











✨ Introduction : Pourquoi les limites comptent plus que le code
Dans le paysage logiciel en évolution rapide d’aujourd’hui, l’excellence technique seule est insuffisante. Les systèmes les plus sophistiqués échouent lorsque les parties prenantes ne comprennent pas leur objectif, leur portée ou leurs dépendances.La clarté est la ressource la plus rare en génie logiciel moderne—et définir les limites du contexte du système est l’outil le plus puissant dont nous disposons pour la préserver.
Avant qu’une seule ligne de code ne soit écrite, une architecture réussie commence par un acte délibéré : tracer les lignes qui séparent ce que votre systèmeest par rapport à ce qu’ilinteragit. Ces limites ne sont pas simplement des conventions diagrammatiques ; ce sont des décisions stratégiques qui façonnent l’autonomie des équipes, les stratégies de déploiement, les postures de sécurité et la maintenabilité à long terme. Lorsque les limites sont floues, la dette technique s’accumule silencieusement. Lorsqu’elles sont explicites, la collaboration prospère et la complexité devient gérable.
Ce guide fournit un cadre structuré et actionnable pour définir les limites du contexte du système en utilisant des approches de modélisation éprouvées, comme le modèle C4 [[1]]. Que vous soyez en train d’architecturer un microservice de nouvelle génération, de moderniser un monolithe hérité ou d’aligner des équipes transversales autour d’une vision partagée, maîtriser la définition des limites élèvera votre pratique architecturale et générera une valeur commerciale concrète.
📐 Comprendre le rôle du diagramme de contexte du système
Le diagramme de contexte du système agit comme une carte de haut niveau de votre solution. C’est la première vue que les parties prenantes rencontrent lorsqu’elles cherchent à comprendre l’architecture. Contrairement aux documents de conception détaillés, cette vue se concentre sur l’interaction entre le système et le monde qui l’entoure. Elle élimine la complexité interne pour révéler les relations essentielles [[7]].
Ce niveau d’abstraction remplit plusieurs objectifs clés :
-
Communication : Il permet aux parties prenantes non techniques de comprendre ce que fait le système sans s’enfoncer dans les détails d’implémentation [[29]].
-
Gestion du périmètre : Il définit visuellement ce qui est inclus dans le périmètre du projet et ce qui est considéré comme externe [[15]].
-
Identification des dépendances : Il met en évidence les connexions critiques nécessaires au fonctionnement du système.
-
Intégration : Les nouveaux membres de l’équipe peuvent rapidement comprendre l’écosystème dans lequel ils travailleront.
Sans un diagramme de contexte clair, les équipes ont souvent des difficultés avec des hypothèses. Un développeur pourrait supposer qu’une base de données spécifique est interne, tandis qu’un autre la considère comme un service externe. Ces malentendus entraînent des erreurs d’intégration et de la dette technique. Une limite définie élimine cette ambiguïté en précisant explicitement les limites de propriété et de responsabilité [[11]].
🎯 Identifier la limite du système principal
Définir la limite du système lui-même est un processus de prise de décision qui exige une réflexion attentive. La limite n’est pas nécessairement une ligne physique dans le code, mais une séparation logique de responsabilités. Elle répond à la question :« Qu’est-ce que cette solution spécifique contrôle, et sur quoi elle dépend ? » [[12]].
Lorsque vous déterminez le système principal, tenez compte des facteurs suivants :
-
Propriété métier : Quel domaine métier ce système sert-il directement ? La limite du système s’aligne souvent sur la propriété fonctionnelle d’une équipe ou d’un département.
-
Unité de déploiement : Le système peut-il être déployé de manière indépendante ? Si la base de code peut être publiée sans nécessiter une mise à jour synchronisée provenant d’un autre service, cela indique probablement une frontière valide [[18]].
