











जटिल सॉफ्टवेयर प्रणालियों की वास्तुकला में, स्पष्टता सफलता की मुद्रा है। एक भी लॉजिक लाइन लिखे जाने से पहले, सूचना के आंदोलन को समझना आवश्यक है। यहीं पर डेटा फ्लो डायग्राम (DFD) अनिवार्य हो जाता है। एक DFD यह दिखाता है कि डेटा प्रणाली में कैसे प्रवेश करता है, इसे कैसे परिवर्तित किया जाता है, इसे कहाँ संग्रहीत किया जाता है और यह कैसे बाहर निकलता है। यह एक संरचनात्मक नक्शा है जो ‘क्या’ को ‘कैसे’ से अलग करता है। कोड के विपरीत, जो विशिष्ट कार्यान्वयन विवरण निर्धारित करता है, DFD पूरी प्रणाली में सूचना के तार्किक प्रवाह पर ध्यान केंद्रित करता है।
बहुत से टीमें डेटा के आंदोलन के एक ठोस दृश्य प्रतिनिधित्व के बिना कोडिंग में जल्दी कर देती हैं। इससे स्पैगेटी लॉजिक, आवश्यकता से अधिक डेटाबेस क्वेरीज और व्यवसाय प्रक्रियाओं से मेल न खाने वाले इंटरफेस बनते हैं। DFD के निर्माण और व्याख्या को समझने के बाद, वास्तुकार प्रणाली के आधार को उसके उद्देश्य के अनुरूप सुदृढ़ बनाते हैं। यह मार्गदर्शिका प्रभावी आरेख बनाने के यांत्रिकी, नियम और उत्तम प्रथाओं का विवरण देती है, जो अमूर्त आवश्यकताओं और वास्तविक कार्यान्वयन के बीच के अंतर को पार करती है।
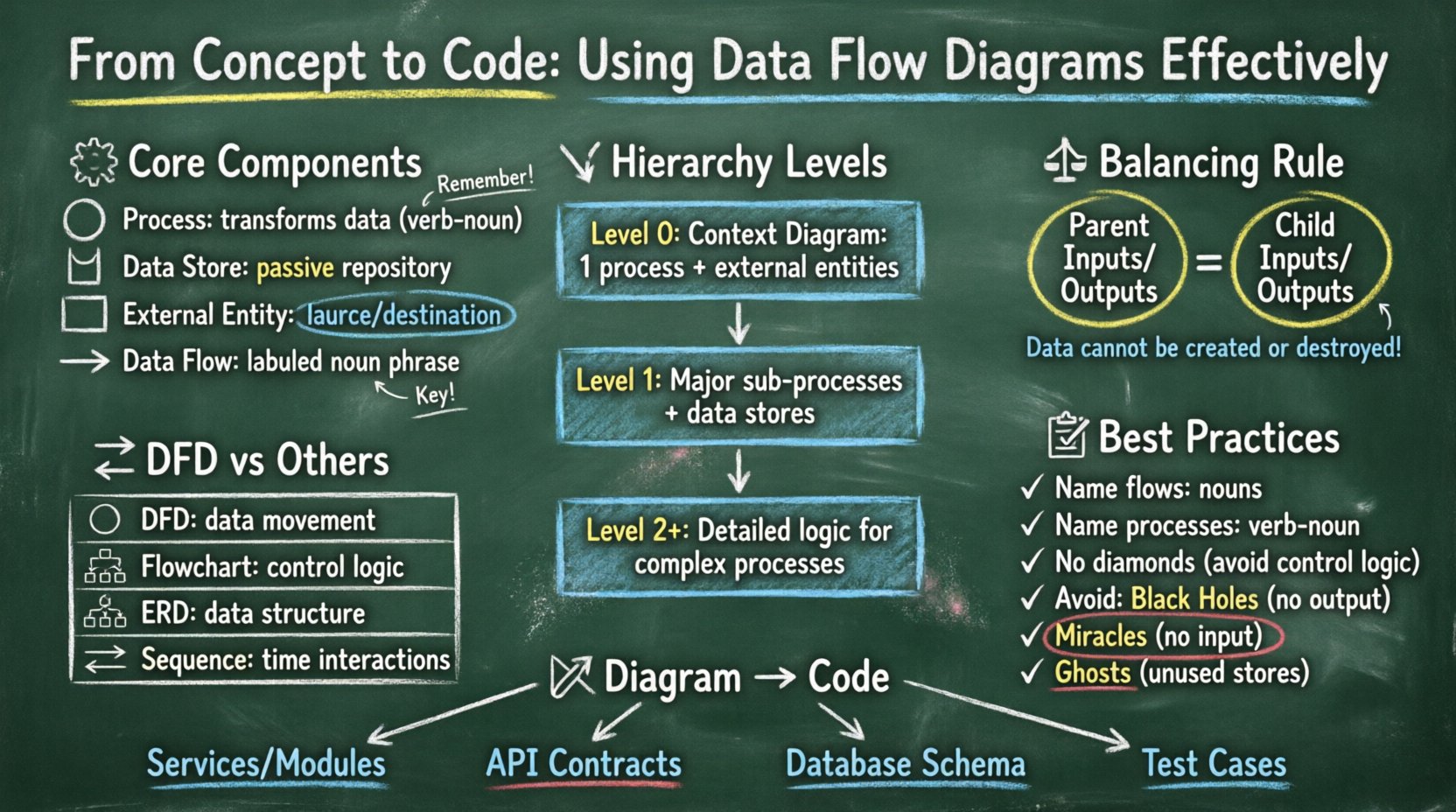
🧩 DFD के मुख्य घटकों को समझना
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। इसमें नियंत्रण प्रवाह, जैसे लूप या निर्णय शाखाएं, नहीं दिखाई जाती हैं, बल्कि डेटा को ही दिखाया जाता है। एक वैध आरेख बनाने के लिए, मानक नोटेशन में उपयोग किए जाने वाले चार मूल चिह्नों को समझना आवश्यक है।
- प्रक्रिया:एक वृत्त या गोल कोने वाला आयत द्वारा दर्शाया जाता है, एक प्रक्रिया आने वाले डेटा प्रवाह को बाहर निकलने वाले डेटा प्रवाह में बदलती है। यह परिवर्तन, गणना या संग्रह का प्रतिनिधित्व करता है। एक प्रक्रिया अकेले नहीं रह सकती; इसे कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
- डेटा भंडार:खुले छोर वाले आयत या समानांतर रेखाओं के रूप में दिखाया जाता है, यह प्रतीक डेटा के भंडार का प्रतिनिधित्व करता है। यह एक सक्रिय भंडार है जहां डेटा प्रक्रियाओं के बीच रुकता है। उदाहरण में डेटाबेस तालिकाएं, फ्लैट फाइलें या मेमोरी में संग्रहीत कैश शामिल हैं।
- बाहरी एकाधिकार:एक टर्मिनेटर के रूप में भी जाना जाता है, यह एक आयत है जो प्रणाली की सीमाओं के बाहर डेटा के स्रोत या गंतव्य का प्रतिनिधित्व करता है। यह एक उपयोगकर्ता, दूसरी प्रणाली या एक भौतिक उपकरण हो सकता है।
