s’estompe. Cette intégration garantit que la documentation reste toujours exacte.
Pensées finales sur la documentation de l’architecture 📝
Les diagrammes de flux de données évoluent de dessins statiques vers des composants dynamiques de l’infrastructure du système. À mesure que les architectures deviennent plus distribuées et automatisées, la nécessité de visualisations claires, précises et à jour augmente. En adoptant l’automatisation, en intégrant les considérations de sécurité et en mettant en œuvre des pratiques collaboratives, les organisations peuvent garantir que leurs diagrammes restent des actifs précieux.
L’avenir des diagrammes de flux de données réside dans leur capacité à s’adapter. Ils doivent soutenir la rapidité du développement moderne sans sacrifier la clarté. Les architectes qui considèrent ces diagrammes comme des documents vivants se trouveront mieux équipés pour gérer la complexité et stimuler l’innovation. L’objectif n’est pas seulement de dessiner le système, mais de le comprendre suffisamment en profondeur pour l’améliorer continuellement.