











Создание программного обеспечения для облака требует смены мышления. Традиционные монолитные архитектуры полагались на тесно связанные компоненты, разделяющие память и локальные файловые системы. Приложения, ориентированные на облако, однако, функционируют в распределённых средах, часто охватывающих несколько сетей и границ безопасности. Чтобы справиться с этой сложностью, инженерам необходимы чёткие визуальные представления о том, как информация перемещается по системе. Именно здесь диаграмма потоков данных (DFD) становится незаменимым инструментом. С помощью карты потока данных между процессами, хранилищами и внешними сущностями команды могут проектировать надёжные, масштабируемые и защищённые системы, не полагаясь на догадки.
В этом руководстве рассматриваются способы применения принципов DFD в контексте приложений, ориентированных на облако. Мы изучим основные компоненты, необходимые адаптации для распределённых систем и практические шаги по созданию диаграмм, которые будут полезны даже при развитии инфраструктуры. Независимо от того, проектируете ли вы экосистему микросервисов или цепочку функций без сервера, понимание перемещения данных является основой надёжной инженерии.
🌩️ Понимание смены парадигмы в моделировании приложений, ориентированных на облако
В традиционной локальной среде система часто существует в пределах одного физического контура. Данные перемещаются локально между процессами. В среде, ориентированной на облако, границы являются нестабильными. Одно логическое приложение может состоять из десятков независимых сервисов, работающих в контейнерах, оркестрируемых в разных регионах или зонах доступности. Задержки в сети, временная согласованность и политики безопасности вводят переменные, которых не существует в монолитных архитектурах.
При создании диаграммы потоков данных для такой среды необходимо учитывать:
- Границы сети:Данные часто проходят через публичные сети или защищённые VPC. Каждый переход представляет собой потенциальную точку отказа или задержку.
- Управление состоянием:Облачные сервисы часто являются безсостоятельными. Процессы должны получать состояние из внешних хранилищ, а не хранить его в памяти.
- Асинхронная коммуникация:Синхронные вызовы (запрос-ответ) не всегда являются наилучшим выбором. Очереди сообщений и потоки событий меняют способ перемещения данных между компонентами.
