











Concevoir une architecture de données robuste exige un équilibre entre des priorités contradictoires. L’intégrité, les performances et la maintenabilité tirent souvent dans des directions différentes. Lorsque le système se concentre davantage sur des opérations intensives en lectures, les règles traditionnelles de conception de schéma subissent une pression considérable. Le diagramme d’entité-relations (ERD) devient plus qu’un simple plan statique ; il agit comme le contrat entre la logique de l’application et le moteur de stockage. Ce guide explore la divergence stratégique entre les approches normalisées et dénormalisées, spécifiquement dans le contexte de charges de travail intensives en lectures.
Le choix entre normaliser ou dénormaliser n’est pas binaire. Il implique de comprendre le coût de la duplication de données par rapport au coût de récupération des données. Dans les environnements où les opérations de lecture dominent les journaux de transactions, minimiser la complexité des jointures devient souvent la cible principale d’optimisation. Toutefois, l’introduction de redondance crée de nouveaux défis en matière de cohérence des données et d’opérations d’écriture. Nous devons analyser les compromis afin de choisir la stratégie structurelle appropriée.
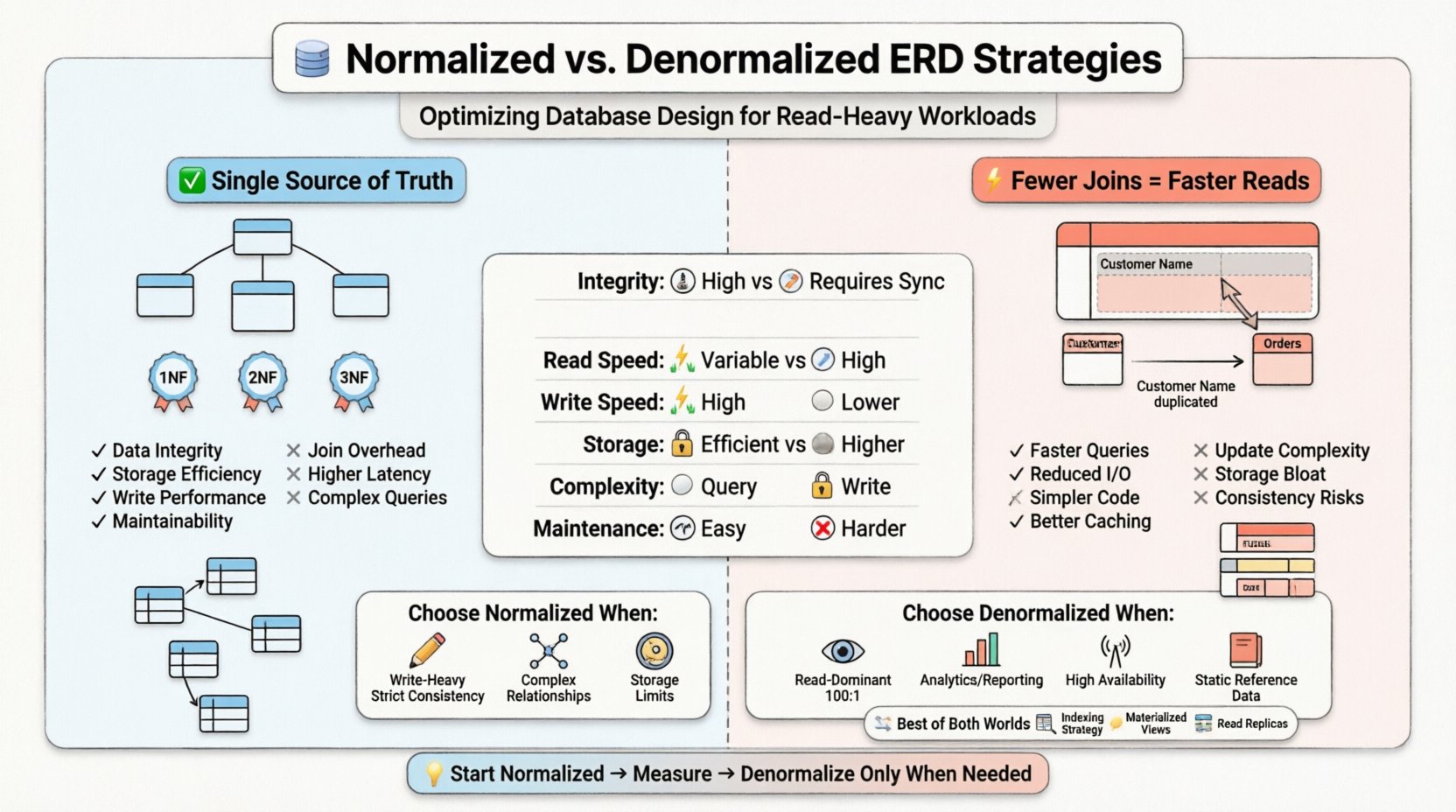
🏗️ Comprendre la normalisation dans la conception des diagrammes d’entité-relations
La normalisation est un processus systématique utilisé pour réduire la redondance des données et améliorer l’intégrité des données. Elle organise les attributs et les tables dans une base de données relationnelle afin de minimiser les anomalies lors des opérations d’insertion, de mise à jour et de suppression. L’objectif est de garantir que chaque morceau de données soit stocké à un seul endroit.
Principes fondamentaux de la normalisation
Lors de la construction d’un diagramme d’entité-relations, les architectes s’alignent généralement sur une hiérarchie de règles appelées Formes Normales. Chaque forme traite des types spécifiques de redondance.
- Première Forme Normale (1NF) : Assure que chaque colonne contient des valeurs atomiques et qu’il n’y a pas de groupes répétés. Cela établit une structure plate pour les lignes.
