











💡 मुख्य बातें
-
दृश्य स्पष्टता:रिवर्स इंजीनियरिंग घने स्रोत कोड को पठनीय UML डायग्राम में बदलती है, छिपी हुई संरचना को उजागर करती है।
-
निर्भरता मैपिंग:स्वचालित विश्लेषण मॉड्यूल के बीच संबंधों को पहचानता है, रीफैक्टरिंग और कपलिंग को समझने में सहायता करता है।
-
पुराने प्रणाली का आधुनिकीकरण:मौजूदा कोडबेस से डायग्राम बनाना तकनीकी ऋण और भविष्य के दस्तावेजीकरण के बीच के अंतर को पाटता है।
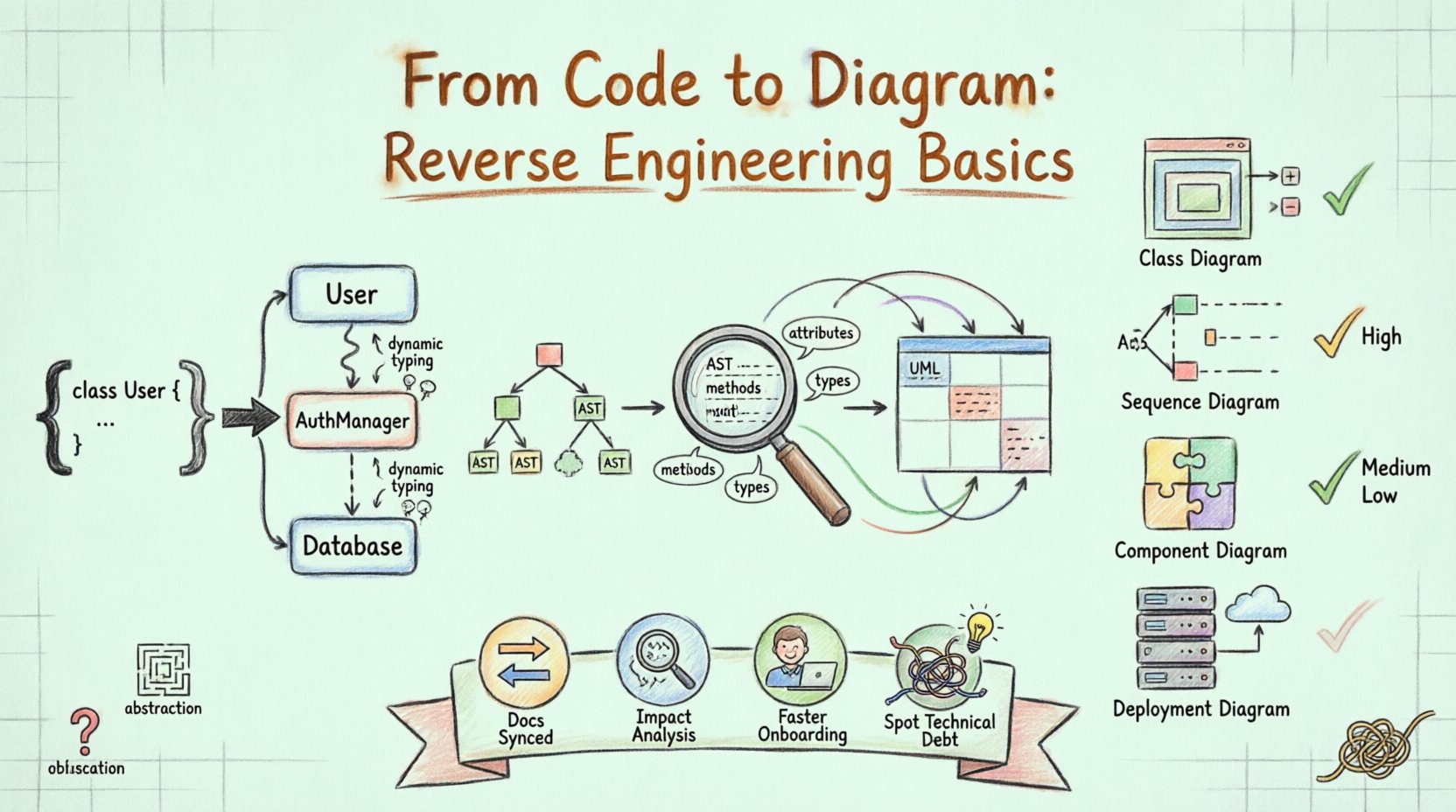
सॉफ्टवेयर विकास के क्षेत्र में, दस्तावेजीकरण को बनाए रखना अक्सर कार्यान्वयन की गति के पीछे रह जाता है। कोडबेस बढ़ते हैं, फीचर जोड़े जाते हैं, और मूल आर्किटेक्चरल निर्णय धुंधले हो जाते हैं। यहीं पर रिवर्स इंजीनियरिंग एक आवश्यक विषय बन जाती है। इसमें मौजूदा स्रोत कोड के विश्लेषण के माध्यम से एक दृश्य प्रतिनिधित्व को पुनर्निर्मित करना शामिल है, जिसमें आमतौर पर संयुक्त मॉडलिंग भाषा (UML) डायग्राम का उपयोग किया जाता है। इस प्रक्रिया केवल यह दर्ज करने के लिए नहीं है कि क्या मौजूद है; यह घटकों के बीच बातचीत, निर्भरताओं के स्थान और प्रणाली की संरचना को स्पष्ट करती है।
UML के संदर्भ में रिवर्स इंजीनियरिंग को समझना 🧩
सॉफ्टवेयर विकास में रिवर्स इंजीनियरिंग एक प्रणाली के विश्लेषण की प्रक्रिया है ताकि उसके घटकों और उनके बीच के संबंधों को पहचाना जा सके। UML पर लागू करने पर, लक्ष्य वास्तविक कार्यान्वयन से एक आरेखीय प्रतिनिधित्व निकालना है। फॉरवर्ड इंजीनियरिंग के विपरीत, जहां आरेख कोड लिखने के लिए निर्देश देते हैं, रिवर्स इंजीनियरिंग कोड से शुरू होती है और आरेख निकालती है।
यह दृष्टिकोण विशेष रूप से पुरानी प्रणालियों के लिए मूल्यवान है जहां दस्तावेजीकरण पुराना हो सकता है या अस्तित्व में नहीं हो सकता है। स्रोत कोड के पार्स करने से उपकरण कक्षा के नाम, विधि सिग्नेचर, विरासत पदानुक्रम और संबंध संबंधों को निकाल सकते हैं। इन तत्वों को कक्षा आरेख, अनुक्रम आरेख और घटक आरेख के निर्माण के आधार के रूप में उपयोग किया जाता है।
मुख्य उद्देश्य
