











Die Landschaft der Datenverwaltung hat sich in den letzten zehn Jahren dramatisch verändert. Als Anwendungen an Umfang und Komplexität zunahmen, begannen die starren Strukturen der Vergangenheit zu bröckeln. NoSQL-Datenbanken traten auf, um riesige Datensätze, hochgeschwindige Datenströme und unstrukturierte Informationen zu verarbeiten, die traditionelle relationale Modelle ineffizient handhaben konnten. Diese Entwicklung hat eine anhaltende Debatte zwischen Architekten und Entwicklern ausgelöst:Wird NoSQL die Notwendigkeit traditioneller Entity-Relationship-Diagramme (ERDs) beseitigen? 🤔
Um diese Frage zu beantworten, müssen wir über die Hype hinaussehen und den grundlegenden Zweck der Datenmodellierung untersuchen. Während NoSQL-Technologien verändert haben, wie wir Daten speichern, bleibt die Notwendigkeit, Beziehungen zu visualisieren und Informationen zu strukturieren, eine zentrale Anforderung für die Stabilität von Systemen. Dieser Leitfaden untersucht die Feinheiten der Schema-Designs, die Rolle von ERDs in einer Welt mit polyglotten Persistenzlösungen und wohin die Branche sich entwickelt.
Verständnis der Grundlage: Was ist ein ERD? 🏗️
Ein Entity-Relationship-Diagramm ist eine visuelle Darstellung von Datenstrukturen und deren Beziehungen zueinander. Es wurde Anfang der 1970er Jahre entwickelt und wurde zum Bauplan für die Gestaltung relationaler Datenbanken. Ein ERD verwendet spezifische Symbole, um Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel) darzustellen.
Die primären Ziele eines ERDs umfassen:
- Klarheit: Bereitstellung einer visuellen Karte, damit Entwickler den Datenfluss verstehen können.
- Integrität: Sicherstellen, dass Datenregeln vor der Inbetriebnahme des Systems durchgesetzt werden.
- Kommunikation: Als universelle Sprache zwischen Geschäftsinteressenten und Ingenieurteams fungieren.
- Normalisierung: Daten organisieren, um Redundanz zu reduzieren und Konsistenz zu verbessern.
In einem relationalen Kontext sind diese Diagramme nicht freiwillig. Sie sind der Vertrag zwischen der Anwendung und der Speicherengine. Ohne sie werden Joins unmöglich zu planen, und die transaktionale Integrität ist gefährdet.
Die NoSQL-Störung: Ein neues Paradigma 📉
NoSQL-Datenbanken wurden nicht geschaffen, um Regeln aus Rebellion zu brechen. Sie entstanden aus Notwendigkeit. Als das Web skalierte, wurde die Notwendigkeit für horizontales Skalieren (Hinzufügen weiterer Server) wichtiger als vertikales Skalieren (Hinzufügen mehr Leistung zu einem Server). Relationale Datenbanken, die oft mit horizontalem Skalieren Probleme haben, machten Platz für Alternativen.
