











एंटिटी रिलेशनशिप डायग्राम (ERD) डेटाबेस आर्किटेक्चर के लिए ब्लूप्रिंट के रूप में कार्य करते हैं। वे यह निर्धारित करते हैं कि डेटा कैसे संरचित, स्टोर और एप्लिकेशन के भीतर जुड़ा है। सीनियर बैकएंड डेवलपर्स के लिए एक टिकाऊ स्कीमा डिजाइन करने की क्षमता एक मूलभूत कौशल है। हालांकि, अनुभव कभी-कभी आलस्य को जन्म दे सकता है। यहां तक कि अनुभवी इंजीनियर भी ऐसे फंदे में फंस जाते हैं जो डेटा अखंडता, सिस्टम प्रदर्शन और लंबे समय तक रखरखाव को कमजोर करते हैं।
यह गाइड एरडी डिजाइन चरण के दौरान सामना की जाने वाली अक्सर गलतियों का विश्लेषण करता है। हम विशिष्ट तकनीकी त्रुटियों, उनके परिणामों और उनसे बचने के तरीकों का अध्ययन करेंगे। ध्यान मूल सिद्धांतों पर बना रहेगा, विशिष्ट उपकरणों या प्लेटफॉर्म्स पर नहीं।
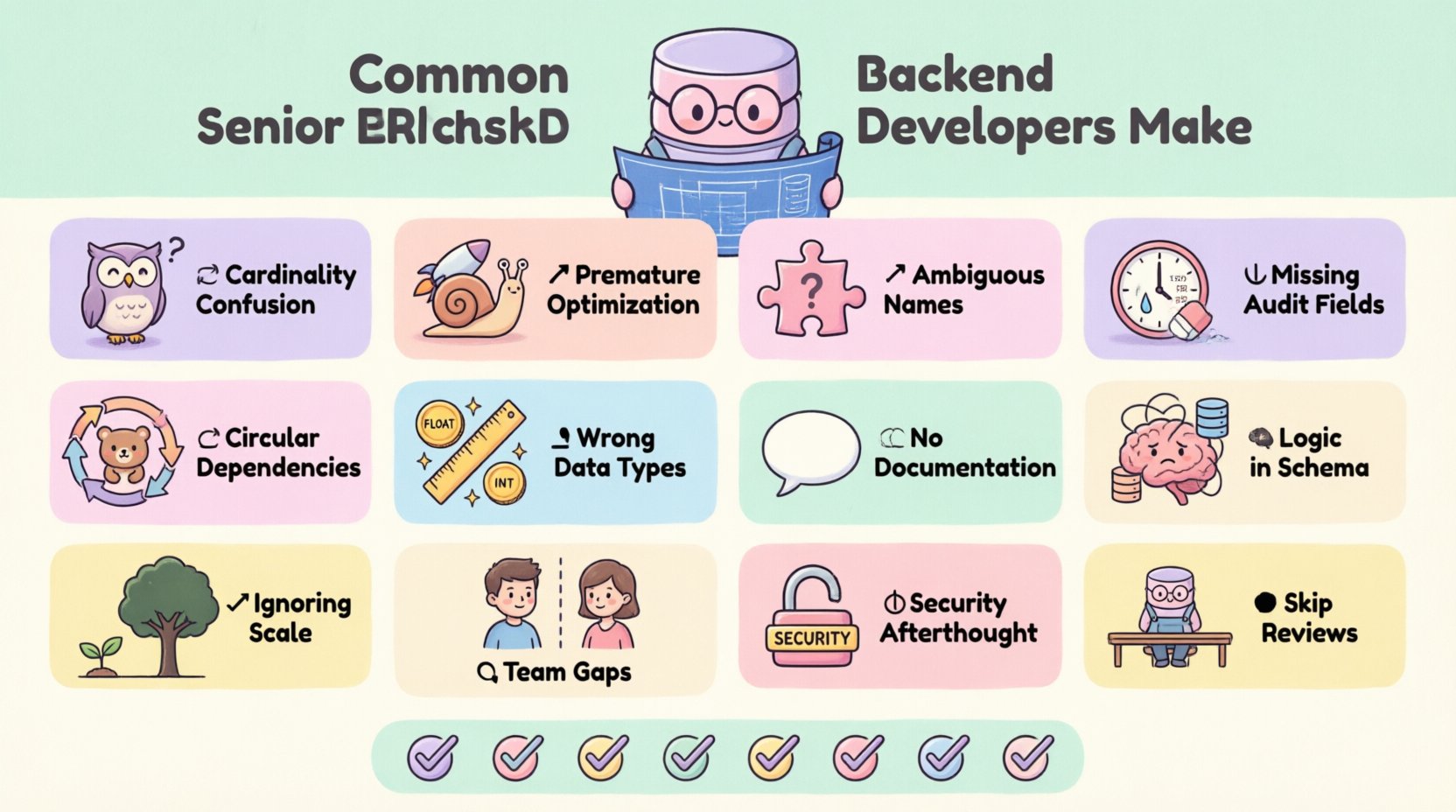
1. कार्डिनैलिटी सीमाओं का गलत अर्थ निकालना 🔄
कार्डिनैलिटी एंटिटी के बीच संख्यात्मक संबंध को परिभाषित करती है। इन संबंधों को गलत ढंग से मैप करना डेटा विचलन का सबसे आम कारण हो सकता है। सीनियर डेवलपर्स अक्सर इस चरण को जल्दी करते हैं, बिना स्पष्ट पुष्टि के संबंधों को स्पष्ट मान लेते हैं।
एक-से-एक भ्रम
एक-से-बहुत के स्थान पर एक-से-एक संबंध मानना डेटा के नुकसान का कारण बन सकता है। उदाहरण के लिए, यदि एक उपयोगकर्ता एंटिटी को एक प्रोफाइलएंटिटी के रूप में एक-से-एक के रूप में जुड़ी है, लेकिन व्यावसायिक तर्क समय के साथ बहुत सी प्रोफाइलों की अनुमति देता है, तो स्कीमा पुराने डेटा के हटाने के लिए मजबूर करता है।
- प्रभाव:ऐतिहासिक डेटा अप्राप्य हो जाता है।
- सुधार:डेटा के जीवनचक्र की समीक्षा करें। क्या एक एंटिटी दूसरी को बदलती है या बनी रहती है?
