











Concevoir des modèles de données pour les infrastructures modernes exige un changement fondamental de pensée. Les diagrammes traditionnels d’entités et de relations (ERD) convenaient bien aux architectures monolithiques, où une seule instance de base de données gérait toutes les transactions. Cependant, à mesure que les systèmes évoluent vers des environnements distribués, les règles d’intégrité des données et de cartographie des relations changent considérablement. Ce guide explore des modèles avancés de diagrammes ERD spécifiquement adaptés aux systèmes complexes de transactions distribuées. Nous examinerons comment modéliser la cohérence, gérer l’état à travers les services et visualiser les dépendances sans dépendre de produits logiciels spécifiques.
Dans un contexte distribué, la frontière entre la propriété des données devient floue. Une entité peut exister dans plusieurs magasins logiques, ce qui nécessite une définition claire de la manière dont les relations sont maintenues. Ce document propose une approche structurée pour modéliser ces complexités.
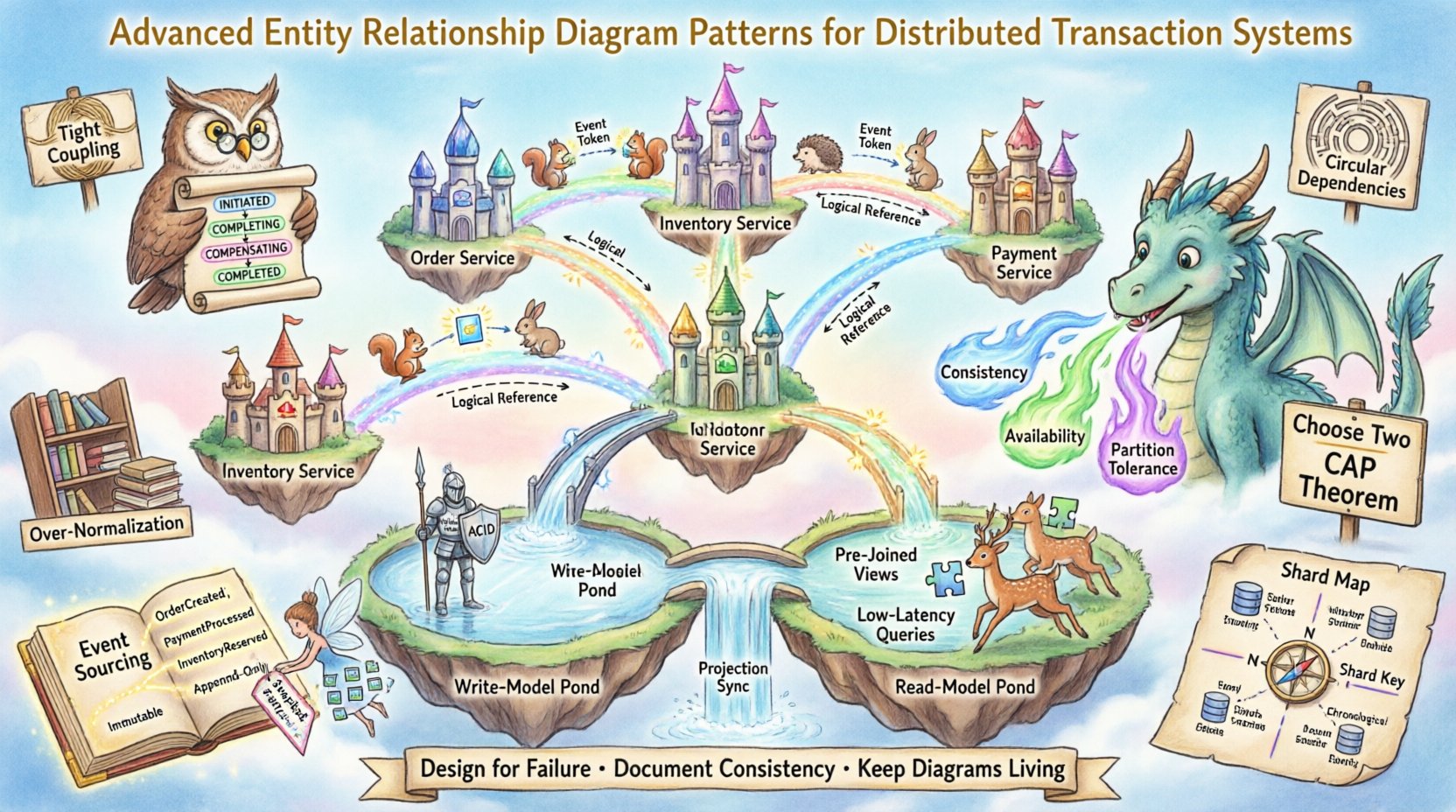
🧠 L’impact de l’architecture distribuée sur la modélisation des données
Avant de plonger dans des modèles spécifiques, il est essentiel de comprendre les contraintes imposées par les frontières réseau. Dans une architecture monolithique, une contrainte de clé étrangère garantit l’intégrité référentielle. Dans un système distribué, la latence réseau et les partitions potentielles signifient que la cohérence immédiate est souvent impossible ou prohibitivement coûteuse.
