











ソフトウェアの配信は、過去20年間で大きく進化しました。硬直的な段階と膨大な初期文書化が特徴の従来のウォーターフォールモデルは、ほとんどが反復的で継続的なアプローチに置き換わりました。この現代的な環境において、データフローダイアグラム(DFD)その関連性についてしばしば疑問視されることがあります。批判者は、静的な図はアジャイルおよびDevOps文化に内在する変化の速さに対応できないと主張します。しかし、適切に調整された場合、これらの視覚的モデルはシステムの論理を理解し、ボトルネックを特定し、セキュリティ準拠を確保するための重要なツールとして機能し続けます。
このガイドでは、データフローダイアグラムを高速な環境に効果的に統合する方法を探ります。DFDの核心的な構成要素、アジャイルの儀式内での具体的な応用、DevOpsパイプラインにおける役割、開発の速度を落とさずに正確性を維持するための戦略について検討します。
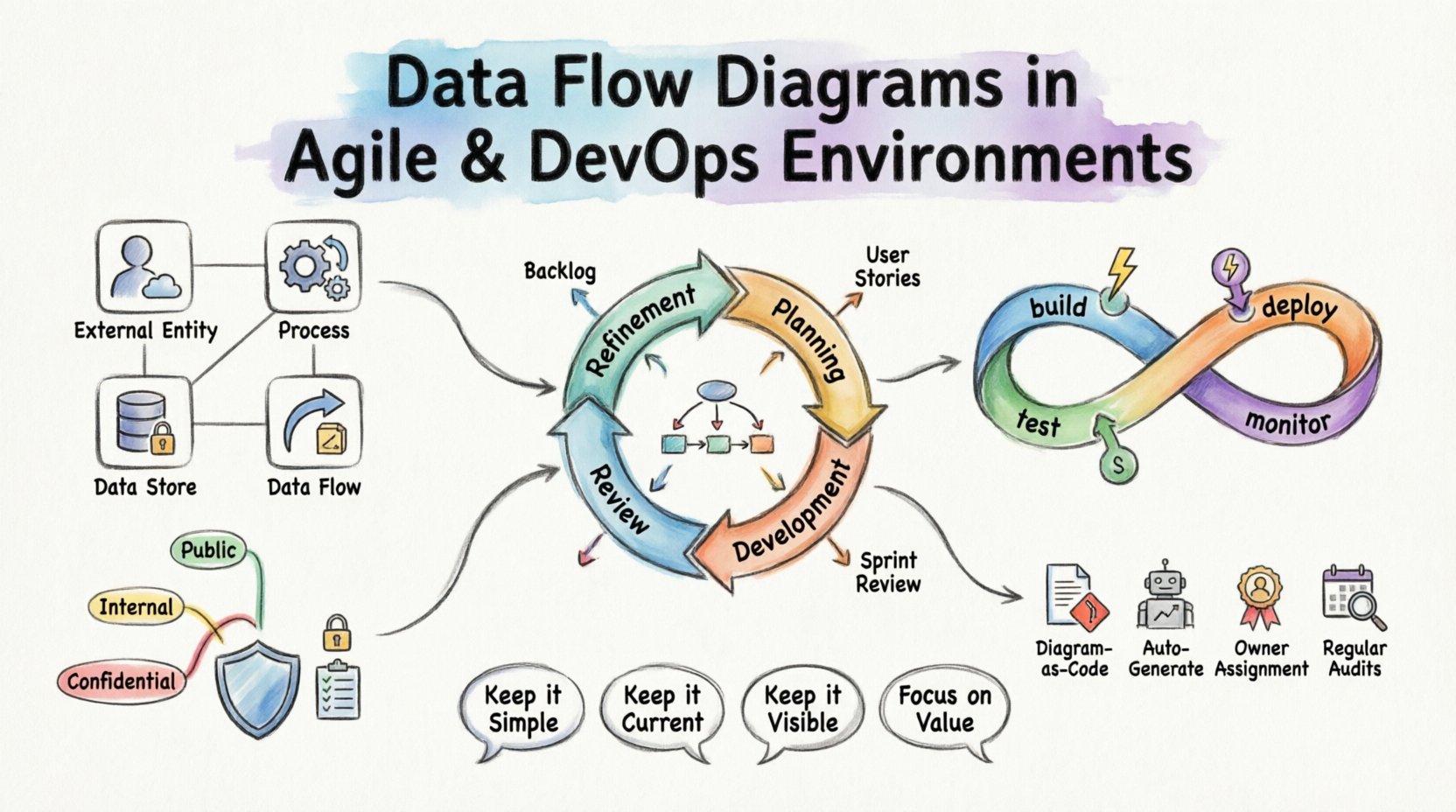
DFDの核心的な構成要素を理解する 🧩
DFDを現代のワークフローに統合する前に、記法について共有された理解を確立する必要があります。データフローダイアグラムは、データがシステム内でどのように移動するかをマッピングします。制御フローまたはタイミングに注目するのではなく、情報の変換と保存に焦点を当てます。
標準的なDFDは、4つの主要な要素で構成されます:
- 外部エンティティ:システム境界外のデータの発信元または受信先(例:ユーザー、他のシステム、ハードウェアデバイス)。
- プロセス:入力データを出力データに変換する変換。これらは論理またはビジネスルールを表します。
- データストア:データが静止状態で保持されるリポジトリ(例:データベース、ファイルシステム、キュー)。
- データフロー:データがエンティティ、プロセス、ストアの間を移動する経路。
これらの構成要素を可視化することで、チームは情報がアーキテクチャをどのように通過するかについて一致した理解を持つことができます。複雑なシステムでは、データが断片化されたり、見えにくくなったりすることがあります。明確な図は、これらの経路を直ちに明らかにします。
アジャイルの文脈:ドキュメントを生き生きとしたアーティファクトとして 📝
アジャイル手法は、包括的なドキュメントよりも動作するソフトウェアを優先します。この原則は、アーキテクチャ図の放棄につながることもあります。しかし、視覚的ドキュメントを完全に省略すると、知識の孤島が生じる可能性があります。重要なメンバーが退職したり、新しいメンバーが加入したりした際、参照ポイントがなければ、システムのデータ論理を理解することが難しくなります。
アジャイル環境では、DFDは静的な成果物から生き生きとしたアーティファクトへと進化しなければなりません。それらは、ユーザー・ストーリーと並行して段階的に更新されるべきです。
スプリントとの統合
DFDがスプリントサイクルにどのように適合するかを検討しましょう:
- 精査:バックログの精査中に、チームは新規ストーリーをレビューします。高レベルのDFDは、異なるデータストアや外部システム間の依存関係を特定するのに役立ちます。
- 計画:ストーリーを分解する際、開発者はDFDを参照して入力要件と出力の期待を理解できます。
