









Die Unternehmensarchitektur erfordert präzise Definitionen, um sicherzustellen, dass Systeme wie vorgesehen funktionieren. Daten bilden die Grundlage für diese Funktionalität. Beim Modellieren im ArchiMate-Framework ist es entscheidend zu verstehen, wo sich Daten befinden und wie sie mit Anwendungen interagieren. Die Anwendungsschicht bietet einen spezifischen Kontext, um visuell darzustellen, wie Informationen verarbeitet werden. Diese Anleitung beschreibt die Methodik zur Strukturierung von Datenmodellen innerhalb dieser spezifischen Schicht. Wir werden die Beziehungen, Elemente und bewährten Praktiken untersuchen, die für eine genaue Darstellung erforderlich sind.
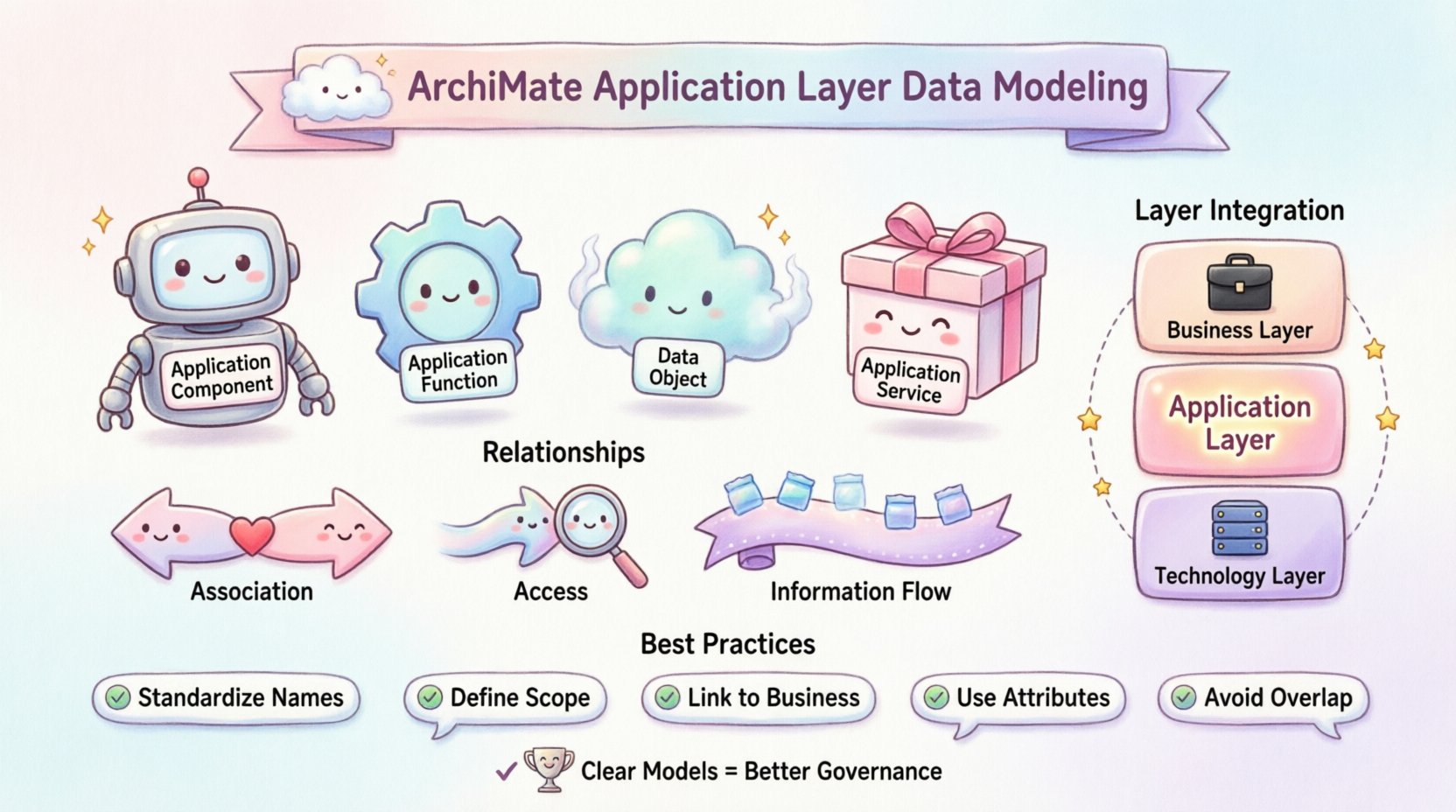
📊 Der Kontext der Anwendungsschicht
Die Anwendungsschicht wirkt als Schnittstelle zwischen geschäftlichen Anforderungen und technischer Umsetzung. Sie beschreibt die Softwarekomponenten und Dienste, die Funktionalität für die Organisation bereitstellen. Im Gegensatz zur Geschäftslogikschicht, die sich auf Prozesse und Rollen konzentriert, fokussiert sich die Anwendungsschicht auf die wieder Datenverarbeitung. Datenobjekte in dieser Schicht repräsentieren den Informationszustand, der von bestimmten Anwendungen verwaltet wird.
