











Das C4-Modell ist zum Standard für die Visualisierung von Softwarearchitekturen geworden und bietet eine klare Hierarchie von Kontext über Container, Komponente bis hin zum Code. Doch die zunehmende Verbreitung serverloser Computing-Technologien bringt einzigartige Herausforderungen für dieses statische Modellierungsframework mit sich. Serverlose Funktionen sind flüchtig, ereignisgesteuert und werden oft von Cloud-Anbietern verwaltet, was ihre Darstellung innerhalb eines strukturierten Diagramms nicht trivial macht. Dieser Leitfaden erläutert, wie man serverlose Architekturen genau mit den C4-Prinzipien modelliert, ohne auf spezifische Anbieterwerkzeuge angewiesen zu sein. 📚
Verständnis der Spannungen: C4 gegenüber serverlosen Systemen 🤔
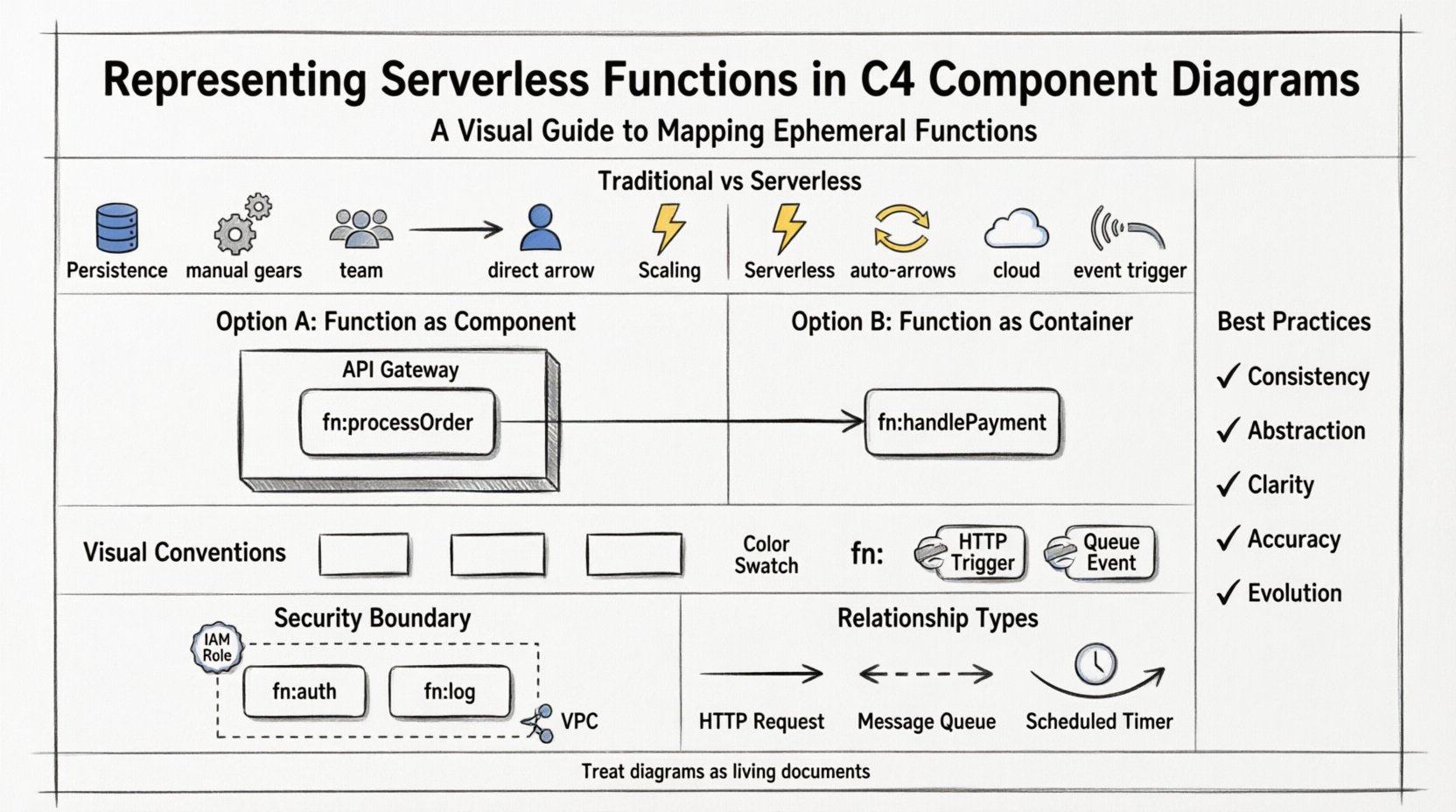
Das C4-Modell wurde mit traditionellen Anwendungsstrukturen im Blick entwickelt. Es geht davon aus, dass Container eine gewisse Persistenz und Zustandsverwaltung aufweisen. Serverlose Funktionen hingegen sind darauf ausgelegt, zustandslos zu sein und nach Bedarf zu skalieren. Wenn man versucht, eine Funktion einer C4-Komponente zuzuordnen, ergeben sich Fragen zu Grenzen, Lebenszyklus und Eigentum. Ohne klare Richtlinien können Diagramme verwirrend oder irreführend werden und den eigentlichen Daten- und Steuerungsfluss verdecken. Wir müssen das Modell anpassen, um die dynamische Natur moderner Cloud-Infrastrukturen widerzuspiegeln. 🌥️
Um diese Lücke zu schließen, müssen wir die grundlegenden Unterschiede verstehen:
- Persistenz:Traditionelle Container speichern oft den Zustand im Speicher. Serverlose Funktionen tun dies nicht. Sie werden nach der Ausführung zerstört.
