











Los diagramas de relaciones entre entidades (ERD) se encuentran en la base de una arquitectura de datos sólida. Proporcionan el plano visual de cómo se estructura, almacena y accede a la información dentro de un sistema de bases de datos. A pesar de su importancia crítica, el panorama que rodea el diseño de ERD a menudo está nublado por narrativas de marketing. Los proveedores y consultores presentan con frecuencia las herramientas de diagramación como balas de plata que resuelven instantáneamente desafíos complejos de modelado de datos. Este enfoque ignora la lógica rigurosa necesaria para construir un entorno de datos sostenible.
Para construir sistemas que perduren, debemos mirar más allá de la hype. Necesitamos comprender las realidades técnicas de las relaciones, las restricciones y la normalización. Esta guía analiza los mitos comunes sobre los ERD. Exploraremos la diferencia entre un modelo teórico y una implementación física. El objetivo no es promover una herramienta o metodología específica, sino aclarar los principios que rigen la integridad de los datos.
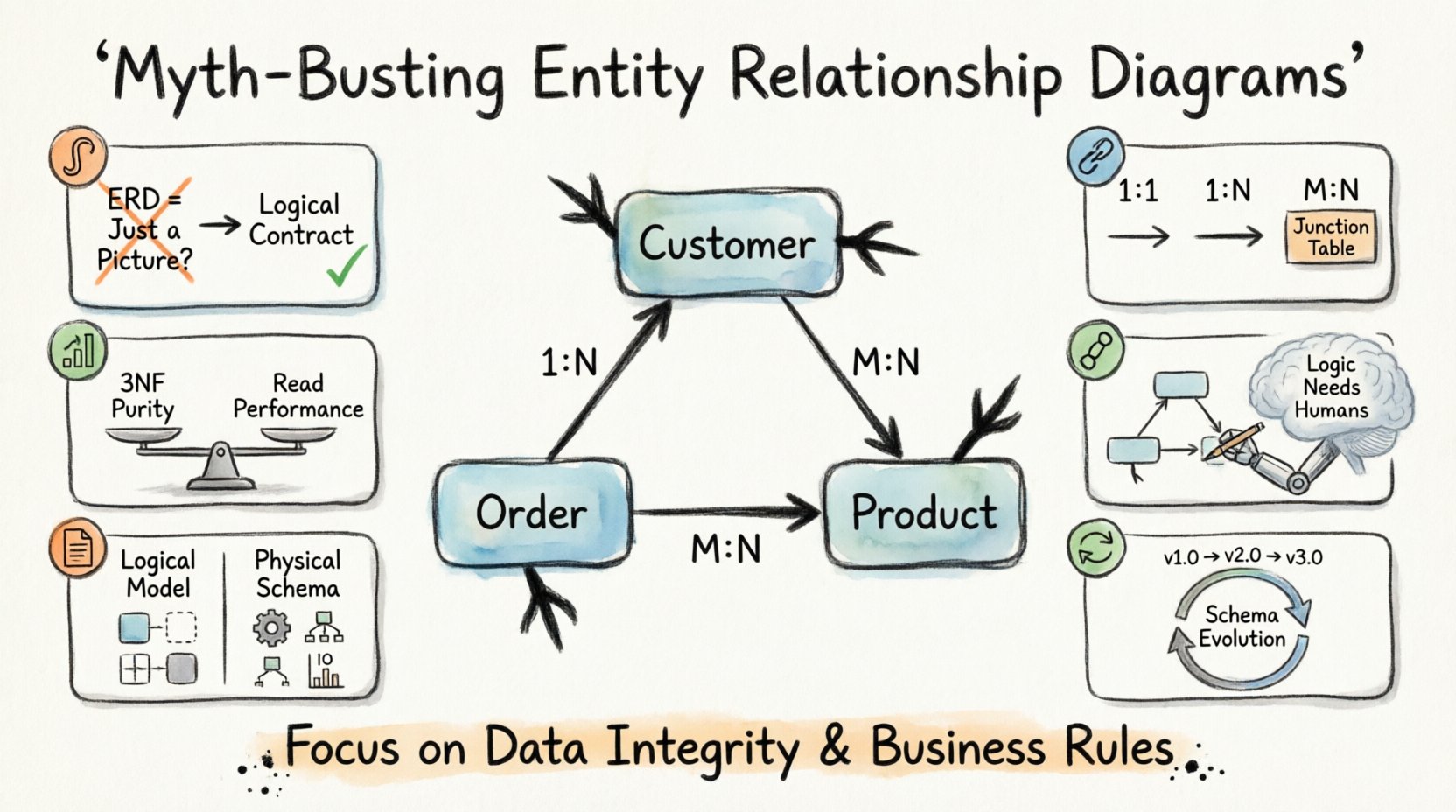
1. La trampa visual: ¿Un ERD es solo un diagrama? 🎨
Uno de los mitos más extendidos sugiere que un diagrama de relaciones entre entidades es meramente un artefacto de documentación. Muchos equipos tratan el diagrama como un entregable posterior al proyecto, algo creado después de escribir el código para satisfacer a los interesados. Esta visión es fundamentalmente defectuosa. Un ERD es un contrato lógico, no una imagen.
