











In der Landschaft der Systemanalyse und Softwaretechnik ist die Visualisierung der Informationsbewegung von entscheidender Bedeutung. Ein Datenumflussdiagramm, kurz DFD genannt, dient als grafische Darstellung des Datenflusses durch ein Informationssystem. Im Gegensatz zu Flussdiagrammen, die die Steuerungsflüsse abbilden, konzentriert sich ein DFD ausschließlich auf Daten-Eingaben, -Ausgaben und -Speicherung. Diese Unterscheidung ist für Architekten und Analysten entscheidend, die verstehen müssen, welche Daten ein System verarbeitet, ohne sich in die prozedurale Logik der Datenverarbeitung einzulassen.
Entwickelt in den 1970er Jahren bleibt das DFD eine zentrale Methode der Anforderungsingenieurwesen. Es bietet einen Überblick auf hoher Ebene über ein System und ermöglicht es den Stakeholdern, sicherzustellen, dass alle notwendigen Daten-Eingaben erfasst und alle erforderlichen Daten-Ausgaben generiert werden. Durch die Aufteilung komplexer Systeme in handhabbare Komponenten erleichtern DFDs die Kommunikation zwischen technischen Teams und Geschäftsanwendern. Dieser Leitfaden beschreibt die strukturellen Elemente, Notationsvarianten und methodischen Regeln, die zur Erstellung genauer Diagramme erforderlich sind.
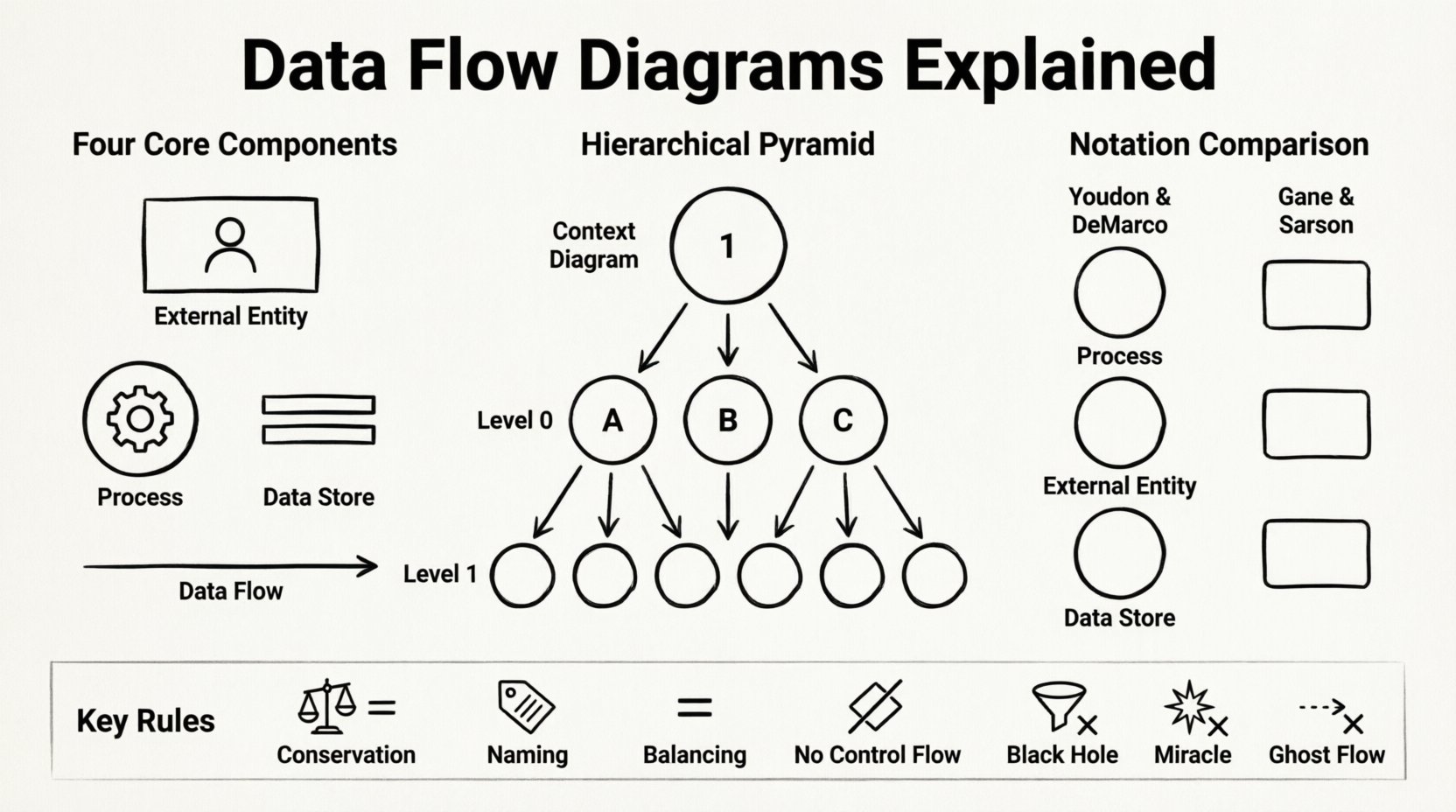
Kernkomponenten eines Datenumflussdiagramms 🔍
Um ein gültiges DFD zu erstellen, muss man die vier grundlegenden Bausteine verstehen. Jedes Diagramm, unabhängig von seiner Komplexität, beruht auf diesen Elementen, um die Grenzen des Systems und dessen interne Abläufe darzustellen. Die falsche Identifizierung dieser Komponenten kann zu Modellen führen, die mehrdeutig oder logisch inkonsistent sind.