- डेटा प्रवाह:तीर वाली रेखा के रूप में दर्शाया जाता है, यह घटकों के बीच डेटा के आंदोलन को दिखाता है। यह भौतिक संकेत के बजाय डेटा को ही दर्शाता है। प्रत्येक प्रवाह को उसकी सामग्री का वर्णन करने वाला अर्थपूर्ण लेबल होना चाहिए।
इन घटकों के बीच अंतर को समझना महत्वपूर्ण है। उदाहरण के लिए, एक सामान्य त्रुटि यह है कि एक बाहरी एकाधिकार से दूसरे बाहरी एकाधिकार तक डेटा प्रवाह बनाना, जिसमें प्रणाली को छोड़ दिया जाता है। इसका अर्थ है कि प्रणाली डेटा को प्रक्रिया नहीं कर रही है, जो विश्लेषण की सीमा का उल्लंघन करता है। इसी तरह, प्रक्रिया के बिना डेटा भंडार को बाहरी एकाधिकार से सीधे जोड़ना अनधिकृत पहुंच या नियंत्रण की कमी को दर्शाता है।
📉 DFD स्तरों की पदानुक्रमिकता
डेटा फ्लो डायग्राम स्थिर नहीं होते; वे पदानुक्रमिक होते हैं। इससे एक प्रणाली को उच्च स्तर के सारांश से लेकर विस्तृत विवरण तक वर्णित किया जा सकता है। इस विभाजन से जटिलता को प्रबंधित करने में मदद मिलती है, क्योंकि प्रणाली को प्रबंधन योग्य भागों में बांटा जाता है। विभाजन के तीन मुख्य स्तर हैं।
1. संदर्भ आरेख (स्तर 0)
संदर्भ आरेख उच्चतम स्तर के अमूर्तता प्रदान करता है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एकाधिकारों के साथ बातचीत को दर्शाता है। यह आरेख प्रश्न का उत्तर देता है: ‘प्रणाली क्या है?’ यह उन स्टेकहोल्डर्स के लिए उपयोगी है जो आंतरिक विवरणों में फंसे बिना त्वरित सारांश चाहते हैं।
- परिसर:पूरी प्रणाली का प्रतिनिधित्व करने वाली एक केंद्रीय प्रक्रिया।
- एकाधिकार:सभी बाहरी स्रोत और गंतव्य।
- प्रवाह:मुख्य डेटा इनपुट और आउटपुट।
2. स्तर 1 आरेख
स्तर 1 आरेख संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करता है। यह प्रणाली डिजाइन दस्तावेजीकरण के लिए सबसे आम स्तर है। यह प्रणाली के मुख्य कार्यात्मक क्षेत्रों को उजागर करता है। यहां पहचानी गई प्रत्येक मुख्य कार्य एक अलग प्रक्रिया नोड बन जाती है।
- परिसर:मुख्य कार्यात्मक मॉड्यूल।
- बातचीत:डेटा इन मॉड्यूलों और बाहरी एकाधिकारों के बीच आता-जाता है।
- स्टोरेज:प्राथमिक डेटाबेस या फाइल प्रणालियों का परिचय दिया जाता है।
3. स्तर 2 और नीचे
स्तर 2 के आरेख स्तर 1 के आरेख से विशिष्ट प्रक्रियाओं को अधिक विस्तार से बांटते हैं। इसका उपयोग उन जटिल प्रक्रियाओं के लिए किया जाता है जिनमें महत्वपूर्ण तर्क या डेटा संचालन शामिल होता है। इस स्तर पर अत्यधिक विभाजन के कारण आरेख बहुत बड़े हो सकते हैं, जिससे पढ़ने में कठिनाई होती है, इसलिए सावधानी बरतने की सलाह दी जाती है। आमतौर पर केवल सबसे जटिल कार्यों के लिए इस गहराई की आवश्यकता होती है।
⚖️ संतुलन का सिद्धांत