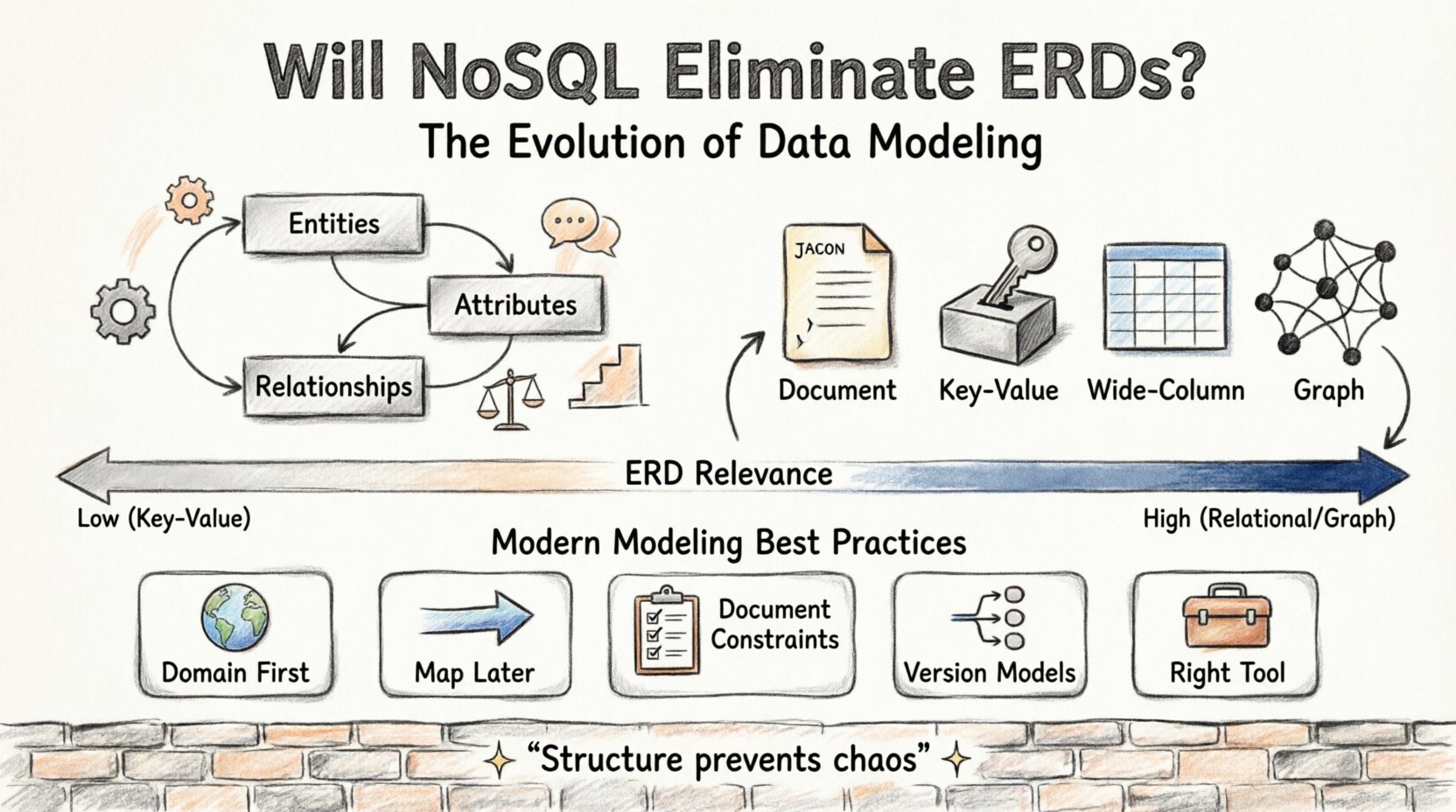
Es gibt mehrere Kategorien von NoSQL-Systemen, jeweils mit unterschiedlichen Modellierungsanforderungen:
- Dokumentenspeicher: Speichern Daten in JSON-ähnlichen Dokumenten. Beziehungen werden oft eingebettet statt über Fremdschlüssel verknüpft.
- Schlüssel-Wert-Speicher: Einfache Abfragen basierend auf eindeutigen Kennungen. Keine komplexen Beziehungen.
- Breitspalten-Speicher: Optimiert für riesige Datensätze über verteilte Systeme hinweg. Das Schema ist flexibel und wird beim Lesen definiert.
- Graphdatenbanken: Speziell für stark miteinander verbundene Daten konzipiert. Knoten und Kanten ersetzen Tabellen und Zeilen.