- Externe Entitäten: Auch als Terminatoren oder Quellen bekannt, stellen sie Personen, Organisationen oder externe Systeme dar, die mit dem zu modellierenden System interagieren. Sie sind die Ausgangs- oder Endpunkte der Datenflüsse. Eine Entität existiert außerhalb der Systemgrenze und sendet Daten in das System oder empfängt Daten daraus. Zum Beispiel ein Kunde, der eine Bestellung aufgibt, oder eine staatliche Steuerbehörde, die Berichte erhält.
- Prozesse: Dies sind die Aktionen oder Transformationen, die innerhalb des Systems stattfinden. Ein Prozess nimmt Daten von einer oder mehreren Quellen entgegen, verändert sie und sendet sie an andere Ziele. Es ist entscheidend zu beachten, dass ein Prozess keine Daten speichert; er transformiert sie lediglich. Prozesse werden typischerweise mit einer Verbenform bezeichnet, wie zum Beispiel „Steuern berechnen“ oder „Benutzerberechtigungen überprüfen“.
- Datenbanken: Diese stellen Speicherorte dar, an denen Daten für spätere Verwendung aufbewahrt werden. Im Gegensatz zu Prozessen führen Datenbanken keine Berechnungen durch. Sie sind passive Container. Im physischen Kontext könnten dies Datenbanktabellen, Dateien oder physische Aktenordner sein. Im logischen Kontext deuten sie lediglich an, wo Informationen gespeichert werden. Datenflüsse müssen in Datenbanken eintreten und sie verlassen, um Aktualisierungen oder Abrufe anzuzeigen.
- Datenflüsse: Dies sind die Pfeile, die die Komponenten verbinden. Sie repräsentieren die Bewegung von Daten. Ein Datenfluss muss einen Namen haben, der den Inhalt des Datenpakets beschreibt, wie zum Beispiel „Bestelldetails“ oder „Zahlungsbestätigung“. Jeder Datenfluss muss zwei Komponenten verbinden; er kann weder in der Luft beginnen noch enden.