मुख्य उद्देश्य समझ की स्थिति प्राप्त करना है। विकासकर्ता अक्सर पुराने कोड के सामने आते हैं जो एक काले बॉक्स की तरह महसूस होता है। रिवर्स इंजीनियरिंग इस बॉक्स को खोलती है, जिससे टीमें डेटा प्रवाह और संरचनात्मक तर्क को देख सकती हैं बिना प्रत्येक कोड लाइन को पढ़े। यह कोड की वास्तविकता और डिजाइन की अमूर्त अवधारणा के बीच एक पुल के रूप में कार्य करती है।
कोड से आरेख क्यों बनाएं? 📊
इस प्रक्रिया को करने के कई रणनीतिक कारण हैं। यह सिर्फ सुंदर चित्र बनाने के बारे में नहीं है; यह जोखिम कम करने और स्पष्टता प्राप्त करने के बारे में है।
-
दस्तावेजीकरण समन्वय:कोड अक्सर बदलता है। कोड से उत्पन्न आरेख हमेशा अद्यतन रहते हैं, जो प्रणाली की वर्तमान स्थिति को दर्शाते हैं।
-
प्रभाव विश्लेषण:किसी मॉड्यूल को रीफैक्टर करने से पहले, विकासकर्ताओं को यह जानने की आवश्यकता होती है कि क्या उस पर निर्भर है। आरेख इन निर्भरताओं को स्पष्ट रूप से उजागर करते हैं।
-
ऑनबोर्डिंग:नए टीम सदस्य आरेखों को देखकर फाइलों के भंडार में घूमने की तुलना में प्रणाली संरचना को बहुत तेजी से समझ सकते हैं।
-
तकनीकी ऋण की पहचान करना:जटिल संरचनाएं अक्सर आरेखों में जटिल जाल के रूप में उभरती हैं, जो उन क्षेत्रों को उजागर करती हैं जिन्हें सरल बनाने की आवश्यकता होती है।
रिवर्स इंजीनियरिंग की प्रक्रिया 🔄
कोड को आरेख में बदलने में एक व्यवस्थित कार्य प्रवाह शामिल होता है। जबकि विशिष्ट कार्यान्वयन भिन्न होते हैं, तर्कसंगत चरण पर्यावरणों में स्थिर रहते हैं।
1. पार्सिंग और विश्लेषण
पहला चरण स्रोत कोड फाइलों को पढ़ने में शामिल होता है। प्रणाली सिंटैक्स को पार्स करती है ताकि संरचना को समझा जा सके। यह कक्षाओं, इंटरफेस, फंक्शन और चर की पहचान करती है। इस चरण में कच्चे टेक्स्ट को एक संरचित डेटा प्रारूप में बदला जाता है, जो आमतौर पर एब्स्ट्रैक्ट सिंटैक्स ट्री (AST) होता है। पार्सर को भाषा-संवेदनशील होना चाहिए ताकि उपयोग की जा रही प्रोग्रामिंग भाषा के विशिष्ट सिंटैक्स को सही तरीके से व्याख्या किया जा सके।
2. मेटाडेटा का निकास
जब कोड को पार्स कर लिया जाता है, तो प्रणाली विशिष्ट मेटाडेटा का निकास करती है। इसमें शामिल है:
-
लक्षण: क्लासेस के भीतर डेटा क्षेत्र।
-
