











データベースのパフォーマンスは、問題が深刻なボトルネックになるまでしばしば目に見えない。ユーザーが遅延、タイムアウト、応答なしのインターフェースを経験するとき、根本原因はアプリケーション層の表面下に存在することが多い。それはデータそのもののアーキテクチャにある。データがどのように構造化され、関連付けられ、保存されるかを規定する設計図がエンティティ関係図(ERD)である。適切に作成されたERDは、データの整合性と効率的な取得を保証する。逆に、不完全な図は、アプリケーションレベルのキャッシュをいくら用いても完全に解消できない遅延を引き起こす。
このガイドでは、下位のスキーマ設計を分析することで、遅延クエリのトラブルシューティングについて深く掘り下げます。ERD内の構造的決定が、クエリ実行計画、I/O操作、全体的なシステム応答性にどのように直接影響するかを検討します。リレーショナル設計のメカニズムを理解することで、症状の対処ではなく、問題の根本原因を特定できるようになります。
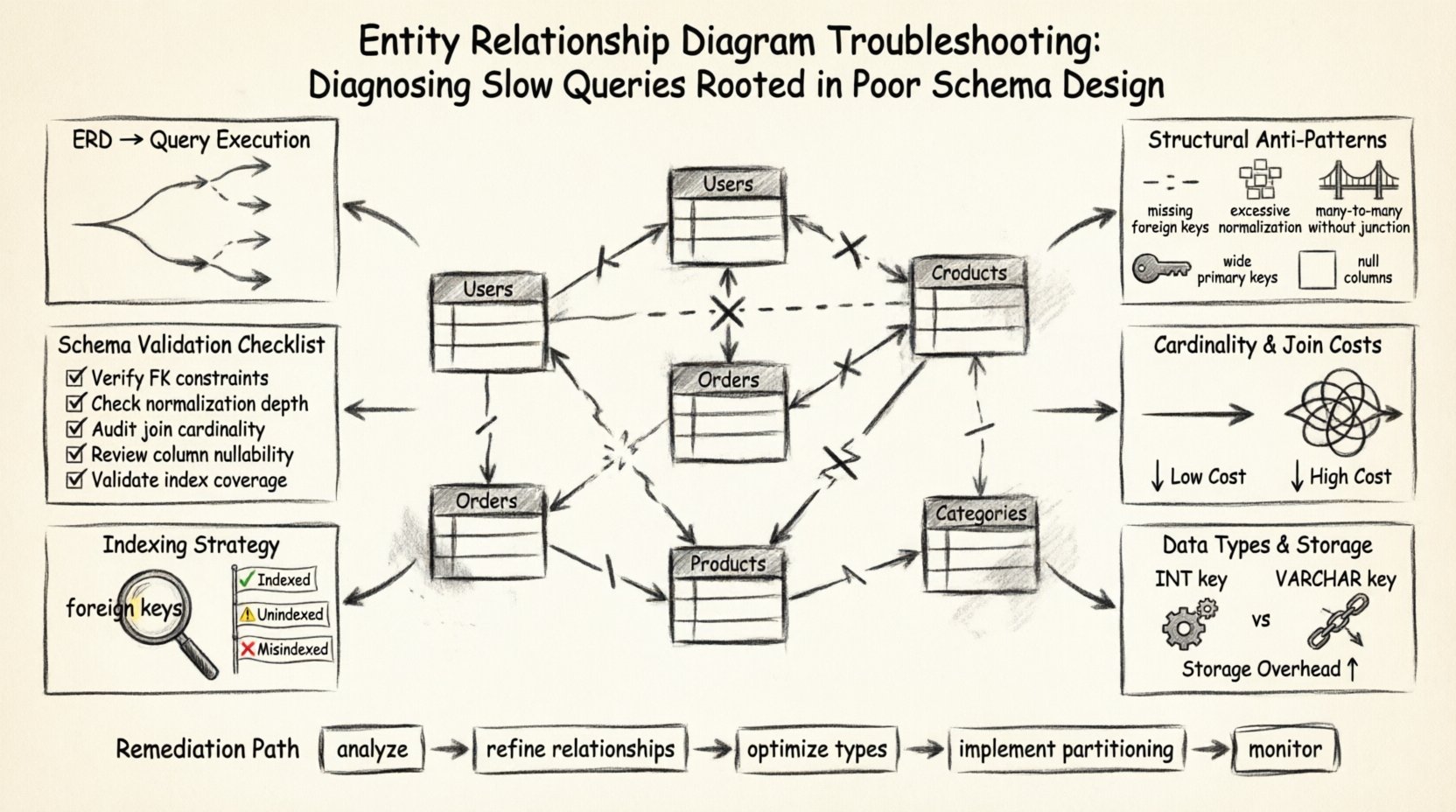
🏗️ 基盤:ERDがクエリ実行に与える影響
問題を診断する前に、データの視覚的表現とコマンドの物理的実行との関係を理解することが不可欠です。ERDは文書化のための単なる図面ではなく、データベースエンジンが強制しなければならないルールの集合です。テーブル間のすべての線、定義されたすべての制約、指定されたすべてのデータ型が、ストレージエンジンが情報を読み書きする方法を決定します。
クエリが送信されると、データベースオプティマイザはスキーマメタデータに基づいてリクエストを分析します。スキーマが曖昧または非効率な場合、オプティマイザは最適でないパスを選択する可能性があります。これは、インデックスシークではなくフルテーブルスキャンが発生する、または処理時間を指数関数的に増大させるネストループ結合が発生する形で現れます。
ERDがパフォーマンスに影響を与える主な領域には以下が含まれます:
- 結合の複雑さ: 定義された関係の数が、関連データを取得するために必要な結合の数を決定する。
- データ整合性制約: 外部キーと一意制約は書き込み操作にオーバーヘッドを加えるが、読み込み操作を最適化できる。
- 正規化レベル: データがテーブル間でどれだけ分割されるかの度合いが、取得時にスキャンされるデータ量に影響する。
- インデックス戦略: スキーマ設計が、一般的なクエリパターンをサポートするために論理的にインデックスを配置できる場所を決定する。
🔍 構造的アンチパターンの特定
多くのパフォーマンス問題は、初期設計段階では許容可能だったパターンに起因するが、データ量が増加するにつれて負債となる。これらのアンチパターンは図面ではしばしば微妙に見えるが、クエリエンジンでは顕著な摩擦を引き起こす。以下に、一般的な構造的欠陥とその速度への直接的な影響を説明する。
| アンチパターン | ERDにおける視覚的インジケータ | パフォーマンスへの影響 |
|---|---|---|
| 外部キーの欠落 | 制約定義のないテーブルをつなぐ線。 | 孤立したレコードを許可し、複雑なクエリが無効なデータを手動でフィルタリングする必要を強いる。 |
| 過剰な正規化 | 単一カラムの関係を持つ多数のテーブル。 | 単一の論理的エンティティを再構成するために過剰な結合が必要となり、CPU使用量が増加する。 |
| 結合テーブルなしの多対多 | 2つのエンティティ間の直接的な多対多関係の線。 | データベースエンジンは通常、ブリッジテーブルを必要とするが、これを欠くと非効率な代替手段が発生する。 |
