









L’architecture d’entreprise nécessite des définitions précises pour garantir que les systèmes fonctionnent comme prévu. Les données constituent la base de cette fonctionnalité. Lors de la modélisation dans le cadre ArchiMate, comprendre où se trouvent les données et comment elles interagissent avec les applications est essentiel. La couche Application fournit un contexte spécifique pour visualiser le traitement de l’information. Ce guide détaille la méthodologie pour structurer les modèles de données au sein de cette couche spécifique. Nous explorerons les relations, les éléments et les bonnes pratiques nécessaires à une représentation précise.
📊 Le contexte de la couche Application
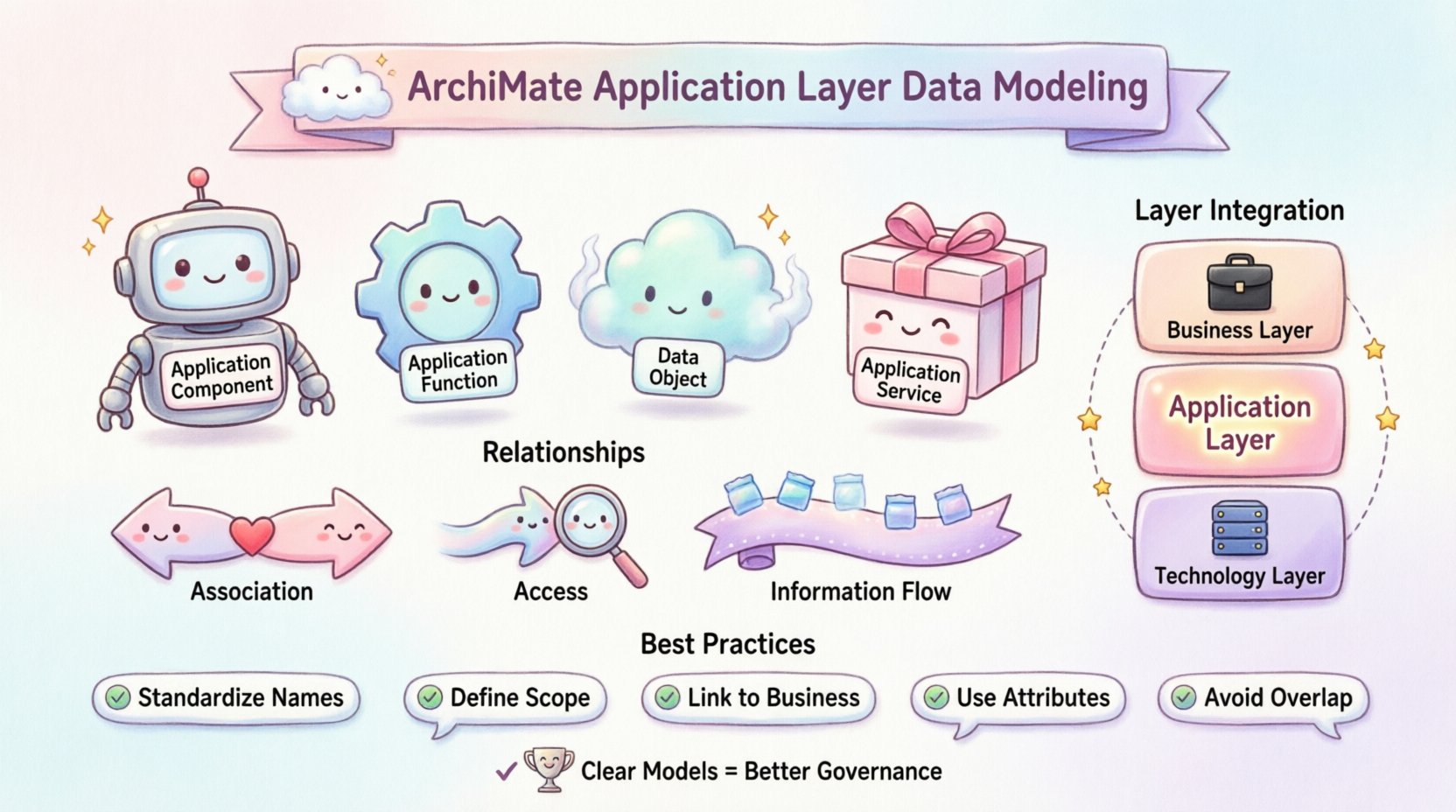
La couche Application agit comme interface entre les exigences métiers et la mise en œuvre technique. Elle décrit les composants logiciels et les services qui fournissent des fonctionnalités à l’organisation. Contrairement à la couche Métier, qui se concentre sur les processus et les rôles, la couche Application se concentre sur le commentdu traitement des données. Les objets de données de cette couche représentent l’état de l’information géré par des applications spécifiques.