- Зоны безопасности:Данные, входящие в периметр, должны быть аутентифицированы и зашифрованы до того, как достигнут внутренних процессов.
Визуализация этих ограничений на ранних этапах предотвращает накопление архитектурного долга. Диаграмма, игнорирующая сегментацию сети или требования к безсостоятельности, приведёт к системе, которую трудно отлаживать и масштабировать. Цель заключается не просто в том, чтобы показать, куда идёт данные, но и в том, чтобы выделить, где он преобразуется, хранится и защищается.
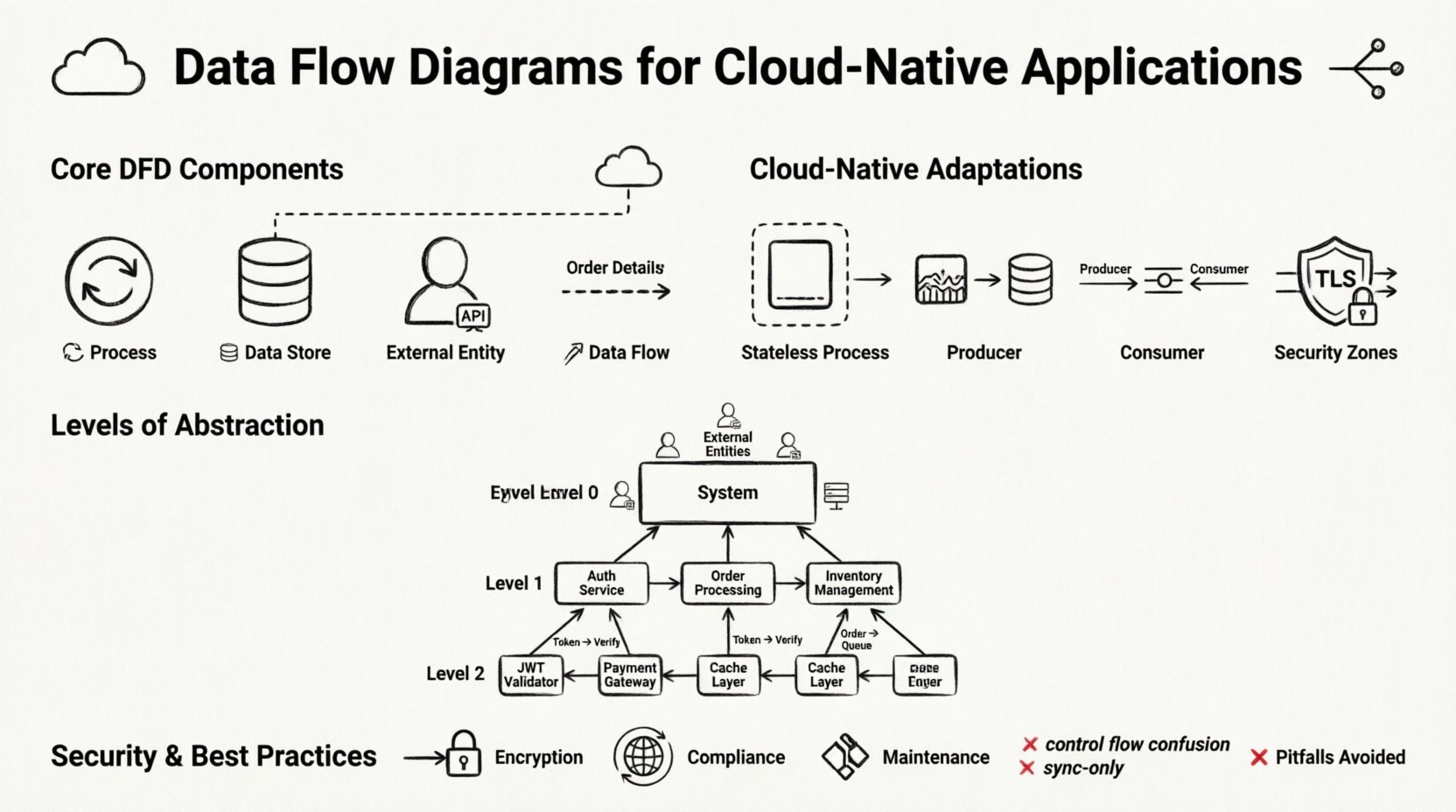
🧩 Основные компоненты диаграммы потоков данных
Прежде чем адаптировать эти диаграммы для облака, мы должны определить стандартные элементы построения. DFD — это не блок-схема; она не показывает логику управления или временные интервалы. Она показывает перемещение данных. Четыре основных элемента остаются неизменными, даже в распределённых системах.
1. Процессы 🔄
Процесс представляет собой деятельность, преобразующую входные данные в выходные. В контексте приложений, ориентированных на облако, процесс часто представляет собой функцию, приложение в контейнере или экземпляр микросервиса. Важно называть процессы в соответствии с их функцией, а не техническим названием. Например, вместо «API сервиса пользователей» используйте «Проверка учётных данных пользователя». Это позволяет сохранить фокус диаграммы на логике преобразования данных.
- Преобразование:Каждый процесс должен изменять данные каким-либо образом. Если данные проходят без изменений, они не должны представляться как процесс.
- Инкапсуляция:В микросервисах каждый процесс инкапсулирован. Внутренняя логика скрыта; для диаграммы важны только входные и выходные интерфейсы.
- Безсостоятельность:Большинство облачных процессов являются временным. Они не сохраняют память о предыдущих взаимодействиях. Это должно быть отражено в требованиях к потоку данных.
2. Хранилища данных 🗄️
Хранилище данных представляет собой место, где данные находятся в состоянии ожидания, пока не будут обработаны. В облаке это может быть реляционная база данных, хранилище документов NoSQL, бакет объектного хранилища или распределённый кэш. В отличие от файловой системы, облачные хранилища данных часто доступны по сети.
- Надёжность хранения:Данные должны быть сохранены в хранилище, если они должны сохраняться при сбое процесса или его перезапуске.