- 開発:コードが書かれるにつれて、図は健全性の確認として機能します。実装は設計されたフローと一致していますか?
- レビュー:スプリントレビューの際、更新された図はステークホルダーに新しい機能の視覚的確認を提供します。
詳細レベル
すべての図が必要として深い掘り下げがあるわけではない。異なる抽象化レベルはそれぞれ異なる目的に適している:
| レベル | 焦点 | 最も適した使用者 |
|---|---|---|
| コンテキスト図 | システム境界と外部の相互作用 | 関係者、プロダクトオーナー |
| レベル0(上位レベル) | 主要なプロセスとデータストア | アーキテクト、シニア開発者 |
| レベル1(詳細) | 特定の論理とサブプロセス | 開発者、QAエンジニア |
アジャイルチームでは、レベル0またはコンテキスト図を維持するだけで、上位レベルの整合性を図るのに十分であることが多い。詳細なレベル1図は、特定の機能に複雑なデータ変換ロジックが必要な場合にのみ作成すべきである。
DevOpsと自動化:パイプラインのマッピング 🚀
DevOpsはソフトウェア配信プロセスの自動化に注力する。これには継続的インテグレーションと継続的デプロイメント(CI/CD)が含まれる。CI/CDパイプラインはコードの移動を自動化するが、アプリケーション内部でのデータの移動は依然として重要な課題である。
DevOpsの文脈におけるデータフローダイアグラムは、アプリケーション層とインフラストラクチャ層の相互作用を可視化するのに役立つ。
ボトルネックの特定
パフォーマンスの問題は計算よりもデータ処理に起因することが多い。データフローをマッピングすることで、チームは以下を特定できる:
- 不要な転送:キャッシュ可能またはローカルで処理できるのに、サービス間を移動しているデータ。
- 遅延ポイント:ユーザー操作をブロックする同期呼び出し。
- 大量処理:パイプラインを通過する大規模なデータセットで、ネットワーク帯域を飽和させる可能性がある。
CI/CDパイプラインの統合
自動テスト戦略はDFDを活用してデータ整合性を確保できる。新しいサービスをデプロイする際、自動チェックによりデータフローが定義された図と一致しているかを検証できる。
- コントラクトテスト:プロセスの入力と出力が、フローで定義された期待されるスキーマと一致していることを確認する。
- 依存関係スキャン:データストアへの変更が下流のコンシューマーを破壊しないことを確認する。
- セキュリティスキャン:機密データが不安全なチャネルを通じて流れているかどうかを確認する。
セキュリティおよびコンプライアンスの考慮事項 🛡️
データセキュリティは、現代のソフトウェア配信における主要な懸念事項です。GDPRやHIPAAなどの規制では、個人データがどこに保存され、どのように処理されるかについて厳格な制御が求められます。DFDは、コンプライアンスを証明する上で重要な役割を果たします。
データ分類
図を作成する際には、データフローに機密性レベルを付与すると便利です。これにより、セキュリティチームは保護対策の優先順位を決定できます。
- 公開データ:特別な暗号化は不要。
- 内部データ:送信中は暗号化され、アクセス制御される。
- 機密データ:保存時および送信中ともに暗号化され、アクセスログは厳格に管理される。
