











Los diagramas de relaciones de entidades (ERD) sirven como plano maestro para la arquitectura de bases de datos. Definen cómo se estructura, almacena y conecta la información dentro de una aplicación. Para los desarrolladores senior de backend, la capacidad de diseñar un esquema sólido es una habilidad fundamental. Sin embargo, la experiencia a veces genera complacencia. Incluso ingenieros con amplia experiencia caen en trampas que comprometen la integridad de los datos, el rendimiento del sistema y la mantenibilidad a largo plazo.
Esta guía examina los errores frecuentes que se encuentran durante la fase de diseño de ERD. Exploraremos errores técnicos específicos, sus consecuencias y las estrategias para evitarlos. El enfoque se mantiene en principios fundamentales, más que en herramientas o plataformas específicas.
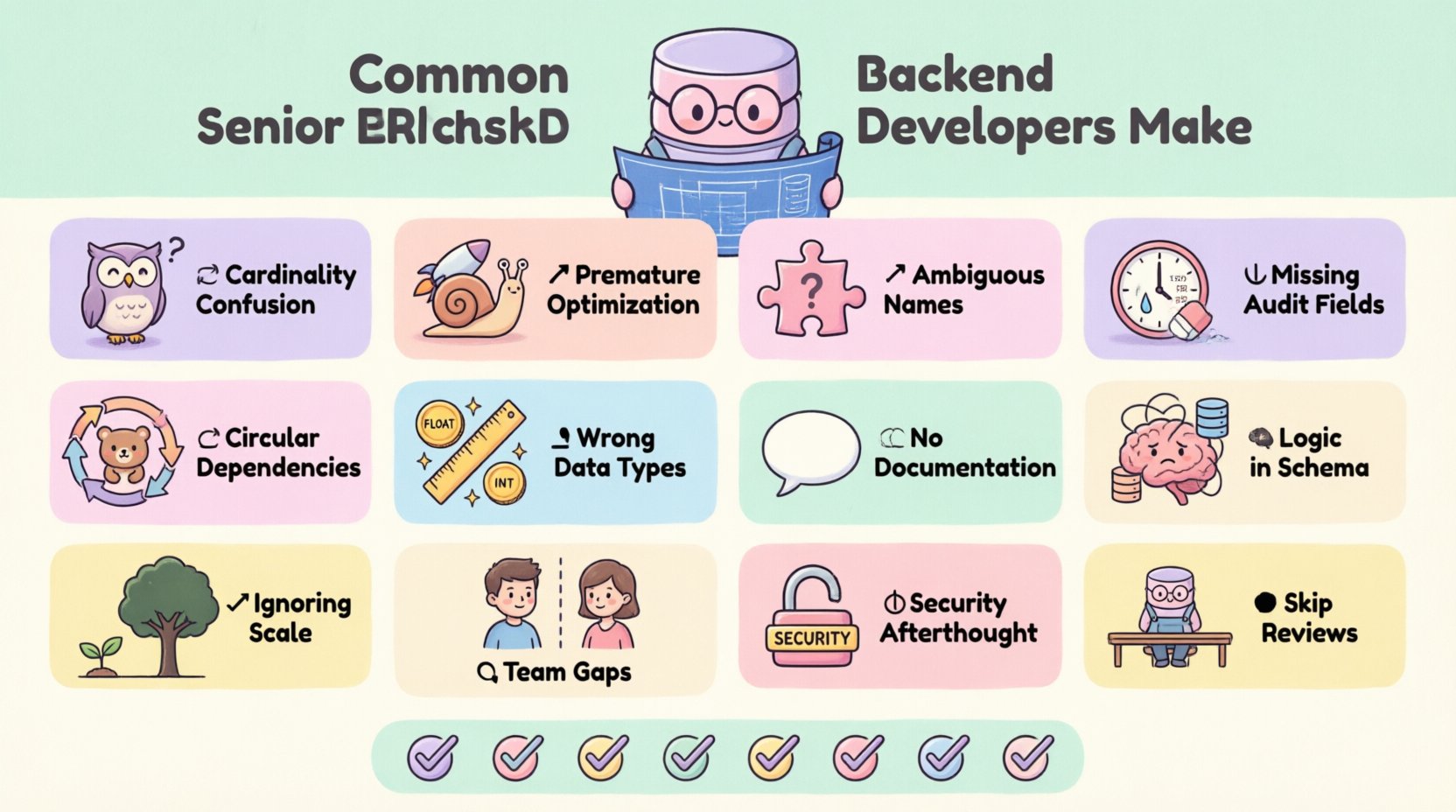
1. Interpretación incorrecta de las restricciones de cardinalidad 🔄
La cardinalidad define la relación numérica entre entidades. Mapear incorrectamente estas relaciones es quizás la fuente más común de anomalías en los datos. Los desarrolladores senior a menudo se apresuran en este paso, asumiendo que las relaciones son obvias sin una validación explícita.