- Паттерны доступа: Хранилища с высокой нагрузкой на чтение отличаются от хранилищ с высокой нагрузкой на запись. Диаграмма должна указывать тип доступа, если он существенно влияет на архитектуру.
- Безопасность:Хранилища чувствительных данных требуют различных механизмов контроля доступа. Это различие имеет решающее значение для аудита безопасности.
3. Внешние сущности 👥
Внешние сущности — это источники или пункты назначения данных за пределами границ системы. К ним могут относиться человеко-пользователи, сторонние API, устаревшие системы или аппаратные устройства. На диаграмме, ориентированной на облачные технологии, внешние сущности часто представляют границу интернета или другие облачные сервисы.
- Доверенные и ненадежные:Различайте данные, поступающие от известного внутреннего сервиса, и трафик из публичного интернета.
- Инициирование:Сущности часто инициируют поток. Запрос пользователя запускает процесс; запланированная задача запускает синхронизацию данных.
4. Потоки данных 📡
Потоки данных — это стрелки, соединяющие компоненты. Они представляют передачу данных. В облачных средах эти потоки часто проходят через сети. Метки на стрелках имеют критическое значение. Они должны описывать пакет данных, а не протокол. Например, метку стрелки следует указывать как «Сведения о заказе», а не «HTTP POST». Это делает диаграмму независимой от протокола и будущей-доказуемой.
- Направленность:Потоки односторонние. Если данные перемещаются туда и обратно, необходимо нарисовать две отдельные стрелки.
- Объем:Потоки данных с высоким объемом могут требовать другой инфраструктуры (например, выделенной пропускной способности), по сравнению с потоками управления с низким объемом.
- Шифрование:Потоки, пересекающие границы безопасности, должны быть помечены как зашифрованные, чтобы подчеркнуть требования к соответствию.
☁️ Адаптация диаграмм потоков данных для распределенных систем
Стандартные диаграммы потоков данных предполагают единую систему. Облачные системы являются распределенными. Чтобы сделать диаграмму потоков данных полезной в этом контексте, необходимо явно моделировать распределенную природу инфраструктуры. Это включает добавление уровней абстракции, представляющих топологию сети и границы сервисов.
Границы сервисов
Микросервисы являются стандартными блоками для приложений, ориентированных на облачные технологии. Каждый сервис должен быть, как правило, отдельным процессом на диаграмме. Однако рисование каждого отдельного сервиса может привести к перегруженности. Распространенный подход — объединять связанные сервисы в логическую область, например, «Область биллинга» или «Область управления пользователями». Это позволяет увидеть общий поток, скрывая внутреннюю сложность.
Шлюзы API
Большинство приложений, ориентированных на облачные технологии, размещаются за шлюзом API или балансировщиком нагрузки. Этот компонент выступает единым точкой входа. На диаграмме потоков данных шлюз является процессом, который маршрутизирует запросы. Он обрабатывает аутентификацию, ограничение скорости и преобразование протоколов. Не следует рассматривать шлюз как простую трубу; он активно изменяет поток данных.
Архитектуры, основанные на событиях
Многие современные системы используют паттерны, основанные на событиях. Производитель генерирует событие, а потребитель обрабатывает его позже. Это разрывает синхронную связь между процессом и потоком данных. На диаграмме потоков данных это представляется с помощью очереди событий или потока как хранилища данных. Производитель записывает событие, а потребитель его читает. Такая декомпозиция критически важна для отказоустойчивости.
| Компонент | Традиционная монолитная архитектура | Адаптация для облачных технологий |
|---|---|---|
| Процесс | Функция в памяти | Контейнеризированный микросервис / функция без сервера |
| Хранилище данных | Локальный файл / SQL-база данных | Управляемая облачная база данных / объектное хранилище |
| Поток | Вызов локальной памяти | HTTP / gRPC / Очередь сообщений |
| Состояние | Общая память | Внешнее хранилище состояния |
📉 Уровни абстракции в архитектуре облачных систем
Сложные системы требуют нескольких уровней диаграмм. Попытка зафиксировать все детали в одном представлении приводит к путанице. Стандартный подход DFD уровней 0, 1 и 2 хорошо работает для облачных систем при правильном применении.