機密データの移動先を可視化することで、チームは第三者のサービスや承認のない外部エンティティに意図せず暴露されないよう確保できます。
アクセス制御のマッピング
DFDは、最小権限の原則を明確にするのに役立ちます。図にプロセスがデータストアにアクセスしていることが示されている場合、そのプロセスが使用するサービスアカウントが必要な権限しか持たないことを確認できます。
正確性の維持:陳腐化した図の罠を避ける 🔄
現代の環境におけるDFDの最も一般的な失敗要因は陳腐化です。初期設計段階で作成された図は、最初のスプリントが終了した段階ですでに不正確になることがよくあります。陳腐化した図は、開発者を誤解させ、誤った仮定を生み出すため、まったく図がないよりも悪影響を及ぼします。
同期のための戦略
図が陳腐化するのを防ぐため、チームは特定の保守戦略を採用しなければなりません。
- 図をコードとして扱う:図の定義をアプリケーションコードと一緒にバージョン管理に保存する。これにより、変更はプルリクエスト経由でレビューできる。
- 自動生成:可能な限り、コードベースまたはインフラ定義から図を自動生成する。これにより、視覚的な表現が実際のデプロイメントと一致することを保証できる。
- 所有者割り当て: 図のセクションに対して特定の所有者を割り当てる。機能が変更された際には、所有者が関連するフローを更新する責任を負う。
- 定期的な監査:アーキテクチャ図の四半期ごとのレビューをスケジュールする。本番環境を正確に反映していることを確認する。
チーム間の連携 🤝
データフローダイアグラムは単なる技術文書ではなく、コミュニケーションツールです。開発、運用、セキュリティ、ビジネス関係者との間のギャップを埋める役割を果たします。
開発と運用の整合性
開発者は機能性に注目しがちですが、運用チームは安定性と稼働時間に注目します。DFDは運用チームがデータ量の急増が発生する場所を理解するのを助けます。また、開発者は復旧に際してデータの永続性が重要な場所を理解するのに役立ちます。
セキュリティチームの統合
セキュリティチームはDFDを用いて脅威モデリングを行うことができます。すべての入力ポイント(外部エンティティ)とすべての保存ポイント(データストア)を特定することで、潜在的な攻撃ベクトルを体系的に評価できます。
ビジネス関係者の可視化
技術的知識のない関係者にとって、コンテキスト図は有益です。技術的な実装の詳細に巻き込まれることなく、ビジネスの入力がどのようにビジネスの出力に結びつくかを把握できます。これにより、信頼関係が深まり、期待が明確になります。
一般的な課題と解決策 🛠️
アジャイルおよびDevOps環境にDFDを導入することは、課題を伴います。以下に一般的な問題と実用的な解決策を示します。
| 課題 | 影響 | 解決策 |
|---|---|---|
| 図の複雑さ | 詳細が多すぎると、図が読みにくくなります。 | 抽象化レイヤーを使用する。詳細は要求されるまで隠す。 |
| ツールの使いにくさ | エディタが遅い、または別途ライセンスが必要な場合がある。 | 軽量で共同作業が可能な、テキストベースのツールを使用する。 |
| 時間の消費 | 図の作成に時間がかかり、コーディングの時間に影響する。 | 高価値の図のみに注力する。他の図は自動化する。 |
