











Entitäts-Beziehungs-Diagramme (ERDs) bilden die Grundlage einer robusten Datenarchitektur. Sie liefern die visuelle Bauplanung dafür, wie Informationen innerhalb eines Datenbanksystems strukturiert, gespeichert und abgerufen werden. Trotz ihrer entscheidenden Bedeutung ist das Umfeld rund um die ERD-Design-Praxis oft durch Marketinggeschichten verschleiert. Anbieter und Berater präsentieren Diagrammierwerkzeuge häufig als Allheilmittel, die komplexe Datenmodellierungsprobleme sofort lösen. Dieser Ansatz ignoriert die strenge Logik, die erforderlich ist, um eine nachhaltige Datenumgebung aufzubauen.
Um Systeme zu schaffen, die Bestand haben, müssen wir über die Hype hinaussehen. Wir müssen die technischen Realitäten von Beziehungen, Einschränkungen und Normalisierung verstehen. Diese Anleitung entlarvt verbreitete Missverständnisse über ERDs. Wir werden den Unterschied zwischen einem theoretischen Modell und einer physischen Implementierung untersuchen. Ziel ist es nicht, ein bestimmtes Werkzeug oder eine Methode zu fördern, sondern die Prinzipien zu klären, die die Datenintegrität regeln.
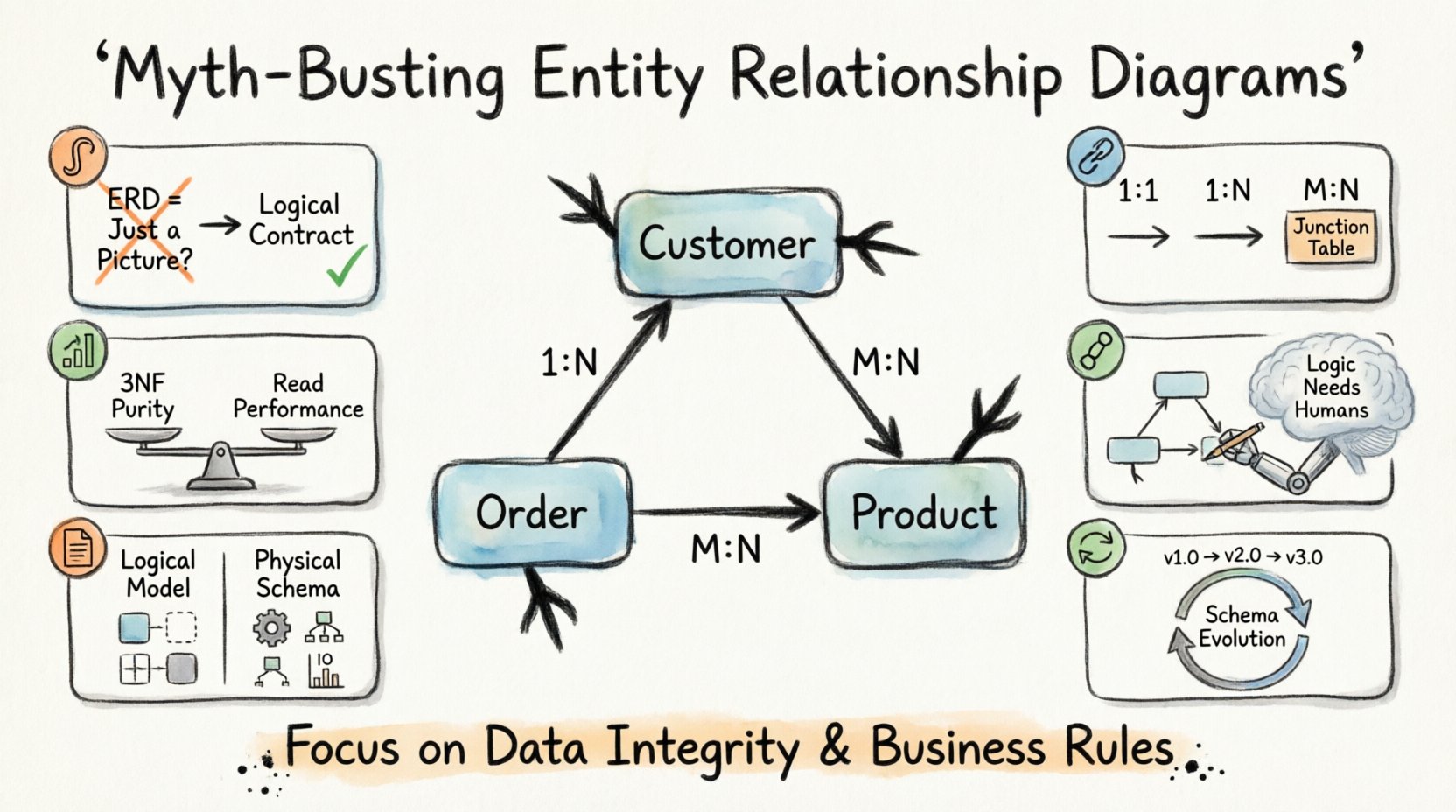
1. Der visuelle Sog: Ist ein ERD einfach nur ein Diagramm? 🎨
Ein weit verbreiteter Mythos besagt, dass ein Entitäts-Beziehungs-Diagramm lediglich ein Dokumentationsobjekt sei. Viele Teams behandeln das Diagramm als Nachprojektlieferung, etwas, das nach dem Schreiben des Codes erstellt wird, um Stakeholder zu befriedigen. Diese Sichtweise ist grundlegend fehlerhaft. Ein ERD ist ein logischer Vertrag, kein Bild.
Wenn ein ERD als visuelles Nachgedanken behandelt wird, ergeben sich mehrere Risiken:
- Schema-Abweichung: Die Datenbankstruktur weicht von der vorgesehenen Gestaltung ab, was zu inkonsistenten Dateneingaben führt.