-
Propriété des données : Le système maintient-il son propre état persistant ? Si les données sont partagées ou gérées par une autre entité, la frontière pourrait nécessiter un ajustement.
-
Domaine de défaillance : Si ce système échoue, entraîne-t-il l’effondrement de l’ensemble de l’écosystème ? Si oui, la frontière pourrait être trop large.
Il est courant de rencontrer des situations où la frontière est floue. Par exemple, un module de reporting doit-il faire partie du système central de transaction ou constituer un service de reporting indépendant ? Cette décision influence la circulation des données et la collaboration entre les équipes. Une frontière plus stricte encourage une spécialisation, tandis qu’une frontière plus souple simplifie la coordination. L’objectif est de trouver un équilibre qui soutient les besoins actuels de l’entreprise sans surconcevoir pour des scénarios futurs [[19]].
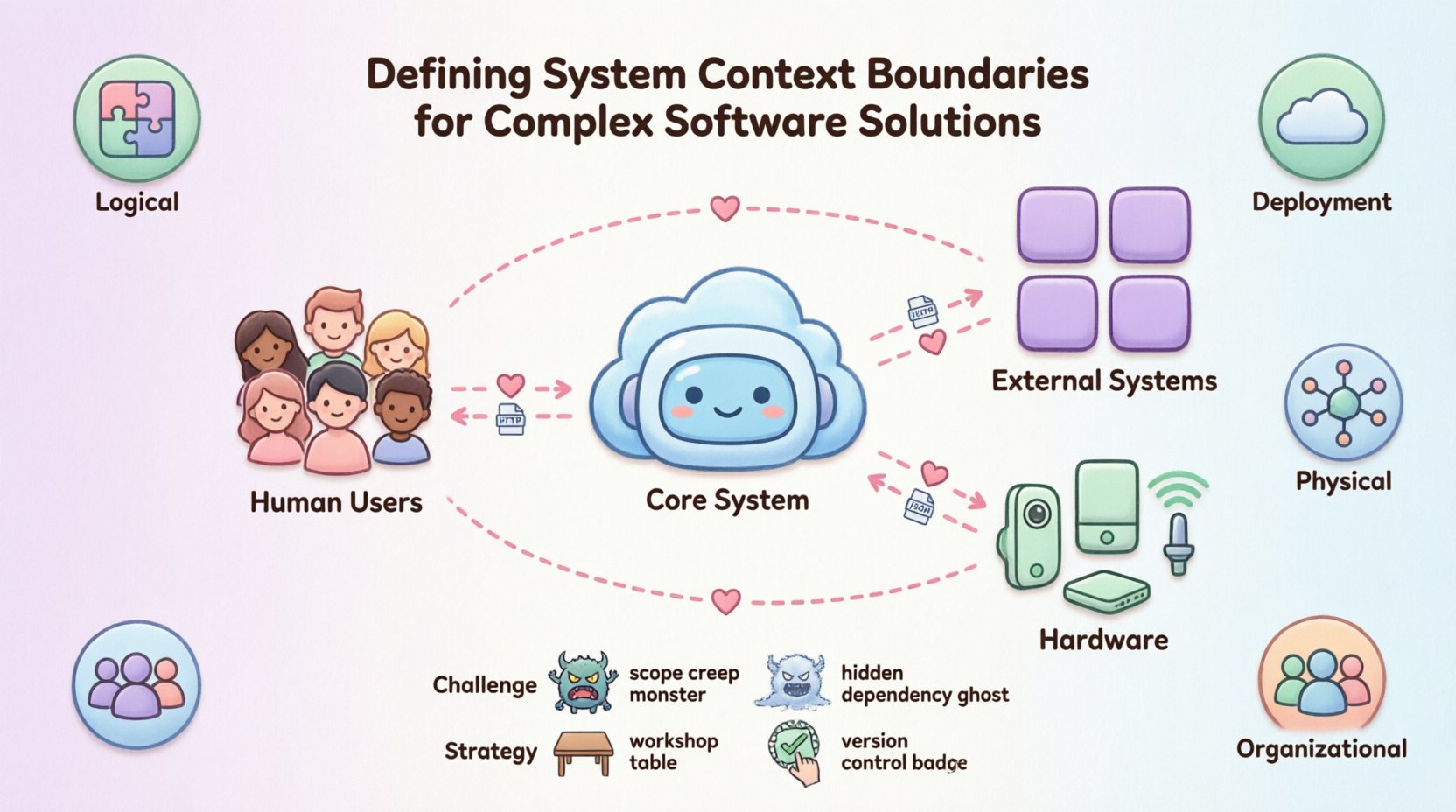
👥 Catalogage des acteurs externes
Une fois le système central défini, la prochaine étape consiste à identifier les acteurs. Les acteurs sont les entités qui interagissent avec le système. Ils ne font pas partie du système lui-même, mais ils sont essentiels à son fonctionnement. Une mauvaise identification des acteurs est une source courante de confusion architecturale.