DFD निर्माण में सबसे महत्वपूर्ण नियमों में से एक संतुलन है। संतुलन सुनिश्चित करता है कि माता-पिता प्रक्रिया के इनपुट और आउटपुट उसके बच्चे प्रक्रियाओं के इनपुट और आउटपुट के साथ मेल खाते हैं। यदि माता-पिता प्रक्रिया को इनपुट प्रवाह “आदेश अनुरोध” है, तो बच्चे प्रक्रिया को भी “आदेश अनुरोध” (या उसका एक उपसमुच्चय जो तार्किक रूप से उसके योग के बराबर हो) स्वीकार करना चाहिए।
इस नियम का उल्लंघन असंगतियां पैदा करता है। एक विकासकर्ता जो बच्चे के आरेख को पढ़ रहा है, उसे एक इनपुट दिखाई दे सकता है जिसके बारे में माता-पिता आरेख कहता है कि वह कभी नहीं होता। इससे अनुप्रयोग त्रुटियां होती हैं। जब किसी प्रक्रिया को विभाजित करते हैं, तो आपको सुनिश्चित करना चाहिए:
- माता-पिता प्रक्रिया में प्रवेश करने वाले सभी डेटा प्रवाह बच्चे की प्रक्रियाओं में भी प्रवेश करते हैं।
- बच्चे की प्रक्रियाओं से निकलने वाले सभी डेटा प्रवाह माता-पिता प्रक्रिया से भी निकलते हैं।
- माता-पिता के संदर्भ में बिना तर्कसंगत कारण के कोई नया डेटा प्रवाह नहीं जोड़ा जाता है।
- विभाजन के दौरान कोई मौजूदा प्रवाह नहीं खोया जाता है।
संतुलन को डेटा के संरक्षण के नियम के रूप में सोचें। डेटा को प्रणाली की सीमाओं के भीतर न तो बनाया जा सकता है और न ही नष्ट किया जा सकता है; यह केवल परिवर्तित किया जाता है। इस सिद्धांत के कारण डिज़ाइनर को प्रत्येक डेटा के लिए तर्क देना होता है जो प्रणाली में प्रवेश करता है या बाहर जाता है।
🔄 DFD बनाम अन्य आरेखण तकनीकें
DFD, फ्लोचार्ट और एंटिटी-रिलेशनशिप आरेख (ERD) के बीच अक्सर भ्रम पैदा होता है। हालांकि वे सभी प्रणालियों को मॉडल करते हैं, लेकिन उनके उद्देश्य अलग-अलग होते हैं। किसी विशिष्ट कार्य के लिए गलत आरेख का उपयोग डिज़ाइन के उद्देश्य को धुंधला कर सकता है।
| आरेख प्रकार | प्राथमिक फोकस | सर्वोत्तम उपयोग के लिए |
|---|---|---|
| डेटा प्रवाह आरेख (DFD) | डेटा का तार्किक गतिशीलता | प्रणाली विश्लेषण, प्रणाली सीमाओं को परिभाषित करना, डेटा रूपांतरण |
| फ्लोचार्ट | नियंत्रण प्रवाह और तर्क | एल्गोरिदम डिज़ाइन, निर्णय मार्ग, विशिष्ट प्रक्रिया तर्क |
| एंटिटी-रिलेशनशिप आरेख (ERD) | डेटा संरचना और संबंध | डेटाबेस स्कीमा डिज़ाइन, डेटा मॉडलिंग, स्टोरेज सामान्यीकरण |
| अनुक्रम आरेख | समय के अंतराल में बातचीत | API कॉल, उपयोगकर्ता सत्र प्रवाह, समय संबंधित निर्भरता |
उदाहरण के लिए, यदि आपको यह परिभाषित करने की आवश्यकता है कि उपयोगकर्ता प्रमाणीकरण टोकन का प्रमाणीकरण कैसे किया जाता है, तो फ्लोचार्ट उत्तीर्ण/असफल तर्क को दिखाने के लिए बेहतर हो सकता है। यदि आपको यह परिभाषित करने की आवश्यकता है कि उस टोकन को कहां संग्रहीत और पुनर्प्राप्त किया जाता है, तो DFD स्टोर की ओर प्रवाह दिखाता है, जबकि ERD स्टोरेज तालिका की संरचना दिखाता है। DFD कार्यात्मक नक्शा प्रदान करता है, जबकि अन्य आरेख संरचनात्मक और तार्किक विवरण प्रदान करते हैं।