Confusión entre uno a uno
Asumir una relación uno a uno donde existe una relación uno a muchos puede provocar pérdida de datos. Por ejemplo, si una Usuario entidad está vinculada a una Perfil entidad como uno a uno, pero la lógica de negocio permite múltiples perfiles con el tiempo, el esquema obliga a eliminar los datos antiguos.
- Impacto:Los datos históricos se vuelven inaccesibles.
- Solución:Revise el ciclo de vida de los datos. ¿Persiste una entidad o reemplaza a otra?
Omisiónes en relaciones muchos a muchos
Vincular directamente dos tablas con múltiples claves foráneas sin una tabla de unión intermedia crea redundancia. Una relación muchos a muchos requiere una entidad asociativa.
- Impacto:Duplicación de datos y anomalías de actualización.
- Solución:Introduzca una tabla de unión para resolver la relación.
2. Optimización prematura para el rendimiento 🚀
Es tentador normalizar los datos hasta el límite absoluto (Tercera Forma Normal) para reducir el almacenamiento. Por el contrario, algunos desarrolladores denormalizan demasiado pronto para acelerar las lecturas. Ambos extremos pueden causar problemas.
Sobrenormalización
Crear demasiadas tablas para detalles triviales aumenta el número de uniones necesarias para recuperar datos. Esto ralentiza la ejecución de consultas, especialmente bajo carga.
- Escenario:Almacenar una dirección en una tabla separada cuando solo se necesita una vez por registro de usuario.
- Consecuencia:Consultas complejas que son difíciles de mantener y optimizar.
Subnormalización
Duplicar datos entre tablas para evitar uniones crea un alto riesgo de inconsistencia. Si un usuario cambia su nombre, debe actualizarlo en cada tabla donde se almacena.
- Escenario:Incrustar nombres de productos directamente en los registros de pedidos.
- Consecuencia:Problemas de integridad de datos si los detalles del producto cambian más adelante.
3. Convenciones de nombres ambiguas 📝
Una nomenclatura clara es la base de la documentación y la comunicación. Cuando los nombres de tablas o columnas son ambiguos, el diagrama ERD se convierte en un rompecabezas para los desarrolladores futuros. Los desarrolladores senior deben imponer estándares estrictos.
- Nombres de tablas:Use sustantivos en plural (por ejemplo,
usuariosen lugar deusuario). - Claves foráneas: Nómbralas de forma consistente (por ejemplo,
id_usuarioen lugar deuidofk_usuario). - Campos booleanos: Prefija con
is_ohas_(por ejemplo,is_active).
La ambigüedad conduce a errores en los que los desarrolladores consultan la columna incorrecta o asumen que existe una relación cuando no la hay.
4. Ignorar eliminaciones suaves y campos de auditoría ⏳
Las eliminaciones permanentes eliminan los datos de forma definitiva. En muchos sistemas, esto no es deseable. Un diseño avanzado debe considerar las eliminaciones suaves (marcar un registro como inactivo en lugar de eliminarlo).
Faltan marcas de tiempo
Cada tabla debe registrar cuándo se creó una fila y cuándo se modificó por última vez. Sin created_at y updated_atcolumnas, depurar el historial de datos se vuelve casi imposible.
Ignorar las marcas de eliminación suave
Sin una marca como deleted_at, eliminar un registro afecta a todos los informes históricos que dependen de él. Esto interrumpe las rutas de auditoría y los requisitos de cumplimiento.
5. Dependencias circulares y referencias recursivas 🔁
Las jerarquías complejas a menudo conducen a claves foráneas circulares. Por ejemplo, si la tabla A referencia a la tabla B, y la tabla B referencia a la tabla A, se crea un ciclo.
- Problema:Esto puede impedir la inicialización de la base de datos o causar bucles infinitos durante las consultas recursivas.
- Referencia recursiva:Una tabla que se referencia a sí misma (por ejemplo,
empleadosreferenciandomanager_iddentro de la misma tabla) requiere una gestión cuidadosa de las restricciones.
Al diseñar estas estructuras, asegúrese de que al menos una entidad pueda existir de forma independiente sin la otra.
6. Tipos de datos y errores de precisión 📏
Elegir el tipo de dato incorrecto es un error sutil pero crítico. Afecta el tamaño de almacenamiento, el rendimiento y la precisión de los cálculos.
Float frente a Decimal
Usar números de punto flotante para el dinero es un error clásico. La aritmética de punto flotante introduce errores de redondeo que son inaceptables en contextos financieros.
- Recomendación:Utilice tipos decimales de punto fijo para el dinero.
Límites de longitud de cadena
Establecer una columna en VARCHAR(255) por defecto puede parecer seguro, pero desperdicia espacio si los datos reales son más cortos. Por el contrario, VARCHAR(50) podría ser demasiado corto para nombres de usuario o direcciones modernas.
- Recomendación: Analice los requisitos reales de datos antes de establecer límites.
7. Falta de documentación y comentarios 📄
Un ERD es un documento vivo. Sin comentarios que expliquen las reglas de negocio, el diagrama pierde valor con el tiempo. Los desarrolladores senior deben documentar las restricciones que no son evidentes.
- Reglas de negocio: Explique por qué una relación es opcional.
- Restricciones: Documente las restricciones únicas y las restricciones de verificación.