बहु-से-बहु लापरवाही
एक मध्यवर्ती जॉइन टेबल के बिना दो टेबल को बहुत सारे विदेशी कुंजियों के साथ सीधे जोड़ने से अतिरिक्तता उत्पन्न होती है। बहु-से-बहु संबंध के लिए एक सह-संबंधित एंटिटी की आवश्यकता होती है।
- प्रभाव:डेटा दोहराव और अपडेट विचलन।
- सुधार:संबंध को दूर करने के लिए एक जंक्शन टेबल शामिल करें।
2. प्रदर्शन के लिए अतिशीघ्र अनुकूलन 🚀
डेटा को भंडारण कम करने के लिए निरपेक्ष सीमा तक (तृतीय सामान्य रूप) सामान्यीकृत करने के लिए आकर्षक होता है। दूसरी ओर, कुछ डेवलपर्स पढ़ने को तेज करने के लिए अतिशीघ्र असामान्य बनाते हैं। दोनों चरम दुर्घटनाओं का कारण बन सकते हैं।
अत्यधिक सामान्यीकरण
साधारण विवरणों के लिए बहुत सारी टेबलें बनाने से डेटा प्राप्त करने के लिए आवश्यक जॉइन की संख्या बढ़ जाती है। इससे क्वेरी निष्पादन धीमा हो जाता है, खासकर भार के तहत।
- परिदृश्य:एक उपयोगकर्ता रिकॉर्ड प्रति बार केवल एक बार आवश्यक होने पर एक अलग टेबल में पता संग्रहीत करना।
- परिणाम:जटिल क्वेरीज जो रखरखाव और अनुकूलन के लिए कठिन हैं।
अपर्याप्त सामान्यीकरण
टेबलों में जॉइन को बचाने के लिए डेटा की दोहराई बनाने से असंगति का उच्च जोखिम होता है। यदि एक उपयोगकर्ता अपना नाम बदलता है, तो आपको उसे हर ऐसी टेबल में अपडेट करना होगा जहां इसका भंडारण किया गया है।
- परिदृश्य:आदेश रिकॉर्ड में उत्पाद नामों को सीधे एम्बेड करना।
- परिणाम:उत्पाद विवरण बाद में बदलने पर डेटा अखंडता की समस्याएं।
3. अस्पष्ट नामकरण प्रणाली 📝
स्पष्ट नामकरण दस्तावेजीकरण और संचार की आधारशिला है। जब टेबल या कॉलम के नाम अस्पष्ट होते हैं, तो भविष्य के विकासकर्ताओं के लिए ईआरडी एक पहेली बन जाती है। सीनियर विकासकर्ताओं को सख्त मानकों को लागू करना चाहिए।
- टेबल नाम: बहुवचन संज्ञा का उपयोग करें (उदाहरण के लिए,
उपयोगकर्ताके बजायउपयोगकर्ता). - विदेशी कुंजियाँ: उन्हें संगत रूप से नामित करें (उदाहरण के लिए,
उपयोगकर्ता_आईडीके बजायआईयूडीयाएफके_उपयोगकर्ता). - बूलियन फ़ील्ड्स: के साथ प्रीफिक्स करें
है_याहै_(उदाहरण के लिए,है_सक्रिय).