- Deuxième Forme Normale (2NF) : S’appuie sur la 1NF en éliminant les dépendances partielles. Les attributs doivent dépendre de la clé primaire entière, et non seulement d’une partie de celle-ci.
- Troisième Forme Normale (3NF) : Élimine les dépendances transitives. Les attributs non clés doivent dépendre uniquement de la clé primaire, et non d’autres attributs non clés.
Dans un ERD fortement normalisé, les tables sont granulaires. Une table client peut exister séparément de sa table d’adresse, liée par une clé étrangère. Une table de commande fait référence au client, et une table d’éléments de commande fait référence à la commande. Cette structure garantit qu’en cas de déménagement d’un client, la mise à jour a lieu à un seul endroit et se propage automatiquement.
Avantages d’un schéma normalisé
- Intégrité des données : Des sources uniques de vérité réduisent le risque d’informations contradictoires.
- Efficacité du stockage : Moins de données redondantes signifient que la taille de la base de données est plus petite.
- Performances d’écriture : Les opérations d’insertion, de mise à jour et de suppression sont généralement plus rapides, car moins de lignes doivent être modifiées à travers plusieurs tables.
- Maintenabilité : Les modifications aux structures de données sont localisées. L’ajout d’un nouvel attribut à une entité spécifique n’exige pas de modifications en cascade sur des tables non liées.
Inconvénients pour les systèmes à forte charge de lectures
Bien que la normalisation excelle dans les environnements à forte charge d’écriture ou mixtes, elle introduit des difficultés pour les opérations de lecture. Chaque jointure nécessaire pour assembler un enregistrement complet représente une opération physique sur le disque ou le cache mémoire. Dans une charge de travail intensive en lectures, le système peut devoir récupérer des données provenant de cinq ou six tables différentes pour afficher une vue unique du tableau de bord.
- Surcharge des jointures : Le processeur de requêtes doit correspondre les clés entre les tables. Cela consomme des cycles CPU et de la bande passante mémoire.
- Opérations d’E/S : Si les tables sont grandes, le moteur de stockage doit effectuer plusieurs recherches pour récupérer les données associées.