Cuando un ERD se trata como una consideración visual posterior, surgen varios riesgos:
- Desviación de esquema: La estructura de la base de datos se desvía del diseño previsto, lo que conduce a entradas de datos inconsistentes.
- Cuellos de botella de rendimiento: Las consultas fallan porque la estructura subyacente no soporta de forma eficiente las uniones necesarias.
- Pérdida de integridad de datos: Las restricciones de clave foránea se ignoran, permitiendo la existencia de registros huérfanos.
Considere el ciclo de vida de una tabla de base de datos. Comienza con un requisito del negocio. Luego pasa a un modelo lógico. A continuación se convierte en un esquema físico. El ERD puentes el vacío entre la lógica del negocio y el almacenamiento técnico. Si el diagrama no es la fuente de la verdad, la base de datos inevitablemente sufrirá ambigüedades.
Un modelado de datos eficaz requiere una atención rigurosa a los detalles. No se trata de dibujar cajas y líneas. Se trata de definir las reglas de interacción para los datos. Cada línea en un ERD representa una restricción. Cada caja representa una unidad de datos que debe conservarse. Ignorar esta realidad conduce a sistemas frágiles y difíciles de mantener.
2. Cardinalidad y relaciones: Más allá de lo básico 🔗
La cardinalidad define la relación numérica entre entidades. Responde a la pregunta: ¿Cuántas instancias de una entidad se relacionan con instancias de otra? Los materiales de marketing suelen simplificar esto en uno a muchos o muchos a muchos sin explicar las implicaciones.
Comprender la cardinalidad es crucial para el rendimiento de las consultas y la consistencia de los datos. Hay tres tipos principales de relaciones:
- Uno a uno (1:1): Cada registro en la tabla A se relaciona con exactamente un registro en la tabla B. Esto se utiliza a menudo para seguridad o separación de datos.
- Uno a muchos (1:N): Un registro en la tabla A se relaciona con múltiples registros en la tabla B. Esta es la relación más común en los sistemas transaccionales.
- Muchos a muchos (M:N): Varios registros en la tabla A se relacionan con varios registros en la tabla B. Esto requiere una tabla de unión para resolver físicamente.
Un malentendido común es que las relaciones uno a uno siempre son superiores para la separación de datos. Aunque ofrecen aislamiento, pueden introducir una complejidad innecesaria. Dividir los datos en dos tablas cuando una sola tabla sería suficiente aumenta la sobrecarga de unión. Esto puede degradar el rendimiento durante las operaciones de lectura.
Por el contrario, ignorar las relaciones muchos a muchos puede llevar a la duplicación de datos. Si intenta almacenar una lista de valores en una sola columna sin una tabla de unión adecuada, viola las reglas de normalización. Esto hace que actualizar y consultar los datos sea significativamente más difícil.
| Tipo de relación | Implementación física | Error común |
|---|---|---|
| Uno a uno | Clave foránea en cualquiera de las tablas | Sobresegmentación de datos |
| Uno a muchos | Clave foránea en la tabla «muchos» | Errores de referencia circular |
| Muchos a muchos | Tabla de unión con dos claves foráneas | Falta de restricciones únicas en la tabla de unión |
Al diseñar estas relaciones, debe considerar las reglas del negocio. ¿Un cliente tiene una dirección o varias? ¿Un producto pertenece a una categoría o a varias? El diagrama debe reflejar la realidad operativa, no una versión idealizada de ella.