विधियाँ: कार्य और उनके पहुँच संकेतक (सार्वजनिक, निजी, सुरक्षित)।
-
प्रकार: लक्षणों और लौटाए गए मानों से जुड़े डेटा प्रकार।
-
संबंध: विरासत (एक्सटेंड्स/इम्प्लीमेंट्स), संबंध (उपयोग), और संगठन (संयोजन)।
3. UML अर्थशास्त्र के अनुरूप नक्शा बनाना
निकाले गए मेटाडेटा को UML नोटेशन के अनुरूप नक्शा बनाना आवश्यक है। उदाहरण के लिए, एक क्लास परिभाषा क्लास डायग्राम बॉक्स के अनुरूप होती है। एक फंक्शन के भीतर एक विधि कॉल सीक्वेंस डायग्राम में एक इंटरैक्शन के अनुरूप होती है। इस नक्शा बनाने के लिए तार्किक निष्कर्ष आवश्यक है। यदि क्लास A क्लास B का एक उदाहरण बनाती है, तो प्रणाली एक संबंध या निर्भरता का निष्कर्ष निकालती है।
4. दृश्यीकरण और रेंडरिंग
अंतिम चरण डेटा को एक दृश्य रूप में रेंडर करना है। इसमें कैनवास पर तत्वों को रखना और संबंधों का प्रतिनिधित्व करने के लिए रेखाएँ खींचना शामिल है। लेआउट एल्गोरिदम डायग्राम को पठनीय बनाने की कोशिश करते हैं, लाइनों के प्रतिच्छेदन को कम करते हैं और संबंधित घटकों को समूहित करते हैं।
सामान्य डायग्राम उत्पन्न किए गए 📝
सभी डायग्राम रिवर्स इंजीनियरिंग के लिए समान रूप से उपयुक्त नहीं होते हैं। कुछ स्थिर संरचना को दर्शाते हैं, जबकि अन्य गतिशील व्यवहार को दर्शाते हैं।
|
डायग्राम प्रकार |
फोकस |
रिवर्स इंजीनियरिंग में उपयोगिता |
|---|---|---|
|
क्लास डायग्राम |
स्थिर संरचना |
उच्च। कोड से सीधे विरासत, लक्षण और विधियाँ दिखाता है। |
|
अनुक्रम डायग्राम |
गतिशील व्यवहार |
मध्यम। इंटरैक्शन फ्लो को समझने के लिए विधि कॉल का अनुसरण करने की आवश्यकता होती है। |
|
घटक डायग्राम |
प्रणाली मॉड्यूल |
उच्च। क्लासेस को तार्किक इकाइयों या लाइब्रेरी में समूहित करता है। |
|
डिप्लॉयमेंट डायग्राम |
इंफ्रास्ट्रक्चर |
कम। केवल कोड के बजाय सर्वर कॉन्फ़िगरेशन के ज्ञान की आवश्यकता होती है। |
प्रक्रिया में चुनौतियाँ ⚠️
जबकि शक्तिशाली, रिवर्स इंजीनियरिंग कठिनाइयों से बची नहीं है। सटीक आरेखों के उत्पादन को जटिल बनाने वाले कई कारक हो सकते हैं।
अब्स्ट्रैक्शन और छिपाना