- Leistungsengpässe: Abfragen scheitern, weil die zugrundeliegende Struktur die erforderlichen Joins nicht effizient unterstützt.
- Verlust der Datenintegrität: Fremdschlüsselbeschränkungen werden ignoriert, was das Vorhandensein verwaister Datensätze ermöglicht.
Betrachten Sie den Lebenszyklus einer Datenbanktabelle. Er beginnt mit einer geschäftlichen Anforderung. Er geht über ein logisches Modell hin zu einer physischen Schema. Das ERD verbindet die Lücke zwischen der geschäftlichen Logik und der technischen Speicherung. Wenn das Diagramm nicht die Quelle der Wahrheit ist, wird die Datenbank zwangsläufig unter Mehrdeutigkeit leiden.
Effektives Datenmodellieren erfordert sorgfältige Aufmerksamkeit für Details. Es geht nicht darum, Kästchen und Linien zu zeichnen. Es geht darum, die Regeln für die Interaktion mit Daten festzulegen. Jede Linie in einem ERD steht für eine Einschränkung. Jedes Kästchen steht für eine Dateneinheit, die erhalten bleiben muss. Die Ignorierung dieser Realität führt zu Systemen, die zerbrechlich und schwer zu pflegen sind.
2. Kardinalität und Beziehungen: Weiter als die Grundlagen 🔗
Die Kardinalität definiert die numerische Beziehung zwischen Entitäten. Sie beantwortet die Frage: Wie viele Instanzen einer Entität stehen mit Instanzen einer anderen Entität in Beziehung? Marketingmaterialien vereinfachen dies oft zu ein-zu-viele oder viele-zu-viele, ohne die Implikationen zu erklären.
Das Verständnis der Kardinalität ist entscheidend für die Abfrageleistung und die Datenkonsistenz. Es gibt drei Hauptarten von Beziehungen:
- Ein-zu-eins (1:1): Jeder Datensatz in Tabelle A steht genau mit einem Datensatz in Tabelle B in Beziehung. Dies wird oft für Sicherheit oder Datengetrenntheit verwendet.
- Ein-zu-viele (1:N): Ein Datensatz in Tabelle A steht mit mehreren Datensätzen in Tabelle B in Beziehung. Dies ist die häufigste Beziehung in transaktionalen Systemen.
