











Производительность базы данных часто остается незаметной, пока она не превращается в критический узкий участок. Когда пользователи сталкиваются с задержками, тайм-аутами или неработающими интерфейсами, истинная причина часто скрывается за пределами слоя приложения. Она заключается в архитектуре самих данных. Чертеж, который определяет, как структурируются, связаны и хранятся данные, — это диаграмма отношений сущностей (ERD). Хорошо продуманная ERD обеспечивает целостность данных и эффективный доступ к ним. Напротив, неудачная диаграмма вводит задержки, которые никакое кэширование на уровне приложения не может полностью устранить.
Это руководство предлагает глубокий анализ устранения медленных запросов путем анализа лежащей в основе схемы проектирования. Мы рассмотрим, как структурные решения в ERD напрямую влияют на планы выполнения запросов, операции ввода-вывода и общую отзывчивость системы. Понимая механику реляционного проектирования, вы сможете диагностировать проблемы производительности на их истинной причине, а не просто лечить симптомы.
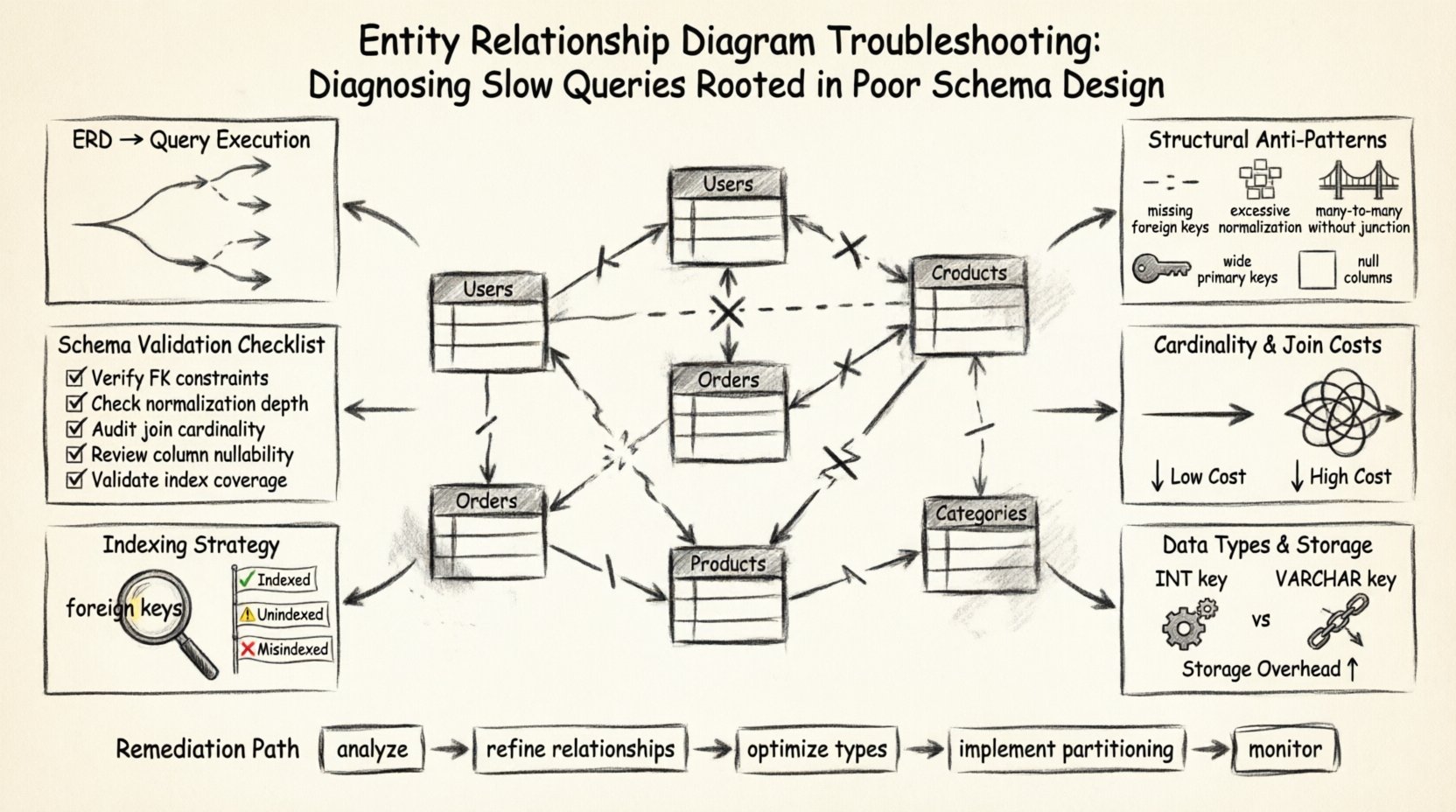
🏗️ Основа: как ERD влияют на выполнение запросов
Прежде чем диагностировать проблему, необходимо понимать связь между визуальным представлением данных и физическим выполнением команд. ERD — это не просто схема для документации; это набор правил, которые должна соблюдать база данных. Каждая линия, соединяющая таблицы, каждое определенное ограничение и каждый указанный тип данных определяют, как движок хранения читает и записывает информацию.