- Partitions réseau : Le théorème CAP indique qu’en cas de partition réseau, vous devez choisir entre la cohérence et la disponibilité.
- Propriété des données : Les services doivent posséder leurs propres données afin d’éviter un couplage étroit. Cela limite les relations de clés étrangères directes au-delà des frontières des services.
- Frontières des transactions : Les transactions globales s’étendant sur plusieurs bases de données sont généralement déconseillées en raison des risques liés aux performances et à la fiabilité.
Lors de la création d’un ERD pour cet environnement, le diagramme doit refléter les relations logiques plutôt que seulement les contraintes physiques. La représentation visuelle doit communiquer où se trouvent les données et comment elles sont synchronisées.
🔗 Gérer l’intégrité référentielle sans clés étrangères
Dans un système de transaction distribué, les clés étrangères physiques sont souvent absentes. En revanche, les relations logiques sont assurées par la logique d’application ou des événements asynchrones. Le diagramme ERD doit capturer clairement ces liens logiques.
1. Références d’identifiants logiques
Au lieu d’une contrainte de clé physique, les modèles utilisent des identifiants uniques. Lors du dessin du diagramme, indiquez qu’une relation est un lien logique.
- Utilisez des lignes pointillées pour représenter les dépendances logiques.
- Libellez la relation comme « Référence » plutôt que « Contrainte ».
- Précisez le type de données de l’ID afin d’assurer la sécurité des types dans le schéma.
2. Référencement souple
Les suppressions définitives sont risquées dans les systèmes distribués. Un modèle courant consiste à marquer les enregistrements comme supprimés plutôt que de les supprimer. Le diagramme ERD doit inclure un champ d’état.
- Inclure un champ
is_activeoustatuscolonne. - Documentez le cycle de vie de l’entité dans les notes du diagramme.
- Précisez comment les enregistrements orphelins sont traités lors d’un événement de suppression.
3. Modélisation de la cohérence éventuelle
Lorsque les données sont répliquées entre les services, la cohérence n’est pas immédiate. Le diagramme ERD doit visualiser le délai de réplication.
- Marquez les entités qui sont des répliques en lecture seule.
- Différenciez entre la « source de vérité » et la « version mise en cache ».
- Indiquez le mécanisme utilisé pour synchroniser les modifications (par exemple, Capture des modifications de données).
⚡ Modélisation du patron Saga
Le patron Saga est une pierre angulaire des transactions distribuées. Il gère les opérations longues en divisant une transaction en une séquence de transactions locales. Chaque transaction locale met à jour les données au sein d’un service spécifique et déclenche l’étape suivante.
1. Représentation des machines d’état
Étant donné que les Sagas reposent sur l’état, le MCD doit modéliser explicitement les transitions d’état du processus.
- Créez une
SagaInstanceentité. - Définissez des états tels que
INITIÉ,EN COURS DE COMPLÉTION,EN COURS DE COMPENSATION, etTERMINÉ. - Liez l’instance Saga aux entités métiers spécifiques qu’elle affecte.