- Latence : Le temps cumulé de plusieurs recherches augmente le temps de réponse pour l’utilisateur final.
🔗 L’approche de dénormalisation
La dénormalisation consiste à introduire délibérément des redondances dans une conception de base de données. L’objectif est d’optimiser le système pour les performances de lecture en réduisant le nombre de jointures nécessaires. Dans le diagramme Entité-Relation, cela se traduit par des colonnes qui dupliquent des données provenant d’autres tables ou par des tables plus larges qui regroupent des informations connexes.
Comment fonctionne la dénormalisation
Au lieu de stocker une clé étrangère pour rechercher le nom d’un client, une table de commandes dénormalisée pourrait stocker le nom du client directement. Si le client change de nom, l’enregistrement de commande doit être mis à jour ou signalé, ou le système accepte que la commande reflète le nom au moment de l’achat.
Cette stratégie déplace la complexité du chemin de lecture vers le chemin d’écriture. Le système doit désormais gérer la logique de mise à jour des copies redondantes des données.
Avantages pour les charges de travail intensives en lecture
- Exécution de requêtes plus rapide : Moins de jointures signifient une surcharge computationnelle réduite.
- Réduction de l’I/O : Plus de données sont récupérées lors d’une seule analyse de table plutôt que par plusieurs recherches.
- Requêtes simplifiées : Le code de l’application nécessite moins de logique pour assembler les résultats.
- Efficacité du cache : Les structures plus plates sont souvent plus faciles à mettre en cache efficacement en mémoire.
Risques et inconvénients
Le coût principal de la dénormalisation est la cohérence des données. Si les données sources changent, toutes les copies redondantes doivent être mises à jour simultanément. En cas d’échec, cela entraîne des données obsolètes.
- Anomalies de mise à jour : La mise à jour du nom d’un client exige de trouver et de modifier chaque enregistrement de commande qui fait référence à ce client.
- Surdimensionnement du stockage : La réplication des données augmente la taille totale de la base de données.
- Complexité des écritures : Les transactions d’écriture deviennent plus complexes, souvent en nécessitant plus de verrous ou des durées de transaction plus longues.
- Rigidité du schéma : L’ajout d’un nouveau champ peut nécessiter la mise à jour de plusieurs tables, et non seulement une.
📈 Analyse des caractéristiques des charges de travail intensives en lecture
Pour choisir la bonne stratégie, il faut comprendre la nature spécifique de la charge de travail. Les systèmes intensifs en lecture diffèrent considérablement des systèmes transactionnels où les écritures sont fréquentes et critiques.
Modèles de requêtes
L’application effectue-t-elle des requêtes analytiques complexes ou des recherches simples ? Les requêtes complexes impliquant des agrégations sur de nombreuses tables bénéficient de la dénormalisation. Les recherches simples par ID peuvent fonctionner correctement avec la normalisation si les index sont bien ajustés.
- Requêtes ponctuelles : Récupération d’un enregistrement unique par ID.
- Requêtes sur plage : Récupération d’un ensemble d’enregistrements dans une plage de dates.
- Agrégations : Calcul des totaux, des moyennes ou des comptages sur de grandes ensembles de données.
Exigences de latence
Les plateformes de trading à haute fréquence ou les tableaux de bord en temps réel ne peuvent pas supporter la latence introduite par des jointures complexes. Dans ces scénarios, la dénormalisation est souvent une exigence plutôt qu’un choix. À l’inverse, si l’application peut tolérer quelques centaines de millisecondes de délai, la normalisation pourrait suffire avec un indexage approprié.
Tolérance à la cohérence des données
La cohérence immédiate est-elle requise ? Si le système peut tolérer une cohérence éventuelle, la dénormalisation devient beaucoup plus sûre. Les réplicas de lecture ou les mécanismes de mise à jour asynchrones peuvent gérer la synchronisation des données redondantes sans bloquer les opérations d’écriture.