Die korrekte Strukturierung dieser Modelle vermeidet Mehrdeutigkeiten. Ein klares Modell stellt sicher, dass Stakeholder verstehen, welche Anwendung welche Daten besitzt. Diese Klarheit unterstützt die Governance und reduziert technischen Schulden. Folgende Kernkomponenten sind an dieser Struktur beteiligt:
- Anwendungskomponente: Eine bereitstellbare Einheit von Software, die Informationen verarbeitet.
- Anwendungsfunction: Eine logische Funktion, die von einer Anwendungskomponente ausgeführt wird.
- Datenobjekt: Der Informationszustand oder das Dokument, das von der Anwendung verwaltet wird.
- Anwendungsdienst: Die Fähigkeit, die die Anwendung der Außenwelt bietet.
🔗 Definieren von Beziehungen für Daten
Beziehungen definieren den Fluss und die Abhängigkeit von Daten innerhalb der Architektur. In der Anwendungsschicht ordnen spezifische Beziehungstypen die Bewegung von Informationen zwischen Funktionen und Komponenten zu. Das Verständnis dieser Zuordnungen ist entscheidend für die Verfolgung der Datenherkunft.
1. Assoziation mit Datenobjekten
Eine AssoziationBeziehung zeigt an, dass eine bestimmte Funktion oder Komponente mit einem Datenobjekt interagiert. Dies ist der häufigste Link bei der Datenmodellierung. Sie impliziert, dass die Funktion aus dem Datenobjekt liest, in das Datenobjekt schreibt oder das Datenobjekt modifiziert.
- Richtung: Typischerweise bidirektional, obwohl die Semantik einen Fluss implizieren kann.
- Verwendung: Verwenden Sie dies, um Eigentum oder direkten Zugriff zu zeigen.
- Beispiel: Eine „Kundenverwaltungs-Funktion“ ist mit dem Datenobjekt „Kundenprotokoll“ assoziiert.
2. Zugriffsbeziehungen
Obwohl ähnlich wie Assoziation, ist eine Zugriff Beziehung legt fest, dass eine Funktion auf ein Datenobjekt zugreift. Dies wird häufig verwendet, wenn die Interaktion hauptsächlich Lesevorgänge umfasst oder wenn die Funktion ein Client ist, der auf ein von einer anderen Komponente verwaltetes Datenspeicher zugreift.
- Verwendung: Unterscheidet zwischen Eigentum und Nutzung.
- Klarheit: Hilft dabei, festzustellen, welche Komponente die Quelle der Wahrheit ist.
3. Informationsfluss
Informationsfluss beschreibt die Bewegung von Daten von einem Element zum anderen. In der Anwendungsschicht erfolgt dies häufig zwischen Funktionen oder zwischen einer Funktion und einer externen Entität.
- Auslöser: Die Daten bewegen sich, wenn ein bestimmtes Ereignis eintritt.
- Format: Der Fluss trägt einen bestimmten Datentyp.
- Kontext: Nützlich für die Integrationsschemaerstellung.