Les acteurs se divisent généralement en trois catégories :
-
Utilisateurs humains : Ce sont les personnes qui interagissent directement avec le système. Cela inclut les administrateurs, les utilisateurs finaux ou les opérateurs. Leur rôle consiste à initier des actions ou à consommer des données.
-
Systèmes externes : Ce sont d’autres applications logicielles avec lesquelles le système communique. Cela peut être un processeur de paiement, une base de données héritée ou une API tierce. Le système les traite comme des boîtes noires [[1]].
-
Matériel : Dans certains contextes, les dispositifs physiques sont des acteurs. Cela inclut les capteurs, les dispositifs IoT ou des serveurs spécialisés qui hébergent l’application.
Il est crucial d’être précis lors de l’étiquetage des acteurs. Au lieu de simplement étiqueter un groupe comme « Utilisateurs », précisez le rôle. Par exemple, « Client » est plus utile que « Utilisateur ». De même, lors de la gestion des systèmes externes, utilisez le nom du système plutôt que des termes génériques comme « Base de données », sauf si le type spécifique de base de données est sans importance. Cette précision aide à comprendre la nature de l’interaction [[32]].
🔗 Définition des interfaces et des flux de données
Les frontières ne sont pas seulement des lignes ; ce sont des portes. Les données et les requêtes circulent à travers ces portes. Définir les interfaces à la frontière est aussi important que de définir la frontière elle-même. Une interface définit le contrat entre le système et l’acteur.
Les considérations clés pour la définition des interfaces incluent :
-
Protocole : La communication utilise-t-elle HTTP, TCP ou une file d’attente de messages ? Le protocole détermine la nature de l’interaction.
-
Direction : Les données circulent-elles vers l’intérieur, vers l’extérieur ou dans les deux sens ? Certains acteurs n’envoient que des données (par exemple, un capteur), tandis que d’autres ne les consomment que (par exemple, un outil d’analyse).
-
Authentification : Comment est contrôlé l’accès ? L’acteur a-t-il besoin d’une clé API, d’un jeton OAuth ou d’un certificat ?
-
Format : Quelle structure de données est échangée ? JSON, XML ou binaire ?
Documenter ces détails au niveau du contexte évite les problèmes ultérieurs. Si l’interface est floue, les développeurs feront des hypothèses qui pourraient entrer en conflit avec les exigences réelles. Par exemple, supposer qu’un format de données est synchrone alors qu’il est en réalité asynchrone peut entraîner des problèmes de blocage dans l’architecture.
| Type de frontière | Définition | Implication |
|---|---|---|
| Frontière logique | Définie par les modules de code ou les espaces de noms. | Facile à modifier, mais le déploiement peut être couplé. |
| Frontière de déploiement | Définie par l’emplacement où le code s’exécute. | Impacte le dimensionnement et les coûts d’infrastructure. |
| Frontière physique | Définie par la topologie du réseau ou le matériel. | Impacte la latence et les politiques de sécurité. |
| Frontière organisationnelle | Définie par la propriété par équipe. | Impacte les canaux de communication et la vitesse des décisions. |
⚠️ Défis courants dans la définition des frontières
Même avec une méthodologie claire, définir des frontières peut être difficile. Les équipes rencontrent souvent des pièges spécifiques qui dégradent la qualité de l’architecture. Reconnaître ces défis tôt permet de les atténuer.