आधुनिक कोडबेस अब्स्ट्रैक्शन पर भारी निर्भरता रखते हैं। इंटरफेस और पॉलीमॉर्फिज्म वास्तविक कार्यान्वयन को धुंधला कर सकते हैं। एक विधि एक इंटरफेस में परिभाषित हो सकती है लेकिन बहुत सारे क्लासेस में कार्यान्वित हो सकती है। इसका दृश्यीकरण करने के लिए दोनों संवाद और वास्तविकता को दिखाना आवश्यक होता है, जो आरेख को भारी बना सकता है।
डायनामिक टाइपिंग
डायनामिक टाइपिंग का समर्थन करने वाली भाषाएं (जहां चर के प्रकार को रनटाइम पर निर्धारित किया जाता है) स्थिर विश्लेषण के लिए एक चुनौती प्रस्तुत करती हैं। रिवर्स इंजीनियरिंग टूल को कोड को निष्पादित किए बिना या जटिल नियंत्रण प्रवाहों के विश्लेषण किए बिना एक वस्तु के ठीक प्रकार को निर्धारित करने में कठिनाई हो सकती है।
कोड ओब्फस्केशन
कुछ संदर्भों में, संपत्ति की सुरक्षा के लिए कोड को ओब्फस्केट किया जाता है। चर के नाम बदलने और कोड को संक्षिप्त करने से स्रोत कोड मानवों और मशीनों द्वारा पढ़ने में कठिनाई होती है। ओब्फस्केट कोड को रिवर्स इंजीनियर करने के लिए बहुत अधिक उन्नत विश्लेषण तकनीकों की आवश्यकता होती है।
जटिल निर्भरताएं
बड़े प्रणालियों में अक्सर चक्रीय निर्भरताएं या तंतु बंधे मॉड्यूल होते हैं। जब एक आरेख बनाया जाता है, तो इन निर्भरताओं के कारण एक “स्पैगेटी” प्रभाव बन सकता है, जहां रेखाएं अव्यवस्थित रूप से प्रतिच्छेद करती हैं। लेआउट को साफ करने और संबंधित तत्वों को तार्किक रूप से समूहित करने के लिए अक्सर मैन्युअल हस्तक्षेप की आवश्यकता होती है।
सटीकता के लिए सर्वोत्तम प्रथाएं ✅
यह सुनिश्चित करने के लिए कि उत्पन्न आरेख उपयोगी हों, रिवर्स इंजीनियरिंग प्रक्रिया के दौरान कुछ प्रथाओं का पालन करना चाहिए।
-
नॉइज़ फ़िल्टर करें: मानक लाइब्रेरी या बॉयलरप्लेट कोड को बाहर रखें जो संरचनात्मक मूल्य के बिना दृश्य भार बढ़ाता है। कस्टम व्यापार तर्क पर ध्यान केंद्रित करें।
-
मॉड्यूल समूहित करें: क्लासेस को समूहित करने के लिए पैकेज या नेमस्पेस का उपयोग करें। इससे आरेख के एक विशाल नोड में बदलने से बचा जा सकता है।
-
संबंधों की पुष्टि करें: स्वचालित उपकरण कभी-कभी संबंधों की गलत व्याख्या कर सकते हैं। उत्पन्न लिंक की समीक्षा करें ताकि यह सुनिश्चित हो कि वे कोड तर्क का सही प्रतिनिधित्व करते हैं।
-