📝 Zuordnung von Datenobjekten zu Funktionen
Um Daten effektiv zu strukturieren, muss man Objekte den Funktionen zuordnen, die mit ihnen arbeiten. Diese Zuordnung erstellt eine Matrix des Datenbesitzes. Die folgende Tabelle zeigt, wie verschiedene Datenbestandteile mit Anwendungsfunktionen interagieren.
| Datenelementtyp | Funktionsinteraktion | Beziehungstyp |
|---|---|---|
| Transaktionsprotokoll | Verarbeitungsfunktion | Zugriff |
| Stammdaten | Verwaltungsfunktion | Assoziation |
| Protokolldatei | Überwachungsfunktion | Zugriff |
| Berichtsausgabe | Berichtsfunktion | Informationsfluss |
Dieser strukturierte Ansatz hilft bei der Identifizierung von Datenredundanz. Wenn mehrere Funktionen mit demselben Datenobjekt assoziiert sind, muss überprüft werden, ob sie dieselbe Quelle teilen oder ob eines eine Kopie ist. Diese Überprüfung unterstützt die Datenkonsistenz.
🛠️ Best Practices für das Modellieren
Konsistenz ist entscheidend beim Erstellen dieser Modelle. Die Einhaltung etablierter Konventionen stellt sicher, dass die Architektur über die Zeit hinweg verständlich bleibt. Die folgenden Praktiken sollten in den Modellierungsprozess integriert werden.
- Standardisieren Sie Namenskonventionen: Stellen Sie sicher, dass Datenobjekte klare, eindeutige Namen haben. Vermeiden Sie Abkürzungen, die an anderer Stelle nicht dokumentiert sind.
- Definieren Sie den Umfang eindeutig: Bestimmen Sie, ob ein Datenobjekt logisch oder physisch ist. Die Anwendungsschicht befasst sich typischerweise mit logischen Datenstrukturen.
- Verknüpfen Sie mit der Geschäftslogik-Ebene: Verfolgen Sie Datenobjekte zurück zu Geschäftsobjekten. Dadurch wird sichergestellt, dass der geschäftliche Kontext erhalten bleibt.
- Verwenden Sie Attribute: Definieren Sie Attribute für Datenobjekte, um ihre Struktur zu beschreiben, ohne die Darstellung unnötig zu komplizieren.
- Vermeiden Sie Überlappungen: Modellieren Sie dasselbe Datenobjekt nicht in mehreren Ebenen, es sei denn, es gibt einen spezifischen Grund (z. B. logisch vs. physisch).
⚠️ Häufige Fehler, die vermieden werden sollten
Selbst erfahrene Architekten begehen Fehler beim Modellieren von Daten. Die Erkennung dieser Muster kann erheblichen Umarbeitungsaufwand einsparen. Nachfolgend finden Sie häufige Probleme, die bei der Strukturierung auftreten.
1. Vermischung von Ebenen
Das direkte Platzieren von Geschäftsobjekten in der Anwendungsschicht erzeugt Verwirrung. Geschäftsobjekte gehören zur Geschäftslogik-Ebene. Die Anwendungsschicht sollte Datenobjekte enthalten, die die Umsetzung dieser Geschäftskonzepte darstellen.
- Korrektur: Ordnen Sie das Geschäftsobjekt über eine Realisierungsbeziehung dem Datenobjekt zu.
- Auswirkung: Die Vermischung von Ebenen verschleiert die Grenze zwischen geschäftlichem Ziel und Systemfunktion.
2. Übermodellierung
Das Versuch, jedes einzelne Feld einer Datenbank innerhalb der Anwendungsschicht zu dokumentieren, führt zu Unübersichtlichkeit. Der Zweck dieser Ebene ist es, Fähigkeiten und Flüsse zu zeigen, nicht detaillierte Schemata.
- Korrektur: Verwenden Sie hochwertige Datenobjekte. Gehen Sie erst dann auf physische Modelle zurück, wenn dies für die technische Spezifikation notwendig ist.
- Auswirkung: Hält die Architektur übersichtlich und wartbar.
3. Ignorieren der Persistenz
Datenmodelle müssen die Persistenz berücksichtigen. Einige Daten sind transient (im Speicher), während andere gespeichert werden (Datenbank). Die Nichtunterscheidung dieser Arten kann zu falschen Annahmen über die Systemresilienz führen.