1. Le piège de l’élargissement du périmètre
À mesure que les exigences évoluent, la frontière du système s’étend souvent. Les fonctionnalités qui étaient autrefois « sympa à avoir » deviennent des exigences fondamentales. Sans gouvernance stricte, le diagramme de contexte du système devient rapidement obsolète. La solution consiste à considérer le diagramme comme un document vivant qui nécessite un contrôle formel des modifications de frontière [[16]].
2. Dépendances cachées
Parfois, un système dépend d’un service qui n’est pas immédiatement évident. Par exemple, un microservice peut dépendre d’un magasin de configuration partagé qui n’est pas représenté dans le diagramme. Ce couplage caché crée de la fragilité. Toute dépendance doit être explicite dans la vue de contexte [[15]].
3. Sur-abstraction
Inversement, les systèmes peuvent être regroupés de manière trop large. Regrouper plusieurs domaines métier distincts dans un seul « Système » rend impossible la compréhension du flux interne. Si le système contient trop de sous-domaines, il est souvent préférable de diviser la frontière en plusieurs systèmes [[8]].
4. État implicite
Les dépendances basées sur un état implicite sont dangereuses. Si le système A suppose que le système B est dans un état spécifique, un changement dans le système B casse le système A. Les frontières doivent imposer un transfert d’état explicite. Les données doivent être transmises, et non supposées.
🔄 Stratégies pour le raffinement itératif
Définir des frontières est rarement une opération ponctuelle. C’est un processus itératif qui évolue avec la maturité du système. Les stratégies suivantes aident à maintenir la clarté au fil du temps.
-
Ateliers : Organisez des sessions avec les parties prenantes pour valider la frontière. Demandez-leur de décrire le système à leur manière. Si leur description diffère du diagramme, cela indique un manque de compréhension [[29]].
-
Analyse du code : Utilisez des outils d’analyse statique pour identifier les dépendances réelles. Comparez ces résultats au diagramme de contexte documenté afin de garantir l’exactitude.
-
Boucles de retour : Encouragez les développeurs à signaler les écarts entre le schéma et le code. Créez une culture où la documentation est partagée par l’équipe, et non seulement par l’architecte.
-
Gestion des versions : Gérez les versions des schémas en parallèle avec le code. Cela garantit que les décisions historiques peuvent être retracées jusqu’à une vue contextuelle précise.
Le raffinement implique également l’élagage. Si une connexion vers un acteur externe est peu utilisée, elle doit être revue. Supprimer la complexité inutile de la vue contextuelle réduit la charge cognitive et améliore la maintenabilité [[23]].
🔗 Connecter le contexte à la conception interne
Le schéma de contexte du système n’est pas une île. Il sert d’ancrage aux schémas de niveau inférieur. Dans le modélisme structuré, la vue contextuelle alimente la vue des conteneurs. Les conteneurs sont les principaux éléments de construction à l’intérieur de la frontière du système [[3]].
Lors du passage du contexte à la vue des conteneurs, assurez-vous de la cohérence. Les acteurs définis dans le schéma de contexte doivent correspondre aux points d’entrée des conteneurs. Si un système externe se connecte au « Système » dans le schéma de contexte, il doit exister un conteneur spécifique dans ce système qui expose l’interface.
