











En la ingeniería de software moderna, los sistemas rara vez existen como entidades monolíticas. Están compuestos por múltiples servicios, procesos y unidades de almacenamiento que interactúan a través de límites de red. Comprender cómo se mueve la información entre estas unidades distintas es fundamental para mantener la integridad del sistema, diagnosticar fallos y planificar la escalabilidad. Esta guía explora el proceso de mapear y visualizar el flujo de datos dentro de arquitecturas distribuidas, utilizando específicamente el modelo C4 como marco estructural.
Sin una documentación clara, los sistemas distribuidos se convierten rápidamente en cajas negras. Los ingenieros tienen dificultades para rastrear solicitudes, identificar cuellos de botella o comprender el impacto de los cambios. Visualizar el movimiento de datos proporciona claridad. Transforma la lógica abstracta en diagramas concretos que los interesados pueden interpretar. Este documento describe las metodologías para definir límites, mapear conexiones y mantener estos diagramas con el tiempo.
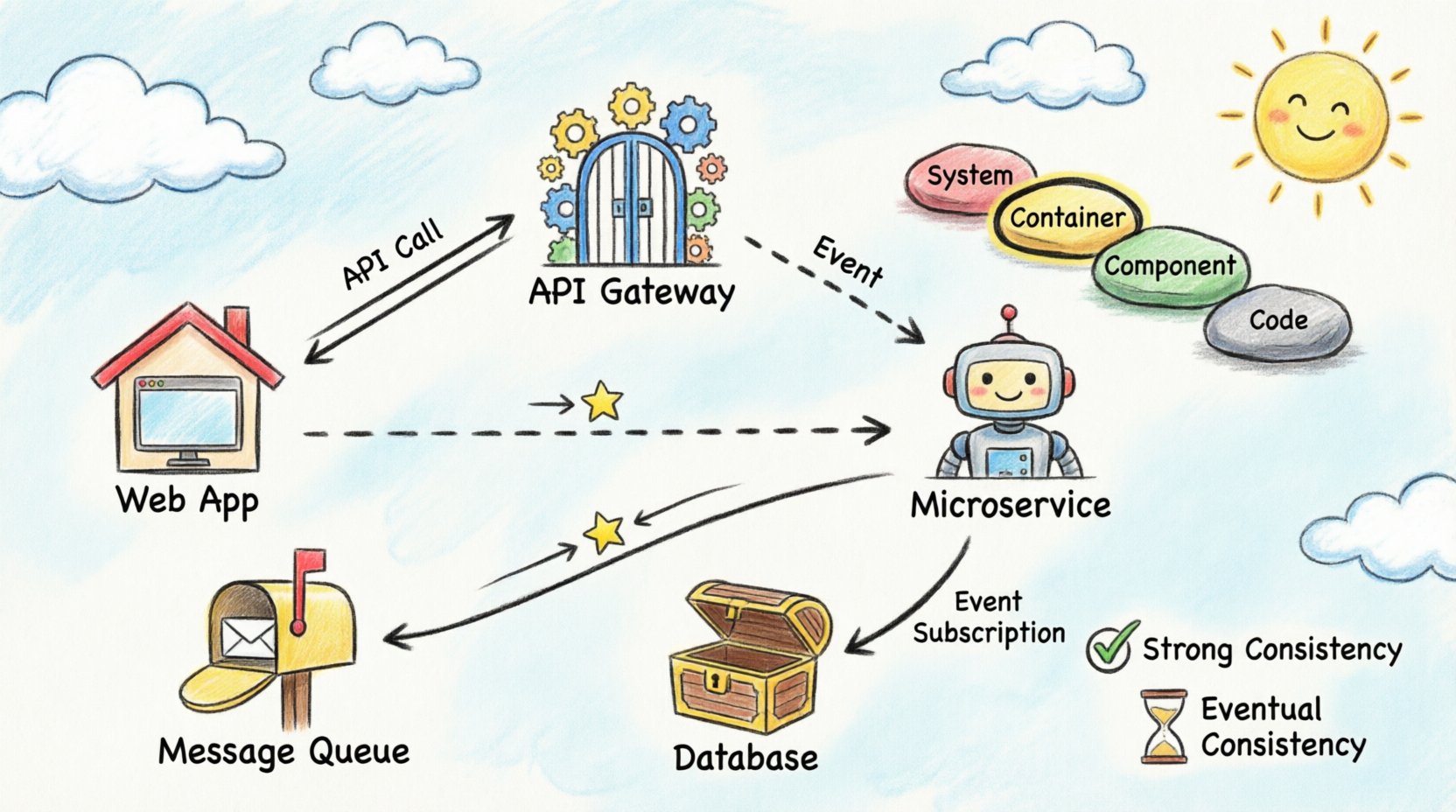
1. El panorama de la arquitectura 🌍
Los sistemas distribuidos introducen complejidad que las aplicaciones monolíticas no enfrentan. Cuando un solo proceso maneja toda la lógica, el flujo de datos es interno y lineal. Cuando intervienen múltiples contenedores o servicios, los datos atraviesan redes, pasan por firewalls y cruzan límites de confianza. Cada salto introduce latencia y puntos potenciales de fallo.
