










Entitäts-Beziehungs-Diagramme (ERDs) dienen als grundlegende Baupläne für die Datenbankarchitektur. Sie übersetzen abstrakte Geschäftslogik in strukturierte Datenmodelle, die Systeme verarbeiten können. In diesem Kontext steht die Eins-zu-Viele-Beziehung als am häufigsten vorkommendes strukturelles Muster. Allerdings bestehen weit verbreitete Missverständnisse bezüglich ihrer Implementierung, Kardinalität und Leistungsaspekte. Das Verständnis der Feinheiten dieser Verbindungen ist entscheidend für die Erstellung robuster, skalierbarer Datenmodelle.
Viele Praktiker nähern sich der Datenmodellierung mit vorhergefassten Vorstellungen, die aus vereinfachten Tutorials oder veralteten Praktiken stammen. Diese Annahmen führen oft zu Ineffizienzen, Datenintegritätsproblemen oder schwierigen Wartungszyklen später im Projektverlauf. Dieser Leitfaden analysiert die verbreiteten Mythen rund um Eins-zu-Viele-Beziehungen. Wir untersuchen die technischen Realitäten von Kardinalität, Fremdschlüsseln und Normalisierung, ohne auf spezifische Softwareanbieter zurückzugreifen.
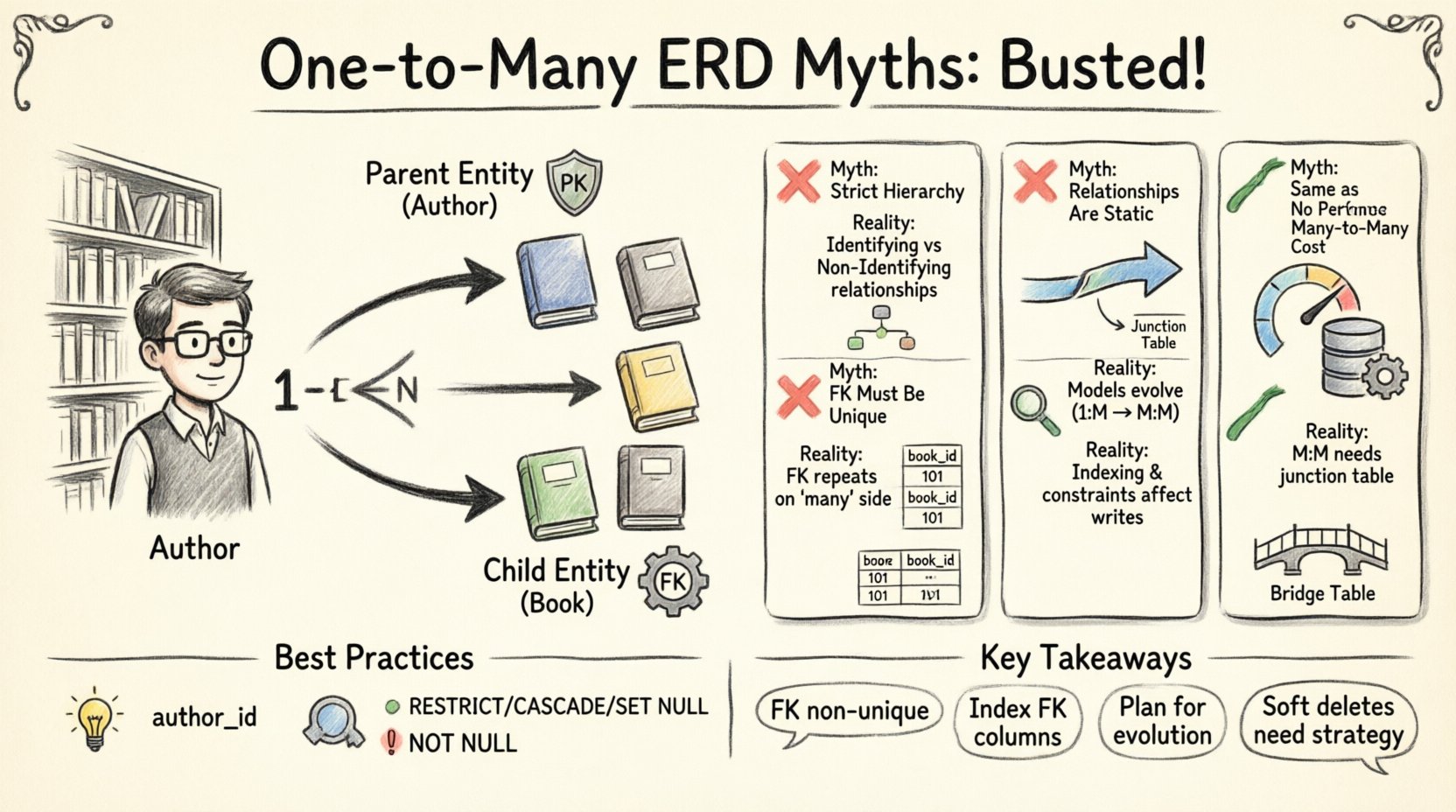
🧐 Verständnis des Kernkonzepts
Bevor wir Missverständnisse ansprechen, ist es unerlässlich, eine klare Definition zu schaffen. In der Datenmodellierung beschreibt eine Beziehung, wie Instanzen einer Entität mit Instanzen einer anderen Entität verbunden sind. Die Eins-zu-VieleBeziehung zeigt an, dass ein einzelner Datensatz in der ersten Entität mit mehreren Datensätzen in der zweiten Entität verknüpft sein kann.
Betrachten wir ein Bibliothekssystem. Eine einzelne AutorEntität kann mit mehreren BuchEntitäten verknüpft werden. Umgekehrt ist ein bestimmtes Buchwird gewöhnlich von einem bestimmten Autorgeschrieben (in einem vereinfachten Modell). Dies ist die klassische Eins-zu-Viele-Dynamik. Die Entität auf der EinsSeite wird oft als Elternteil bezeichnet, während die Entität auf der VieleSeite das Kind ist.