Уровень 0: Диаграмма контекста
Диаграмма контекста показывает всю систему как единый процесс. Она выделяет внешние сущности, взаимодействующие с системой. Для облачного приложения это определяет границы системы. Отвечает на вопрос: «Что входит в систему и что из неё выходит?» Это наиболее высокий уровень представления, полезный для заинтересованных сторон, которым нужно понять охват системы без технических деталей.
- Акцент:Границы системы и внешние интерфейсы.
- Детализация: Минимальная. Один центральный процесс.
- Сценарий использования:Определение масштаба проекта и стратегическое планирование безопасности на высоком уровне.
Уровень 1: Основные процессы
Уровень 1 разбивает центральный процесс на основные подпроцессы. В контексте облачных решений это обычно основные функциональные области. Например, диаграмма уровня 1 для платформы электронной коммерции может показать «Обработка заказов», «Управление запасами» и «Обработка платежей» как отдельные процессы. На этом уровне видно, как данные перемещаются между основными группами сервисов.
- Акцент:Основные функциональные модули и их взаимодействие.
- Детализация:Входы и выходы для каждого основного модуля.
- Сценарий использования:Архитектурный обзор и декомпозиция сервисов.
Уровень 2: Подробная логика
Уровень 2 углубляется в конкретные подпроцессы. Именно здесь становятся актуальными детали технической реализации. Например, процесс «Обработка платежей» может быть расширен до показа «Проверка карты», «Списание средств», «Обновление чека». Этот уровень используется разработчиками при реализации конкретных сервисов.
- Фокус: Внутренняя логика конкретных сервисов.
- Деталь: Конкретные преобразования данных и локальные хранилища данных.
- Сценарий использования: Реализация разработки и сценарии тестирования.
🔒 Безопасность и соответствие требованиям при сопоставлении данных
Безопасность не является дополнительной задачей при разработке приложений для облака; это требование к проектированию. Диаграмма потоков данных — отличный инструмент для выявления рисков безопасности. Отслеживая путь данных, вы можете обнаружить, где конфиденциальная информация может быть раскрыта или неправильно хранится.
Определение конфиденциальных данных
Не все потоки данных одинаковы. Персональные данные (PII), финансовые записи и медицинские данные требуют более строгого обращения. В вашей диаграмме отметьте потоки, содержащие конфиденциальные данные. Это гарантирует, что каждый процесс, работающий с такой информацией, будет проверен на соответствие требованиям.
- Шифрование в процессе передачи: Потоки, пересекающие границы сети, должны быть зашифрованы (TLS/SSL). Четко отметьте эти потоки.
- Шифрование при хранении: Хранилища данных, содержащие конфиденциальную информацию, должны быть зашифрованы. Укажите это в метке хранилища данных.
- Контроль доступа: Определите, какие процессы имеют разрешение на чтение или запись в конкретные хранилища данных. Это помогает настроить управление доступом на основе ролей (RBAC).
Границы соответствия
В разных регионах действуют разные законы о суверенитете данных. Данные могут быть обязаны оставаться в пределах определенной географической границы. Диаграмма потоков данных помогает визуализировать эти ограничения. Если процесс в регионе А отправляет данные в регион Б, этот поток должен быть помечен для юридической проверки. Это предотвращает случайные нарушения таких норм, как GDPR или CCPA.
⚠️ Распространённые ошибки и как их избежать
Создание диаграмм потоков данных для облачных систем — непростая задача. Существуют распространённые ошибки, которые команды допускают, часто пытаясь перенести старые паттерны в новые среды. Избегание этих ошибок гарантирует, что ваши диаграммы останутся точными и полезными.
1. Смешивание управления и потока данных
Диаграммы потоков данных не должны отображать логику управления. Не рисуйте стрелки, чтобы показать «если это, то то». Используйте точки принятия решений или внешние примечания для логики, но оставьте стрелки направленными на перемещение данных. В облачных системах, где логика управления часто обрабатывается платформами оркестрации, диаграмма потоков данных должна фокусироваться на содержимом (payload).