| 広いプライマリキー | 複数の大きな列を含む複合キー。 | このキーを参照するすべてのインデックスのサイズを増加させ、検索を遅くする。 |
| NULL値で埋められた列 | 論理的な理由なくNULLを許容する属性。 | インデックスの使用を妨げたり、インデックスの選択性を低下させたりし、フルスキャンを引き起こす可能性がある。 |
🔗 関係の基数と結合コスト
基数は、あるエンティティのインスタンスが別のエンティティのインスタンスと関連する数を定義する。これはクエリパフォーマンスに関するERDの最も重要な側面である。誤った基数定義は、クエリを満たすために必要な行よりも多くの行を処理させることをシステムに強いる。
遅いクエリをトラブルシューティングする際には、図上の関係がアプリケーションの論理的要件と一致していることを確認しなければならない。もし、1対多であるべき関係が多対多として定義されている場合、クエリエンジンは存在しないか、非効率にデータが入力された結合テーブルを介した結合を準備することになる。
一般的な基数の問題
- 基数が定義されていない: 図が関係が必須かオプションかを明示していない場合、クエリオプティマイザは最悪のシナリオを仮定し、NULL値の追加チェックを加える可能性がある。
- 再帰的関係: 自己参照テーブル(例:マネージャーを参照するために自身を参照するEmployeeテーブル)は、クエリに深いネストを引き起こす可能性がある。自己参照列に適切なインデックスがなければ、これらのクエリは指数関数的に遅くなる。
- 循環依存: Table AがBにリンクし、BがCにリンクし、CがAに戻る複雑な関係のネットワーク。この構造はエンジンがデータグラフをたどることを難しくし、しばしばメモリ上に一時テーブルが作成される結果となる。
これらの問題を軽減するため、ERDがオプションリンクと必須リンクを明確に区別していることを確認する。必須リンクはオプティマイザがNULLチェックをスキップできるようにし、実行速度を向上させる。オプションリンクは、関係が存在しない場合を処理するための追加ロジックを必要とする。
📏 データ型とストレージ効率
スキーマ定義内のデータ型の選択は、ストレージサイズと比較速度に大きな影響を与える。異なるデータ型の2つの列を比較するクエリは、しばしば暗黙の変換を引き起こす。これらの変換はインデックスの使用を妨げ、エンジンにすべての行を処理させることを強いる。
ストレージへの影響
スキーマがすべての列に汎用的なデータ型(例:短いコードに大きなテキストフィールドを使用)を使用すると、ディスクスペースとメモリをより多く消費する。これにより、バッファプールの実効サイズが減少し、メモリに保持できるホットデータページが少なくなる。結果として、システムはより多くのデータを遅いディスクサブシステムから読み取らなければならない。
比較性能
整数の比較は文字列の比較よりも著しく高速である。ERDで外部キーを文字列(例:VARCHAR)として定義しているが、整数(例:INT)であるべき場合、結合操作はバイナリ数値比較ではなく、文字単位で比較しなければならない。これにより、処理される各行にCPUサイクルが追加される。
- 固定長型を使用する: 国コードやステータスフラグなどのフィールドでは、固定長文字列を使用する。可変長文字列は、読み込み毎に長さを計算するオーバーヘッドをもたらす。
- キーに大規模なテキストを避ける: テキストが大量に含まれる列をプライマリキーまたは外部キーとして決して使用しない。これにより、それを参照するすべてのインデックスが肥大化する。