In vielen dieser Modelle wird das Konzept eines starren, vordefinierten Schemas gelockert. Diese Flexibilität führte zur Annahme, traditionelle Planungswerkzeuge wie ERDs seien veraltet. Entwickler konnten mit dem Codieren beginnen, Daten hochladen und die Struktur später korrigieren. Dieser Ansatz wird oft als „Schema-on-Read“ bezeichnet.
Warum das „Kein ERD“-Mythos weiterhin besteht 🚫📄
Die Idee, dass NoSQL keine Gestaltung erfordert, stammt aus der anfänglichen Benutzerfreundlichkeit. In einem dokumentenorientierten Speicher können Sie eine Aufzeichnung einfügen, ohne die Spalten vorher zu definieren. Diese Geschwindigkeit ist für die Prototypenerstellung reizvoll. Doch je weiter die Anwendung wächst, desto mehr führt dieser Mangel an Struktur zu technischem Schulden.
Häufige Missverständnisse sind:
- „Es ist einfach nur JSON.“ Obwohl der Payload wie JSON aussieht, erfordert der zugrundeliegende Speicher-Engine immer noch eine Organisation, um effizient abfragen zu können.
- „Beziehungen spielen keine Rolle.“Daten sind selten isoliert. Ein Benutzer hat Bestellungen, Bestellungen haben Artikel, und Artikel haben Kategorien. Das Ignorieren dieser Verbindungen führt zu Daten-Duplikation und Inkonsistenz.
- „Die Schema-Evolution ist automatisch.“Die Änderung der Datenstruktur in einem verteilten System ohne Planung kann zu Ausfällen oder Datenkorruption während der Migration führen.
Die Rolle von ERDs in der modernen Architektur 🔄
Während die strenge 1-zu-1-Zuordnung von ERDs zu SQL-Tabellen abnimmt, entwickelt sich dasKonzeptvon ERD weiterentwickelt. Es geht nicht mehr nur um Tabellen, sondern um Datenverbindungen. Selbst in NoSQL-Umgebungen ist das Verständnis der Verbindungen zwischen Datenentitäten entscheidend für Leistung und Wartbarkeit.
Hier ist, wie sich die Funktion der Datenmodellierung je nach Speichertyp verändert:
| Datenbanktyp | Modellierungsschwerpunkt | Relevanz von ERDs |
|---|---|---|
| Relational (SQL) | Normalisierung, Fremdschlüssel | Hoch (Wesentlich) |
| Dokumentenspeicher | De-Normalisierung, Einbetten | Mittel (Konzeptionell) |
| Graphdatenbank | Knoten, Kanten, Durchlauf | Hoch (anders visualisiert) |
| Schlüssel-Wert-Speicher | Identifikator-Suche | Niedrig (minimal) |
| Breitspalten | Partitionsschlüssel, Clustering | Mittel (strukturiert) |
Wie in der Tabelle gezeigt ist, verschiebt sich die Relevanz der Diagrammierung. Bei Graphdatenbanken ist ein visuelles Diagramm tatsächlich wichtiger als bei Schlüssel-Wert-Speichern. Die Terminologie ändert sich von „Tabellen“ zu „Knoten“, aber der Bedarf, Verbindungen zu verstehen, bleibt bestehen.
Wenn ERDs immer noch entscheidend sind 🛡️
Es gibt bestimmte Szenarien, in denen das Überspringen der Entwurfsphase ein Rezept für Misserfolg ist. Selbst bei flexiblen NoSQL-Speichern gelten bestimmte Einschränkungen.
1. Datenintegrität und Konsistenz
In Finanzsystemen oder der Bestandsverwaltung ist die Datenkorrektheit unverhandelbar. Wenn Sie eine Transaktion in einem Dokumentenspeicher speichern, ohne das Schema zu definieren, besteht die Gefahr, einen ungültigen Zustand einzufügen. Ein Diagramm hilft dabei, zu erkennen, wo Referenzintegritätsprüfungen erforderlich sind, auch wenn diese in der Anwendungsschicht statt in der Datenbankschicht durchgeführt werden.