- Viele-zu-viele (M:N): Mehrere Datensätze in Tabelle A stehen mit mehreren Datensätzen in Tabelle B in Beziehung. Dazu ist eine Verbindungstabelle erforderlich, um dies physisch aufzulösen.
Ein verbreiteter Irrtum ist, dass ein-zu-eins-Beziehungen immer besser für die Datengetrenntheit sind. Obwohl sie Isolation bieten, können sie unnötige Komplexität einführen. Die Aufteilung der Daten in zwei Tabellen, wenn eine einzige Tabelle ausreichen würde, erhöht die Join-Kosten. Dies kann die Leistung bei Lesevorgängen verschlechtern.
Umgekehrt führt das Ignorieren von viele-zu-viele-Beziehungen zu Daten-Duplikation. Wenn Sie versuchen, eine Liste von Werten in einer einzigen Spalte zu speichern, ohne eine geeignete Verbindungstabelle zu verwenden, verletzen Sie die Normalisierungsregeln. Dies macht das Aktualisieren und Abfragen der Daten erheblich schwieriger.
| Beziehungstyp | Physische Implementierung | Häufiger Fehler |
|---|---|---|
| Ein-zu-eins | Fremdschlüssel in einer der Tabellen | Übersegmentierung von Daten |
| Eins-zu-Viele | Fremdschlüssel in der „Viele“-Tabelle | Zirkuläre Referenzfehler |
| Viele-zu-Viele | Verbindungstabelle mit zwei Fremdschlüsseln | Fehlende eindeutige Einschränkungen in der Verbindung |
Beim Entwerfen dieser Beziehungen müssen Sie die Geschäftsregeln berücksichtigen. Hat ein Kunde eine Adresse oder mehrere? Gehört ein Produkt einer Kategorie an oder mehreren? Das Diagramm muss die operative Realität widerspiegeln, nicht eine idealisierte Version davon.
3. Normalisierung: Das 3NF-Mythos 📊
Die Normalisierung ist eine Technik zur Organisation von Daten, um Redundanz zu reduzieren. Die Dritte Normalform (3NF) wird oft als Goldstandard genannt. Der Mythos besagt, dass jede Datenbank vollständig auf 3NF normalisiert sein muss, um als gültig zu gelten. Das ist nicht immer der Fall.
Die Normalisierung beseitigt Anomalien. Dabei handelt es sich um Probleme, die bei der Dateneinfügung, Aktualisierung oder Löschung auftreten. Wenn beispielsweise der Kundename in jedem Auftragseintrag gespeichert wird, erfordert die Änderung des Namens die Aktualisierung von Tausenden von Zeilen. Dies ist eine Aktualisierungsanomalie. Die Normalisierung behebt dies, indem der Name in eine separate Kundentabelle verschoben wird.
Allerdings kann eine strikte Einhaltung der 3NF die Leistung beeinträchtigen. Jede Beziehung erfordert einen Join. Joins sind rechenintensiv. In hochbelasteten Berichtssystemen kann übermäßige Normalisierung die Abfrageausführung verlangsamen. Hier kommt die Denormalisierung ins Spiel.
Die Denormalisierung ist die bewusste Einführung von Redundanz, um die Leseleistung zu verbessern. Es handelt sich um einen Kompromiss. Sie opfern Schreibgeschwindigkeit und Speichereffizienz zugunsten schnellerer Lesevorgänge. Diese Entscheidung sollte niemals leichtfertig getroffen werden. Sie erfordert ein tiefes Verständnis der Zugriffsmuster.
Wichtige Überlegungen bei der Normalisierung sind:
- Lese- vs. Schreibbalance:Ist das System leseschwer oder schreibschwer?
- Abfragekomplexität:Wie komplex sind die erforderlichen Berichte?
- Speicherkosten:Ist Redundanz vertretbar?
Blindes Folgen der 3NF ohne Analyse der Arbeitslast ist ein Rezept für eine träge Anwendung. Ziel ist es, die Datenintegrität mit Leistungsanforderungen in Einklang zu bringen. Manchmal ist eine sorgfältig denormalisierte Ansicht die bessere Lösung als ein perfekt normalisierter Schema.