- Evolución: Anote por qué se tomó una decisión de diseño específica para referencia futura.
8. Mezclar lógica de dominio con el diseño de esquema 🧠
Los esquemas de base de datos deben almacenar datos, no lógica. Incorporar reglas de negocio directamente en la capa de base de datos (por ejemplo, mediante desencadenadores o procedimientos almacenados) hace que el sistema sea difícil de migrar o escalar.
- Práctica incorrecta: Imponer la lógica de validación en la base de datos.
- Buena práctica: Mantenga el esquema simple y mueva la lógica a la capa de aplicación.
Esta separación garantiza que la base de datos permanezca estable incluso si el código de la aplicación cambia.
9. Ignorar la escalabilidad y la partición 📈
Los diseños que funcionan para conjuntos de datos pequeños a menudo fallan a escala. Un desarrollador senior debe anticipar el crecimiento.
- Indizado: Planee índices para las columnas utilizadas en operaciones de búsqueda y unión.
- Partición: Considere cómo se dividirán las tablas si crecen hasta miles de millones de filas.
- Fragmentación: Comprenda qué claves se utilizarán para fragmentar los datos entre múltiples servidores.
Comparación: Errores comunes frente a mejores prácticas
| Área | Error común ❌ | Mejor práctica ✅ |
|---|---|---|
| Relaciones | Asumir 1:1 sin prueba | Validar la cardinalidad con los requisitos del negocio |
| Rendimiento | Sobrenormalización para almacenamiento | Equilibrar la normalización con las necesidades de consulta |
| Nombres | Alias cortos y ambiguos | Estándares de nomenclatura descriptivos y consistentes |
| Historial | Eliminaciones duras únicamente | Implementar eliminaciones suaves y registros de auditoría |
| Dinero | Usar Float/Double | Usar tipos Decimal/punto fijo |
| Lógica | Disparadores para validación | Validación a nivel de aplicación |
| Crecimiento | Sin estrategia de indexación | Planificar índices y particionamiento desde temprano |
10. Brechas de comunicación con los equipos de frontend 🤝
El esquema no se construye en el vacío. Debe servir a los contratos de la API que consumen las aplicaciones frontend. Una discrepancia entre el ERD y la estructura de respuesta de la API genera fricción.
- Conflictos de nombres:Las columnas de la base de datos suelen usar snake_case, mientras que las APIs usan camelCase. Asegúrese de tener una estrategia clara de mapeo.
- Exposición de datos: No expongas identificadores internos (como
user_id) en las API públicas a menos que sea necesario. Usa identificadores opacos si hay preocupación por seguridad. - Versionado: Planifica las migraciones de esquema. Los cambios en el ERD no deben romper a los clientes existentes.
11. Consideraciones de seguridad 🔒
La seguridad a menudo se considera al final en el diseño del ERD. Los datos sensibles requieren un manejo específico.
PII y cifrado
La información personalmente identificable (PII) debe identificarse en el esquema. Los campos que contengan correos electrónicos, números de teléfono o direcciones deben marcarse para cifrado o hashing.
Control de acceso
Aunque la base de datos maneja la seguridad a nivel de fila, el esquema debe respaldarla. Diseña tablas que permitan la aislamiento de inquilinos o el control de acceso basado en roles si se requiere multi-inquilino.
12. El factor humano: revisión y colaboración 👥
Incluso los mejores diseñadores se equivocan. La revisión entre pares es esencial. Una mirada fresca puede detectar una dependencia circular o un conflicto de nombres que el autor original pasó por alto.
- Revisión de diseño: Programa sesiones en las que el ERD se revisa línea por línea.
- Comentarios de los interesados: Asegúrate de que los expertos en el dominio verifiquen que el modelo de datos coincida con los procesos del mundo real.
- Documentación: Mantén el diagrama actualizado con la base de código.
Resumen de los puntos clave 📌
- Valida la cardinalidad: Nunca asumas relaciones. Verifícalas contra las reglas del negocio.
- Equilibra la normalización: Optimiza tanto para el almacenamiento como para el rendimiento de las consultas.
- Estandariza la nomenclatura: Usa convenciones claras y consistentes en todo el esquema.
- Planifica el historial: Implementa eliminaciones suaves y marcas de tiempo de auditoría.
- Elige los tipos con cuidado: Usa decimales para el dinero y longitudes adecuadas para las cadenas.
- Separar la lógica:Mantenga la base de datos para los datos, no para las reglas de negocio.
- Documentar todo:Explique el «por qué» detrás de las decisiones de diseño.
- Considerar la escalabilidad:Diseñe teniendo en cuenta el índice y la partición desde el primer día.
- Colaborar:Involucre al frontend y a los interesados en el proceso de diseño.
Diseñar un diagrama de relaciones de entidades es una tarea crítica que establece la base para toda la aplicación. Al evitar estos errores comunes, los desarrolladores senior de backend pueden asegurarse de que sus sistemas sean robustos, mantenibles y listos para crecer. El objetivo no es solo almacenar datos, sino estructurarlos de una manera que apoye indefinidamente al negocio.