Structurer ces modèles correctement évite toute ambiguïté. Un modèle clair garantit que les parties prenantes comprennent quelle application possède quelles données. Cette clarté soutient la gouvernance et réduit la dette technique. Voici les composants principaux impliqués dans cette structure :
- Composant Application : Une unité logicielle déployable qui traite des informations.
- Fonction Application : Une fonction logique effectuée par un composant application.
- Objet de données : L’état de l’information ou le document géré par l’application.
- Service Application : La capacité offerte par l’application au monde extérieur.
🔗 Définition des relations pour les données
Les relations définissent le flux et la dépendance des données au sein de l’architecture. Dans la couche Application, des types spécifiques de relations cartographient le déplacement de l’information entre les fonctions et les composants. Comprendre ces cartographies est essentiel pour suivre l’origine des données.
1. Association avec les objets de données
Une AssociationUne relation d’association indique qu’une fonction ou un composant spécifique interagit avec un objet de données. C’est le lien le plus courant dans la modélisation des données. Elle implique que la fonction lit, écrit ou modifie l’objet de données.
- Direction : Généralement bidirectionnelle, bien que les sémantiques puissent indiquer un sens de flux.
- Utilisation : Utilisez-le pour montrer la propriété ou l’accès direct.
- Exemple : Une « Fonction de gestion des clients » est associée à l’objet de données « Fiche client ».
2. Relations d’accès
Bien que similaire à l’association, une Accès relation spécifie qu’une fonction accède à un objet de données. Cela est souvent utilisé lorsque l’interaction est très lourde en lecture ou lorsque la fonction est un client accédant à un magasin de données géré par un autre composant.
- Utilisation :Différencie entre la propriété et l’utilisation.
- Clarté :Aide à identifier quel composant est la source de vérité.
3. Flux d’information
Flux d’information décrit le déplacement des données d’un élément à un autre. Dans la couche Application, cela se produit souvent entre des fonctions ou entre une fonction et une entité externe.
- Déclencheur :Les données se déplacent lorsqu’un événement spécifique se produit.
- Format :Le flux transporte un type spécifique d’objet de données.
- Contexte :Utile pour la cartographie d’intégration.
📝 Cartographie des objets de données vers les fonctions
Pour structurer les données de manière efficace, il faut cartographier les objets sur les fonctions qui les manipulent. Cette cartographie crée une matrice de propriété des données. Le tableau suivant décrit comment les différents éléments de données interagissent avec les fonctions applicatives.
| Type d’élément de données | Interaction fonctionnelle | Type de relation |
|---|---|---|
| Enregistrement de transaction | Fonction de traitement | Accès |
| Données maîtres | Fonction de gestion | Association |
| Fichier journal | Fonction de surveillance | Accès |
| Sortie de rapport | Fonction de reporting | Flux d’information |
Cette approche structurée aide à identifier la redondance des données. Si plusieurs fonctions sont associées au même objet de données, il faut vérifier si elles partagent la même source ou si l’une est une copie. Cette vérification soutient la cohérence des données.
🛠️ Meilleures pratiques pour la modélisation
La cohérence est essentielle lors de la construction de ces modèles. Respecter les conventions établies garantit que l’architecture reste compréhensible au fil du temps. Les pratiques suivantes doivent être intégrées au processus de modélisation.
- Standardisez les conventions de nommage : Assurez-vous que les objets de données ont des noms clairs et uniques. Évitez les abréviations non documentées ailleurs.
