











In der modernen Softwareentwicklung existieren Systeme selten als monolithische Einheiten. Sie bestehen aus mehreren Diensten, Prozessen und Speichereinheiten, die über Netzwerkgrenzen hinweg interagieren. Das Verständnis dafür, wie Informationen zwischen diesen unterschiedlichen Einheiten fließen, ist entscheidend für die Aufrechterhaltung der Systemintegrität, die Diagnose von Fehlern und die Planung der Skalierbarkeit. Dieser Leitfaden untersucht den Prozess der Kartierung und Visualisierung des Datenflusses innerhalb verteilter Architekturen, wobei speziell das C4-Modell als strukturelles Framework genutzt wird.
Ohne klare Dokumentation werden verteilte Systeme schnell zu schwarzen Kisten. Ingenieure haben Mühe, Anfragen zurückzuverfolgen, Engpässe zu identifizieren oder die Auswirkungen von Änderungen zu verstehen. Die Visualisierung der Datenbewegung schafft Klarheit. Sie wandelt abstrakte Logik in konkrete Diagramme um, die Stakeholder interpretieren können. Dieses Dokument skizziert die Methoden zur Definition von Grenzen, zur Kartierung von Verbindungen und zur Pflege dieser Diagramme über die Zeit.
1. Die Architekturlandschaft 🌍
Verteilte Systeme bringen eine Komplexität mit sich, die monolithische Anwendungen nicht haben. Wenn ein einzelner Prozess alle Logik verarbeitet, ist der Datenfluss intern und linear. Wenn mehrere Container oder Dienste beteiligt sind, durchquert der Datenverkehr Netzwerke, passiert Firewalls und überschreitet Vertrauensgrenzen. Jeder Sprung bringt Latenz und potenzielle Ausfallpunkte mit sich.
Die Visualisierung dieser Landschaft erfordert einen standardisierten Ansatz. Ad-hoc-Diagramme führen oft zu Inkonsistenzen. Ein Ingenieur könnte eine Datenbank als Zylinder zeichnen, während ein anderer ein Rechteck verwendet. Die Standardisierung stellt sicher, dass das Diagramm beim Betrachten sofort verständlich ist. Das C4-Modell bietet diese Standardisierung durch die Definition spezifischer Abstraktionsstufen.
Wichtige Herausforderungen bei der Visualisierung verteilter Systeme sind:
- Netzwerklatenz:Visualisierung, wo Daten in Warteschlangen oder Netzwerken warten.
- Datenkonsistenz:Anzeigen, wie der Zustand über Knoten hinweg synchronisiert wird.
- Ausfallbereiche:Identifizieren, was geschieht, wenn ein Container nicht mehr antwortet.
- Sicherheitsgrenzen:Markieren, wo Datenverschlüsselung oder Authentifizierung erforderlich ist.
2. Das C4-Modell erklärt 📐
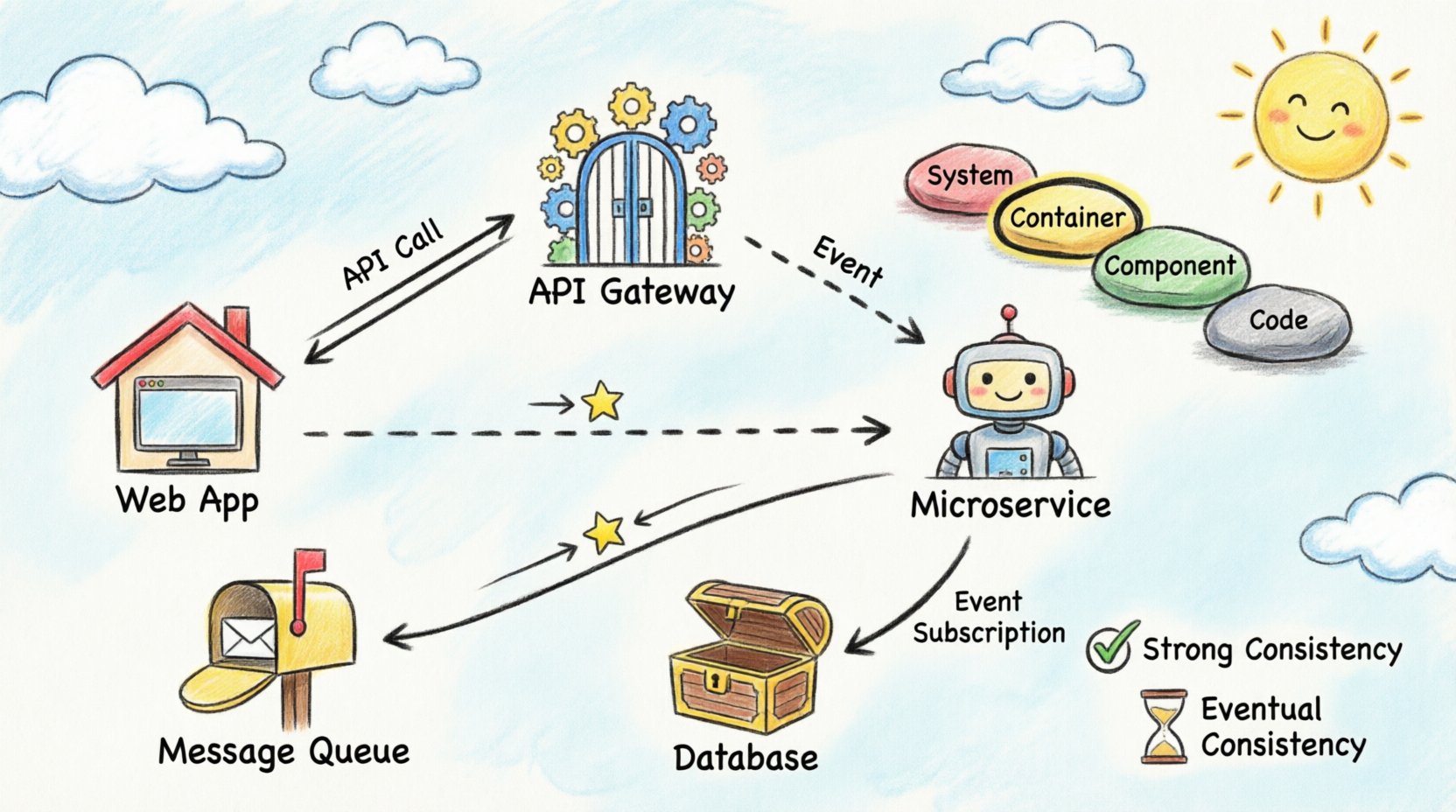
Das C4-Modell ist eine Hierarchie von Diagrammen, die zur Beschreibung von Softwarearchitekturen verwendet wird. Es besteht aus vier Ebenen, die jeweils einer unterschiedlichen Zielgruppe und einem anderen Zweck dienen. Für die Visualisierung des Datenflusses über Container sind die Ebenen Container und Komponente am relevantesten.
Ebene 1: Systemkontext
Diese Übersichtsebene zeigt das System als ein einzelnes Block und seine Interaktionen mit externen Benutzern und Systemen. Sie beantwortet die Frage: „Was macht dieses System, und wer nutzt es?“ Obwohl sie für den Kontext nützlich ist, zeigt sie keinen internen Datenfluss zwischen Containern.
Ebene 2: Container
Dies ist das Herzstück der Visualisierung verteilter Systeme. Ein Container stellt eine eindeutige Bereitstellungseinheit dar. Beispiele hierfür sind Webanwendungen, Mobile Apps, Microservices und Datenbanken. Diese Ebene zeigt, wie Daten zwischen diesen Einheiten fließen. Es ist der ideale Ort, um API-Aufrufe, Nachrichtenwarteschlangen und direkte Datenbankverbindungen abzubilden.
Ebene 3: Komponenten
Innerhalb eines Containers stellen Komponenten unterschiedliche Teile der Software dar. Diese Ebene geht tiefer in die Logik ein und zeigt interne Klasseninteraktionen oder Modulabhängigkeiten. Obwohl sie wichtig sind, sind sie oft zu detailliert für die Analyse des Datenflusses auf hoher Ebene.
Ebene 4: Code
Diese Ebene entspricht spezifischen Klassen und Methoden. Sie ist im Allgemeinen für die Dokumentation architektonischer Flüsse unnötig und besser für Entwickler-spezifische Referenzmaterialien geeignet.