🛠 डिज़ाइन सिद्धांत और उत्तम व्यवहार
एक आरेख बनाना केवल बॉक्स और तीर खींचने के बारे में नहीं है। इसमें ऐसे नियमों का पालन करना आवश्यक है जो सुनिश्चित करते हैं कि आरेख समय के साथ पठनीय और सटीक रहे। इन सिद्धांतों का पालन करने से डॉक्यूमेंटेशन ड्रिफ्ट को रोका जा सकता है, जहां आरेख कोड के अनुरूप नहीं रहता है।
1. नामकरण प्रथाएं
लेबल वह पाठ है जो अर्थ ले जाता है। स्पष्ट लेबल के बिना एक DFD बेकार है। प्रत्येक डेटा प्रवाह को एक संज्ञा वाक्यांश (उदाहरण के लिए, “उपयोगकर्ता ID”, “लेनदेन लॉग”) होना चाहिए। प्रत्येक प्रक्रिया को क्रिया वाक्यांश (उदाहरण के लिए, “पासवर्ड की पुष्टि करें”, “इन्वॉइस उत्पन्न करें”) होना चाहिए। इस व्याकरणिक अंतर से क्रिया और सामग्री के बीच स्पष्टता आती है।
- प्रक्रिया नाम:क्रिया-संज्ञा संरचना। “प्रक्रिया” या “तर्क” जैसे एकल शब्दों से बचें।
- डेटा प्रवाह नाम:सूचना पैकेट का वर्णन करने वाले संज्ञा वाक्यांश।
- डेटा स्टोर नाम:संज्ञा वाक्यांश, बहुवचन या एकवचन, संग्रह को इंगित करते हैं (उदाहरण के लिए, “ग्राहक रिकॉर्ड”)।
2. नियंत्रण तर्क से बचना
एक सामान्य गलती यह है कि DFD में नियंत्रण तर्क को शामिल करना। DFDs डेटा के गतिशीलता का वर्णन करते हैं, निर्णय लेने का नहीं। आपको “हां/नहीं” शाखा को इंगित करने वाले हीरे के आकार को नहीं बनाना चाहिए। यदि एक निर्णय मौजूद है, तो वह डेटा को फ़िल्टर करने वाली एक प्रक्रिया है। प्रवाह में डेटा के प्रक्रिया में प्रवेश करने और विशिष्ट डेटा प्रकार के बाहर निकलने को दिखाना चाहिए। उदाहरण के लिए, शाखा के बजाय, दो प्रवाह दिखाएं: “अनुमोदित आदेश” और “अस्वीकृत आदेश”, जो “आदेश प्रक्रिया” नोड से बाहर निकलते हैं।
3. काले छेद और चमत्कारों का प्रबंधन
प्रणाली विश्लेषण में, कुछ विचलनों से बचना आवश्यक है:
- काला छेद:एक प्रक्रिया जिसमें इनपुट हैं लेकिन आउटपुट नहीं हैं। इसका अर्थ है कि डेटा का उपभोग किया जाता है और कोई परिणाम बिना गायब हो जाता है।
- चमत्कार:एक प्रक्रिया जिसमें आउटपुट हैं लेकिन इनपुट नहीं हैं। इसका अर्थ है कि डेटा का निर्माण बिना किसी कारण के होता है।
- भूत:एक डेटा स्टोर जिसमें कोई डेटा प्रवाह नहीं जुड़ा है। इसका अर्थ है कि एक भंडारण स्थान है जिसका कभी उपयोग नहीं किया जाता है।