- Elternteil-Entität: Die Entität, die den eindeutigen Schlüssel (Primärschlüssel) enthält.
- Kind-Entität: Die Entität, die die Referenz auf das Elternteil enthält (Fremdschlüssel).
- Kardinalität: Die numerische Begrenzung von Beziehungen (z. B. 1 zu N).
Die visuelle Notation variiert je nach Standard wie Chen, Crow’s Foot oder UML. Unabhängig vom verwendeten Symbol bleibt die zugrundeliegende mathematische Logik konstant. Die Integrität dieser Beziehung bestimmt, wie Daten gespeichert, abgerufen und geschützt werden.
❌ Mythos 1: Eins-zu-Viele impliziert immer eine strenge Hierarchie
Eine verbreitete Annahme ist, dass Eins-zu-Viele-Beziehungen eine strenge Elternteil-Kind-Hierarchie festlegen, bei der das Elternteil die Existenz des Kindes kontrolliert. Obwohl dies in einigen spezifischen Geschäftsregeln zutrifft, ist es keine universelle Regel der Datenbankgestaltung.
🔍 Die Wirklichkeit der Existenzabhängigkeit
Nicht alle Kinddatensätze hängen von dem übergeordneten Datensatz für ihre Existenz ab. In der Datenbankterminologie wird dies alsExistenzabhängigkeit. Wenn ein Kinddatensatz ohne einen übergeordneten Datensatz existieren kann, ist die Beziehungnicht identifizierend. Wenn das Kind nicht ohne den übergeordneten Datensatz existieren kann, ist esidentifizierend.
- Nicht identifizierend: Ein Kunde kann ohne eine Bestellung. Die Kunden-Tabelle steht für sich allein. Die Bestellungs-Tabelle verweist auf den Kunden.
- Identifizierend: Eine Bestellposition kann nicht ohne eine Bestellung. Die Bestellpositions-Tabelle könnte die Bestellungs-ID als Teil ihres Primärschlüssels gemeinsam nutzen.
Die Annahme einer strengen Hierarchie, wo keine besteht, kann zu unnötigen Einschränkungen führen. Zum Beispiel könnte die Durchsetzung einerCASCADE-LÖSCHEN bei einer nicht abhängigen Beziehung unbeabsichtigt gültige Daten entfernen. Überprüfen Sie immer die Geschäftsregel, bevor Sie strenge Referenzintegritätsbeschränkungen anwenden.