2. Komplexe Abfragemuster
Das Abfragen von Daten wird exponentiell schwieriger, je größer die Datensammlung wird. Wenn Sie nicht planen, wie Sie die Daten abrufen werden, können Sie letztendlich vollständige Tabellenscans oder ineffiziente Abfragen durchführen. Das Verständnis der Lesezugriffe hilft dabei, die Struktur der Dokumente oder Spalten zu bestimmen.
3. Teamzusammenarbeit
Große Teams können sich nicht auf mündliche Vereinbarungen über die Datenstruktur verlassen. Ein ERD dient als Dokumentation. Wenn ein neuer Entwickler beitritt, schaut er sich das Diagramm an, um das Domänenmodell zu verstehen. Ohne dies dauert die Einarbeitung länger und die Anzahl der Fehler steigt.
4. Polyglotte Persistenz
Moderne Anwendungen verwenden häufig gleichzeitig mehrere Datenbanktypen. Sie könnten eine relationale Datenbank für Benutzerkonten, einen Dokumentenspeicher für Produktkataloge und einen Graphenspeicher für Empfehlungssysteme nutzen. Ein Gesamtsystemarchitekturdiagramm ist notwendig, um aufzuzeigen, wie die Daten zwischen diesen verschiedenen Speichern fließen.
Modellierung für NoSQL: Über das traditionelle ERD hinaus 🧠
Die Einführung von NoSQL erfordert eine Veränderung des Denkens. Die traditionellen Normalisierungsregeln (1NF, 2NF, 3NF) werden oft umgekehrt. Die Denormalisierung wird zu einer Best-Practice, um die Anzahl der erforderlichen Abfragen zu reduzieren. Genau hier ändert sich die Form des „Diagramms“.
Denormalisierungsmuster:
- Einbetten: Speichern verwandter Daten innerhalb eines einzelnen Dokuments. Beispiel: Speichern einer Adresse innerhalb eines Benutzerprofils.
- Verweisen: Beibehalten eines separaten Dokuments und Verknüpfen per ID. Beispiel: Eine Benutzer-ID in einem Bestelldokument.
- Aggregation: Vorab-Berechnung von Daten, um Laufzeitberechnungen zu vermeiden. Beispiel: Speichern des Gesamtpreises im Warenkorb.
Beim Gestalten dieser Strukturen erstellen Architekten oft ein Logisches Datenmodell anstelle eines strengen physischen ERDs. Dieses Modell konzentriert sich auf die Beziehungen und Kardinalitäten, ohne sich an konkrete Tabellendefinitionen zu binden. Es beantwortet Fragen wie:
- Handelt es sich um eine Eins-zu-Eins- oder eine Eins-zu-Viele-Beziehung?
- Auf welcher Seite der Beziehung ist der „Besitzer“?
- Wie häufig wird diese Daten gelesen im Vergleich zu Schreibvorgängen?
Herausforderungen bei der Diagrammierung von NoSQL-Systemen ⚠️
Die Erstellung eines Diagramms für ein flexibles Schema bringt einzigartige Herausforderungen mit sich. Traditionelle Werkzeuge erwarten feste Spalten. NoSQL erwartet dynamische Strukturen. Diese Diskrepanz kann Reibung im Gestaltungsprozess verursachen.
1. Schema-Evolution
Da NoSQL Schema-Änderungen zulässt, fühlen sich Teams oft weniger unter Druck, im Voraus zu planen. Änderungen an einer zentralen Datenstruktur in einem verteilten System können jedoch kostspielig sein. Migrations-Skripte müssen sorgfältig geschrieben werden. Ein Diagramm hilft dabei, Versionsänderungen im Laufe der Zeit zu verfolgen.