2. Transactions de compensation
Si une étape échoue, la Saga doit annuler les étapes précédentes. Le diagramme doit montrer les relations inverses.
- Documentez l’action de compensation pour chaque étape.
- Assurez-vous que la table
SagaLogcapture l’historique de toutes les étapes. - Visualisez le chemin d’annulation sous forme d’une ligne de relation distincte.
3. Déclencheurs d’événements
Les Sagas sont souvent pilotées par des événements. Le MCD doit montrer comment les événements déclenchent des changements d’état.
- Incluez un
Journal des événementstableau. - Associez les événements aux transitions d’état spécifiques de la Saga.
- Indiquez quels services consomment quels événements.
📊 Comparaison des modèles de cohérence
Comprendre les compromis entre les différents modèles de cohérence est essentiel pour une conception précise du schéma ERD. Le tableau ci-dessous décrit les caractéristiques des modèles courants.
| Modèle | Niveau de cohérence | Complexité du schéma ERD | Meilleur cas d’utilisation |
|---|---|---|---|
| Validation en deux phases | Fort | Faible | Coordination interne des services |
| Orchestration de Saga | Éventuelle | Élevé | Processus métier longs |
| Chorégraphie de Saga | Éventuelle | Moyen | Microservices faiblement couplés |
| Modèle de lecture CQRS | Éventuelle | Moyen | Charge de lecture élevée |
| Sourcing d’événements | Fort (par agrégat) | Élevé | Traçabilité des audits et reconstruction d’état |
🔄 Séparation des responsabilités Commande-Requête (CQRS)
CQRS sépare les modèles de lecture et d’écriture. Cela signifie que le MCD pour le côté écriture différera considérablement du MCD pour le côté lecture.
1. Conception du modèle d’écriture
Le modèle d’écriture se concentre sur l’intégrité des données et les règles métiers.
- Normalisez les données pour réduire la redondance.
- Appliquez des règles de validation strictes à la création.
- Maintenez le schéma rigide pour éviter les erreurs logiques.
2. Conception du modèle de lecture
Le modèle de lecture se concentre sur les performances et la vitesse des requêtes.
- Dénormalisez les données pour éviter les jointures.
- Incluez des champs pré-jointes pour les requêtes fréquentes.
- Structurez les tables en fonction des exigences de l’interface utilisateur plutôt que de la logique.
3. Mécanisme de synchronisation
Le MCD doit montrer comment le modèle d’écriture met à jour le modèle de lecture.
- Utilisez des entités de projection pour représenter le flux.
- Documentez le délai entre la disponibilité de l’écriture et celle de la lecture.
- Incluez un processus de reconciliation pour le décalage des données.
🗂️ Fractionnement et clés de partition
Le dimensionnement nécessite souvent le fractionnement des données sur plusieurs nœuds. Le MCD doit refléter la manière dont les données sont réparties pour assurer une interrogation efficace.
1. Identification de la clé de fractionnement
La clé de fractionnement détermine quel nœud détient les données.
- Marquez clairement la clé de fractionnement dans la définition de l’entité.
- Assurez-vous que la clé est fréquemment utilisée dans les requêtes.
- Évitez les clés qui entraînent une répartition déséquilibrée des données.
2. Relations entre fractionnements
Les relations qui s’étendent sur plusieurs fractionnements sont coûteuses. Le MCD doit mettre en évidence ces cas.
- Utilisez une notation spécifique pour les liens entre fractionnements.
- Minimisez le nombre de relations qui traversent les limites des fractionnements.
- Considérez la dénormalisation pour éviter les jointures entre fractionnements.
3. Indexs globaux versus locaux
Les stratégies d’indexation diffèrent selon le modèle de fractionnement.
- Les index locaux sont efficaces pour les requêtes sur une seule partition.
- Les index globaux nécessitent un balayage de toutes les partitions, ce qui affecte les performances.
- Documentez quels index sont locaux et quels index sont globaux.
📜 L’approche par événements et l’état immuable
L’approche par événements stocke l’état d’une entité sous forme de séquence d’événements. Cela modifie la manière dont le schéma ERD représente l’entité elle-même.
