











💡 关键要点
-
视觉清晰度: 逆向工程将复杂的源代码转化为可读的UML图表,揭示隐藏的架构。
-
依赖关系映射: 自动化分析可识别模块之间的关系,有助于重构和理解耦合性。
-
遗留系统现代化: 从现有代码库创建图表,弥合了技术债务与未来文档之间的差距。
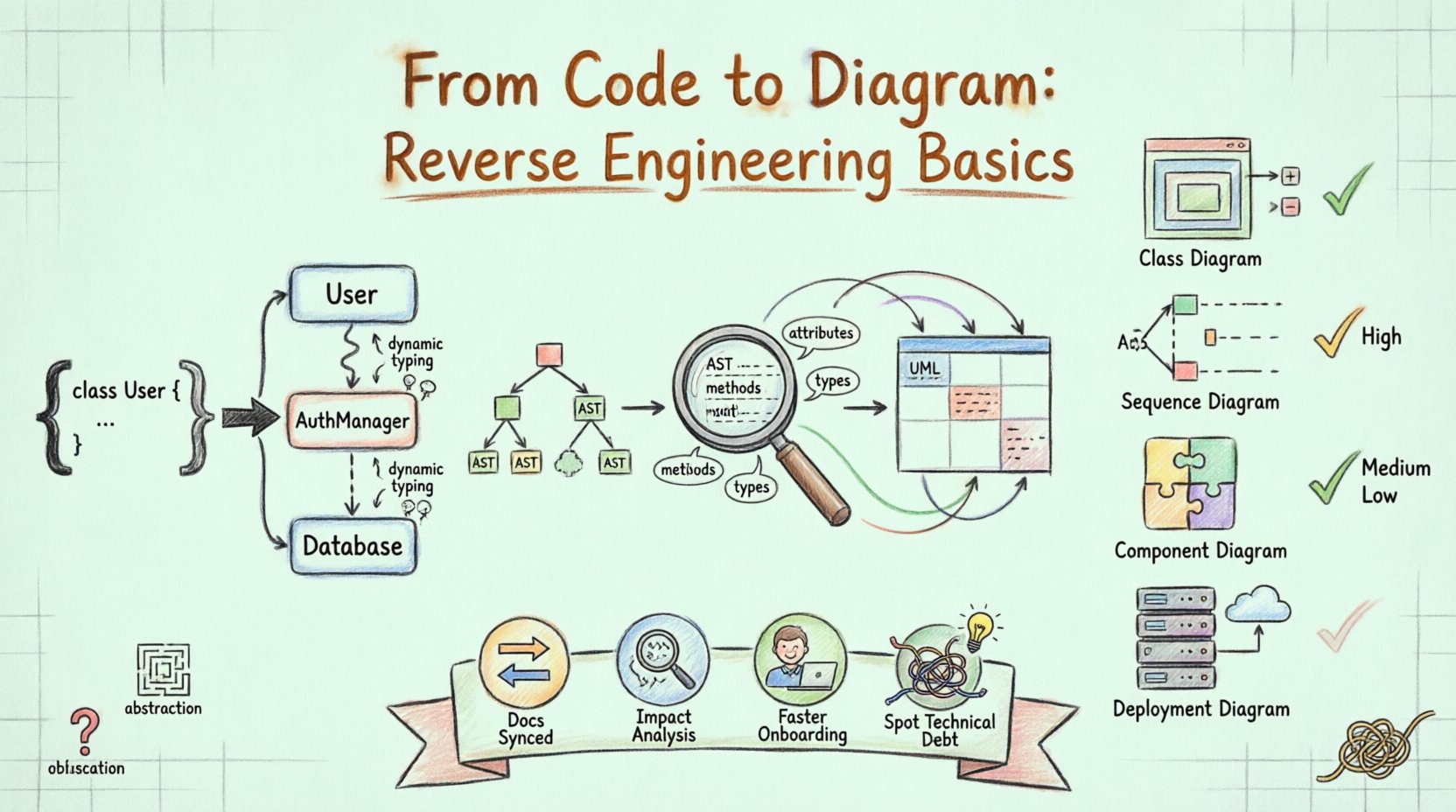
在软件开发领域,维护文档往往跟不上实现的速度。代码库不断增长,功能不断添加,原始的架构决策逐渐变得模糊。这正是逆向工程成为关键学科的原因。它涉及分析现有的源代码,以重建可视化的表示形式,通常使用统一建模语言(UML)图表。这一过程不仅仅是记录现有内容,更在于阐明组件之间的交互方式、依赖关系的位置以及系统的整体结构。
在UML背景下理解逆向工程 🧩
在软件开发中,逆向工程是分析一个系统以识别其组件及其相互关系的过程。当应用于UML时,目标是从实际实现中推导出图形化表示。与正向工程(其中图表指导代码编写)不同,逆向工程从代码出发,推导出图表。
这种方法对遗留系统尤其有价值,因为这些系统的文档可能已过时或根本不存在。通过解析源代码,工具可以提取类名、方法签名、继承层次结构和关联链接。这些元素构成了类图、序列图和组件图的基本构建块。
核心目标
主要目标是实现理解的状态。开发者经常遇到感觉像黑箱的遗留代码。逆向工程打开了这个黑箱,使团队能够在无需阅读每一行实现代码的情况下,可视化数据流和结构逻辑。它架起了代码具体现实与设计抽象概念之间的桥梁。
为什么要从代码生成图表? 📊
进行这一过程有多个战略原因。这不仅仅是制作漂亮的图片;更关乎降低风险和提升清晰度。
-
文档同步: 代码频繁变更。从代码生成的图表始终是最新状态,反映了系统的当前情况。
-
影响分析: 在重构某个模块之前,开发者需要知道哪些部分依赖于它。图表能清晰地突出这些依赖关系。
-
入职培训: 新成员通过查看图表,能比在文件仓库中逐个浏览更快地掌握系统架构。
-
识别技术债务: 复杂的结构通常在图表中表现为错综复杂的网络,突显出需要简化的区域。
逆向工程的过程 🔄
将代码转换为图表涉及一个系统化的工作流程。尽管具体实现方式各不相同,但逻辑步骤在各种环境中保持一致。
1. 解析与分析
第一步是读取源代码文件。系统解析语法以理解结构,识别类、接口、函数和变量。此阶段将原始文本转换为结构化数据格式,通常是抽象语法树(AST)。解析器必须具备语言感知能力,以正确解释所用编程语言的特定语法。
2. 元数据提取
代码解析完成后,系统会提取特定的元数据。这包括:
-
属性:类中的数据字段。
-
方法:函数及其访问修饰符(public、private、protected)。
-
类型:与属性和返回值相关联的数据类型。
-
关系:继承(extends/implements)、关联(使用)和聚合(组合)。
3. 映射到UML语义
提取的元数据必须映射到UML符号。例如,类定义映射到类图中的一个方框。函数内的方法调用映射到顺序图中的一个交互。这种映射需要逻辑推断。如果类A创建了类B的实例,系统将推断出一种关联或依赖关系。
4. 可视化与渲染