Arten von Datenumflussdiagrammen 🗺️
DFDs sind hierarchisch aufgebaut. Ein komplexes System kann nicht in einer einzigen Ansicht verstanden werden. Daher ist es üblich, das System in mehrere Abstraktionsstufen zu zerlegen. Dieser Ansatz ermöglicht es Analysten, sich auf bestimmte Bereiche zu konzentrieren, ohne den Gesamtzusammenhang aus dem Auge zu verlieren.
1. Kontextdiagramm (Ebene 0)
Dies ist die höchste Abstraktionsstufe. Es zeigt das gesamte System als eine einzige Prozessblase. Es zeigt die Beziehung zwischen dem System und den externen Entitäten. Zu diesem Zeitpunkt sind keine internen Prozesse oder Datenbanken sichtbar. Der Zweck besteht darin, die Systemgrenze klar zu definieren. Es beantwortet die Frage: „Was tut dieses System für die Außenwelt?“
2. Ebene-0-Diagramm (Diagramm 0)
Auch als konzeptionelles Modell bekannt, zerlegt dieses Diagramm den einzelnen Prozess aus dem Kontextdiagramm in wesentliche Unterverarbeitungen. Es bietet eine Übersicht über die Hauptfunktionen des Systems. Es zeigt, wie die wichtigsten Datenflüsse die primären Prozesse mit den Datenbanken und externen Entitäten verbinden. Es ist oft der erste Schritt bei der detaillierten Gestaltung.
3. Ebene 1 und Zerlegung
Je tiefer die Analyse wird, desto weiter werden die Prozesse der Ebene 0 in Diagramme der Ebene 1 zerlegt. Dies geschieht, bis die Prozesse einfach genug sind, um direkt implementiert zu werden. Jedes Kind-Diagramm muss mit seinem Eltern-Diagramm abgestimmt sein. Das bedeutet, dass die Eingaben und Ausgaben eines Prozesses im Eltern-Diagramm mit den Eingaben und Ausgaben des Kind-Diagramms übereinstimmen müssen, das den zerlegten Prozess enthält.
Vergleich der Notationsstandards 📐
Es gibt keinen einzigen universellen Standard für die Erstellung von DFDs. Zwei Hauptrichtungen prägen die Branche. Beide vermitteln die gleiche logische Information, verwenden jedoch unterschiedliche Formen zur Darstellung der Komponenten. Die Auswahl eines Standards und die strikte Einhaltung desselben sind entscheidend für die Konsistenz innerhalb eines Projekts.
| Komponente | Yourdon & DeMarco-Notation | Gane & Sarson-Notation |
|---|---|---|
| Prozess | Kreis oder abgerundetes Rechteck | Abgerundetes Rechteck |
| Datenbank | Zwei parallele horizontale Linien | Offener Rechteck |
| Externe Entität | Rechteck | Rechteck |
| Datenfluss | Gekrümmter oder gerader Pfeil | Gerader Pfeil |
| Anmerkung | Text neben dem Fluss | Text neben dem Fluss |
Während die Formen variieren, bleiben die Regeln für die Verbindungen identisch. Der Yourdon & DeMarco-Stil wird oft in älteren Legacy-Dokumentationen bevorzugt, während der Gane & Sarson-Stil aufgrund seiner saubereren rechteckigen Ästhetik häufig in modernen Systemen verwendet wird.
Der logische vs. physische Unterschied 🔄
Ein entscheidender Begriff im DFD-Modellieren ist die Trennung zwischen logischem und physischem Design. Diese Unterscheidung stellt sicher, dass das Modell auch dann gültig bleibt, wenn sich die zugrundeliegende Technologie ändert.
- Logisches DFD: Konzentriert sich auf die geschäftlichen Anforderungen. Beschreibt, was das System tut, nicht, wie es es tut. In einem logischen Diagramm könnte eine „Datenbank“ generisch als Datenspeicher dargestellt werden, ohne anzugeben, ob es sich um SQL, NoSQL oder eine einfache Textdatei handelt. Ein „Prozess“ könnte „Darlehen genehmigen“ sein, unabhängig davon, ob die Genehmigung von einem Menschen, einem Skript oder einem KI-Algorithmus erfolgt.