4. Werkzeugabhängigkeit: Automatisierung vs. Logik 🤖
Moderne Werkzeuge bieten Funktionen wie automatische Schemaerzeugung und Reverse Engineering. Anbieter vermarkten diese Fähigkeiten als Zeitersparnis. Der Mythos hier ist, dass das Werkzeug den Designer ersetzen kann. Ein Diagrammwerkzeug kann Linien ziehen, versteht aber keinen Geschäftskontext.
Die automatisierte Generierung erzeugt oft technisch korrekte, aber logisch fehlerhafte Schemata. Sie kann Tabellen basierend auf Code-Inspektionen anstatt auf Geschäftsanforderungen erstellen. Sie könnte versteckte Beziehungen übersehen, die nicht explizit codiert sind.
Menschliche Überwachung ist unverzichtbar. Der Datenmodellierer muss die Ausgabe anhand der tatsächlichen Bedürfnisse der Organisation validieren. Zu den Aufgaben, die nicht automatisiert werden können, gehören:
- Definition von Geschäftsregeln:Bestimmung, welche Attribute obligatorisch sind.
- Behandlung von Randfällen:Entscheidung darüber, wie NULL-Werte oder weiche Löschungen behandelt werden sollen.
- Optimierung für zukünftiges Wachstum: Die Erweiterung der Daten vorwegzunehmen.
Werkzeuge sind Hilfsmittel, keine Architekten. Sie erleichtern die Erstellung des Diagramms, doch die Logik liegt im menschlichen Geist. Die alleinige Abhängigkeit von Automatisierung führt zu Systemen, die starr und schwer anpassbar sind. Das Werkzeug sollte den Arbeitsablauf unterstützen, nicht ihn vorschreiben.
5. Die Lücke bei der physischen Umsetzung 📝
Es besteht ein deutlicher Unterschied zwischen einem logischen Modell und einem physischen Modell. Das logische Modell beschreibt Entitäten und Beziehungen konzeptionell. Das physische Modell definiert Datentypen, Indizes und Einschränkungen.
Viele Teams gehen davon aus, dass das logische Modell direkt in die physische Datenbank übersetzt wird. Das ist selten der Fall. Verschiedene Datenbanksysteme verfügen über unterschiedliche Fähigkeiten. Eine Beziehung, die in einem System gut funktioniert, könnte in einem anderen schlecht performen.
Zum Beispiel unterscheiden sich Datentypen. Ein Feld, das im logischen Modell als „Text“ definiert ist, könnte im physischen Datenbankmodell als „VARCHAR(255)“ oder „TEXT“ benötigt werden. Auch die Indizierungsstrategien variieren. Ein Index, der Abfragen in einem System beschleunigt, könnte in einem anderen die Schreibvorgänge verlangsamen.
Beim Übergang von der Gestaltung zur Umsetzung müssen Sie sich an die spezifische Technologie-Stack anpassen. Berücksichtigen Sie die folgenden Anpassungen:
- Datentypen: Stellen Sie sicher, dass die gewählten Typen mit dem Speicher-Engine übereinstimmen.
- Indizes: Fügen Sie Indizes für häufig abgefragte Spalten hinzu.
- Partitionierung: Überlegen Sie, große Tabellen zur besseren Verwaltung zu teilen.
- Einschränkungen: Entscheiden Sie sich zwischen Überprüfungen auf Anwendungsebene und Einschränkungen auf Datenbankebene.
Die Ignorierung dieser Unterschiede führt zu einer Lücke zwischen dem Entwurf und der Realität. Das System mag funktionieren, wird aber nicht optimiert sein. Eine gründliche Überprüfung der physischen Umsetzung ist notwendig, um sicherzustellen, dass der Entwurf unter Last Bestand hat.
6. Wartung und Evolution 🔄
Ein weiteres bedeutendes Missverständnis ist, dass ein Datenbankentwurf statisch ist. Sobald das ERD genehmigt ist, ist es in Stein gemeißelt. In Wirklichkeit ändern sich die Geschäftsanforderungen. Neue Funktionen werden hinzugefügt. Vorschriften entwickeln sich weiter. Das Datenmodell muss sich mit ihnen weiterentwickeln.