- 親テーブルと子テーブルの型を一致させる: 子テーブルのデータ型が親テーブルと正確に一致していることを確認する。わずかな違い(例:INT vs BIGINT)でも、結合時に変換を強制する可能性がある。
🔑 インデックスの可視性と戦略
ERDは論理構造の視覚的表現であるが、物理的なインデックス戦略にも影響を与えるべきである。インデックスはしばしばスキーマ作成後に追加されるが、設計段階でどこにインデックスが必要かを予測すべきである。インデックスが設定されていない列でフィルタリングを行うクエリは、設計上のギャップを示す主要な兆候である。
ERDにおけるインデックス化の機会
パフォーマンスのボトルネックを検討する際、検索条件や結合で頻繁に使用されるカラムを確認してください。
- 外部キー:これらはほぼ常にインデックス化されるべきです。クエリが外部キーを使ってTable AとTable Bを結合する場合、Table Bのキーがインデックス化されていないと、Table Aの各行に対してTable B全体をスキャンしなければなりません。
- ステータスフラグ:レコードの状態を定義するカラム(例:Is_Active、Order_Status)は、よくWHERE句で使用されます。これらがインデックス化されていない場合、フィルタリングはフルテーブルスキャンになります。
- 日付範囲:監査ログや取引ログを持つテーブルは、日付で頻繁にクエリが行われます。日付カラムは範囲スキャンを効率的に行えるようにインデックス化すべきです。
インデックスの数を書き込みパフォーマンスとバランスさせることが重要です。各インデックスはINSERT、UPDATE、DELETE操作にオーバーヘッドを追加します。しかし、読み込みが重いスキーマが適切にインデックス化されていないと、書き込みコストをはるかに上回るシステムの遅延が発生します。ERDは、読み込みが重いテーブル(例:参照テーブル)と書き込みが重いテーブル(例:取引ログ)を可視化するのに役立ち、インデックス化の意思決定を支援します。
🚫 結合の病理学
遅いクエリの最も一般的な原因の一つが結合経路です。これは、データベースエンジンがリクエストを満たすためにテーブルを接続する順序を指します。設計が不十分なスキーマは、論理的には正しいが計算コストが高い経路にエンジンを強いることがあります。
カルテシアン積
スキーマに適切な制約がなく、またはクエリロジックが結合条件を正しく指定していない場合、エンジンはカルテシアン積を生成する可能性があります。これはTable Aの各行がTable Bの各行すべてと組み合わされる状態です。結果セットは指数関数的に増大し、クエリがタイムアウトするか、利用可能なメモリをすべて消費する可能性があります。
ERDでは、多対多の関係が結合テーブルによって適切に中継されていない場合、または結合テーブルに必要な外部キー制約が欠けている場合に、この状況がよく発生します。
サブクエリ vs. 結合
スキーマ設計は、クエリがシンプルな結合で実行できるか、サブクエリを必要とするかに影響します。サブクエリは、外部クエリの各行に対して内部クエリを一度ずつ実行するため、時間計算量が二次関数的になります。直接結合が可能な正規化されたスキーマは、サブクエリを強制する非正規化構造よりも一般的に好まれます。
✅ スキーマ検証チェックリスト
ERDに基づいて遅いクエリを体系的にトラブルシューティングするためには、構造的なレビューを行ってください。このチェックリストにより、設計のすべての重要な要素を検証できます。
1. 外部キー制約の確認
- すべての外部キーが図面上で明示的に定義されていますか?