❌ Mythos 2: Fremdschlüssel müssen eindeutig sein
Verwirrung entsteht oft bezüglich der Eindeutigkeitsbeschränkung in der Fremdschlüsselspalte. Ein Fremdschlüssel in einer ein-zu-viele-Beziehung ist explizit darauf ausgelegt,nicht eindeutig auf der vielen-Seite zu sein.
🔍 Die Wirklichkeit von Kardinalitätsbeschränkungen
Der Primärschlüssel der übergeordneten Tabelle ist eindeutig. Der Fremdschlüssel in der Kindtabelle verweist auf diesen Primärschlüssel. Da ein übergeordneter Datensatz mit vielen Kindern verbunden ist, muss der Fremdschlüsselwert sich wiederholen. Wenn der Fremdschlüssel eindeutig wäre, würde die Beziehung zu einer ein-zu-eins-Beziehung werden.
| Aspekt | Ein-zu-eins | Ein-zu-Viele |
|---|---|---|
| Eindeutigkeit des Fremdschlüssels | Eindeutig | Nicht eindeutig |
| Indizierungsstrategie | Häufig eindeutiger Index | Standard-Index |
| Datenspeicherung | Niedrig | Höher (durch Entwurf) |
Die Sicherstellung, dass der Fremdschlüssel nicht eindeutig ist, ist entscheidend. Wenn ein System die Eindeutigkeit auf der Kindseite erzwingt, beschränkt dies das Modell auf eine einzige Assoziation und bricht die beabsichtigte Datenstruktur. Dies ist ein häufiger Konfigurationsfehler in automatisierten Modellierungstools.
❌ Mythos 3: Beziehungen sind statisch
Viele Designer gehen davon aus, dass eine Ein-zu-Viele-Beziehung, sobald sie im Diagramm definiert ist, unveränderlich bleibt. Datenmodelle müssen sich jedoch mit dem Geschäft entwickeln. Annahmen über statische Beziehungen ignorieren die dynamische Natur der Daten.
🔍 Die Wirklichkeit der Modellentwicklung
Geschäftsanforderungen ändern sich. Ein Produkt könnte ursprünglich einer Kategorie zugeordnet sein, aber später könnte das Unternehmen erweitern, um mehrere Kategorien pro Produkt zuzulassen. Dadurch ändert sich das Modell von Ein-zu-Viele zu Viele-zu-Viele.
- Refactoring-Risiko:Die Änderung eines Beziehungstyps erfordert oft Datenmigrationsskripte.
- Abwärtskompatibilität:Alte Berichte könnten auf die ursprüngliche Struktur angewiesen sein.
- Versionsverwaltung:Die Aufrechterhaltung einer Historie von Schemaänderungen ist für die langfristige Stabilität unerlässlich.
Designer sollten zukünftiges Wachstum vorhersehen. Obwohl eine Ein-zu-Viele-Beziehung derzeit Standard ist, sollte das Schema Flexibilität zulassen. Die Verwendung von Surrogatschlüsseln (auto-incrementierende IDs) statt natürlicher Schlüssel (wie E-Mail-Adressen) als Fremdschlüssel vereinfacht diese Übergänge oft.
❌ Mythos 4: Fremdschlüssel haben keine Leistungskosten
Es besteht die Ansicht, dass das Hinzufügen von Fremdschlüsselbeschränkungen rein logisch ist und vernachlässigbaren Einfluss auf die Leistung hat. Tatsächlich erfordert jede Beschränkung, dass die Datenbankengine während Schreibvorgänge Überprüfungen durchführt.
🔍 Die Wirklichkeit der Schreibleistung
Beim Einfügen eines Datensatzes in die Kindtabelle muss die Datenbank überprüfen, ob der verwiesene Elterndatensatz existiert. Dies erfordert eine Suchoperation. In Systemen mit hoher Durchsatzrate fügt diese Suche Latenz hinzu.
- Index-Aufwand:Spalten für Fremdschlüssel sollten indiziert werden, um den Überprüfungsprozess zu beschleunigen.