डिज़ाइन चरण के दौरान इन विचलनों की पहचान करने से बाद में महत्वपूर्ण डिबगिंग समय बचता है। यदि कोई प्रक्रिया कोई आउटपुट नहीं देती है, तो प्रणाली उस इनपुट के लिए मूल्य प्रदान नहीं कर रही है। यदि कोई स्टोर कोई इनपुट नहीं लेता है, तो वह खाली और अनावश्यक है।
🔗 आरेख से कोड तक: कार्यान्वयन रणनीति
जब DFD अंतिम रूप दे दिया जाता है, तो यह विकास टीम के लिए एक अनुबंध के रूप में कार्य करता है। इस दृश्य मॉडल को कार्यान्वित कोड में बदलने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। आरेख आर्किटेक्चर, डेटाबेस स्कीमा और API एंडपॉइंट्स को प्रभावित करता है।
1. सेवाओं और मॉड्यूल की पहचान करना
लेवल 1 आरेख में प्रत्येक प्रक्रिया अक्सर एक माइक्रोसर्विस, मॉड्यूल या क्लास के संगत होती है। उदाहरण के लिए, “कर की गणना” नामक प्रक्रिया बिलिंग मॉड्यूल के भीतर एक विशेष कार्य के रूप में बन सकती है। “उपयोगकर्ता प्रोफ़ाइल प्रबंधित करें” नामक प्रक्रिया एक उपयोगकर्ता सेवा के साथ मैप हो सकती है। इस मैपिंग से यह सुनिश्चित होता है कि कोड संरचना व्यापार तर्क का प्रतिनिधित्व करती है।
2. API अनुबंधों को परिभाषित करना
बाहरी एकाइयों और प्रक्रियाओं के बीच डेटा प्रवाह अक्सर API अनुरोधों और प्रतिक्रियाओं में बदल जाता है। यदि कोई एकाइयां “पंजीकरण डेटा” को प्रक्रिया को भेजती है, तो संबंधित API एंडपॉइंट को उस डेटा संरचना के अनुरूप पेलोड स्वीकार करना चाहिए। DFD इन एंडपॉइंट्स के लिए इनपुट और आउटपुट स्कीमा को निर्धारित करता है। इससे फ्रंटएंड और बैकएंड टीमों के बीच बार-बार समझौते की आवश्यकता कम हो जाती है।
3. डेटाबेस स्कीमा डिज़ाइन
DFD में डेटा स्टोर परिस्थिति परत का प्रतिनिधित्व करते हैं। यद्यपि DFD में फ़ील्ड या कीज़ नहीं दिखाए जाते हैं, लेकिन यह यह निर्धारित करता है कि कौन सी डेटा को सहेजने की आवश्यकता है। “आदेश इतिहास” का अर्थ है आदेशों के लिए एक तालिका या संग्रह। “सक्रिय सत्र” उपयोगकर्ता स्थिति के लिए एक भंडारण का अर्थ है। डेवलपर DFD का उपयोग करके यह निर्धारित कर सकते हैं कि कौन सी तालिकाएं महत्वपूर्ण हैं और सुनिश्चित कर सकते हैं कि डेटा स्टोर के बीच संबंध जानकारी के प्रवाह के अनुरूप हैं।
4. सत्यापन और परीक्षण
परीक्षण मामले सीधे डेटा प्रवाह से निकाले जा सकते हैं। प्रत्येक तीर एक संभावित परीक्षण मार्ग का प्रतिनिधित्व करता है। “अगर मैं एक आदेश भेजता हूं, तो क्या सिस्टम एक इन्वॉइस वापस लौटाता है?” इस ट्रेसेबिलिटी सुनिश्चित करती है कि प्रत्येक कोड लाइन मूल डिजाइन में निर्धारित उद्देश्य के लिए उपयोग की जाती है। यह “फीचर क्रीप” को रोकती है, जहां कोड जोड़ा जाता है जो डेटा प्रवाह में नहीं दिखाई देता है।
🛡 रखरखाव और दस्तावेज़ीकरण जीवनचक्र