- Définissez clairement le périmètre : Déterminez si un objet de données est logique ou physique. Le niveau Application traite généralement des structures de données logiques.
- Liez au niveau Métier : Revenez aux objets métiers à partir des objets de données. Cela garantit que le contexte métier est préservé.
- Utilisez les attributs : Définissez des attributs pour les objets de données afin de décrire leur structure sans surcharger le schéma.
- Évitez les chevauchements : Ne modélisez pas le même objet de données dans plusieurs couches, sauf si une raison spécifique le justifie (par exemple, logique vs physique).
⚠️ Pièges courants à éviter
Même les architectes expérimentés commettent des erreurs lors de la modélisation des données. Reconnaître ces schémas peut éviter un travail de reprise important. Voici les problèmes courants rencontrés au cours du processus de structuration.
1. Mélange des couches
Placer directement les objets métiers dans le niveau Application crée de la confusion. Les objets métiers appartiennent au niveau Métier. Le niveau Application doit contenir des objets de données représentant l’implémentation de ces concepts métiers.
- Correction : Associez l’objet métier à l’objet de données par une relation de réalisation.
- Impact : Le mélange des couches floute la frontière entre l’intention métier et la fonction système.
2. Sur-modélisation
Tenter de documenter chaque champ individuel d’une base de données au sein du niveau Application entraîne un encombrement. L’objectif de cette couche est de montrer les capacités et les flux, et non un schéma détaillé.
- Correction : Utilisez des objets de données de haut niveau. Descendez vers des modèles physiques uniquement lorsque cela est nécessaire pour une spécification technique.
- Impact : Garantit que l’architecture reste visible et maintenable.
3. Ignorer la persistance
Les modèles de données doivent tenir compte de la persistance. Certaines données sont temporaires (en mémoire), tandis que d’autres sont stockées (base de données). Ne pas distinguer ces cas peut conduire à des hypothèses erronées sur la résilience du système.
- Correction : Notez le mécanisme de persistance dans les attributs ou via une cartographie séparée au niveau de la couche Technologie.
- Impact : Précise les exigences relatives au cycle de vie des données et à la récupération.
🔗 Intégration avec les autres couches
La couche Application n’existe pas en isolation. Elle est connectée à la couche Métier et à la couche Technologie. Une intégration appropriée assure une architecture cohérente.
Connexion à la couche Métier
Les données de la couche Application soutiennent les processus métiers. Une Réalisation relation relie un objet métier à un objet de données d’application. Cela confirme que l’application soutient le besoin métier.
- Flux : Processus métier crée objet métier → Fonction application crée objet de données application.
- Avantage : Assure la traçabilité du besoin à la mise en œuvre.
Connexion à la couche Technologie
La couche Application dépend de la couche Technologie pour le stockage et le calcul.Déploiement Les relations cartographient les composants application aux nœuds technologie. Les objets de données de la couche Application peuvent être réalisés comme des magasins de données dans la couche Technologie.
- Cartographie : Objet de données application → Magasin de données technologie.
- Avantage : Valide que l’infrastructure technique soutient les besoins logiques en données.
📈 Gestion de la gouvernance des données
Une fois le modèle structuré, il sert de référence pour la gouvernance. Les politiques de gouvernance des données peuvent être appliquées aux éléments du modèle. Cela garantit que les exigences de conformité et les normes de qualité sont respectées.
- Propriété : Attribuez des responsables de données à des objets de données spécifiques du modèle.
- Classification : Étiquetez les objets de données selon leur niveau de sensibilité (par exemple, Public, Interne, Confidentiel).
- Rétention : Définissez des politiques de rétention liées aux objets de données.
- Contrôle d’accès :Mettez en correspondance les rôles de la couche Métier avec les fonctions qui accèdent aux données.
Cette couche de gouvernance ajoute de la valeur au-delà de la simple visualisation. Elle transforme le modèle d’architecture en un outil de gestion. Les revues régulières de ces modèles assurent que les politiques de gouvernance restent alignées sur le comportement réel du système.