Cette hiérarchie garantit la traçabilité. Si une modification est nécessaire dans un système externe, son impact peut être suivi depuis le schéma de contexte jusqu’au conteneur et au composant spécifiques. Cette traçabilité est essentielle pour l’évaluation des risques et l’analyse des impacts [[5]].
📅 Maintenance et contrôle de version
Le décalage documentaire est un tueur silencieux de l’architecture logicielle. Au fil du temps, le code évolue, mais les schémas restent statiques. Cela crée un décalage entre ce que l’équipe pense construire et ce qu’elle construit réellement. Pour y remédier :
-
Génération automatisée : Lorsque c’est possible, générez les schémas à partir des annotations de code ou des fichiers de configuration. Cela réduit l’effort manuel nécessaire pour les maintenir à jour [[25]].
-
Fréquence des revues : Intégrez les revues de schémas dans les réunions de planification de sprint ou les réunions de revue architecturale. Faites-en une étape standard de la définition de terminé.
-
Journaux de modifications : Maintenez un journal des modifications des frontières. Enregistrez la raison pour laquelle une frontière a été déplacée ou fusionnée. Cela fournit un contexte pour les architectes futurs.
Maintenir le contexte du système est un investissement. Il rapporte en temps d’intégration réduit, moins de bogues d’intégration et des prises de décision plus claires. En traitant la frontière comme un artefact de première importance, les équipes s’assurent que leurs solutions logicielles restent compréhensibles et gérables à mesure qu’elles grandissent [[22]].
🧩 Gestion des contextes hérités
Tous les systèmes ne commencent pas à partir d’une feuille blanche. De nombreuses organisations héritent de systèmes anciens où les frontières n’ont jamais été clairement définies. Dans ces cas, l’objectif est de reconstruire le contexte sans perturber les opérations.
L’approche consiste à :
-
Cartographie du trafic : Analysez les journaux réseau et les passerelles API pour identifier les connexions actives.
-
Entrevues avec les opérateurs : Parlez aux personnes qui gèrent le système. Elles connaissent souvent les systèmes externes critiques.
-
Création d’une vue « Tel qu’il est » : Documentez l’état actuel avec précision, même s’il est désordonné. Cela fournit une base de départ pour le restructurage.
-
Refactoring progressif : Une fois la frontière connue, déconnectez progressivement les dépendances. Déplacez la frontière vers un état plus propre au fil du temps.
Les systèmes anciens souffrent souvent du syndrome du « Système-Dieu », où tout est connecté à tout. L’objectif ici n’est pas de tout corriger d’un coup, mais d’identifier la frontière centrale et de commencer à isoler les composants. Cette approche progressive minimise les risques tout en améliorant la clarté [[28]].
🛡️ Sécurité et considérations relatives aux frontières
La sécurité est inextricablement liée aux frontières. Une frontière définit où s’arrête la confiance et où commence la vérification. Les acteurs externes ne doivent jamais être implicitement considérés comme fiables. La frontière est la zone périphérique où les contrôles de sécurité sont appliqués.
Les principaux aspects de sécurité à considérer incluent :
-
Authentification à la périphérie : Toute requête traversant la frontière doit être authentifiée. Cela empêche l’accès non autorisé aux composants internes.
-
Minimisation des données : Transmettez uniquement les données nécessaires à l’interaction à travers la frontière. Réduire l’exposition des données diminue l’impact potentiel des violations de sécurité.
-
Chiffrement : Les données en transit à travers la frontière doivent être chiffrées. Cela protège les informations sensibles contre toute interception.
-
Limitation de débit : Les frontières sont de bons endroits pour imposer des limites de débit afin de prévenir les attaques par déni de service provenant d’acteurs externes.
En définissant clairement la frontière, les équipes de sécurité peuvent configurer plus efficacement les pare-feu, les proxys et les passerelles. Elles savent exactement quel trafic attendre et quel trafic bloquer.