📋 Tableau comparatif stratégique
Le tableau suivant résume les principales différences entre les deux approches dans le contexte de la conception de bases de données.
| Fonctionnalité | Schéma normalisé | Schéma dénormalisé |
|---|---|---|
| Intégrité des données | Élevée (source unique de vérité) | Moins élevée (nécessite une logique de synchronisation) |
| Performance de lecture | Variable (dépend des jointures) | Élevée (moins de jointures) |
| Performance d’écriture | Élevée (rédundance minimale) | Moins élevée (mise à jour de plusieurs lignes) |
| Utilisation du stockage | Efficace | Plus élevée (données redondantes) |
| Complexité | Complexité élevée des requêtes | Complexité élevée des écritures |
| Maintenabilité | Facile pour les modifications du schéma | Plus difficile pour les modifications du schéma |
🧭 Cadre décisionnel pour les architectes
Choisir la bonne voie nécessite d’évaluer les exigences métiers par rapport aux contraintes techniques. Le cadre suivant aide à guider le processus de décision.
Quand choisir la normalisation
- Intensité des écritures : Si les opérations d’écriture sont fréquentes par rapport aux lectures, la normalisation évite les anomalies de mise à jour.
- Consistance stricte : Les systèmes financiers ou les dossiers médicaux exigent souvent une conformité stricte aux principes ACID, où la redondance est inacceptable.
- Relations complexes : Lorsque les entités ont des relations plusieurs à plusieurs qui changent fréquemment, la normalisation gère le mappage de manière propre.
- Contraintes de stockage : Si l’espace disque est une ressource précieuse, minimiser la redondance est avantageux.
Quand choisir la dénormalisation
- Prédominance des lectures : Si les lectures surpassent largement les écritures (par exemple, 100:1), les gains de performance dus à un moindre nombre de jointures dépassent les coûts d’écriture.
- Reporting et analyse : Les entrepôts de données et les moteurs de reporting dénormalisent souvent pour accélérer les requêtes d’agrégation.
- Haute disponibilité : Les systèmes distribués peuvent dénormaliser les données pour permettre des lectures sur des nœuds locaux sans sauts réseau vers d’autres partitions.
- Données de référence statiques : Les données qui changent rarement (par exemple, les codes pays, les taux de change) sont de bons candidats à la duplication.
🛠️ Approches hybrides et optimisation
Il est rarement nécessaire de choisir un extrême au détriment de l’autre. Les systèmes modernes utilisent souvent des stratégies hybrides pour équilibrer les avantages des deux modèles.
Stratégies d’indexation
Avant de dénormaliser, assurez-vous que le schéma normalisé est entièrement indexé. Les index couvrants permettent au moteur de stockage de récupérer toutes les données nécessaires directement depuis l’index, évitant ainsi les recherches dans les tables. Cela peut parfois permettre des vitesses de lecture proches de celles de la dénormalisation, sans redondance de données.
- Index composés : Ordonnez les colonnes par les champs les plus sélectifs afin d’accélérer les balayages par plage.
- Index partiels : Indexez uniquement des sous-ensembles spécifiques de données afin de réduire la taille de l’index et son coût de maintenance.
Vues matérialisées
Une vue matérialisée est un objet de base de données qui stocke physiquement le résultat d’une requête. Elle permet au système de maintenir une vue dénormalisée des données sans modifier les tables de base. Lorsque les données sous-jacentes changent, la vue matérialisée peut être actualisée.
- Pré-calcul :Les agrégations complexes sont calculées à l’avance.
- Cycles d’actualisation :Peut être configuré pour s’exécuter selon un calendrier ou être déclenché lors d’un changement de données.
- Séparation des lectures :Les requêtes accèdent à la vue matérialisée, tandis que les écritures vont vers les tables de base.
Réplicas de lecture
Dans les architectures distribuées, les réplicas de lecture peuvent être configurés pour héberger des copies dénormalisées des données. Le nœud principal gère les écritures et maintient le schéma normalisé. Le réplica reçoit les mises à jour de manière asynchrone et assure le trafic de lecture avec un schéma optimisé.