- Skalierung:Container skalieren über Orchestrierung (wie Kubernetes). Serverlose Systeme skalieren automatisch mit der Anzahl an Ereignissen.
- Eigentum:Container werden oft von der Entwicklerteam verwaltet. Serverlose Laufzeiten werden vom Cloud-Anbieter verwaltet.
- Einstiegspunkte:APIs sind oft der Auslöser für serverlose Systeme, nicht die direkte Interaktion eines Benutzers mit einem persistierenden Prozess.
Zuordnung von serverlosen Systemen zur C4-Hierarchie 🗺️
Wo befinden sich serverlose Funktionen innerhalb der C4-Hierarchie? Die Antwort hängt von der benötigten Granularität für die Zielgruppe ab. Es gibt keine einzige richtige Antwort, aber es gibt bewährte Praktiken, um Klarheit zu bewahren. 🛠️
Option 1: Serverlos als Komponente ⚙️
Dies ist der häufigste Ansatz. Sie behandeln die serverlose Funktion als eine Komponente innerhalb eines Containers. Der Container steht für den logischen Dienst oder die API-Gateway, der den Datenverkehr an die Funktion weiterleitet. Diese Trennung ist entscheidend, da sie den Einstiegspunkt (das Gateway) von der Logikausführung (der Funktion) unterscheidet.
- Container: Das API-Gateway oder der Lastverteiler, das HTTP-Anfragen akzeptiert.
- Komponente: Die spezifische serverlose Funktion, die die Anfrage verarbeitet.
- Vorteil: Trennt die Anliegen von Routing und Geschäftslogik klar voneinander.
Option 2: Serverlos als Container 📦
In einigen Fällen fungiert eine einzelne Funktion als der gesamte Einstiegspunkt für ein Mikroservice. Wenn die Funktion die API-Logik und den Datenzugriff direkt verarbeitet, kann sie als Container modelliert werden. Dies wird oft bei kleineren, selbstständigen Diensten verwendet, bei denen der Aufwand, einen separaten Gateway-Container zu definieren, unnötig wäre.
- Container: Die serverlose Funktion selbst.
- Grenze: Die Funktion führt ihre eigene Eingabebestätigung und Ausgabeformatierung durch.
- Vorteil: Vereinfacht Diagramme für kleine serverlose Anwendungen.
Vergleichstabelle: Platzierungsstrategien 📊
| Strategie | Beste Einsatzmöglichkeit | Komplexität | Klarheit |
|---|---|---|---|
| Funktion als Komponente | Reife Mikrodienste mit eindeutigen Gateways | Mittel | Hoch |
| Funktion als Container | Einfache, einzigartige Funktionen | Niedrig | Mittel |
| Mehrere Funktionen als Komponenten | Komplexe Workflows mit Orchestrierung | Hoch | Hoch |
Visuelle Konventionen für serverlose Systeme 🎨
Konsistenz in der visuellen Darstellung hilft den Stakeholdern, serverlose Elemente schnell zu erkennen. Obwohl das C4-Modell keine spezifischen Symbole vorschreibt, verbessert die Einführung von Konventionen die Lesbarkeit. Verwenden Sie Standardformen für Komponenten, ergänzen Sie jedoch visuelle Hinweise, um serverlose Eigenschaften zu kennzeichnen.
Symbolik und Gestaltung
- Form:Verwenden Sie das Standardrechteck für Komponenten (abgerundet oder quadratisch).
- Farbcodierung: Weisen Sie allen serverlosen Komponenten eine spezifische Farbe (z. B. heller Grauton oder ein bestimmter Akzent) zu, um sie von dauerhaften Containern zu unterscheiden.
