











Les diagrammes entité-association (ERD) sont au cœur d’une architecture de données solide. Ils fournissent le plan visuel de la manière dont les informations sont structurées, stockées et accessibles au sein d’un système de base de données. Malgré leur importance cruciale, le paysage entourant la conception des ERD est souvent brouillé par des récits marketing. Les fournisseurs et les consultants présentent fréquemment les outils de modélisation comme des solutions miracles capables de résoudre instantanément des défis complexes de modélisation des données. Cette approche néglige la logique rigoureuse nécessaire pour construire un environnement de données durable.
Pour construire des systèmes durables, nous devons aller au-delà de la hype. Nous devons comprendre les réalités techniques des relations, des contraintes et de la normalisation. Ce guide démonte les idées reçues courantes sur les ERD. Nous explorerons la différence entre un modèle théorique et une implémentation physique. L’objectif n’est pas de promouvoir un outil ou une méthode spécifique, mais de clarifier les principes qui régissent l’intégrité des données.
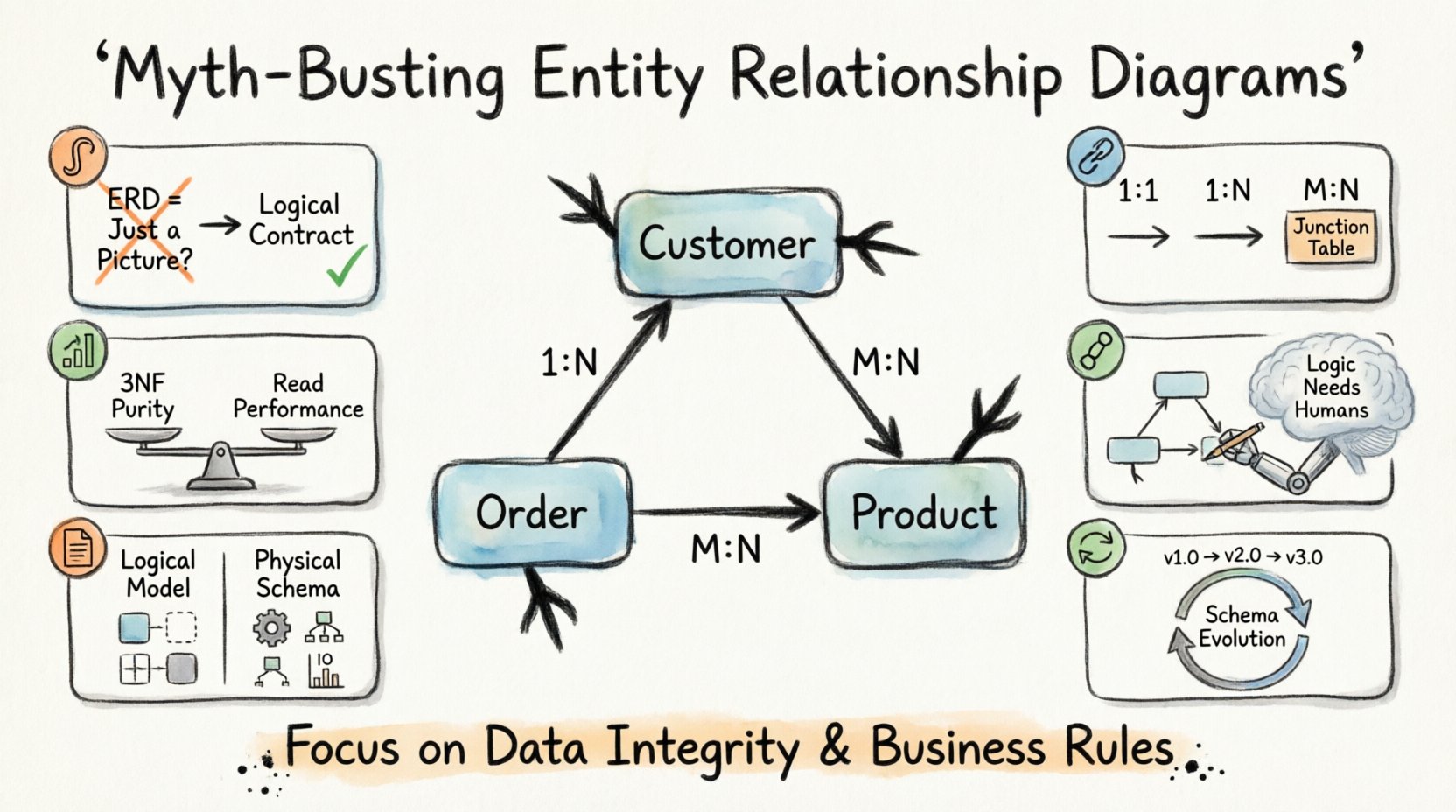
1. Le piège visuel : Un ERD n’est-il qu’un diagramme ? 🎨
L’un des mythes les plus répandus suggère qu’un diagramme entité-association n’est qu’un simple document de documentation. De nombreuses équipes traitent le diagramme comme un livrable post-projet, quelque chose de créé après l’écriture du code afin de satisfaire les parties prenantes. Cette vision est fondamentalement erronée. Un ERD est un contrat logique, pas une simple image.