最后一步是将数据渲染为可视化格式。这包括将元素放置在画布上,并绘制线条以表示关系。布局算法试图组织图表,使其易于阅读,尽量减少线条交叉并分组相关组件。
常见生成的图表 📝
并非所有图表都同样适用于逆向工程。有些捕捉静态结构,而另一些则捕捉动态行为。
|
图表类型 |
关注点 |
在逆向工程中的实用性 |
|---|---|---|
|
类图 |
静态结构 |
高。可直接从代码中显示继承、属性和方法。 |
|
顺序图 |
动态行为 |
中等。需要追踪方法调用以理解交互流程。 |
|
组件图 |
系统模块 |
高。将类分组为逻辑单元或库。 |
|
部署图 |
基础设施 |
低。需要了解服务器配置,而不仅仅是代码。 |
过程中的挑战 ⚠️
虽然强大,但逆向工程并非没有困难。多个因素可能使生成准确的图表变得复杂。
抽象与隐藏
现代代码库严重依赖抽象。接口和多态性可能会掩盖实际的实现。一个方法可能在接口中定义,但在多个类中实现。可视化这一点需要同时展示契约和实现,这可能导致图表杂乱。
动态类型
支持动态类型的编程语言(变量类型在运行时确定)给静态分析带来了挑战。逆向工程工具可能难以在不执行代码或分析复杂控制流的情况下确定对象的确切类型。
代码混淆
在某些情况下,代码会被混淆以保护知识产权。代码压缩和变量重命名使得源代码对人类和机器都难以阅读。逆向工程混淆后的代码需要显著更复杂的分析技术。
复杂依赖
大型系统通常存在循环依赖或紧密耦合的模块。生成图表时,这些依赖关系可能造成“意大利面式”效应,导致线条杂乱交叉。通常需要人工干预来清理布局,并逻辑地分组相关元素。
确保准确性的最佳实践 ✅
为了确保生成的图表具有实用性,在逆向工程过程中应遵循某些实践。
-
过滤噪声:排除标准库或样板代码,这些代码会增加视觉杂乱但没有架构价值。应专注于自定义业务逻辑。
-
分组模块:使用包或命名空间来分组类。这可以防止图表变成一个巨大的单一节点。
-
验证关系:自动化工具有时会误解关系。应审查生成的链接,以确保它们准确反映代码逻辑。
-
迭代:逆向工程很少是一次性任务。随着代码库的演进,应定期重新生成并审查图表。
自动化的作用 🤖
对于大型项目,手动逆向工程是不切实际的。自动化是关键。自动化解析器扫描代码库,构建依赖关系图,并导出为 XMI 或 PlantUML 等标准格式。这使得团队能够将图表生成集成到其 CI/CD 流水线中。
自动化确保文档永远不会过时。如果开发者提交的更改破坏了依赖关系,图表生成过程可以标记出不一致之处。这种持续验证有助于长期保持系统完整性。
将图表融入维护工作 🛠️
一旦生成了图表,就应积极使用。它们不仅仅是用于展示。团队可以利用它们来规划重构工作。例如,如果类图显示某个类具有过多依赖,那么它就应被考虑进行分解。
此外,图表有助于代码审查。审查者可以在阅读差异之前,先查看所提议更改的结构影响。这将关注点从语法转移到架构,从而提升代码库的质量。
关于结构洞察的结论 🏁
将代码逆向工程为 UML 图表是维护复杂软件系统的基本实践。它将晦涩的代码转化为透明的架构,从而支持更好的决策和更清晰的沟通。尽管在动态类型和复杂依赖方面存在挑战,但同步文档带来的好处仍远超成本。通过优先考虑结构清晰性,团队可以自信地处理遗留系统,并精准地现代化其应用程序。