Когда запрос отправляется, оптимизатор базы данных анализирует его на основе метаданных схемы. Если схема неоднозначна или неэффективна, оптимизатор может выбрать неоптимальный путь. Это часто проявляется в полном сканировании таблицы вместо поиска по индексу или вложенных циклов соединения, которые экспоненциально увеличивают время обработки.
Ключевые области, в которых ERD влияет на производительность, включают:
- Сложность соединений: Количество определенных отношений определяет количество соединений, необходимых для получения связанных данных.
- Ограничения целостности данных: Внешние ключи и уникальные ограничения увеличивают накладные расходы при операциях записи, но могут оптимизировать операции чтения.
- Уровни нормализации: Степень, в которой данные разделяются между таблицами, влияет на объем данных, сканируемых при извлечении.
- Стратегия индексации: Проектирование схемы определяет, где логически можно разместить индексы для поддержки типичных шаблонов запросов.
🔍 Выявление структурных антипаттернов
Многие проблемы производительности возникают из-за паттернов, которые были допустимы на начальном этапе проектирования, но становятся проблемами по мере роста объема данных. Эти антипаттерны часто выглядят незаметно на схеме, но вызывают серьезные трудности в движке запросов. Ниже приведен анализ распространенных структурных недостатков и их прямого влияния на скорость.
| Антипаттерн | Визуальный индикатор на ERD | Влияние на производительность |
|---|---|---|
| Отсутствующие внешние ключи | Линии, соединяющие таблицы, без определения ограничений. | Позволяет существование «сиротских» записей, вынуждая сложные запросы вручную фильтровать недопустимые данные. |
| Чрезмерная нормализация | Большое количество таблиц с отношениями, состоящими из одного столбца. | Требует чрезмерного количества соединений для воссоздания одного логического объекта, увеличивая нагрузку на процессор. |
| Многие-ко-многим без промежуточной таблицы | Прямые линии отношений «многие-ко-многим» между двумя сущностями. | Движки баз данных обычно требуют промежуточной таблицы; её отсутствие приводит к неэффективным обходным решениям. |
| Широкие первичные ключи | Составные ключи с несколькими большими столбцами. | Увеличивает размер всех индексов, ссылающихся на этот ключ, замедляя поиск. |
| Столбцы с заполненными значениями NULL | Атрибуты, помеченные как допускающие NULL без логической причины. | Может препятствовать использованию индексов или снижать их выборочность, что приводит к полным сканированиям. |
🔗 Мощность отношений и стоимость соединений
Мощность определяет, сколько экземпляров одного объекта связаны с экземплярами другого. Это наиболее важный аспект ERD в отношении производительности запросов. Неправильные определения мощности заставляют систему обрабатывать больше строк, чем необходимо для выполнения запроса.
При устранении проблем с медленными запросами необходимо проверить, соответствуют ли отношения на диаграмме логическим требованиям приложения. Если отношение определено как «многие ко многим», тогда как оно должно быть «один ко многим», движок запросов будет готовиться к соединению через промежуточную таблицу, которая может не существовать или быть заполнена неэффективно.
Распространённые проблемы мощности отношений
- Неопределённая мощность:Если на диаграмме не указано, является ли отношение обязательным или необязательным, оптимизатор запросов может предположить худший сценарий, добавляя дополнительные проверки на наличие значений NULL.
- Рекурсивные отношения:Таблицы, ссылающиеся сами на себя (например, таблица сотрудников, ссылающаяся на себя для указания менеджера), могут вызывать глубокую вложенность в запросах. При отсутствии правильного индексирования столбца, ссылающегося на себя, такие запросы становятся экспоненциально медленнее.