2. Пренебрежение асинхронными потоками
Облачные системы редко бывают полностью синхронными. Задачи выполняются в фоновом режиме. Если вы рисуете только синхронные потоки запрос-ответ, ваша диаграмма будет неполной. Всегда включайте фоновые задачи и потоки событий как потоки данных, входящие в хранилища данных или выходящие из них.
3. Избыточная оптимизация под конкретные инструменты
Не проектируйте свою диаграмму, исходя из возможностей конкретного инструмента или платформы. Если вы выберете конкретную базу данных или брокер сообщений, диаграмма может устареть при переходе на другие технологии. Сосредоточьтесь на логическом потоке данных, а не на физической реализации.
4. Пренебрежение потоками ошибок
Успешные пути легко изобразить. Пути с ошибками сложнее, но необходимы. В облачной среде сервисы часто выходят из строя. Укажите, где фиксируются данные об ошибках или запускаются механизмы повторных попыток. Это помогает разрабатывать надежные системы мониторинга и оповещения.
🔄 Обновление диаграмм с течением времени
Диаграмма полезна только в том случае, если она точна. Приложения для облака быстро меняются. Добавляются новые сервисы, устаревают старые, эволюционируют модели данных. Если диаграмма не соответствует работающей системе, она становится вводящей в заблуждение документацией. Вот как их поддерживать.
- Контроль версий:Рассматривайте диаграммы как код. Храните их в системе контроля версий вместе с кодом приложения. Это обеспечивает историю и отслеживаемость.
- Циклы проверки:Включайте обновления диаграмм в процесс проверки кода. Если разработчик изменяет поток данных, диаграмма должна быть обновлена в том же коммите или запросе на вливание.
- Автоматическая генерация: Где возможно, генерируйте диаграммы из кода или определений инфраструктуры как кода. Это сокращает разрыв между документацией и реальностью.
- Согласование с заинтересованными сторонами: Регулярно обсуждайте диаграммы с заинтересованными сторонами, не являющимися техническими специалистами. Это гарантирует, что уровень абстракции соответствует аудитории.
📋 Сравнение DFD с другими архитектурными представлениями
Часто путают DFD с другими диаграммами, такими как диаграммы последовательности или диаграммы архитектуры системы. Понимание различий помогает выбрать правильный инструмент для решения задачи.
| Тип диаграммы | Основное внимание | Наилучшее применение |
|---|---|---|
| Диаграмма потоков данных | Перемещение и преобразование данных | Проектирование системы, аудит безопасности, сопоставление данных |
| Диаграмма последовательности | Взаимодействие между объектами по времени | Интеграция API, отладка цепочек вызовов |
| Архитектура системы | Инфраструктура и развертывание | DevOps, масштабирование, требования к оборудованию |
| Сущность-связь | Структура данных и отношения | Проектирование баз данных, планирование схем |
DFD дополняет эти представления. В то время как диаграмма архитектуры показывает, где расположены серверы, DFD показывает, как информация перемещается между ними. В то время как диаграмма последовательности показывает порядок вызовов, DFD показывает нагрузку. Использование их вместе даёт полную картину системы.
🚀 Будущие тенденции в моделировании облачных систем
По мере развития облачных технологий меняются и требования к моделированию. Рост безсерверных вычислений и вычислений на краю сети порождает новые вызовы. Потоки данных становятся более децентрализованными. Процессы выполняются ближе к пользователю. Этот сдвиг требует, чтобы DFD учитывали узлы на краю сети и временные вычислительные ресурсы.
Более того, интеграция искусственного интеллекта в рабочие процессы добавляет сложности. Модели ИИ потребляют данные и генерируют ценную информацию. Эти процессы часто требуют больших объёмов данных и специализированного оборудования. Будущие DFD должны отображать эти вычислительно интенсивные процессы и каналы данных, питающие их. Основные принципы остаются неизменными, но детализация и масштаб будут расширяться.
Соблюдая основы диаграмм потоков данных, одновременно адаптируясь к реалиям облачных систем, команды инженеров могут создавать системы, которые прозрачны, безопасны и масштабируемы. Визуализация данных — это не просто документирование; это критически важный этап проектирования, предотвращающий ошибки до их попадания в производство.