3. Normalización: El mito de la 3FN 📊
La normalización es una técnica utilizada para organizar los datos y reducir la redundancia. La Tercera Forma Normal (3FN) a menudo se cita como el estándar de oro. El mito sugiere que cada base de datos debe estar completamente normalizada hasta la 3FN para considerarse válida. Esto no siempre es cierto.
La normalización elimina las anomalías. Estas son problemas que ocurren durante la inserción, actualización o eliminación de datos. Por ejemplo, si almacena el nombre de un cliente en cada registro de pedido, cambiar el nombre requiere actualizar miles de filas. Esto es una anomalía de actualización. La normalización lo corrige al mover el nombre a una tabla de clientes separada.
Sin embargo, el cumplimiento estricto de la 3FN puede perjudicar el rendimiento. Cada relación requiere una unión. Las uniones son computacionalmente costosas. En sistemas de informes de alto tráfico, la normalización excesiva puede ralentizar la ejecución de consultas. Es aquí donde entra en juego la denormalización.
La denormalización es la introducción intencional de redundancia para mejorar el rendimiento de lectura. Es una compensación. Usted sacrifica la velocidad de escritura y la eficiencia de almacenamiento a cambio de lecturas más rápidas. Esta decisión nunca debe tomarse a la ligera. Requiere una comprensión profunda de los patrones de acceso.
Las consideraciones clave para la normalización incluyen:
- Equilibrio entre lectura y escritura:¿El sistema es de lectura intensiva o de escritura intensiva?
- Complejidad de la consulta:¿Qué tan complejos son los informes requeridos?
- Costos de almacenamiento:¿Es asequible la redundancia?
Seguir ciegamente la 3FN sin analizar la carga de trabajo es una receta para una aplicación lenta. El objetivo es equilibrar la integridad de los datos con los requisitos de rendimiento. A veces, una vista denormalizada con cuidado es la solución mejor que un esquema perfectamente normalizado.
4. Dependencia de herramientas: Automatización frente a lógica 🤖
Las herramientas modernas ofrecen funciones como generación automática de esquemas y ingeniería inversa. Los proveedores promocionan estas capacidades como ahorradores de tiempo. El mito aquí es que la herramienta puede reemplazar al diseñador. Una herramienta de diagramación puede dibujar líneas, pero no puede comprender el contexto del negocio.
La generación automatizada a menudo produce esquemas técnicamente correctos pero lógicamente defectuosos. Puede crear tablas basadas en la inspección de código en lugar de los requisitos del negocio. Podría pasar por alto relaciones ocultas que no están explícitamente codificadas.
La supervisión humana es esencial. El modelador de datos debe validar la salida contra las necesidades reales de la organización. Las tareas clave que no pueden automatizarse incluyen:
- Definir reglas de negocio:Determinar qué atributos son obligatorios.
- Manejo de casos extremos:Decidir cómo manejar valores nulos o eliminaciones suaves.
- Optimización para el crecimiento futuro: Anticipando cómo crecerá los datos.
Las herramientas son auxiliares, no arquitectos. Facilitan la creación del diagrama, pero la lógica reside en la mente humana. Depender únicamente de la automatización lleva a sistemas rígidos y difíciles de adaptar. La herramienta debe apoyar el flujo de trabajo, no dictarlo.
5. La brecha de implementación física 📝
Existe una diferencia clara entre un modelo lógico y un modelo físico. El modelo lógico describe entidades y relaciones de forma conceptual. El modelo físico define tipos de datos, índices y restricciones.
Muchos equipos asumen que el modelo lógico se traduce directamente en la base de datos física. Esto rara vez ocurre. Los diferentes sistemas de bases de datos tienen capacidades distintas. Una relación que funciona bien en un sistema podría funcionar mal en otro.
Por ejemplo, los tipos de datos varían. Un campo definido como «Texto» en un modelo lógico podría necesitar ser «VARCHAR(255)» o «TEXT» en la base de datos física. Las estrategias de indexación también difieren. Un índice que acelera las consultas en un sistema podría ralentizar las escrituras en otro.