- Циклические зависимости:Сложные сети отношений, где таблица A ссылается на B, B — на C, а C — обратно на A. Такая структура затрудняет обход графа данных для движка, часто приводя к созданию временных таблиц в памяти.
Чтобы смягчить эти проблемы, убедитесь, что ERD чётко различает необязательные и обязательные связи. Обязательные связи позволяют оптимизатору пропускать проверки на NULL, что ускоряет выполнение. Необязательные связи требуют дополнительной логики для обработки случаев, когда связь отсутствует.
📏 Типы данных и эффективность хранения
Выбор типов данных в определении схемы оказывает глубокое влияние на размер хранилища и скорость сравнения. Запрос, сравнивающий два столбца разных типов, часто вызывает неявные преобразования. Эти преобразования мешают использованию индексов и заставляют движок обрабатывать каждую строку.
Последствия хранения
Когда схема использует общий тип данных для всех столбцов, например, большой текстовый поле для коротких кодов, это потребляет больше места на диске и памяти. Это уменьшает эффективный размер буферного пула, что означает, что меньше «горячих» страниц данных можно хранить в памяти. В результате система должна читать больше данных с более медленной дисковой подсистемы.
Производительность сравнения
Сравнение целых чисел значительно быстрее, чем сравнение строк. Если ERD определяет внешний ключ как строку (например, VARCHAR), а не как целое число (например, INT), операция соединения должна сравнивать символ за символом, а не использовать бинарное числовое сравнение. Это добавляет циклы ЦП на каждую обрабатываемую строку.
- Используйте типы фиксированной длины: Для полей, таких как коды стран или флаги состояния, используйте строки фиксированной длины. Строки переменной длины вводят накладные расходы на вычисление длины при каждом чтении.
- Избегайте больших текстовых полей в ключах: Никогда не используйте столбец с большим объёмом текста в качестве первичного или внешнего ключа. Это увеличивает размер каждого индекса, ссылающегося на него.
- Соответствие типов родительской и дочерней таблиц: Убедитесь, что тип данных в дочерней таблице точно соответствует типу в родительской таблице. Даже небольшое различие (например, INT против BIGINT) может вызвать преобразование при соединениях.
🔑 Видимость индексации и стратегия
ERD — это визуальное представление логической структуры, но он также должен определять физическую стратегию индексации. Хотя индексы часто добавляются после создания схемы, на этапе проектирования следует заранее определить, где они нужны. Запрос, фильтрующий по столбцу, не имеющему индекса, является основным признаком недостатка в проектировании.
Возможности индексации в ERD
При анализе диаграммы на предмет узких мест производительности ищите столбцы, которые часто используются в условиях поиска или соединениях.
- Внешние ключи: Их почти всегда следует индексировать. Если запрос соединяет Table A с Table B по внешнему ключу, а ключ в Table B не проиндексирован, движку необходимо просканировать всю Table B для каждой строки в Table A.
- Флаги состояния: Столбцы, определяющие состояние записи (например, Is_Active, Order_Status), часто используются в предложениях WHERE. Если они не проиндексированы, фильтрация превращается в полное сканирование таблицы.
- Диапазоны дат: Таблицы с журналами аудита или журналами транзакций часто выполняют запросы по дате. Столбец даты должен быть проиндексирован, чтобы обеспечить эффективное сканирование диапазонов.
Критически важно сбалансировать количество индексов с производительностью записи. Каждый индекс добавляет накладные расходы на операции INSERT, UPDATE и DELETE. Однако плохо проиндексированная схема, ориентированная на чтение, вызовет задержки в системе, которые превысят стоимость записи. ERD помогает визуализировать, какие таблицы ориентированы на чтение (например, таблицы справочников), а какие — на запись (например, журналы транзакций), что направляет решение по индексации.
🚫 Патология соединений
Одной из наиболее распространённых причин медленных запросов является путь соединения. Это означает последовательность, в которой база данных соединяет таблицы для выполнения запроса. Плохо спроектированная схема может заставить движок выбирать путь, который логически правилен, но вычислительно затратен.
Декартово произведение
Если схема не имеет соответствующих ограничений или логика запроса не правильно указывает условия соединения, движок может создать декартово произведение. Это происходит, когда каждая строка в Table A комбинируется со всеми строками в Table B. Размер результата растёт экспоненциально, и запрос может завершиться таймаутом или потребить всю доступную память.