Lorsqu’un ERD est traité comme une réflexion visuelle tardive, plusieurs risques apparaissent :
- Décalage du schéma : La structure de la base de données s’écarte du design prévu, entraînant une saisie de données incohérente.
- Blocs de performance : Les requêtes échouent parce que la structure sous-jacente ne supporte pas efficacement les jointures nécessaires.
- Perte d’intégrité des données : Les contraintes de clés étrangères sont ignorées, permettant l’existence de données orphelines.
Prenons en compte le cycle de vie d’une table de base de données. Il commence par une exigence métier. Il passe à un modèle logique, puis devient un schéma physique. L’ERD comble le fossé entre la logique métier et le stockage technique. Si le diagramme n’est pas la source de vérité, la base de données souffrira inévitablement d’ambiguïté.
Une modélisation de données efficace exige une attention rigoureuse aux détails. Ce n’est pas simplement dessiner des boîtes et des lignes. C’est définir les règles d’engagement pour les données. Chaque ligne dans un ERD représente une contrainte. Chaque boîte représente une unité de données qui doit être préservée. Ignorer cette réalité conduit à des systèmes fragiles et difficiles à maintenir.
2. Cardinalité et relations : au-delà des bases 🔗
La cardinalité définit la relation numérique entre les entités. Elle répond à la question : Combien d’instances d’une entité sont liées à des instances d’une autre ? Les supports marketing simplifient souvent cela en une relation un-à-plusieurs ou plusieurs-à-plusieurs sans expliquer les implications.
Comprendre la cardinalité est crucial pour les performances des requêtes et la cohérence des données. Il existe trois types principaux de relations :
- Un-à-un (1:1) : Chaque enregistrement dans la table A est lié à exactement un enregistrement dans la table B. Cela est souvent utilisé pour la sécurité ou la séparation des données.
- Un-à-plusieurs (1:N) : Un enregistrement dans la table A est lié à plusieurs enregistrements dans la table B. C’est la relation la plus courante dans les systèmes transactionnels.
- Plusieurs-à-plusieurs (M:N) : Plusieurs enregistrements dans la table A sont liés à plusieurs enregistrements dans la table B. Cela nécessite une table de jonction pour être résolu physiquement.
Une idée reçue courante est que les relations un-à-un sont toujours supérieures pour la séparation des données. Bien qu’elles offrent une isolation, elles peuvent introduire une complexité inutile. Fractionner les données en deux tables alors qu’une seule suffirait augmente la charge des jointures. Cela peut dégrader les performances lors des opérations de lecture.
Inversement, ignorer les relations plusieurs-à-plusieurs peut entraîner une duplication de données. Si vous tentez de stocker une liste de valeurs dans une seule colonne sans table de jonction appropriée, vous violez les règles de normalisation. Cela rend la mise à jour et la requête des données considérablement plus difficiles.
| Type de relation | Implémentation physique | Piège courant |
|---|---|---|
| Un-à-un | Clé étrangère dans l’une des deux tables | Sursegmentation des données |
| Un-à-plusieurs | Clé étrangère dans la table « Plusieurs » | Erreurs de référence circulaire |
| Plusieurs-à-plusieurs | Table de jonction avec deux clés étrangères | Contraintes uniques manquantes sur la table de jonction |
Lors de la conception de ces relations, vous devez tenir compte des règles métier. Un client a-t-il une seule adresse ou plusieurs ? Un produit appartient-il à une seule catégorie ou à plusieurs ? Le schéma doit refléter la réalité opérationnelle, et non une version idéalisée.