1. Le magasin d’événements
L’entité principale devient le journal d’événements.
- Créez une
EventStreamtable. - Stockez des métadonnées telles que
event_id,timestamp, etaggregate_id. - Assurez-vous que le contenu est stocké sous forme de données structurées.
2. Les agrégats
Les agrégats sont les entités racines qui déclenchent des événements.
- Liez l’ID de l’agrégat au flux d’événements.
- Ne stockez pas l’état actuel comme colonne.
- Reconstruisez l’état en rejouant les événements à partir du journal.
3. La prise de capture d’état
Pour optimiser les performances, des captures d’état de l’état actuel peuvent être stockées.
- Créez une
Snapshottable. - Liez la capture d’état à l’ID de l’agrégat.
- Documentez le numéro de version pour l’instantané.
🛡️ Les pièges courants et les mauvaises pratiques
Même avec des modèles avancés, des erreurs peuvent survenir. Reconnaître les mauvaises pratiques aide à maintenir la santé du système.
- Couplage étroit :Évitez de faire référence directement aux entités d’autres services. Utilisez des identifiants à la place.
- Dépendances circulaires :Assurez-vous qu’Entity A ne dépend pas d’Entity B si Entity B dépend d’Entity A.
- Sur-normalisation :Dans les systèmes à forte lecture, une normalisation excessive nuit aux performances.
- Ignorer les fuseaux horaires :Les systèmes distribués fonctionnent à l’échelle mondiale. Stockez les horodatages en UTC.
- Absence d’idempotence :Assurez-vous que les opérations peuvent être répétées sans effets secondaires.
🔄 Évolution du schéma et versioning
Les systèmes distribués évoluent plus rapidement que les monolithes. Le schéma ERD doit permettre les modifications du schéma sans briser les services existants.
1. Compatibilité descendante
Les modifications du schéma ne doivent pas briser les consommateurs.
- Ajoutez uniquement des champs, ne supprimez ni ne renommez jamais immédiatement les champs existants.
- Dépréciez progressivement les champs au fil du temps.
- Versionnez les contrats API en parallèle du schéma.
2. Stratégies de migration
La gestion de la migration des données en production exige une grande prudence.
- Utilisez les modèles d’expansion et de contraction pour le déploiement.
- Assurez-vous que le vieux schéma reste lisible pendant la transition.
- Documentez le plan de retour arrière en cas d’échec de la migration.
🖼️ Visualisation des dépendances entre services
Un ERD standard affiche les tables au sein d’une seule base de données. Un ERD distribué doit montrer les services.
1. Frontières des services
Regroupez les tables par le service qui les possède.
- Utilisez des conteneurs distincts pour chaque service.
- Étiquetez le conteneur avec le nom du service.
- Montrez le flux de données entre les conteneurs à l’aide de flèches.
2. Flux de données
Indiquez comment les données se déplacent entre les services.
- Utilisez des lignes pleines pour les appels synchrones.
- Utilisez des lignes pointillées pour les événements asynchrones.
- Étiquetez le sens du flux de données.
3. Points d’intégration
Identifiez où les services interagissent.
- Mettez en évidence les passerelles API dans le schéma.
- Marquez les brokers de messages comme intermédiaires.
- Documentez le protocole utilisé pour chaque intégration.
🏁 Considérations finales pour les concepteurs de systèmes
Concevoir pour les transactions distribuées est un exercice de gestion de la complexité. Le MCD est un outil pour communiquer cette complexité à l’équipe. Il ne doit pas seulement montrer des tables ; il doit montrer la logique du système.
- Concentrez-vous sur les relations logiques plutôt que sur les contraintes physiques.
- Documentez les garanties de cohérence pour chaque relation.
- Prévoyez les scénarios d’échec dans le modèle de données.
- Maintenez le schéma à jour au fur et à mesure que le système évolue.
En suivant ces modèles, vous créez un plan directeur qui soutient la haute disponibilité et l’intégrité des données. Le schéma devient un document vivant qui guide le développement et la maintenance.