2. Abfrage-erstes Design
In NoSQL gestalten Sie die Datenstruktur oft basierend darauf, wie Sie sie abfragen werden, nicht nur darauf, wie Sie sie speichern. Dies wird als „abfragegetriebenes Design“ bezeichnet. Ein traditionelles ERD konzentriert sich auf Speichereffizienz. Ein NoSQL-Modell konzentriert sich auf Abfrageeffizienz. Das Diagramm muss Lesepfade widerspiegeln, nicht nur Schreibpfade.
3. Visuelle Komplexität
Graphdatenbanken können unglaublich dichte Diagramme erzeugen. Bei Tausenden von Knoten wird ein statisches Bild unlesbar. Automatisierte Visualisierungstools sind erforderlich, um diese Skalierung zu bewältigen, aber die logischen Beziehungen müssen weiterhin definiert werden.
Zukünftige Trends in der Datenmodellierung 🚀
Die Branche bewegt sich in Richtung eines hybriden Ansatzes. Wir verlassen die Struktur nicht, sondern passen sie an. Hier ist, was die Zukunft wahrscheinlich bringen wird.
- Schema-Validierungsebenen:Viele NoSQL-Engines bieten nun optionale Schema-Validierung an. Dies ermöglicht die Flexibilität von NoSQL mit der Sicherheit von SQL. Dadurch wird die Notwendigkeit für ERDs wieder relevant, da Sie die Regeln definieren müssen, die Sie durchsetzen möchten.
- Data Mesh: Dieser architektonische Trend dezentralisiert die Datenverantwortung. Verschiedene Teams besitzen ihre eigenen Datenbereiche. ERDs werden zu bereichsspezifischen Verträgen statt zu globalen Bauplänen.
- KI-unterstütztes Modellieren:Künstliche Intelligenz-Tools beginnen, Schema-Entwürfe basierend auf Abfrageprotokollen vorzuschlagen. Diese Tools können ERD-ähnliche Visualisierungen aus tatsächlichen Nutzungsmustern generieren.
- Einheitliche Abfragemotoren:Neue Motoren ermöglichen die Abfrage verschiedener Datenbanktypen (SQL und NoSQL) gleichzeitig. Dafür ist eine einheitliche Metadaten-Schicht erforderlich, die im Wesentlichen als globales ERD fungiert.
Best Practices für moderne Datenmodellierung 📝
Wenn Sie heute ein System entwerfen, wie sollten Sie bei der Dokumentation vorgehen? Hier sind praktikable Richtlinien.
1. Beginnen Sie mit dem Bereich, nicht mit der Datenbank
Definieren Sie zunächst die geschäftlichen Entitäten. Was ist ein „Kunde“? Was ist ein „Produkt“? Dies ist unabhängig davon, ob Sie sie in SQL oder NoSQL speichern. Verwenden Sie ein ERD, um diese Entitäten und ihre Beziehungen abstrakt zu definieren.
2. Später zur Speicherung abbilden
Sobald das Domänenmodell klar ist, ordnen Sie es der Speichertechnologie zu. Entscheiden Sie, wo Sie de-normalisieren und wo Sie normalisieren. Diese Trennung der Verantwortlichkeiten hält die Gestaltung flexibel.
3. Beschränkungen explizit dokumentieren
Selbst wenn die Datenbank keine Beschränkungen durchsetzt, dokumentieren Sie sie. Stellen Sie klar: „Benutzer-ID muss eindeutig sein“ oder „Bestelldatum darf nicht in der Zukunft liegen“. Dadurch wird sichergestellt, dass die Anwendungsschicht das durchsetzt, was die Speicherschicht zulässt.
4. Versionieren Sie Ihre Modelle
Behandeln Sie Ihre Datenmodelle wie Code. Halten Sie sie in der Versionskontrolle. Wenn Sie eine Beziehung ändern, committen Sie die Änderung. Dadurch entsteht eine Nachverfolgung der Entwicklung des Systems.