3. Normalisation : Le mythe de la 3FN 📊
La normalisation est une technique utilisée pour organiser les données afin de réduire la redondance. La Troisième Forme Normale (3FN) est souvent citée comme la norme d’or. Le mythe suggère qu’une base de données doit être entièrement normalisée jusqu’à la 3FN pour être considérée comme valide. Ce n’est pas toujours le cas.
La normalisation élimine les anomalies. Ce sont des problèmes qui surviennent lors de l’insertion, de la mise à jour ou de la suppression des données. Par exemple, si vous stockez le nom d’un client dans chaque enregistrement de commande, modifier le nom nécessite de mettre à jour des milliers de lignes. Il s’agit d’une anomalie de mise à jour. La normalisation corrige cela en déplaçant le nom vers une table client distincte.
Cependant, une application stricte de la 3FN peut nuire aux performances. Chaque relation nécessite une jointure. Les jointures sont coûteuses en termes de calcul. Dans les systèmes de reporting à fort trafic, une normalisation excessive peut ralentir l’exécution des requêtes. C’est là que la dénormalisation entre en jeu.
La dénormalisation consiste à introduire intentionnellement de la redondance afin d’améliorer les performances de lecture. C’est un compromis. Vous sacrifiez la vitesse d’écriture et l’efficacité du stockage au profit de lectures plus rapides. Cette décision ne doit jamais être prise à la légère. Elle exige une compréhension approfondie des modèles d’accès.
Les principaux éléments à considérer lors de la normalisation incluent :
- Équilibre lecture vs. écriture :Le système est-il plus orienté lecture ou écriture ?
- Complexité des requêtes :Quelle est la complexité des rapports requis ?
- Coûts de stockage :La redondance est-elle abordable ?
Suivre aveuglément la 3FN sans analyser la charge de travail est une recette pour une application lente. L’objectif est d’équilibrer l’intégrité des données avec les exigences de performance. Parfois, une vue dénormalisée avec soin est une meilleure solution qu’un schéma parfaitement normalisé.
4. Dépendance aux outils : Automatisation vs. Logique 🤖
Les outils modernes offrent des fonctionnalités telles que la génération automatique de schémas et l’ingénierie inverse. Les fournisseurs présentent ces capacités comme des gagnants de temps. Le mythe ici est que l’outil peut remplacer le concepteur. Un outil de diagrammation peut tracer des lignes, mais il ne peut pas comprendre le contexte métier.
La génération automatique produit souvent des schémas corrects sur le plan technique mais erronés sur le plan logique. Elle peut créer des tables en se basant sur l’inspection du code plutôt que sur les exigences métiers. Elle peut passer à côté de relations cachées qui ne sont pas explicitement codées.
Une surveillance humaine est essentielle. Le concepteur de données doit valider les résultats par rapport aux besoins réels de l’organisation. Les tâches clés qui ne peuvent pas être automatisées incluent :
- Définition des règles métiers :Déterminer quels attributs sont obligatoires.
- Gestion des cas limites :Décider comment gérer les valeurs nulles ou les suppressions douces.
- Optimisation pour la croissance future : Anticiper l’expansion des données.
Les outils sont des aides, pas des architectes. Ils facilitent la création du schéma, mais la logique réside dans l’esprit humain. Se fier uniquement à l’automatisation conduit à des systèmes rigides et difficiles à adapter. L’outil doit soutenir le flux de travail, pas le dicter.
5. Le fossé entre la conception et la mise en œuvre physique 📝
Il existe une différence marquée entre un modèle logique et un modèle physique. Le modèle logique décrit les entités et les relations de manière conceptuelle. Le modèle physique définit les types de données, les index et les contraintes.
Beaucoup d’équipes supposent que le modèle logique se traduit directement en base de données physique. Cela est rarement le cas. Les différents systèmes de bases de données ont des capacités différentes. Une relation qui fonctionne bien dans un système peut mal performer dans un autre.
Par exemple, les types de données varient. Un champ défini comme « Texte » dans un modèle logique pourrait nécessiter « VARCHAR(255) » ou « TEXT » dans la base de données physique. Les stratégies d’indexation diffèrent également. Un index qui accélère les requêtes dans un système peut ralentir les écritures dans un autre.