पुनरावृत्ति करें: रिवर्स इंजीनियरिंग अक्सर एकमात्र कार्य नहीं होता है। जैसे-जैसे कोडबेस विकसित होता है, आरेखों को पुनः उत्पन्न करना और नियमित रूप से समीक्षा करना चाहिए।
स्वचालन की भूमिका 🤖
बड़े प्रोजेक्ट्स के लिए मैन्युअल रिवर्स इंजीनियरिंग अव्यवहार्य है। स्वचालन महत्वपूर्ण है। स्वचालित पार्सर रिपॉजिटरी को स्कैन करते हैं, निर्भरता ग्राफ बनाते हैं और XMI या PlantUML जैसे मानक प्रारूपों में निर्यात करते हैं। इससे टीमों को आरेख उत्पादन को उनके CI/CD पाइपलाइन में एकीकृत करने में सक्षम बनाता है।
स्वचालन सुनिश्चित करता है कि दस्तावेज़ीकरण कभी भी अप्रासंगिक नहीं होता है। यदि कोई डेवलपर एक बदलाव करता है जो निर्भरता तोड़ता है, तो आरेख उत्पादन प्रक्रिया असंगति को चिह्नित कर सकती है। यह निरंतर सत्यापन समय के साथ प्रणाली की अखंडता बनाए रखने में मदद करता है।
रखरखाव में आरेखों को एकीकृत करना 🛠️
जब आरेख उत्पन्न हो जाते हैं, तो उनका सक्रिय रूप से उपयोग किया जाना चाहिए। वे केवल प्रस्तुति के लिए नहीं हैं। टीम उनका उपयोग रिफैक्टरिंग प्रयासों की योजना बनाने के लिए कर सकती है। उदाहरण के लिए, यदि क्लास आरेख किसी क्लास को अत्यधिक निर्भरताओं के साथ दिखाता है, तो इसे विघटन के लिए उपयुक्त माना जा सकता है।
इसके अलावा, आरेख कोड समीक्षा में मदद करते हैं। समीक्षक डिफ को पढ़ने से पहले प्रस्तावित बदलाव के संरचनात्मक प्रभाव को देख सकते हैं। इससे व्याकरण से संरचना की ओर ध्यान केंद्रित करने में सुधार होता है, जिससे कोडबेस की गुणवत्ता में सुधार होता है।
संरचनात्मक दृष्टि पर निष्कर्ष 🏁
कोड को UML आरेखों में रिवर्स इंजीनियर करना जटिल सॉफ्टवेयर प्रणालियों को बनाए रखने के लिए एक मूलभूत अभ्यास है। यह अस्पष्ट कोड को स्पष्ट संरचना में बदल देता है, जिससे बेहतर निर्णय लेने और स्पष्ट संचार की संभावना होती है। डायनामिक टाइपिंग और जटिल निर्भरताओं के संबंध में चुनौतियां मौजूद हैं, लेकिन समन्वित दस्तावेज़ीकरण के लाभ लागत से अधिक हैं। संरचनात्मक स्पष्टता को प्राथमिकता देकर, टीमें विरासत प्रणालियों को आत्मविश्वास के साथ निर्देशित कर सकती हैं और अपने अनुप्रयोगों को सटीकता के साथ आधुनिक बना सकती हैं।