Das Refactoring einer Datenbank ist schwierig. Die Änderung eines Spaltentyps oder einer Beziehung kann bestehende Anwendungen beschädigen. Daher muss der Entwurf flexibel genug sein, um Änderungen zu ermöglichen, ohne eine vollständige Neuberechnung zu erfordern. Strategien für die Wartbarkeit umfassen:
- Versionsverwaltung: Verfolgen Sie die Schemaänderungen im Laufe der Zeit.
- Migrations-Skripte: Automatisieren Sie die Bereitstellung von Änderungen.
- Dokumentation: Halten Sie das Diagramm zusammen mit dem Code aktuell.
Dokumentation wird oft vernachlässigt, bis es zu spät ist. Wenn ein Entwickler das Projekt verlässt, geht das Wissen über die Datenstruktur verloren. Ein aktuelles ERD dient als primäre Referenz für neue Teammitglieder. Es verringert die Lernkurve und verhindert Fehler.
Die Evolution erfordert Disziplin. Jede Änderung muss auf ihre Auswirkungen auf bestehende Daten bewertet werden. Rückwärtskompatibilität sollte so weit wie möglich gewahrt werden. Dadurch wird sichergestellt, dass Anwendungen, die auf der Datenbank basieren, nicht unerwartet ausfallen.
7. Häufige Mythen im Vergleich zur Realität – Zusammenfassung
Zusammenfassend können wir die häufigsten Missverständnisse kategorisieren. Diese Tabelle dient als schneller Leitfaden, um zwischen Marketingbehauptungen und technischen Fakten zu unterscheiden.
| Mythos | Wirklichkeit |
|---|---|
| ERDs sind nur hübsche Bilder | ERDs sind technische Verträge, die Datenregeln definieren |
| Mehr Tabellen bedeuten besseres Design | Komplexität verringert die Leistung; Ausgewogenheit ist entscheidend |
| Normalisierung ist immer das Ziel | Die De-Normalisierung verbessert die Lese-Geschwindigkeit in bestimmten Fällen |
| Werkzeuge können das Design automatisieren | Werkzeuge unterstützen, aber Logik erfordert menschliche Aufsicht |
| Logische Modelle entsprechen physischen Schemata | Die physische Implementierung erfordert spezifische Optimierungen |
| Das Design ist dauerhaft | Schemata müssen sich den Geschäftsbedürfnissen anpassen |
Abschließende Gedanken zur Datenmodellierung 🧭
Der Aufbau eines zuverlässigen Datenbanksystems erfordert ein klares Verständnis der zugrundeliegenden Prinzipien. Entity-Relationship-Diagramme sind leistungsstarke Werkzeuge, wenn sie richtig eingesetzt werden. Sie bieten eine gemeinsame Sprache zwischen Geschäftsinteressenten und technischen Teams.
Sie sind jedoch keine Zauberwaffe. Sie lösen Datenprobleme nicht von allein. Der Wert ergibt sich aus der strengen Anwendung von Logik während der Entwurfsphase. Wir müssen die Vorstellung ablehnen, dass Software-Werkzeuge kritisches Denken ersetzen können. Wir müssen auch akzeptieren, dass Normalisierung keine allgemein gültige Lösung ist.
Erfolg im Datenbankdesign hängt von Klarheit, Präzision und Anpassungsfähigkeit ab. Indem Sie Marketing-Hype von der technischen Realität trennen, können Sie Systeme bauen, die robust und skalierbar sind. Konzentrieren Sie sich auf die Datenintegrität und die Geschäftsregeln. Lassen Sie das Diagramm als Leitfaden dienen, nicht als Ziel.
Wenn Sie beim Datenmodellieren diese Prinzipien im Blick haben, sprechen die Ergebnisse für sich. Das System wird einfacher zu pflegen sein. Abfragen werden schneller laufen. Die Daten bleiben genau. Das ist der wahre Wert eines gut konstruierten Entity-Relationship-Diagramms.