- Beschriftungen: Funktionennamen mit einem Präfix versehen
fn:oderfunc:um ihre ephemere Natur anzudeuten. - Anmerkungen: Fügen Sie Text hinzu, der die Laufzeitumgebung oder den Trigger-Typ angibt (z. B. „HTTP-Trigger“, „Warteschlangenereignis“).
Anzeige der ephemeren Natur
Da serverlose Funktionen nach der Ausführung zerstört werden, können Sie gestrichelte Linien oder spezifische Randstile verwenden, um dies zu veranschaulichen. Allerdings werden standardmäßig durchgezogene Linien oft bevorzugt, um die logischen Abhängigkeiten klar darzustellen. Entscheidend ist es, den Lebenszyklus in den Diagrammnotizen zu dokumentieren, anstatt sich ausschließlich auf Linienstile zu verlassen.
Modellierung von Beziehungen und Abhängigkeiten 🔗
Das Verständnis der Wechselwirkungen zwischen serverlosen Funktionen und anderen Teilen des Systems ist entscheidend. Die Beziehungen in C4-Diagrammen stellen Datenfluss und Abhängigkeiten dar, nicht nur die Netzwerkkonnektivität.
Trigger-Beziehungen
Serverlose Funktionen sind typischerweise ereignisgesteuert. Sie müssen die Quelle dieser Ereignisse eindeutig darstellen.
- HTTP-Anfragen: Verbinden Sie einen API-Gateway-Container mit der Funktionskomponente über eine „Anfrage“-Beziehung.
- Nachrichtenwarteschlangen: Wenn eine Funktion Nachrichten aus einer Warteschlange verarbeitet, zeichnen Sie eine Beziehung vom Warteschlangen-Container zur Funktionskomponente.
- Timer: Bei geplanten Aufgaben geben Sie eine „Planung“-Beziehung von einem Planungs-Container an.
Überlegungen zum Datenfluss
Serverlose Funktionen verarbeiten Daten oft ohne langfristige Speicherung. Stellen Sie sicher, dass Ihr Diagramm diese zustandslose Natur widerspiegelt.
- Temporärer Zustand: Wenn Daten während der Ausführung im Speicher gehalten werden, modellieren Sie sie nicht als Datenbankkomponente.
- Persistente Speicherung: Verbinden Sie die Funktion explizit mit externen Speicherdiensten (z. B. Objektspeicher oder Datenbanken). Nehmen Sie nicht an, dass die Funktion die Daten besitzt.
- Ausgabe: Zeigen Sie deutlich, wohin das Ergebnis der Funktion geht (z. B. eine Antwort an einen Client oder eine Nachricht an eine andere Warteschlange).
Sicherheit und Grenzen 🔒
Sicherheit wird oft in hochgradigen Architekturdiagrammen übersehen, ist aber für serverlose Systeme entscheidend. Identitäts- und Zugriffsmanagement (IAM) spielt hier eine größere Rolle als bei traditionellen containerisierten Anwendungen.
Definition von Sicherheitsgrenzen
Jede serverless-Funktion sollte eine definierte Sicherheitsgrenze haben. In Ihrer Diagramm gruppieren Sie Funktionen, die die gleichen IAM-Rollen oder Netzwerkrichtlinien teilen. Dies hilft bei der Überprüfung und der Verständnis der Berechtigungsverbreitung.
- Gruppierung:Verwenden Sie eine „Systemkontext“- oder „Container“-Grenze, um Funktionen nach Sicherheitsdomäne zu gruppieren.
- Berechtigungen:Beschreiben Sie Komponenten mit dem erforderlichen Zugriffslevel (z. B. „Nur-Lesen“, „Admin-Zugriff“).
- Netzwerk:Geben Sie an, ob eine Funktion innerhalb eines virtuellen privaten Cloud-Netzwerks (VPC) oder öffentlich zugänglich läuft.
Authentifizierung und Autorisierung
Zeichnen Sie den Fluss von Authentifizierungstoken auf. Validiert die Funktion den Token selbst oder verlässt sie sich auf die API-Gateway? Diese Unterscheidung beeinflusst, wo die Sicherheitslogik in Ihrer Architektur implementiert ist.
Häufige Fallen und Herausforderungen ⚠️
Die Modellierung serverloser Architekturen bringt spezifische Herausforderungen mit sich, die zu ungenauen Diagrammen führen können, wenn sie nicht angegangen werden.
Übermäßige Modellierung von Details
Es ist leicht, sich in den Details jeder Funktion zu verlieren. Wenn Sie Hunderte kleiner Funktionen haben, modellieren Sie nicht jede einzeln in einem Komponentendiagramm. Fassen Sie sie stattdessen in logische Gruppen oder höherstufige Komponenten zusammen.
- Faustregel:Wenn eine Komponente zu klein ist, um ein eigenständiges Verhalten zu haben, kombinieren Sie sie mit ihrem übergeordneten Element.