3. Identifizieren von Container-Grenzen 🚧
Bevor Sie Datenflusslinien zeichnen, müssen Sie definieren, was einen Container ausmacht. Ein Container ist eine bereitstellbare Einheit. Er hat einen Lebenszyklus, der unabhängig von anderen Containern ist. Er kann auf dem gleichen physischen Server laufen oder über verschiedene Regionen verteilt sein.
Häufige Container-Typen umfassen:
- Webanwendungen:Frontend-Oberflächen, die über Browser erreicht werden.
- Mikrodienste:Backend-Dienste, die spezifische Geschäftslogik verarbeiten.
- API-Gateways:Eingangspunkte, die den Datenverkehr zu internen Diensten weiterleiten.
- Datenbanken:Datenbanken, Caches oder Dateisysteme.
- Batch-Prozesse:Geplante Aufgaben, die Daten asynchron verarbeiten.
Bei der Definition von Grenzen sollten Sie die Bereitstellungsstrategie berücksichtigen. Wenn zwei Dienste immer gemeinsam bereitgestellt werden und Speicher teilen, könnten sie Teil eines einzelnen Containers sein. Wenn sie unabhängig skaliert werden können, sollten sie separate Container sein. Diese Entscheidung beeinflusst, wie der Datenfluss visualisiert wird.
4. Abbildung von Datenflussmustern 📡
Der Datenfluss ist nicht einfach eine Linie, die zwei Felder verbindet. Er stellt ein bestimmtes Interaktionsmuster dar. Das Verständnis des Musters ist entscheidend für eine genaue Visualisierung. Die folgende Tabelle beschreibt gängige Muster und deren Darstellung.
| Muster | Richtung | Sichtbarkeit | Anwendungsfall |
|---|---|---|---|
| Synchroner Anfrage/Antwort-Vorgang | Zweirichtung (Client → Server → Client) | Sofort | API-Aufrufe, Formularübermittlungen |
| Asynchroner Fire-and-Forget-Vorgang | Einfachrichtung (Client → Server) | Verzögert | Protokollierung, Analyseereignisse |
| Pull-basierte Verarbeitung | Einfachrichtung (Worker ← Warteschlange) | Auf Abruf | Hintergrundaufgaben, Daten-Eingabe |
| Ereignisabonnement | Einfachrichtung (Veröffentlicher → Abonnent) | Ereignisgetriggert | Benachrichtigungen, Zustandsänderungen |
Synchrones Kommunikation
Bei synchronen Abläufen wartet der Absender auf eine Antwort. Dies ist bei API-Interaktionen üblich. Zeichnen Sie dies mit durchgehenden Linien und Pfeilspitzen, die Anfrage und Antwort anzeigen. Kennzeichnen Sie das verwendete Protokoll, beispielsweise HTTP oder gRPC. Dies hilft Ingenieuren, die blockierende Natur der Interaktion zu verstehen.
Asynchrone Kommunikation
Asynchrone Abläufe entkoppeln den Absender vom Empfänger. Der Absender stellt eine Nachricht in eine Warteschlange und fährt fort. Der Empfänger verarbeitet die Nachricht später. Visualisieren Sie dies mit gestrichelten Linien oder markanten Symbolen, die den Nachrichtenbroker darstellen. Es ist entscheidend, den Warteschlangennamen anzugeben, um verschiedene Datenströme voneinander zu unterscheiden.
5. Behandlung von Synchronisation und Konsistenz ⚖️
Ein der schwierigsten Aspekte des verteilten Datenflusses ist die Zustandsverwaltung. Wenn Daten in einen Container geschrieben werden, spiegeln sie sich sofort in einem anderen wider? Die Visualisierung muss diese Konsistenzanforderungen erfassen.
Starke Konsistenz
Einige Systeme erfordern, dass alle Knoten zur gleichen Zeit dieselben Daten sehen. Dies impliziert oft eine einzige Quelle der Wahrheit oder eine synchrone Replikation. Kennzeichnen Sie diese Verbindungen in Diagrammen mit Beschriftungen wie „Starke Konsistenz“ oder „ACID“. Dies warnt die Stakeholder, dass Ausfälle in einem Teil des Systems andere beeinflussen können.