- Sperrung:Überprüfungen der Referenzintegrität können Sperrungen in der Elterntabelle erfordern.
- Kaskadenoperationen: Wenn
CASCADE LÖSCHENist aktiviert, führt das Löschen eines übergeordneten Elements zu mehreren Löschvorgängen für untergeordnete Elemente, was ressourcenintensiv sein kann.
Bei Szenarien mit großem Datenfluss deaktivieren einige Architekten die Fremdschlüsselbeschränkungen temporär, um die Durchsatzleistung zu verbessern. Dies birgt jedoch das Risiko von Datenkorruption. Der Kompromiss zwischen Integrität und Geschwindigkeit muss je nach spezifischem Anwendungsfall abgewogen werden.
❌ Mythos 5: Ein-zu-Viele ist dasselbe wie Viele-zu-Viele
Praktiker verwechseln manchmal die visuelle Darstellung von Ein-zu-Viele mit Viele-zu-Viele. Obwohl sie in hochlevel-Diagrammen ähnlich aussehen, unterscheiden sich die Implementierungen erheblich.
🔍 Die Wirklichkeit von Verbindungstabellen
Eine echte Viele-zu-Viele-Beziehung erfordert eine Zwischentabelle, die oft als Verbindungstabelle oder Brückentabelle bezeichnet wird. Eine Ein-zu-Viele-Beziehung benötigt dies nicht.
- Ein-zu-Viele: Direkte Verbindung über einen Fremdschlüssel in der Kindtabelle.
- Viele-zu-Viele: Erfordert eine neue Tabelle, die Fremdschlüssel für beide Entitäten enthält.
Die Versuch, Viele-zu-Viele-Logik mit einer einzigen Fremdschlüsselspalte zu implementieren, führt zu Datenverdoppelung oder -verlust. Zum Beispiel kann ein Student, der über nur eine Spalte course_id in der Studententabelle verknüpft wird, nur an einem Kurs teilnehmen. Um mehrere Einschreibungen zuzulassen, benötigen Sie eine EinschreibungTabelle.
🛠️ Best Practices für die Implementierung
Die Einhaltung von Best Practices stellt sicher, dass die Ein-zu-Viele-Beziehungen stabil bleiben. Diese Richtlinien konzentrieren sich auf Struktur, Benennung und Integrität.
📝 Namenskonventionen
Konsistente Benennung reduziert Mehrdeutigkeiten. Fremdschlüssel sollten die Beziehung eindeutig anzeigen. Eine Spalte namens author_id ist eindeutiger als auth_id.
- Standardformat:
parent_table_singular_id. - Konsistenz: Wenden Sie dieses Muster auf alle Entitäten an.
- Groß-/Kleinschreibung: Halten Sie sich an Klein- oder Großschreibung, um Probleme mit der Groß-/Kleinschreibung unter verschiedenen Betriebssystemen zu vermeiden.
🔒 Referenzielle Integrität
Die Durchsetzung der Integrität verhindert verwaiste Datensätze. Ein verwaister Datensatz ist ein Kind-Eintrag, der auf ein Elternteil verweist, das nicht mehr existiert.
- ON DELETE RESTRICT: Verhindert die Löschung des Elternteils, wenn Kind-Elemente existieren.
- ON DELETE CASCADE: Löscht die Kinder, wenn das Elternteil entfernt wird.
- ON DELETE SET NULL: Setzt den Fremdschlüssel zurück, wenn das Elternteil entfernt wird.
Die Wahl der richtigen Aktion hängt von der Kritikalität der Daten ab. Bei Finanztransaktionen ist RESTRICT in der Regel sicherer. Für temporäre Protokolle könnte CASCADE akzeptabel sein.
⚙️ Normalisierung und Eins-zu-Viele
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren. Eins-zu-Viele-Beziehungen sind die primäre Methode zur Erreichung der Normalisierung.
📊 Zweite Normalform (2NF)
2NF erfordert, dass alle nichtschlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Eins-zu-Viele-Beziehungen helfen dabei, sich wiederholende Gruppen zu isolieren. Wenn eine Tabelle eine Liste von Elementen enthält, führt das Verschieben dieser Liste in eine separate Tabelle zu einer Eins-zu-Viele-Verbindung.