Visualizar este panorama requiere un enfoque estandarizado. Los diagramas ad hoc a menudo conducen a inconsistencias. Un ingeniero podría dibujar una base de datos como un cilindro, mientras que otro usa una caja. La estandarización garantiza que cuando se visualiza un diagrama, su significado sea inmediatamente comprensible. El modelo C4 proporciona esta estandarización al definir niveles específicos de abstracción.
Los desafíos clave en la visualización distribuida incluyen:
- Latencia de red:Visualizar dónde los datos esperan en colas o redes.
- Consistencia de datos:Mostrar cómo se sincroniza el estado entre nodos.
- Dominios de fallo:Identificar qué ocurre si un contenedor deja de responder.
- Límites de seguridad:Marcar dónde se requiere cifrado de datos o autenticación.
2. Explicación del modelo C4 📐
El modelo C4 es una jerarquía de diagramas utilizada para describir la arquitectura de software. Está compuesto por cuatro niveles, cada uno dirigido a un público y propósito diferente. Para la visualización del flujo de datos entre contenedores, los niveles de Contenedor y Componente son los más relevantes.
Nivel 1: Contexto del sistema
Esta vista de alto nivel muestra el sistema como un bloque único y sus interacciones con usuarios y sistemas externos. Responde a la pregunta: «¿Qué hace este sistema y quién lo utiliza?» Aunque es útil para el contexto, no muestra el flujo de datos interno entre contenedores.
Nivel 2: Contenedores
Este es el núcleo de la visualización distribuida. Un contenedor representa una unidad distinta de despliegue. Ejemplos incluyen aplicaciones web, aplicaciones móviles, microservicios y almacenes de datos. Este nivel ilustra cómo fluye la data entre estas unidades. Es el lugar ideal para mapear llamadas a API, colas de mensajes y conexiones directas a bases de datos.
Nivel 3: Componentes
Dentro de un contenedor, los componentes representan partes distintas del software. Este nivel profundiza en la lógica, mostrando interacciones internas entre clases o dependencias de módulos. Aunque es importante, a menudo es demasiado detallado para el análisis de flujo de datos de alto nivel.
Nivel 4: Código
Este nivel se refiere a clases y métodos específicos. Generalmente no es necesario para la documentación del flujo arquitectónico y es más adecuado para materiales de referencia específicos para desarrolladores.
3. Identificación de los límites de los contenedores 🚧
Antes de dibujar líneas de flujo de datos, debe definirse qué constituye un contenedor. Un contenedor es una unidad desplegable. Tiene un ciclo de vida independiente de otros contenedores. Puede ejecutarse en el mismo servidor físico o distribuirse en diferentes regiones.
Los tipos comunes de contenedores incluyen:
- Aplicaciones web:Interfaces de frontend accedidas a través de navegadores.
- Microservicios:Servicios de backend que manejan lógica de negocio específica.
- Pasarelas de API:Puntos de entrada que enrutan el tráfico a servicios internos.
- Almacenes de datos:Bases de datos, cachés o sistemas de archivos.
- Procesos por lotes:Tareas programadas que procesan datos de forma asíncrona.
Al definir límites, considere la estrategia de despliegue. Si dos servicios siempre se despliegan juntos y comparten memoria, podrían formar parte de un solo contenedor. Si pueden escalarse de forma independiente, deberían ser contenedores separados. Esta decisión afecta la forma en que se visualiza el flujo de datos.