Eventuelle Konsistenz
Viele verteilte Systeme setzen die Verfügbarkeit der sofortigen Konsistenz voran. Die Daten können Sekunden oder Minuten zur Verbreitung benötigen. Visualisieren Sie dies durch Hinzufügen eines Zeitindikators oder einer „Sync“-Beschriftung mit einer Verzögerungsangabe. Dies hilft, die Erwartungen hinsichtlich des Zeitpunkts zu steuern, zu dem Benutzer aktualisierte Informationen sehen.
Zustandslose vs. Zustandsbehaftete Container
Zustandslose Container speichern keine Daten lokal. Sie verlassen sich auf externe Datenbanken oder Caches. Zustandsbehaftete Container speichern Daten innerhalb ihres eigenen Speichers. Stellen Sie beim Abbildung des Flusses sicher, dass externer Speicher klar von den Containern getrennt ist. Wenn ein Container Daten speichert, sollte die Flusslinie auf ein Speichersymbol innerhalb oder an dem Container angebracht sein.
6. Dokumentationspflege 📝
Ein Diagramm ist nur dann nützlich, wenn es genau ist. Im Laufe der Zeit ändern sich der Code, es werden neue Dienste hinzugefügt und veraltete Dienste entfernt. Statische Diagramme werden schnell veraltet. Es ist eine Strategie zur Pflege erforderlich.
Best Practices zur Aktualisierung der Dokumentation umfassen:
- Automatisierte Generierung:Sofern möglich, generieren Sie Diagramme aus Code-Anmerkungen oder Konfigurationsdateien. Dies reduziert den manuellen Aufwand und verhindert Abweichungen zwischen Code und Dokumentation.
- Überprüfungszyklen:Schließen Sie Diagrammaktualisierungen in die Definition des „Fertiggestellt“ für Pull Requests ein. Wenn sich die Schnittstelle eines Dienstes ändert, muss auch das Diagramm geändert werden.
- Versionsverwaltung:Behandeln Sie Architekturdiagramme wie Code. Speichern Sie sie in Versionskontrollsystemen, um die Historie zu verfolgen und bei fehlerhaften Änderungen eine Rückgängigmachung zu ermöglichen.
- Standardisierung der Werkzeuge:Verwenden Sie einen konsistenten Werkzeug-Stack. Vermeiden Sie den Wechsel zwischen verschiedenen Diagramm-Plattformen für verschiedene Teams.
7. Häufige Fehler, die vermieden werden sollten 🛑
Selbst mit einem strukturierten Ansatz können Fehler während des Visualisierungsprozesses auftreten. Die Kenntnis häufiger Fehler hilft, eine hochwertige Dokumentation aufrechtzuerhalten.
Überabstraktion
Es ist verführerisch, Diagramme zu sehr zu vereinfachen. Wenn Sie zehn Dienste in einer einzigen Box mit der Bezeichnung „Backend“ zusammenfassen, verlieren Sie die Fähigkeit, spezifische Datenpfade nachzuverfolgen. Bewahren Sie die Granularität auf Container-Ebene bei. Fügen Sie keine unterschiedlichen Bereitstellungseinheiten zusammen, es sei denn, sie teilen exakt dasselbe Lebenszyklusverhalten.
Ignorieren von Fehlerpfaden
Die meisten Diagramme zeigen den glücklichen Pfad, bei dem alles funktioniert. Eine robuste Visualisierung zeigt auch Fehlerzustände an. Wohin geht der Fluss, wenn ein Dienst abläuft? Gibt es einen Fallback-Dienst? Gibt es eine Dead-Letter-Warteschlange? Das Hinzufügen dieser Pfade macht das Diagramm zu einem Werkzeug für die Resilienzplanung.
Inkonsistente Benennung
Verwenden Sie die gleiche Terminologie für Dienste in der Diagramm wie im Codebase. Wenn ein Dienst im Code „Order-Service“ genannt wird, benennen Sie ihn im Diagramm nicht als „Orders API“. Dies erzeugt Verwirrung während Debugging-Sitzungen.
Fehlende Datentypen
Eine Linie zwischen zwei Containern sagt Ihnen *dass* Daten bewegt werden, aber nicht *welche* Daten bewegt werden. Es ist hilfreich, die Linien mit dem Datentyp des Datenpakets zu kennzeichnen. Zum Beispiel „JSON-Payload“, „Binärbild“ oder „CSV-Batch“. Dies informiert Ingenieure über die Komplexität der Verarbeitung, die am Empfänger erforderlich ist.