- Mise à l’échelle des lectures :Répartit la charge sur plusieurs nœuds.
- Proximité géographique :Place les données plus près de l’utilisateur.
- Consistance éventuelle :Accepte un léger délai dans la propagation des données.
⚠️ Pièges courants dans la conception de schémas
Même avec une stratégie claire, des erreurs d’implémentation peuvent compromettre les performances. Les architectes doivent rester vigilants face aux erreurs courantes.
Sur-normalisation
Créer trop de tables pour un seul concept peut entraîner un nombre excessif de jointures. Bien que la 3NF soit une norme, s’y tenir aveuglément dans les systèmes à forte charge de lecture peut dégrader les performances. Parfois, une violation contrôlée de la 3NF est nécessaire.
Dénormalisation incohérente
Dénormaliser uniquement certaines parties de l’application tout en laissant les autres normalisées crée un système fragmenté. L’incohérence rend difficile pour les développeurs de prévoir les caractéristiques de performance.
Ignorer le volume des données
Un schéma qui fonctionne pour un petit jeu de données peut échouer lorsque le volume augmente. La dénormalisation augmente les besoins en stockage de manière linéaire avec le nombre d’enregistrements. Si les données croissent de manière exponentielle, le coût du stockage et la charge de maintenance de la redondance peuvent devenir ingérables.
Complexité de la logique de mise à jour
Mettre en œuvre la logique pour maintenir les données redondantes synchronisées n’est pas trivial. Cela nécessite souvent des déclencheurs, des transactions au niveau de l’application ou des files de messages. Si cette logique échoue, la corruption des données se produit silencieusement.
🔍 Considérations d’implémentation
Lors du passage de la conception à l’implémentation, des détails techniques spécifiques doivent être abordés pour assurer le succès.
Gestion des transactions
Les mises à jour dénormalisées englobent souvent plusieurs lignes. Elles doivent être encapsulées dans une seule transaction pour garantir l’atomicité. Si le système tombe en panne au milieu, les données doivent être annulées pour éviter toute incohérence.
Niveaux de mise en cache
Même avec la dénormalisation, le fait de mettre en cache les données fréquemment consultées en mémoire peut réduire davantage la charge de la base de données. Le cache doit être invalidé ou mis à jour lorsque les données sous-jacentes changent.
Surveillance et métriques
La surveillance continue est essentielle. Suivez les temps d’exécution des requêtes, les conflits de verrouillage et la croissance du stockage. Si la latence d’écriture augmente brusquement, cela peut indiquer que la logique de mise à jour de la dénormalisation est trop lourde.
📝 Considérations finales pour les architectes
Le choix entre des stratégies ERD normalisées ou dénormalisées est une décision architecturale fondamentale. Elle détermine la manière dont les données circulent dans le système et comment le moteur de stockage interagit avec l’application. Il n’existe pas de réponse unique valable dans tous les cas.
- Mesurez d’abord : Ne pas optimiser sur la base d’hypothèses. Profiliez la charge de travail actuelle pour identifier les goulets d’étranglement.
- Commencez par le simple : Commencez par une conception normalisée. Dénormalisez uniquement lorsque les métriques de performance indiquent un besoin.
- Documentez les décisions : Enregistrez clairement pourquoi la redondance a été introduite. Les futurs mainteneurs doivent comprendre les compromis effectués.
- Prévoyez l’évolution : Les conceptions de schémas doivent évoluer. Une stratégie qui fonctionne aujourd’hui peut nécessiter des ajustements au fur et à mesure que les modèles de données changent.
En comprenant les mécanismes des jointures, le coût de la redondance et les exigences spécifiques des charges de travail intensives en lecture, les architectes peuvent concevoir des systèmes à la fois robustes et performants. L’objectif n’est pas de suivre une règle rigide, mais d’appliquer l’outil le plus adapté à l’environnement de données spécifique.