एक आरेख केवल उसकी ताजगी के बराबर अच्छा होता है। एक ऐसा DFD जो वर्तमान प्रणाली का प्रतिनिधित्व नहीं करता है, तकनीकी ऋण बन जाता है। यह नए विकासकर्ताओं को भ्रमित करता है और वास्तविक तर्क को छिपा देता है। इसलिए, रखरखाव विकास जीवनचक्र का हिस्सा है।
- संस्करण निर्धारण:DFD को कोड की तरह लें। जब प्रणाली में परिवर्तन होता है, तो आरेख को अपडेट करना आवश्यक है। सॉफ्टवेयर रिलीज के अनुरूप संस्करण टैग करें।
- समीक्षा चक्र:कोड समीक्षा प्रक्रियाओं में DFD अपडेट शामिल करें। यदि कोई विकासकर्ता एक नया डेटा प्रवाह जोड़ता है, तो उसे आरेख को अपडेट करना होगा।
- पहुंच:आरेखों को कोड के साथ ही समान रिपॉजिटरी या दस्तावेज़ीकरण प्रणाली में रखें। इससे यह सुनिश्चित होता है कि टीम उपकरण बदलने पर वे खो न जाएँ।
- सरलीकरण:यदि एक आरेख बहुत जटिल हो जाता है, तो उसे विभाजित करने के बारे में सोचें। एक ही पृष्ठ पर 50 प्रक्रियाएँ होना पढ़ने में कठिन होता है। मॉड्यूलर आरेख रखरखाव के लिए आसान होते हैं।
आरेख का नियमित रूप से कोडबेस के खिलाफ ऑडिट करने से अंतर दिखाई देते हैं। क्या कोड में डेटा स्टोर हैं जो आरेख में नहीं हैं? क्या आरेख में प्रक्रियाएँ हैं जो रिफैक्टर कर दी गई हैं? इन अंतरों को दूर करने से प्रणाली दस्तावेज़ीकरण की अखंडता बनी रहती है।
🌟 लाभों का सारांश
डेटा प्रवाह आरेखों के लिए एक अनुशासित दृष्टिकोण लागू करने से निश्चित परिणाम मिलते हैं। यह टीम को तर्क से पहले डेटा के बारे में सोचने के लिए मजबूर करता है। यह एक सामान्य भाषा प्रदान करता है जो विकासकर्ताओं के लिए उपलब्ध है जो कोड नहीं समझते लेकिन व्यापार प्रक्रियाओं को समझते हैं। यह विश्लेषकों, वास्तुकारों और विकासकर्ताओं के बीच संचार के पुल के रूप में कार्य करता है।
संतुलन के नियमों का पालन करने, नियंत्रण तर्क से बचने और स्तरों के पदानुक्रम को बनाए रखने के द्वारा टीमें ऐसे आरेख बना सकती हैं जो दोनों सटीक और उपयोगी हों। विचार से कोड तक का संक्रमण सुगम हो जाता है क्योंकि गंतव्य स्पष्ट रूप से नक्शा बनाया गया है। डेटा प्रवाह की पुष्टि होती है, भंडारण की वैधता होती है, और बाहरी अंतरक्रियाओं को परिभाषित किया जाता है। इससे पुनर्कार्य कम होता है, अस्पष्टता कम होती है, और डिजाइन के आधार पर एक दृढ़ प्रणाली बनती है।
संदर्भ आरेख से शुरू करें। सावधानी से विभाजित करें। अपने प्रवाहों को संतुलित रखें। अपने लेबल सटीक रखें। और याद रखें कि आरेख एक जीवित कृति है, एक बार के डिलीवरेबल नहीं। इन अभ्यासों के साथ, आधुनिक प्रणालियों की जटिलता प्रबंधनीय हो जाती है, और विचार से कार्यान्वयन तक का रास्ता स्पष्ट रहता है।