- Physisches DFD: Konzentriert sich auf die Implementierungsdetails. Beschreibt, wie das System aufgebaut ist. Hier könnte der Datenspeicher beispielsweise als „Oracle-Tabellen auf Server A“ angegeben werden. Der Prozess könnte „Java-Servlet verarbeitet Anfrage“ lauten. Physische Diagramme werden von Entwicklern während der Codierungsphase verwendet.
Die Mischung dieser Ebenen in einem einzigen Diagramm führt zu Verwirrung. Es ist Best Practice, eine logische Sicht für die Überprüfung durch Stakeholder und eine physische Sicht für die technische Implementierung aufrechtzuerhalten.
Regeln für die Erstellung eines DFD ⚙️
Das Erstellen eines Diagramms geht nicht nur darum, Formen zu zeichnen; es geht darum, strenge logische Regeln einzuhalten. Die Verletzung dieser Regeln macht das Diagramm technisch ungültig und nutzlos für die Analyse.
1. Erhaltung der Daten
Daten können innerhalb eines Prozesses nicht erstellt oder zerstört werden. Wenn Daten in einen Prozess eintreten, müssen sie entweder den Prozess verlassen oder gespeichert werden. Ein Prozess kann keine Daten ausgeben, die nicht eingegeben wurden, es sei denn, diese Daten werden aus anderen Eingaben abgeleitet. Dies verhindert „Wunder“ im Systemdesign.
2. Namenskonventionen
Jedes Element muss einen eindeutigen Namen haben. Datenflüsse sollten Substantive sein (z. B. „Rechnung“). Prozesse sollten Verben-Substantiv-Kombinationen sein (z. B. „Rechnung verarbeiten“). Datenspeicher sollten Pluralformen von Substantiven sein (z. B. „Rechnungen“). Konsistenz im Namen gibt eine einfachere Navigation und besseres Verständnis des Systems.
3. Ausbalancierung
Diese Regel gilt für die hierarchische Zerlegung. Wenn ein Prozess in Unterverfahren zerlegt wird, müssen die Eingaben und Ausgaben des übergeordneten Prozesses der Summe der Eingaben und Ausgaben der Unterverfahren entsprechen. Während der Zerlegung können keine Daten verschwinden oder magisch erscheinen.
4. Vermeidung von Steuerfluss
DFDs sind keine Steuerflussdiagramme. Sie zeigen keine Entscheidungspunkte wie „Wenn X, dann Y“. Sie zeigen die Bewegung von Daten. Entscheidungslogik wird innerhalb der Prozessbeschreibung behandelt, nicht auf dem Diagramm selbst. Dies hält die visuelle Darstellung sauber und auf Daten fokussiert.
Häufige Fehler, die vermieden werden sollten ❌
Sogar erfahrene Analysten können Fehler in ein DFD einbringen. Die Aufmerksamkeit für häufige Fehler hilft, die Integrität des Modells zu wahren.
- Schwarze Löcher:Ein Prozess, der Eingaben hat, aber keine Ausgaben. Dies bedeutet, dass Daten verbraucht werden, aber niemals verwendet werden, was ein logischer Fehler ist.
- Wunder:Ein Prozess, der Ausgaben hat, aber keine Eingaben. Dies bedeutet, dass Daten aus dem Nichts entstehen.
- Geisterströme:Datenströme, die mit keinem Komponenten verbunden sind. Jeder Pfeil muss eine klare Quelle und eindeutiges Ziel haben.
- Überlappende Funktionen:Wenn eine einzelne Prozessbox zu viel versucht. Wenn eine Prozessbox mehr als sieben Eingaben oder Ausgaben hat, ist es wahrscheinlich, dass sie zu viele Aufgaben übernimmt und geteilt werden sollte.
- Zyklen externer Entitäten:Externe Entitäten sollten nicht direkt miteinander verbunden sein. Alle Interaktionen müssen durch die Systemgrenze hindurchlaufen.