- Korrektur: Beachten Sie den Persistenzmechanismus in den Attributen oder über eine separate Abbildung in der Technologie-Schicht.
- Auswirkung:Klärt Anforderungen an Lebenszyklus und Wiederherstellung von Daten.
🔗 Integration mit anderen Schichten
Die Anwendungsschicht existiert nicht isoliert. Sie ist mit der Geschäfts-Schicht und der Technologie-Schicht verbunden. Eine korrekte Integration sorgt für eine konsistente Architektur.
Verbindung zur Geschäfts-Schicht
Daten in der Anwendungsschicht unterstützen Geschäftsprozesse. EineRealisierungBeziehung verknüpft ein Geschäftsobjekt mit einem Anwendungsdatenobjekt. Dies bestätigt, dass die Anwendung die Geschäftsanforderung unterstützt.
- Ablauf:Geschäftsprozess erstellt Geschäftsobjekt → Anwendungs-Funktion erstellt Anwendungs-Datenobjekt.
- Vorteil:Stellt die Rückverfolgbarkeit von Anforderungen bis zur Umsetzung sicher.
Verbindung zur Technologie-Schicht
Die Anwendungsschicht verlässt sich auf die Technologie-Schicht für Speicherung und Berechnung.BereitstellungBeziehungen ordnen Anwendungskomponenten Technologie-Knoten zu. Datenobjekte in der Anwendungsschicht können als Datenspeicher in der Technologie-Schicht realisiert werden.
- Abbildung:Anwendungs-Datenobjekt → Technologie-Datenspeicher.
- Vorteil:Bestätigt, dass die technische Infrastruktur die logischen Datenanforderungen erfüllt.
📈 Daten-Governance verwalten
Sobald das Modell strukturiert ist, dient es als Referenz für die Governance. Daten-Governance-Richtlinien können auf die Elemente im Modell angewendet werden. Dadurch wird sichergestellt, dass Compliance und Qualitätsstandards erfüllt werden.
- Eigentum:Weisen Sie Datenbesitzer bestimmten Datenobjekten im Modell zu.
- Klassifizierung:Kennzeichnen Sie Datenobjekte basierend auf ihrer Sensibilität (z. B. Öffentlich, Intern, Vertraulich).
- Aufbewahrung:Definieren Sie Aufbewahrungsrichtlinien, die mit den Datenobjekten verknüpft sind.
- Zugriffskontrolle:Weisen Sie Rollen aus der Geschäftsebene Funktionen zu, die auf die Daten zugreifen.
Diese Governance-Ebene schafft einen Mehrwert über die einfache Visualisierung hinaus. Sie verwandelt das Architekturmodell in ein Management-Tool. Regelmäßige Überprüfungen dieser Modelle stellen sicher, dass Governance-Richtlinien mit dem tatsächlichen Systemverhalten übereinstimmen.
🧩 Erweiterte Szenarien
Manchmal reicht die Standardmodellierung nicht aus, um komplexe Szenarien abzubilden. Erweiterte Situationen erfordern eine sorgfältige Berücksichtigung von Beziehungen und Einschränkungen.
1. Komplexe Datenumformungen
Wenn Daten einer umfassenden Umformung unterzogen werden, können mehrere Funktionen beteiligt sein. Eine Funktion könnte rohe Daten lesen und verarbeitete Daten ausgeben.
- Modellierung:Verwenden Sie zwei verschiedene Datenobjekte, um die Eingabe- und Ausgabestatus darzustellen.
- Verknüpfung:Verbinden Sie sie über die Umformungsfunktion.
- Vorteil:Zeigt deutlich den durch die Umformung hinzugefügten Wert an.
2. Gemeinsam genutzte Datenressourcen
Mehrere Anwendungen können dieselbe Datenressource gemeinsam nutzen. Dies kann zu einem potenziellen Engpass oder Sicherheitsrisiko führen.
- Modellierung:Erstellen Sie ein einzelnes Datenobjekt und verknüpfen Sie mehrere Anwendungsfunktionen damit.