4. Mapeo de patrones de flujo de datos 📡
El flujo de datos no es meramente una línea que conecta dos cajas. Representa un patrón específico de interacción. Comprender el patrón es crucial para una visualización precisa. La siguiente tabla describe patrones comunes y cómo deben representarse.
| Patrón | Dirección | Visibilidad | Casos de uso |
|---|---|---|---|
| Solicitud/Respuesta síncrona | Bidireccional (Cliente → Servidor → Cliente) | Inmediata | Llamadas a API, envíos de formularios |
| Disparo y olvido asíncrono | Unidireccional (Cliente → Servidor) | Diferida | Registro de eventos, eventos de análisis |
| Procesamiento basado en extracción | Unidireccional (Trabajador ← Cola) | A petición | Tareas en segundo plano, Ingesta de datos |
| Suscripción a eventos | Unidireccional (Publicador → Suscriptor) | Desencadenado por evento | Notificaciones, cambios de estado |
Comunicación síncrona
En flujos síncronos, el remitente espera una respuesta. Esto es común en interacciones de API. Al visualizar esto, utiliza líneas sólidas con flechas que indican la solicitud y la respuesta. Etiqueta el protocolo utilizado, como HTTP o gRPC. Esto ayuda a los ingenieros a comprender la naturaleza bloqueante de la interacción.
Comunicación asíncrona
Los flujos asíncronos desacoplan al remitente del receptor. El remitente coloca un mensaje en una cola y continúa. El receptor procesa el mensaje más tarde. Visualízalo utilizando líneas punteadas o íconos distintos para representar el broker de mensajes. Es fundamental indicar el nombre de la cola para distinguir entre diferentes flujos de datos.
5. Manejo de la sincronización y la consistencia ⚖️
Una de las partes más difíciles del flujo de datos distribuido es la gestión del estado. Cuando se escribe datos en un contenedor, ¿se reflejan inmediatamente en otro? La visualización debe capturar estos requisitos de consistencia.
Consistencia fuerte
Algunos sistemas requieren que todos los nodos vean los mismos datos al mismo tiempo. Esto implica a menudo una única fuente de verdad o replicación síncrona. En los diagramas, marca estas conexiones con etiquetas que indiquen “Consistencia fuerte” o “ACID”. Esto alerta a los interesados de que una interrupción en una parte del sistema puede afectar a otras.
Consistencia eventual
Muchos sistemas distribuidos priorizan la disponibilidad sobre la consistencia inmediata. Los datos pueden tardar segundos o minutos en propagarse. Visualízalo añadiendo un indicador de tiempo o una etiqueta “Sincronización” con una notación de retraso. Esto gestiona las expectativas sobre cuándo los usuarios verán la información actualizada.
Contenedores sin estado frente a contenedores con estado
Los contenedores sin estado no almacenan datos localmente. Dependen de bases de datos externas o cachés. Los contenedores con estado almacenan datos dentro de su propio almacenamiento. Al mapear el flujo, asegúrate de que el almacenamiento externo esté claramente separado del contenedor. Si un contenedor almacena datos, la línea de flujo debe apuntar a un ícono de almacenamiento dentro o adjunto a ese contenedor.
6. Mantenimiento de la documentación 📝
Un diagrama solo es útil si es preciso. Con el tiempo, el código cambia, se añaden nuevos servicios y se eliminan servicios obsoletos. Los diagramas estáticos se vuelven obsoletos rápidamente. Se requiere una estrategia de mantenimiento.
Las mejores prácticas para mantener la documentación actualizada incluyen:
- Generación automática:Donde sea posible, genera diagramas a partir de anotaciones de código o archivos de configuración. Esto reduce el esfuerzo manual y evita la desincronización entre el código y la documentación.
- Ciclos de revisión:Incluye las actualizaciones del diagrama en la definición de finalización para las solicitudes de extracción. Si cambia la interfaz de un servicio, el diagrama también debe cambiar.
- Versionado:Trata los diagramas de arquitectura como código. Guárdalos en sistemas de control de versiones para rastrear el historial y permitir la reversión si un cambio es incorrecto.
- Estándares de herramientas:Utiliza una pila de herramientas consistente. Evita cambiar entre diferentes plataformas de diagramación para distintos equipos.
7. Peligros comunes que deben evitarse 🛑
Incluso con un enfoque estructurado, pueden ocurrir errores durante el proceso de visualización. Ser consciente de los errores comunes ayuda a mantener una documentación de alta calidad.