5. Verwenden Sie das richtige Werkzeug für die Aufgabe
Zwingen Sie kein SQL-ERD-Werkzeug nicht dazu, eine Graphdatenbank zu modellieren. Verwenden Sie Werkzeuge, die die spezifische Datenart unterstützen, die Sie verwenden. Für Dokumente verwenden Sie Schema-Definitionen. Für Graphen verwenden Sie Knoten-Verbindungs-Diagramme.
Vergleich der Ansätze: Ein Seiten-zu-Seiten-Vergleich 🔍
Das Verständnis der Kompromisse hilft dabei, die richtige Entscheidung für Ihr spezifisches Projekt zu treffen. Die Tabelle unten stellt die beiden Ansätze gegenüber.
| Aspekt | Traditioneller ERD (relational) | Moderne NoSQL-Modellierung |
|---|---|---|
| Struktur | Festes Schema | Flexibles / dynamisches Schema |
| Beziehungen | Fremdschlüssel | Einbetten oder Verweise |
| Design-Fokus | Normalisierung | De-Normalisierung / Lese-Muster |
| Änderungskosten | Hoch (Migrationen) | Mittel (Anwendungslogik) |
| Dokumentation | Diagramm ist obligatorisch | Diagramm wird dringend empfohlen |
Dieser Vergleich zeigt, dass das Prinzip der Modellierung konstant ist, auch wenn die Implementierung variiert. Sie müssen immer noch wissen, wie Daten miteinander verbunden sind. Sie müssen immer noch wissen, was Daten darstellen.
Die Skeptiker ansprechen 🗣️
Manchmal argumentieren Entwickler, dass Diagramme die Entwicklung verlangsamen. Sie bevorzugen es, zuerst zu coden und die Daten später zu korrigieren. Während dies für kleine Skripte funktioniert, scheitert es bei Enterprise-Systemen.
Berücksichtigen Sie die Kosten der Refaktorisierung. In einer relationalen Datenbank erfordert das Hinzufügen einer Spalte eine Migration. In einem NoSQL-System könnte die Änderung einer Dokumentstruktur eine vollständige Neuschreibung der Daten über Millionen von Datensätzen erfordern. Die Kosten, ein schlechtes Modell zu beheben, sind immer höher als die Kosten für die Planung. Diagramme verringern das Risiko dieser kostspieligen Korrekturen.
Letzte Gedanken zur Zukunft 🌅
Die Frage, ob NoSQL ERDs eliminieren wird, wird beantwortet, indem man den Zweck des Diagramms betrachtet. Wenn der Zweck darin besteht, Tabellenspalten zu definieren, hat NoSQL tatsächlich die Notwendigkeit für diese spezifische Art von Diagramm reduziert. Wenn jedoch der Zweck darin besteht, Datenbeziehungen, Integrität und Fluss zu visualisieren, bleibt der Bedarf an Diagrammen stark.
Die Technologie entwickelt sich weiter, aber die Komplexität der Daten nimmt nicht ab. Je verteilter die Systeme werden, desto größer wird der Bedarf an klarer Dokumentation. Der ERD stirbt nicht; er wandelt sich. Er wird weniger um die physische Speicherung und mehr um den logischen Bereich zentriert.
Architekten, die die Datenmodellierung in einer NoSQL-Umgebung ignorieren, riskieren, Systeme zu schaffen, die schnell zu bauen sind, aber unmöglich zu warten sind. Die Zukunft gehört denen, die Flexibilität mit Struktur ausbalancieren. Wir werden weiterhin Diagramme zeichnen, aber sie werden anders aussehen, sich auf andere Metriken konzentrieren und sich an unterschiedliche Speicher-Engines anpassen.
Die Wahl liegt nicht zwischen Diagrammen und NoSQL. Die Wahl liegt zwischen disziplinierter Modellierung und chaotischer Improvisation. In einer Welt mit unendlichem Datenreichtum ist Struktur das Einzige, was Chaos verhindert. 🧱✨