- Bevor: Eine einzelne Zeile enthält mehrere Produktbezeichnungen.
- Nachher: Der Produkttitel wird in eine neue Tabelle verschoben, die über eine Produkt-ID verknüpft ist.
Diese Trennung stellt sicher, dass die Aktualisierung eines Produktnamens nur eine Zeile betrifft, anstatt mehrere Zeilen zu aktualisieren, in denen der Name wiederholt wird.
📊 Dritte Normalform (3NF)
3NF beseitigt transitive Abhängigkeiten. Eins-zu-Viele-Beziehungen helfen dabei, sicherzustellen, dass nichtschlüsselbasierte Attribute nur vom Primärschlüssel abhängen und nicht von anderen nichtschlüsselbasierten Attributen.
Zum Beispiel speichert eine Tabelle MitarbeiterID, AbteilungsID, und Abteilungsname, es besteht eine transitive Abhängigkeit (Mitarbeiter -> Abteilung -> Abteilungsname). Die Aufteilung in eine Mitarbeiter Tabelle und eine Abteilung Tabelle erstellt eine ein-zu-viele-Beziehung, die die Abhängigkeit auflöst.
🚧 Häufige Fehler, die vermieden werden sollten
Das Vermeiden von Fehlern in der Entwurfsphase spart erhebliche Zeit während der Entwicklung. Die folgenden Fehler werden häufig gemacht.
- Über-Normalisierung: Zu viele Tabellen können Abfragen komplex machen. Finden Sie einen Kompromiss zwischen Normalisierung und Abfrageleistung.
- Fehlende Fremdschlüssel: Sich auf die Anwendungslogik zur Durchsetzung von Beziehungen zu verlassen, ist riskant. Datenbankbeschränkungen sind die einzig wahre Quelle.
- Falsche Zulässigkeit von NULL-Werten: Fremdschlüssel sollten normalerweise
NICHT NULLsein, es sei denn, die Beziehung ist optional. EinNULLFremdschlüssel bedeutet keine Beziehung, was gegen Geschäftsregeln verstoßen könnte. - Datentypen-Abweichung: Stellen Sie sicher, dass der Datentyp des Fremdschlüssels genau dem Primärschlüssel entspricht. Die Verwendung von
VARCHARauf einer Seite undINTauf der anderen Seite bricht die Verbindung ab.
📉 Visuelle Darstellung im ERD
Klarheit im Diagramm ist ebenso wichtig wie die dahinterliegende Logik. Die visuelle Notation vermittelt die Struktur an Stakeholder, die möglicherweise keinen Code schreiben.
👣 Krähenfuß-Notation
Dies ist der häufigste Standard. Die eineSeite hat eine einzelne senkrechte Linie. Die vieleSeite hat einen Krähenfuß (drei verzweigte Linien).
- Kreis:Zeigt eine optionale Beziehung (0..N) an.
- Linie:Zeigt eine obligatorische Beziehung (1..N) an.
📐 Chen-Notation
Verwendet diamantförmige Formen für Beziehungen. Obwohl dies in modernen Werkzeugen weniger üblich ist, bietet es eine klare konzeptionelle Darstellung der Entitäten und ihrer Verbindungen.
🔄 Umgang mit weichen Löschungen
In vielen Systemen wird Daten niemals wirklich gelöscht. Stattdessen wird sie als inaktiv markiert. Dies wird als weiche Löschung bezeichnet.
🔍 Der Einfluss auf Beziehungen
Weiche Löschungen komplizieren ein-zu-viele-Beziehungen. Wenn ein Eltern-Element weich gelöscht wird, sollten die Kind-Elemente weiterhin verknüpft bleiben?
- Option 1:Übertrage das Flag für weiche Löschung auf alle Kinder.
- Option 2:Halte Kinder aktiv, verberge sie aber von Abfragen.
- Option 3:Erfordere eine separate Logik, um die Verknüpfung zu behandeln.
Designer müssen dies bei der Erstellung des Schemas entscheiden. Durch Hinzufügen einer deleted_atSpalte für Zeitstempel in beiden Tabellen sorgt für Konsistenz, ohne die relationale Verbindung zu unterbrechen.