Vorteile in der Systemanalyse 🛠️
Warum Zeit in die Erstellung dieser Diagramme investieren? Der Nutzen geht über einfache Dokumentation hinaus.
- Kommunikation:Es schließt die Lücke zwischen technischen und nicht-technischen Stakeholdern. Visuelle Modelle sind leichter zu diskutieren als Textanforderungen.
- Lückenanalyse:Durch die Abbildung des Flusses können Analysten fehlende Datenanforderungen identifizieren. Wenn ein Benutzer einen Bericht benötigt, aber kein Datenstrom zu einem Datenspeicher führt, der diesen Bericht unterstützt, wird eine Lücke frühzeitig erkannt.
- Testgrundlage:Die Datenströme definieren die Testfälle. Wenn ein bestimmter Datenstrom definiert ist, muss ein Test sicherstellen, dass die Daten korrekt durch diesen Strom fließen.
- Systemdokumentation:Wenn Systeme sich weiterentwickeln, dienen DFDs als lebendige Karte. Wenn neue Funktionen hinzugefügt werden, wird das Diagramm aktualisiert, sodass die Dokumentation mit dem Code synchron bleibt.
Häufig gestellte Fragen ❓
Was ist der Unterschied zwischen einem DFD und einem Flussdiagramm?
Ein Flussdiagramm zeigt die Steuerlogik und Entscheidungspunkte eines Algorithmus. Es zeigt die Reihenfolge der Schritte. Ein DFD zeigt die Daten. Er zeigt, woher die Daten kommen und wohin sie gehen, unabhängig von der Reihenfolge der Operationen. Flussdiagramme dienen der Code-Logik; DFDs dienen der Systemarchitektur.
Kann ein DFD Sicherheitskontrollen zeigen?
Standard-DFDs zeigen Sicherheitsprotokolle wie Verschlüsselung oder Authentifizierung nicht explizit. Ein Sicherheitsanalyst kann Datenströme jedoch mit Anmerkungen versehen, um anzugeben, wo sensible Daten verarbeitet werden oder wo Zugriffssteuerungen durchgesetzt werden. Dies wird oft als Anmerkung am spezifischen Datenstrom dargestellt.
Wird ein spezifisches Werkzeug benötigt, um DFDs zu zeichnen?
Nein. Obwohl viele Software-Tools existieren, ist das Diagramm ein konzeptionelles Artefakt. Es kann auf Papier, Whiteboards oder mit jedem Vektorgrafik-Tool gezeichnet werden. Das Medium verändert die Logik des Modells nicht.
Wie behandeln DFDs Echtzeitdaten?
DFDs sind im Allgemeinen statische Darstellungen. Sie zeigen keine zeitlichen Aspekte oder Latenz implizit. Bei Echtzeitsystemen werden DFDs oft mit Zustandsübergangsdiagrammen oder Zeitdiagrammen kombiniert, um die zeitlichen Aspekte der Datenbewegung zu erfassen.
Schlussfolgerung zur Methodologie
Die Erstellung eines Datenflussdiagramms ist eine disziplinierte Übung der Abstraktion. Sie erfordert vom Analysten, Implementierungsdetails zu entfernen und sich auf das Wesentliche der Datenbewegung zu konzentrieren. Durch Einhaltung der strukturellen Regeln und Notationsstandards können Teams eine klare Bauplanung ihrer Informationssysteme erstellen. Diese Klarheit verringert das Risiko, verbessert die Kommunikation und stellt sicher, dass das endgültige System den tatsächlichen Anforderungen der Daten entspricht, die es verarbeitet.
Das DFD bleibt relevant, weil es eine grundlegende Frage beantwortet: „Wohin geht die Daten?“ In einer Ära komplexer, verteilter Systeme ist die Verfolgung des Informationspfades wichtiger denn je. Ob für eine einfache Webanwendung oder ein großflächiges Unternehmenssystem – die Prinzipien der DFD-Modellierung bieten eine stabile Grundlage für Gestaltung und Analyse.