Sobresimplificación
Es tentador simplificar demasiado los diagramas. Si agrupas diez servicios en una sola caja etiquetada como “Backend”, pierdes la capacidad de rastrear rutas específicas de datos. Mantén el nivel de granularidad del contenedor. No fusiones unidades de despliegue distintas a menos que compartan exactamente el mismo ciclo de vida.
Ignorar las rutas de fallo
La mayoría de los diagramas muestran el camino feliz en el que todo funciona. Una visualización robusta también indica los modos de fallo. ¿A dónde va el flujo si un servicio expira? ¿Existe un servicio de respaldo? ¿Existe una cola de mensajes fallidos? Añadir estas rutas convierte el diagrama en una herramienta para la planificación de resiliencia.
Nombres inconsistentes
Utilice la misma terminología para los servicios en el diagrama que en la base de código. Si un servicio se llama «Order-Service» en el código, no lo etiquete como «API de Pedidos» en el diagrama. Esto genera confusión durante las sesiones de depuración.
Falta de tipos de datos
Una línea entre dos contenedores te indica *que* los datos se mueven, pero no *qué* datos se mueven. Es útil anotar las líneas con el tipo de carga de datos. Por ejemplo, «Carga JSON», «Imagen binaria» o «Lote CSV». Esto informa a los ingenieros sobre la complejidad del procesamiento requerido en el extremo receptor.
8. Mejores prácticas para el mantenimiento y el crecimiento 📈
A medida que el sistema crece, el diagrama puede volverse caótico. Gestionar la complejidad es una tarea continua. Aquí tiene estrategias para mantener la visualización limpia y útil.
- Capas:Utilice capas diferentes para diferentes preocupaciones. Una capa para la seguridad, otra para el flujo de datos y una tercera para la topología de despliegue. Evite dibujar todas estas capas en una sola página.
- Enlaces a detalles:Si un contenedor es complejo, cree un subdiagrama separado para él. Enlace el diagrama principal con la vista detallada en lugar de dibujar cada componente en la página de visión general.
- Codificación por colores:Utilice colores para indicar estado o criticidad. Rojo para rutas críticas, azul para flujos estándar y gris para conexiones obsoletas. Esto permite una inspección visual rápida del estado del sistema.
- Metadatos:Incluya la versión del diagrama y la fecha de la última revisión en el pie de página del documento. Esto proporciona contexto sobre cuán actualizada está la información.
9. Integración con la observabilidad 🔍
Los diagramas estáticos son estáticos. Los sistemas reales son dinámicos. Las arquitecturas modernas integran diagramas con plataformas de observabilidad. Esto significa que el diagrama no es solo una imagen, sino una interfaz en vivo.
Al visualizar el flujo de datos, considere cómo se relaciona el diagrama con los datos de monitoreo. Si observa una alta latencia en una conexión específica en la herramienta de monitoreo, el diagrama debe mostrar claramente esa conexión. Esta vinculación ayuda en el análisis de la causa raíz. Los ingenieros pueden hacer clic en una línea del diagrama y ver las métricas actuales para ese enlace.
Esta integración requiere que el formato del diagrama permita incrustar o vincular con fuentes de datos externas. Asegúrese de que el método elegido para crear diagramas permita esta flexibilidad sin requerir actualizaciones manuales cada vez que cambie una métrica.
10. Resumen de los puntos clave ✅
Visualizar el flujo de datos en sistemas distribuidos es una disciplina que equilibra la precisión técnica con la legibilidad. Al adherirse al modelo C4, los equipos pueden crear un lenguaje consistente para la arquitectura. El nivel de contenedores proporciona los detalles necesarios para comprender las interacciones entre servicios sin sobrecargar con complejidad.
Puntos clave para recordar:
- Defina los límites claramente:Asegúrese de que los contenedores coincidan con las unidades de despliegue.
- Mapee los patrones explícitamente:Distinga entre flujos síncronos y asíncronos.
- Documente los modelos de consistencia:Indique cómo se gestiona el estado a través de los límites.
- Mantenga rigurosamente:Trate los diagramas como documentos vivos que evolucionan con el código.
- Evite el hype:Enfóquese en la claridad y la precisión en lugar de vender la arquitectura.
Al seguir estos principios, los equipos de ingeniería pueden reducir la carga cognitiva, acelerar la incorporación de nuevos miembros y mejorar la fiabilidad general de su infraestructura distribuida. El objetivo no es solo trazar líneas, sino construir una comprensión compartida de cómo funciona el sistema.