- Abstraktion:Verwenden Sie eine „Dienst“-Komponente, um eine Gruppe verwandter Funktionen darzustellen.
Ignorieren von Cold Starts
Obwohl es kein rein visuelles Element ist, beeinflusst der Begriff „Cold Starts“ (Verzögerung beim Initialisieren einer Funktion) die Architektur. Sie könnten Komponenten markieren, bei denen die Latenz kritisch ist. Dies beeinflusst Entscheidungen bezüglich vorab bereitgestellter Konkurrenz oder Caching-Ebenen.
Annahme synchroner Ausführung
Viele serverless-Funktionen sind asynchron. Modellieren Sie sie nicht so, als würden sie immer eine direkte HTTP-Antwort zurückgeben. Verwenden Sie unterschiedliche Beziehungstypen (z. B. „Fire and Forget“ oder „Ereignis“), um asynchrone Abläufe zu kennzeichnen.
Dokumentation und Wartung 📝
Ein C4-Diagramm ist nur so gut wie seine Genauigkeit im Laufe der Zeit. Serverlose Architekturen ändern sich häufig. Um die Diagramme aufzubewahren:
- Versionskontrolle:Speichern Sie Ihre Diagramme zusammen mit Ihrem Infrastrukturcode.
- Automatisierung:Verwenden Sie Werkzeuge, die Diagramme aus Code-Definitionen generieren können, wo immer möglich.
- Überprüfungszyklen:Aktualisieren Sie die Diagramme während der Sprint-Retrospektiven oder architektonischen Überprüfungen.
- Tags: Verwenden Sie Tags im Diagramm, um das Datum der letzten Überarbeitung anzugeben.
Erweiterte Szenarien: Orchestrierung und Zustand 🔄
Komplexe serverlose Anwendungen beinhalten oft eine Orchestrierung. Sie könnten einen Workflows-Engine verwenden, um eine Reihe von Funktionen zu verwalten. Wie passt das in das C4-Modell?
Workflows-Engines
Modellieren Sie die Workflows-Engine als Container. Die einzelnen Schritte innerhalb des Workflows sind Komponenten. Dadurch wird die Steuerungslogik (der Workflow) von der Ausführungslogik (den Funktionen) getrennt.
- Container: Workflows-Orchestrator.
- Komponente: Schritt-Funktion A, Schritt-Funktion B.
- Beziehung: „Auslöst“ oder „Koordiniert“.
Zustandsverwaltung
Wenn Ihre serverlose Anwendung einen Zustand erfordert, muss dieser extern sein. Zeigen Sie nicht an, dass ein Zustand innerhalb der Funktion existiert. Verbinden Sie die Funktion explizit mit einer Datenbank- oder Cache-Komponente. Dadurch wird das zustandslose Muster im visuellen Modell verstärkt.
Zusammenfassung der Best Practices ✅
Um sicherzustellen, dass Ihre C4-Diagramme für serverlose Architekturen wirksam bleiben, halten Sie sich an diese zentralen Prinzipien:
- Konsistenz:Verwenden Sie denselben visuellen Stil für alle serverlosen Komponenten.
- Abstraktion:Modellieren Sie nicht jede einzelne Funktion, wenn dies nur Lärm erzeugt.
- Klarheit:Unterscheiden Sie deutlich zwischen Auslösern, Logik und Speicher.
- Genauigkeit:Berücksichtigen Sie die tatsächlichen Bereitstellungsgrenzen und Berechtigungen.
- Entwicklung:Behandeln Sie Diagramme als lebendige Dokumente, die sich mit dem Code entwickeln.
Abschließende Gedanken zur Architekturdarstellung 🌟
Die Darstellung serverloser Funktionen im C4-Modell erfordert eine Veränderung des Denkens. Sie zeichnen nicht einfach nur Kästchen; Sie übertragen dynamisches Verhalten in statische Darstellungen. Durch die Einhaltung dieser Richtlinien erstellen Sie Diagramme, die als effektive Kommunikationsmittel für Entwickler, Architekten und Stakeholder dienen. Das Ziel ist nicht nur, das Vorhandensein zu dokumentieren, sondern auch zu klären, wie das System unter Last, bei Ausfällen und in verschiedenen Umgebungen reagiert. Ein gut gezeichnetes C4-Diagramm für serverlose Architekturen reduziert Unklarheiten und beschleunigt die Entscheidungsfindung. 🚀
Denken Sie daran, dass der Wert des Diagramms in dem Verständnis liegt, das es vermittelt, nicht in der Komplexität der Darstellung. Halten Sie es einfach, genau und aktuell. Dieser Ansatz stellt sicher, dass Ihre Architektur verständlich bleibt, während sich die technologische Landschaft weiterentwickelt. 🛠️