Lors du passage de la conception à la mise en œuvre, vous devez tenir compte de la pile technologique spécifique. Prenez en compte les ajustements suivants :
- Types de données : Assurez-vous que les types choisis correspondent au moteur de stockage.
- Index : Ajoutez des index pour les colonnes fréquemment interrogées.
- Partitionnement : Pensez à diviser les grandes tables pour une meilleure gestion.
- Contraintes : Décidez entre des vérifications au niveau de l’application et des contraintes au niveau de la base de données.
Ignorer ces différences entraîne un écart entre la conception et la réalité. Le système peut fonctionner, mais il ne sera pas optimisé. Une revue approfondie de la mise en œuvre physique est nécessaire pour s’assurer que la conception résiste aux charges.
6. Maintenance et évolution 🔄
Un autre mythe important est que la conception d’une base de données est statique. Une fois que le MCD est approuvé, il est figé. En réalité, les exigences métier évoluent. De nouvelles fonctionnalités sont ajoutées. Les réglementations évoluent. Le modèle de données doit évoluer avec elles.
Le refactoring d’une base de données est difficile. Changer le type d’une colonne ou une relation peut casser les applications existantes. Par conséquent, la conception doit être suffisamment souple pour accueillir les changements sans nécessiter une reconstruction complète. Les stratégies de maintenabilité incluent :
- Gestion de versions : Suivre les modifications du schéma au fil du temps.
- Scripts de migration : Automatiser le déploiement des modifications.
- Documentation : Maintenez le schéma à jour en parallèle du code.
La documentation est souvent négligée jusqu’à ce qu’il soit trop tard. Lorsqu’un développeur quitte le projet, les connaissances sur la structure des données disparaissent. Un MCD à jour sert de référence principale pour les nouveaux membres de l’équipe. Il réduit la courbe d’apprentissage et prévient les erreurs.
L’évolution exige de la discipline. Chaque changement doit être évalué en termes d’impact sur les données existantes. La compatibilité descendante doit être maintenue autant que possible. Cela garantit que les applications reposant sur la base de données ne cessent pas de fonctionner de manière inattendue.
7. Résumé des mythes courants vs. réalité
Pour résumer les points clés, nous pouvons catégoriser les malentendus les plus fréquents. Ce tableau fournit une référence rapide pour distinguer les affirmations marketing des faits techniques.
| Mythe | Réalité |
|---|---|
| Les diagrammes ER ne sont que de jolis dessins | Les diagrammes ER sont des contrats techniques définissant les règles des données |
| Plus de tables signifient une meilleure conception | La complexité réduit les performances ; l’équilibre est essentiel |
| La normalisation est toujours l’objectif | La dénormalisation améliore la vitesse de lecture dans certains cas |
| Les outils peuvent automatiser la conception | Les outils aident, mais la logique nécessite une surveillance humaine |
| Les modèles logiques équivalent aux schémas physiques | La mise en œuvre physique nécessite des optimisations spécifiques |
| La conception est permanente | Les schémas doivent évoluer avec les besoins métiers |
Réflexions finales sur la modélisation des données 🧭
Construire un système de base de données fiable exige une compréhension claire des principes fondamentaux. Les diagrammes Entité-Relation sont des outils puissants lorsqu’ils sont utilisés correctement. Ils fournissent un langage commun entre les parties prenantes métiers et les équipes techniques.
Cependant, ils ne sont pas magiques. Ils ne résolvent pas eux-mêmes les problèmes de données. La valeur vient de l’application rigoureuse de la logique pendant la phase de conception. Nous devons rejeter l’idée que les outils logiciels peuvent remplacer la pensée critique. Nous devons aussi accepter que la normalisation n’est pas une solution universelle.
Le succès dans la conception des bases de données dépend de la clarté, de la précision et de l’adaptabilité. En séparant le bruit marketing de la réalité technique, vous pouvez construire des systèmes robustes et évolutifs. Concentrez-vous sur l’intégrité des données et les règles métiers. Laissez le diagramme servir de guide, et non de destination.
Lorsque vous abordez la modélisation des données avec ces principes à l’esprit, les résultats parle d’eux-mêmes. Le système sera plus facile à maintenir. Les requêtes s’exécuteront plus rapidement. Les données resteront précises. Voilà la véritable valeur d’un diagramme Entité-Relation bien conçu.