В ERD это часто происходит, когда связь «многие ко многим» не правильно посредничится через промежуточную таблицу, или когда промежуточная таблица не имеет необходимых внешних ключей.
Подзапрос против соединения
Проектирование схемы влияет на то, может ли запрос выполняться как простое соединение или требует подзапроса. Подзапросы часто выполняют внутренний запрос один раз для каждой строки внешнего запроса, что приводит к квадратичной временной сложности. Нормализованная схема, позволяющая прямые соединения, обычно предпочтительнее по сравнению с денормализованными структурами, которые вынуждают использовать подзапросы.
✅ Чек-лист проверки схемы
Чтобы систематически устранять проблемы с медленными запросами на основе ERD, выполните структурированный обзор. Этот чек-лист гарантирует, что вы проверите каждый критически важный компонент проектирования.
1. Проверьте ограничения внешних ключей
- Все ли внешние ключи явно определены на диаграмме?
- Включают ли они правила каскадного действия, которые могут привести к нежелательному перемещению данных?
- Одинаков ли тип данных с обеих сторон связи?
2. Проанализируйте частоту соединений
- Определите таблицы, которые чаще всего соединяются в логике приложения.
- Находятся ли эти таблицы рядом на диаграмме, или путь требует прохождения через несколько промежуточных таблиц?
- Можно ли объединить какие-либо из этих промежуточных таблиц, чтобы снизить глубину соединения?
3. Проверьте возможность NULL
- Столбцы, которые никогда не могут быть NULL, явно помечены как NOT NULL?
- Разрешает ли схема NULL-значения в столбцах, входящих в индекс?
4. Проверьте типы данных
- Используются ли числовые поля наименьшим подходящим размером (например, TINYINT вместо BIGINT)?
- Используются ли текстовые поля с правильной длиной, чтобы избежать обрезки или избыточного хранения?
5. Оценка охвата индексов
- Имеют ли первичные и внешние ключи индексы?
- Проиндексированы ли часто фильтруемые столбцы?
- Существует ли составной индекс для распространённых запросов с несколькими столбцами?
🛠️ Практические шаги по устранению
После анализа ERD и выявления проблем следующий этап — устранение недостатков. Это включает в себя изменение схемы для соответствия требованиям производительности без ущерба целостности данных.
Уточните отношения: Если ERD показывает чрезмерно сложные отношения, рассмотрите возможность их упрощения. Это может означать введение денормализации в конкретных областях, где преобладают операции чтения, для уменьшения необходимости в соединениях. Например, хранение кэшированного количества связанных элементов в родительской таблице может устранить необходимость постоянного соединения и подсчёта.
Оптимизируйте типы данных: Измените типы данных на более эффективные альтернативы. Если дата хранится только с точностью до дня, используйте тип только даты, а не дату и время. Если ID — числовое значение, убедитесь, что оно не хранится как строка.
Реализуйте партиционирование: Для очень больших таблиц ERD может потребовать отражения стратегии партиционирования. Хотя партиционирование часто является физической деталью реализации, логический дизайн должен учитывать, как группируется данные. Партиционирование по дате или региону позволяет движку сканировать только соответствующие сегменты данных.
🔎 Заключительные соображения
Устранение проблем производительности — это итеративный процесс. ERD служит центральным элементом в этом процессе. Рассматривая диаграмму как живой документ, отражающий как логическую структуру, так и физические ограничения производительности, вы можете поддерживать базу данных, которая останется отзывчивой при росте данных.
Помните, что нет единого решения, подходящего для всех сценариев. Схема, оптимизированная для частых операций записи, может работать иначе, чем схема, оптимизированная для сложных аналитических запросов. Цель — согласовать проектирование схемы с конкретными паттернами доступа к вашему приложению. Регулярно проверяйте ERD по фактическим метрикам производительности запросов, чтобы вовремя выявить отклонения.
Фокусируясь на структурной целостности модели данных, вы устраняете коренные причины задержек. Такой подход более устойчив, чем применение патчей на уровне приложения. Надёжная основа схемы гарантирует, что система сможет масштабироваться, адаптироваться и надёжно работать в течение длительного времени.
Продолжайте отслеживать планы выполнения запросов после внесения изменений. Визуализация плана выполнения может подтвердить, что оптимизатор правильно использует новые индексы и ограничения. Этот цикл обратной связи завершает процесс устранения неисправностей, обеспечивая, что теоретические улучшения в ERD превращаются в ощутимые приросты производительности в рабочей среде.