🧩 Scénarios avancés
Parfois, le modélisation standard est insuffisante pour des scénarios complexes. Les situations avancées exigent une attention particulière aux relations et aux contraintes.
1. Transformations de données complexes
Lorsque les données subissent une transformation importante, plusieurs fonctions peuvent être impliquées. Une fonction peut lire des données brutes et produire des données traitées.
- Modélisation :Utilisez deux objets de données distincts pour représenter les états d’entrée et de sortie.
- Lien :Connectez-les via la fonction de transformation.
- Avantage :Montre clairement la valeur ajoutée par la transformation.
2. Ressources de données partagées
Plusieurs applications peuvent partager la même ressource de données. Cela peut créer un goulot d’étranglement potentiel ou un risque de sécurité.
- Modélisation :Créez un seul objet de données et reliez-y plusieurs fonctions d’application.
- Analyse :Utilisez cette vue pour analyser les stratégies de contention et de verrouillage.
- Avantage :Met en évidence les dépendances et les risques partagés.
3. Données historiques
Les applications doivent souvent stocker des versions historiques des données. Cela nécessite de modéliser des attributs basés sur le temps.
- Modélisation :Ajoutez des attributs à l’objet de données pour indiquer la version ou les dates effectives.
- Relation :Assurez-vous que la fonction gère correctement la logique de mise à jour.
- Avantage :Soutient les traçabilités d’audit et les exigences de conformité.
🔍 Revue et validation
Après avoir structuré les modèles de données, une validation est nécessaire. Ce processus garantit que le modèle reflète fidèlement l’état cible. La validation consiste à vérifier la complétude, la cohérence et la correction.
- Complétude :Tous les objets de données critiques sont-ils représentés ?
- Cohérence :Les noms et les définitions sont-ils cohérents dans l’ensemble du modèle ?
- Exactitude :Les relations reflètent-elles précisément le comportement du système ?
Il est recommandé d’impliquer des experts du domaine pendant cette phase. Ils peuvent vérifier si les flux modélisés correspondent à la réalité opérationnelle réelle. Ce cycle de retour d’information améliore la précision de l’architecture.
🔄 Maintenance du modèle
L’architecture n’est pas une tâche ponctuelle. Les systèmes évoluent, et les modèles de données doivent évoluer avec eux. La maintenance consiste à suivre les modifications et à mettre à jour le modèle en conséquence.
- Gestion des changements :Intégrez les mises à jour d’architecture dans le processus de demande de changement.
- Gestion des versions :Gardez un historique des versions du modèle pour suivre son évolution.
- Documentation :Mettez à jour la documentation associée lorsque les éléments du modèle changent.
La synchronisation régulière entre le modèle et les systèmes réels empêche le décalage. Le décalage survient lorsque le modèle ne reflète plus la réalité, le rendant inutile pour la planification.
📉 Mesure du succès
Comment savoir si l’effort de structuration a été couronné de succès ? Plusieurs indicateurs peuvent être utilisés pour mesurer l’efficacité de la modélisation des données.
- Réduction de la redondance :Moins de magasins de données en double identifiés.
- Meilleure clarté :Les parties prenantes peuvent facilement suivre les flux de données.
- Intégration plus rapide :De nouveaux systèmes peuvent être intégrés sur la base des contrats de données définis.
- Meilleure gouvernance :Les politiques de données sont appliquées de manière cohérente.
Ces indicateurs fournissent une base quantitative pour l’effort architectural. Ils démontrent la valeur des modèles de données structurés pour l’organisation.
🎯 Résumé des éléments clés
Pour résumer, le modèle de données de la couche Application repose sur des éléments et des relations spécifiques. Un modèle réussi intègre ces composants de manière fluide.
- Éléments : Composants d’application, fonctions, services et objets de données.
- Relations : Association, accès, flux d’information et réalisation.
- Niveaux : Métier, Application, Technologie et Motivation.
- Processus : Définir, cartographier, valider et maintenir.
En suivant ces principes, les architectes peuvent créer des modèles robustes qui soutiennent la stratégie de données de l’organisation. Le résultat est une vision claire de la manière dont l’information génère de la valeur métier au sein du paysage technique.