| バージョンの衝突 | 複数の人が同じ図を編集している。 | 厳格なバージョン管理とブランチングを導入する。 |
ステップバイステップの導入ガイド 📍
現在のワークフローにデータフローダイアグラムを導入または再導入したい場合、以下の構造化されたアプローチに従ってください。
ステップ1:現在の状態を評価する
まず、既存の文書を確認してください。どのデータフローが既に理解されているか、どこにギャップがあるかを特定します。既存の図が実際に役立つほど正確かどうかを判断します。
ステップ2:範囲を定義する
一度に企業全体を図示しようとしないでください。特定のサービスや重要な機能から始めましょう。システムの境界を明確に定義してください。
ステップ3:コンテキスト図の作成
最も高いレベルの視図を作成する。外部エンティティおよび主要なデータ入力と出力を特定する。より詳細な作業に進む前に、ステークホルダーの承認を得る。
ステップ4:プロセスの分解
主要なプロセスをサブプロセスに分解する。関与するデータストアをマッピングする。すべてのフローが明確な開始点と終了点を持つことを確認する。
ステップ5:レビューと検証
開発チームとウォークスルーを行う。データが入力されてから出力されるまでの経路を追跡できるか確認する。追跡できない場合、図は不完全である。
ステップ6:ワークフローへの統合
図をイシュー追跡システムにリンクする。プルリクエストに図のURLを参照させる。データパスを変更する機能に関しては、完了定義の必須項目とする。
データフロー可視化の未来 🔮
システムがより分散化され、イベント駆動型になると、データフローの性質が変化する。マイクロサービスやサーバーレスアーキテクチャは、静的に可視化しにくい一時的なプロセスを導入する。動的マッピングの重要性が高まっている。
将来の実装では、ランタイムのテレメトリを活用して図を自動更新する可能性がある。観測性ツールはログやメトリクスをインプットし、リアルタイムのデータ経路を表示できる。これにより、DFDは設計資産からモニタリング資産へと移行する。
その日まで、手動でのメンテナンスが不可欠である。DFDを正確に保つために必要な規律は、コード品質やシステム理解の向上につながる。視覚的な明確性に投資するチームは、デバッグが速くなり、オンボーディングが容易になることが多い。
チーム向けの主な教訓 📌
- シンプルを心がける:複雑すぎる図は無意味である。タスクに必要なレベルの詳細に留まる。
- 常に最新を保つ:古くなった図は危険である。更新を自動化するか、所有者を割り当てる。
- 目に見える場所に置く:図をチームが見られる場所に置く。埋もれたドキュメントリポジトリにしまわない。
- 価値に注目する:オンボーディング、セキュリティ監査、依存関係マッピングなど、特定の問題を解決する図だけを作成する。
データフロー図は、システムの挙動を理解するための強力なツールのままである。アジャイルおよびDevOps環境では、軽量で協働的であり、日常のワークフローに統合される必要がある。静的な資産ではなく、生きている文書として扱うことで、チームは速度を損なわずにデータ環境の明確な視覚化を維持できる。
目標は文書の完璧さではなく、理解の明確さである。データの流れを全員が理解しているとき、システムはよりレジリエントで、安全かつ効率的になる。この共有された理解こそ、高パフォーマンスを発揮するエンジニアリングチームの基盤である。