🏁 Conclusion : La clarté comme avantage stratégique
Définir les frontières du contexte du système n’est pas une simple formalité bureaucratique — c’est une discipline stratégique qui transforme l’ambiguïté en alignement. Lorsque les architectes et les équipes consacrent du temps à tracer des frontières claires et bien documentées, elles créent davantage qu’un simple schéma : elles construisent une compréhension partagée, réduisent la charge cognitive et établissent des repères qui permettent une croissance durable.
Les systèmes logiciels les plus résilients ne sont pas ceux qui possèdent le code le plus ingénieux, mais ceux dont l’architecture peut être comprise, évoluée et fait confiance par tous ceux qui y ont accès. En traitant la définition des frontières comme une pratique fondamentale — soutenue par une amélioration itérative, une collaboration avec les parties prenantes et une documentation vivante — vous doterez votre organisation des moyens de naviguer dans la complexité avec confiance.
Souvenez-vous : chaque frontière que vous tracez est une promesse. Une promesse concernant la propriété, les contrats, les attentes. Honorez ces promesses avec clarté, et vos systèmes vous récompenseront par une maintenabilité, une évolutivité et une valeur durable. En fin de compte, la clarté ne gagne pas seulement sur la complexité — elle la rend gérable.
📚 Références
- Outil de diagrammes C4 par Visual Paradigm – Visualisez l’architecture logicielle facilement: Cette ressource met en avant un outil qui permet aux architectes logiciels de créer des diagrammes de systèmes clairs, évolutifs et maintenables en utilisant la méthode de modélisation C4.
- Guide ultime pour la visualisation du modèle C4 à l’aide des outils d’IA de Visual Paradigm: Ce guide explique comment tirer parti de l’intelligence artificielle pour automatiser et améliorer la visualisation du modèle C4 afin de concevoir des architectures plus intelligentes.
- Utilisation de l’AI C4 Studio de Visual Paradigm pour une documentation d’architecture simplifiée: Une exploration de l’AI C4 Studio amélioré, qui permet aux équipes de créer des documents de documentation d’architecture logicielle propres, évolutifs et hautement maintenables.
- Guide pour débutants sur les diagrammes du modèle C4: Un tutoriel étape par étape conçu pour aider les débutants à créer des diagrammes du modèle C4 à tous les quatre niveaux d’abstraction : Contexte, Conteneurs, Composants et Code.
- Le guide ultime pour C4-PlantUML Studio : Révolutionner la conception d’architecture logicielle: Cet article aborde l’intégration de l’automatisation pilotée par l’IA avec la flexibilité de PlantUML afin de simplifier le processus de conception d’architecture logicielle.
- Un guide complet sur l’AI C4 PlantUML Studio de Visual Paradigm: Un guide détaillé expliquant comment cet atelier spécialisé transforme le langage naturel en diagrammes C4 précis et multicouches.
- C4-PlantUML Studio : générateur de diagrammes C4 alimenté par l’IA: Cette présentation des fonctionnalités décrit un outil d’IA qui génère automatiquement des diagrammes d’architecture logicielle C4 directement à partir de descriptions textuelles simples.
- Tutoriel complet : génération et modification de diagrammes de composants C4 avec un chatbot alimenté par l’IA: Un tutoriel pratique démontrant comment utiliser un chatbot alimenté par l’IA pour générer et affiner des diagrammes de composants C4 à travers une étude de cas réelle.
- Sortie de la prise en charge complète du modèle C4 dans Visual Paradigm: Un communiqué officiel concernant l’inclusion d’une prise en charge complète du modèle C4 pour gérer des diagrammes d’architecture à plusieurs niveaux d’abstraction au sein de la plateforme.
- Générateur d’IA du modèle C4 : automatisation des diagrammes pour les équipes DevOps et cloud: Cet article explique comment les invites conversationnelles d’IA automatisent l’intégralité du cycle de vie du modèle C4, assurant ainsi cohérence et rapidité pour les équipes techniques.