📈 Überlegungen zur Skalierung
Wenn das Datenvolumen wächst, können ein-zu-viele-Beziehungen zu Engpässen werden. Eine geeignete Indizierung und Partitionierung sind erforderlich.
🖥️ Indizierungsstrategie
Indiziere immer die Fremdschlüsselspalte. Ohne Index erfordert das Verknüpfen der Tabellen eine vollständige Tabellen-Durchsuchung, was langsam ist.
- Gebundener Index:Der Primärschlüssel ist normalerweise gebunden.
- Nicht-gebundener Index: Der Fremdschlüssel sollte einen dedizierten Index haben.
🖥️ Partitionierung
Wenn die vielenWenn die Tabellenseite mit vielen Zeilen in Milliarden wächst, kann die Partitionierung nach dem Fremdschlüssel die Abfragegeschwindigkeit verbessern. Dadurch bleibt verwandte Daten physisch nahe beieinander auf dem Speichermedium.
📝 Zusammenfassung der wichtigsten Erkenntnisse
Datenmodellierung erfordert Präzision. Die Beziehung von einem zu vielen ist ein grundlegendes Bauelement, birgt aber auch Komplexität. Durch das Verständnis des Unterschieds zwischen identifizierenden und nicht-identifizierenden Beziehungen, die Verwaltung der Leistungskosten und die Einhaltung der Normalisierungsprinzipien können Architekten Systeme schaffen, die sowohl flexibel als auch zuverlässig sind.
- Fremdschlüssel auf der vielenSeite sollten nicht eindeutig sein.
- Referenzielle Integrität fügt Overhead hinzu, gewährleistet aber die Datenqualität.
- Weiche Löschungen erfordern eine sorgfältige Handhabung der Beziehungslinks.
- Konsistente Benennung und Indizierung sind entscheidend für die Wartung.
Das Ignorieren dieser Feinheiten führt zu instabilen Systemen. Die Akzeptanz der technischen Realitäten gewährleistet Langlebigkeit. Wenn Sie Ihr nächstes Schema entwerfen, überprüfen Sie diese Annahmen erneut. Überprüfen Sie die Kardinalität. Prüfen Sie die Einschränkungen. Bauen Sie mit Vertrauen.
🤔 Häufig gestellte Fragen
F: Kann eine Beziehung von einem zu vielen bidirektional sein?
A: In einer physischen Datenbank sind Beziehungen gerichtet (Elternteil zu Kind). In der Anwendungslogik können Sie die Beziehung jedoch in beide Richtungen durchlaufen. Die Datenbankengine stellt die Verbindung vom Kind zurück zum Elternteil sicher.
F: Erfordert eine Beziehung von einem zu vielen eine eindeutige Einschränkung?
A: Nein. Die Fremdschlüsselspalte muss Duplikate zulassen, um die vielenSeite der Beziehung zu unterstützen. Der Primärschlüssel auf der Elternteilseite muss eindeutig sein.
F: Wie handle ich zirkuläre Abhängigkeiten?
A: Zirkuläre Abhängigkeiten treten auf, wenn die Entität A auf B verweist und B zurück auf A. Dies ist bei hierarchischen Daten üblich. Verwenden Sie selbstreferenzierende Fremdschlüssel oder stellen Sie sicher, dass das Design keine unendlichen Schleifen in Abfragen erzeugt.
F: Ist eine Beziehung von einem zu vielen für Berichterstattung effizient?
A: Sie ist effizient für normalisierte Speicherung. Berichterstattung erfordert jedoch oft eine De-Normalisierung. Die Aggregation von Daten aus der Kindtabelle in die Elterntabelle für Berichts-Dashboards kann die Abfragekomplexität reduzieren.
F: Was passiert, wenn ich einen Elternteil lösche, ohne die Kinder zu behandeln?
A: Je nach Einschränkung blockiert das System die Löschung (Beschränken) oder löscht die Kinder automatisch (Kaskadieren). Falls keine Einschränkung existiert, können Sie verwaiste Datensätze erzeugen, die die Anwendungslogik stören.