Al pasar del diseño a la implementación, debes ajustarte a la pila tecnológica específica. Considera los siguientes ajustes:
- Tipos de datos: Asegúrate de que los tipos elegidos coincidan con el motor de almacenamiento.
- Índices: Agrega índices para las columnas consultadas con frecuencia.
- Particionado: Considera dividir las tablas grandes para una mejor gestión.
- Restricciones: Decide entre comprobaciones a nivel de aplicación y restricciones a nivel de base de datos.
Ignorar estas diferencias lleva a una brecha entre el diseño y la realidad. El sistema puede funcionar, pero no estará optimizado. Es necesario realizar una revisión exhaustiva de la implementación física para asegurar que el diseño resista la carga.
6. Mantenimiento y evolución 🔄
Otro mito importante es que un diseño de base de datos es estático. Una vez aprobado el diagrama entidad-relación, queda fijo para siempre. En realidad, los requisitos del negocio cambian. Se añaden nuevas funcionalidades. Las regulaciones evolucionan. El modelo de datos debe evolucionar con ellos.
Refactorizar una base de datos es difícil. Cambiar el tipo de una columna o una relación puede romper aplicaciones existentes. Por lo tanto, el diseño debe ser lo suficientemente flexible para acomodar cambios sin requerir una reconstrucción completa. Las estrategias para la mantenibilidad incluyen:
- Versionado: Rastrea los cambios en el esquema con el tiempo.
- Scripts de migración: Automatiza la implementación de cambios.
- Documentación: Mantén el diagrama actualizado junto con el código.
La documentación a menudo se descuida hasta que ya es demasiado tarde. Cuando un desarrollador abandona el proyecto, se pierde el conocimiento sobre la estructura de los datos. Un diagrama ER actualizado sirve como referencia principal para los nuevos miembros del equipo. Reduce la curva de aprendizaje y previene errores.
La evolución requiere disciplina. Cada cambio debe evaluarse por su impacto en los datos existentes. La compatibilidad hacia atrás debe mantenerse siempre que sea posible. Esto asegura que las aplicaciones que dependen de la base de datos no fallen inesperadamente.
7. Resumen de mitos comunes frente a la realidad
Para resumir los puntos clave, podemos categorizar los mitos más frecuentes. Esta tabla proporciona una referencia rápida para distinguir entre afirmaciones de marketing y hechos técnicos.
| Mito | Realidad |
|---|---|
| Los ERD son solo imágenes atractivas | Los ERD son contratos técnicos que definen las reglas de los datos |
| Más tablas significan un mejor diseño | La complejidad reduce el rendimiento; el equilibrio es clave |
| La normalización siempre es el objetivo | La denormalización mejora la velocidad de lectura en casos específicos |
| Las herramientas pueden automatizar el diseño | Las herramientas ayudan, pero la lógica requiere supervisión humana |
| Los modelos lógicos equivalen a los esquemas físicos | La implementación física requiere optimizaciones específicas |
| El diseño es permanente | Los esquemas deben evolucionar con las necesidades del negocio |
Conclusión final sobre el modelado de datos 🧭
Construir un sistema de bases de datos confiable requiere una comprensión clara de los principios subyacentes. Los Diagramas de Relación de Entidades son herramientas poderosas cuando se usan correctamente. Proporcionan un lenguaje común entre los interesados del negocio y los equipos técnicos.
Sin embargo, no son mágicos. No resuelven por sí mismos los problemas de datos. El valor proviene de la aplicación rigurosa de la lógica durante la fase de diseño. Debemos rechazar la idea de que las herramientas de software pueden reemplazar el pensamiento crítico. También debemos aceptar que la normalización no es una solución de tamaño único para todos los casos.
El éxito en el diseño de bases de datos depende de la claridad, la precisión y la adaptabilidad. Al separar el exceso de promoción comercial de la realidad técnica, puedes construir sistemas que sean robustos y escalables. Enfócate en la integridad de los datos y en las reglas del negocio. Deja que el diagrama sirva como guía, no como destino.
Cuando abordes el modelado de datos con estos principios en mente, los resultados hablan por sí mismos. El sistema será más fácil de mantener. Las consultas se ejecutarán más rápido. Los datos permanecerán precisos. Este es el verdadero valor de un Diagrama de Relación de Entidades bien construido.