- 意図しないデータ移動を引き起こす可能性のある級連ルールを含んでいますか?
- 関係の両側のデータ型は同一ですか?
2. 結合頻度の分析
- アプリケーションロジックで最も頻繁に結合されるテーブルを特定してください。
- これらのテーブルは図面上で隣接していますか?それとも、複数の中間テーブルを経由する必要がありますか?
- これらの中間テーブルのうち、結合の深さを減らすために統合できるものがありますか?
3. NULL許容性の確認
- 決してNULLにならないカラムは、明示的にNOT NULLとしてマークされていますか?
- インデックスの一部であるカラムにNULLを許可していますか?
4. データ型の確認
- 数値フィールドは適切な最小サイズを使用していますか(例:TINYINT と BIGINT)?
- テキストフィールドは、切り捨てや余分なストレージを避けるために適切な長さを使用していますか?
5. インデックスカバレッジの評価
- 主キーおよび外部キーにはインデックスが設定されていますか?
- 頻繁にフィルタリングされるカラムにはインデックスが設定されていますか?
- 一般的な複数カラムクエリ用に複合インデックスがありますか?
🛠️ 修正のための実践的ステップ
ERDの分析と問題の特定が終わったら、次は修正フェーズです。これは、データ整合性を損なわずにパフォーマンス要件に合わせてスキーマを変更することを意味します。
関係の最適化: ERDに過度に複雑な関係が示されている場合、それらを簡素化することを検討してください。特定の読み取りが頻繁な領域で正規化を緩めることで、結合の必要性を減らすことができます。たとえば、親テーブルに関連するアイテムのキャッシュされた数を保存することで、毎回結合してカウントする必要がなくなります。
データ型の最適化:より効率的な代替データ型に変更してください。日付が日単位でしか保存されない場合、時刻を含むdatetimeではなく、日付のみの型を使用してください。IDが数値の場合、文字列として保存されていないか確認してください。
パーティショニングの導入:非常に大きなテーブルの場合、ERDにパーティショニング戦略を反映する必要があるかもしれません。パーティショニングはしばしば物理的な実装の詳細ですが、論理設計ではデータのグループ化方法を考慮する必要があります。日付や地域に基づくパーティショニングにより、エンジンはデータの関連するセグメントのみをスキャンできるようになります。
🔎 最終的な考慮事項
パフォーマンスのトラブルシューティングは反復的なプロセスです。ERDはこのプロセスにおける中心的なアーティファクトです。図を論理構造と物理的パフォーマンス制約を反映する動的な文書として扱うことで、データが増大しても応答性を維持できるデータベースシステムを保つことができます。
あらゆる状況に適した単一の設計は存在しないことを思い出してください。高頻度の書き込みに最適化されたスキーマは、複雑な分析クエリに最適化されたものと異なる性能を示す可能性があります。目標は、アプリケーションの特定のアクセスパターンに合わせてスキーマ設計を調整することです。実際のクエリパフォーマンスメトリクスと照らし合わせてERDを定期的に見直すことで、早期にズレを検出できます。
データモデルの構造的整合性に注目することで、遅延の根本原因を排除できます。アプリケーション層にパッチを当てるよりも、このアプローチの方が持続可能性が高いです。堅固なスキーマの基盤は、システムがスケーリングし、適応し、時間とともに信頼性高く動作することを保証します。
変更を行った後も、クエリ実行計画のモニタリングを継続してください。実行計画を可視化することで、最適化エンジンが新しいインデックスや制約を正しく利用していることを確認できます。このフィードバックループにより、トラブルシューティングのサイクルが完了し、ERD上の理論的な改善がライブ環境での実際のパフォーマンス向上に結びつくことを保証します。