8. Best Practices für Wartung und Wachstum 📈
Je größer das System wird, desto eher wird das Diagramm unübersichtlich. Die Verwaltung der Komplexität ist eine fortlaufende Aufgabe. Hier sind Strategien, um die Visualisierung übersichtlich und nützlich zu halten.
- Schichtung:Verwenden Sie verschiedene Schichten für unterschiedliche Aspekte. Eine Schicht für Sicherheit, eine andere für Datenfluss und eine dritte für die Bereitstellungstopologie. Vermeiden Sie es, all diese auf einer einzigen Seite darzustellen.
- Verknüpfungen zu Details:Wenn ein Container komplex ist, erstellen Sie dafür ein separates Unterdigramm. Verknüpfen Sie das Hauptdiagramm mit der detaillierten Ansicht, anstatt jedes Komponente auf der Übersichtsseite darzustellen.
- Farbcodierung:Verwenden Sie Farben, um Status oder Kritikalität anzugeben. Rot für kritische Pfade, blau für Standardflüsse und grau für veraltete Verbindungen. Dadurch kann die Systemgesundheit schnell visuell überprüft werden.
- Metadaten:Fügen Sie die Version des Diagramms und das Datum der letzten Überprüfung in den Fußbereich des Dokuments ein. Dadurch erhalten Sie Kontext darüber, wie aktuell die Informationen sind.
9. Integration mit Observability 🔍
Statische Diagramme sind statisch. Reale Systeme sind dynamisch. Moderne Architekturen integrieren Diagramme mit Observability-Plattformen. Das bedeutet, dass das Diagramm nicht nur ein Bild ist, sondern eine Live-Schnittstelle.
Beim Visualisieren des Datenflusses sollten Sie berücksichtigen, wie das Diagramm mit Überwachungsdaten zusammenhängt. Wenn Sie in der Überwachungssoftware hohe Latenz auf einer bestimmten Verbindung sehen, sollte das Diagramm diese Verbindung deutlich anzeigen. Diese Verknüpfung hilft bei der Ursachenanalyse. Ingenieure können auf eine Linie im Diagramm klicken und die aktuellen Metriken für diese Verbindung sehen.
Diese Integration erfordert, dass das Diagrammformat das Einbetten oder Verknüpfen mit externen Datenquellen unterstützt. Stellen Sie sicher, dass die gewählte Diagramm-Methode diese Flexibilität ermöglicht, ohne dass manuell bei jeder Änderung einer Metrik aktualisiert werden muss.
10. Zusammenfassung der wichtigsten Erkenntnisse ✅
Die Visualisierung des Datenflusses in verteilten Systemen ist eine Disziplin, die technische Genauigkeit mit Lesbarkeit abwägt. Durch die Einhaltung des C4-Modells können Teams eine konsistente Sprache für die Architektur entwickeln. Die Container-Ebene bietet die notwendige Detailgenauigkeit, um Dienstinteraktionen zu verstehen, ohne die Komplexität zu überfordern.
Wichtige Punkte, die Sie sich merken sollten:
- Grenzen klar definieren:Stellen Sie sicher, dass Container mit Bereitstellungseinheiten übereinstimmen.
- Muster explizit abbilden:Unterscheiden Sie zwischen synchronen und asynchronen Flüssen.
- Konsistenzmodelle dokumentieren:Geben Sie an, wie der Zustand über Grenzen hinweg verwaltet wird.
- Strenge Pflege:Behandeln Sie Diagramme als lebendige Dokumente, die sich mit dem Code entwickeln.
- Vermeiden Sie Hype: Konzentrieren Sie sich auf Klarheit und Genauigkeit statt darauf, die Architektur zu verkaufen.
Durch die Einhaltung dieser Prinzipien können Ingenieurteams die kognitive Belastung reduzieren, die Einarbeitung neuer Mitglieder beschleunigen und die Gesamtreliabilität ihrer verteilten Infrastruktur verbessern. Das Ziel besteht nicht darin, lediglich Linien zu ziehen, sondern ein gemeinsames Verständnis dafür aufzubauen, wie das System funktioniert.