- Analyse:Verwenden Sie diese Ansicht, um Konkurrenz und Sperrstrategien zu analysieren.
- Vorteil:Hebt Abhängigkeiten und gemeinsame Risiken hervor.
3. Historische Daten
Anwendungen müssen häufig historische Versionen von Daten speichern. Dazu ist die Modellierung zeitbasierter Attribute erforderlich.
- Modellierung:Fügen Sie dem Datenobjekt Attribute hinzu, um Versionsnummern oder Gültigkeitsdaten zu kennzeichnen.
- Beziehung:Stellen Sie sicher, dass die Funktion die Aktualisierungslogik korrekt handhabt.
- Vorteil:Unterstützt Audit-Protokolle und Compliance-Anforderungen.
🔍 Überprüfung und Validierung
Nach der Strukturierung der Datenmodelle ist eine Überprüfung notwendig. Dieser Prozess stellt sicher, dass das Modell den Zielzustand genau widerspiegelt. Die Überprüfung umfasst die Prüfung auf Vollständigkeit, Konsistenz und Richtigkeit.
- Vollständigkeit:Sind alle kritischen Datenobjekte dargestellt?
- Konsistenz:Sind Namen und Definitionen im gesamten Modell konsistent?
- Richtigkeit:Spiegeln die Beziehungen das Systemverhalten genau wider?
Es wird empfohlen, Fachexperten in dieser Phase einzubinden. Sie können überprüfen, ob die modellierten Abläufe der tatsächlichen betrieblichen Realität entsprechen. Diese Rückkopplungsschleife verbessert die Genauigkeit der Architektur.
🔄 Pflege des Modells
Die Architektur ist keine einmalige Aufgabe. Systeme entwickeln sich weiter, und Datenmodelle müssen sich mit ihnen weiterentwickeln. Die Pflege beinhaltet das Verfolgen von Änderungen und die entsprechende Aktualisierung des Modells.
- Änderungsmanagement:Integrieren Sie Architektur-Updates in den Änderungsantragprozess.
- Versionsverwaltung:Führen Sie eine Historie der Modellversionen, um die Entwicklung zu verfolgen.
- Dokumentation:Aktualisieren Sie die zugehörige Dokumentation, wenn sich Modellkomponenten ändern.
Regelmäßige Synchronisierung zwischen dem Modell und den tatsächlichen Systemen verhindert eine Abweichung. Eine Abweichung tritt auf, wenn das Modell die Realität nicht mehr widerspiegelt und somit für Planungen nutzlos wird.
📉 Messen des Erfolgs
Wie stellen Sie fest, dass die Strukturierungsarbeit erfolgreich war? Mehrere Indikatoren können verwendet werden, um die Wirksamkeit der Datenmodellierung zu messen.
- Geringere Redundanz:Weniger doppelte Datenspeicher identifiziert.
- Verbesserte Klarheit:Interessenten können Datenflüsse leicht verfolgen.
- Schnellere Integration:Neue Systeme können auf Grundlage der definierten Datenverträge integriert werden.
- Bessere Steuerung:Datenrichtlinien werden konsistent angewendet.
Diese Metriken bieten eine quantitative Grundlage für die architektonische Arbeit. Sie zeigen den Wert der strukturierten Datenmodelle für die Organisation auf.
🎯 Zusammenfassung der Schlüsselelemente
Zusammenfassend basiert das Datenmodell der Anwendungsschicht auf bestimmten Elementen und Beziehungen. Ein gelungenes Modell integriert diese Komponenten nahtlos.
- Elemente: Anwendungskomponenten, Funktionen, Dienstleistungen und Datenobjekte.
- Beziehungen: Assoziation, Zugriff, Informationsfluss und Realisierung.
- Ebenen: Geschäftsebene, Anwendungsebene, Technologieebene und Motivation.
- Prozess: Definieren, Abbilden, Validieren und Pflegen.
Durch Einhaltung dieser Prinzipien können Architekten robuste Modelle erstellen, die der Datenstrategie der Organisation entsprechen. Das Ergebnis ist ein klares Bild davon, wie Informationen innerhalb des technischen Umfelds den geschäftlichen Wert antreiben.