अस्पष्टता त्रुटियों का कारण बनती है जहां विकासकर्ता गलत कॉलम को प्रश्न करते हैं या तब भी संबंध मौजूद है ऐसा मान लेते हैं जब वास्तव में ऐसा नहीं होता।
4. सॉफ्ट डिलीट्स और ऑडिट फील्ड्स को नजरअंदाज करना ⏳
हार्ड डिलीट्स डेटा को स्थायी रूप से हटा देते हैं। बहुत सी प्रणालियों में ऐसा इच्छित नहीं होता है। एक उन्नत डिजाइन में सॉफ्ट डिलीट्स (एक रिकॉर्ड को हटाने के बजाय निष्क्रिय चिह्नित करना) को ध्यान में रखना चाहिए।
टाइमस्टैम्प्स का अभाव
हर टेबल में यह रिकॉर्ड करना चाहिए कि एक पंक्ति कब बनाई गई थी और अंतिम बार कब संशोधित की गई थी। बिना बनाए गए_समय और अद्यतन_किया_गया_समयकॉलम के बिना, डेटा इतिहास के निरीक्षण करना लगभग असंभव हो जाता है।
सॉफ्ट डिलीट फ्लैग्स को नजरअंदाज करना
एक फ्लैग जैसे बिना हटाए_गए_समय, एक रिकॉर्ड को हटाने से उस पर निर्भर सभी ऐतिहासिक रिपोर्ट्स प्रभावित होती हैं। इससे ऑडिट ट्रेल और सुसंगतता की आवश्यकताएं टूट जाती हैं।
5. चक्रीय निर्भरता और स्वयं-संदर्भित 🔁
जटिल हायरार्की अक्सर चक्रीय विदेशी कुंजियों की ओर जाती है। उदाहरण के लिए, यदि टेबल A टेबल B को संदर्भित करता है, और टेबल B टेबल A को संदर्भित करता है, तो इससे एक चक्र बनता है।
- समस्या: इससे डेटाबेस इनिशियलाइजेशन रोका जा सकता है या रिकर्सिव क्वेरी के दौरान अनंत लूप बन सकता है।
- स्वयं-संदर्भित: एक टेबल जो स्वयं को संदर्भित करती है (उदाहरण के लिए,
कर्मचारीसंदर्भित करता हैप्रबंधक_आईडीउसी टेबल के भीतर) को सावधानी से सीमा प्रबंधन की आवश्यकता होती है।
इन संरचनाओं के डिजाइन के समय, यह सुनिश्चित करें कि कम से कम एक एकांकी दूसरे के बिना स्वतंत्र रूप से अस्तित्व में रह सकता है।
6. डेटा प्रकार और सटीकता त्रुटियां 📏
गलत डेटा प्रकार चुनना एक सूक्ष्म लेकिन महत्वपूर्ण गलती है। इसका भंडारण आकार, प्रदर्शन और गणना की सटीकता पर प्रभाव पड़ता है।
फ्लोट बनाम दशमलव
मुद्रा के लिए फ्लोटिंग-पॉइंट संख्याओं का उपयोग एक प्राचीन गलती है। फ्लोटिंग-पॉइंट अंकगणित राउंडिंग त्रुटियों को लाता है जो वित्तीय संदर्भों में अस्वीकार्य हैं।
- सुझाव: पैसे के लिए फिक्स्ड-पॉइंट दशमलव प्रकार का उपयोग करें।
स्ट्रिंग लंबाई सीमाएं
कॉलम को सेट करना VARCHAR(255) डिफ़ॉल्ट रूप से सुरक्षित लग सकता है, लेकिन यदि वास्तविक डेटा छोटा है तो यह स्थान का बर्बाद करता है। विपरीत रूप से, VARCHAR(50) आधुनिक उपयोगकर्ता नामों या पतों के लिए बहुत छोटा हो सकता है।
- सुझाव: सीमाओं को सेट करने से पहले वास्तविक डेटा आवश्यकताओं का विश्लेषण करें।
7. दस्तावेज़ीकरण और टिप्पणियों की कमी 📄
एक ईआरडी एक जीवित दस्तावेज़ है। व्यापार नियमों को समझाने वाली टिप्पणियों के बिना, आरेख समय के साथ मूल्य खो देता है। सीनियर डेवलपर्स को उन सीमाओं को दस्तावेज़ करना चाहिए जो स्पष्ट नहीं हैं।
- व्यापार नियम: बताएं कि किसी संबंध को वैकल्पिक क्यों बनाया गया है।
- सीमाएं: यूनिक सीमाओं और चेक सीमाओं को दस्तावेज़ करें।
- विकास: भविष्य के संदर्भ के लिए नोट करें कि एक विशिष्ट डिज़ाइन निर्णय क्यों लिया गया था।
8. डोमेन लॉजिक को स्कीमा डिज़ाइन के साथ मिलाना 🧠
डेटाबेस स्कीमा डेटा संग्रहीत करना चाहिए, न कि लॉजिक। व्यापार नियमों को डेटाबेस लेयर में सीधे एम्बेड करना (उदाहरण के लिए ट्रिगर्स या स्टोर्ड प्रोसीजर के माध्यम से) सिस्टम को माइग्रेट या स्केल करने में कठिनाई पैदा करता है।
- बुरी प्रथा: डेटाबेस में वैधता लॉजिक को लागू करना।
- अच्छी प्रथा: स्कीमा को सरल रखें और लॉजिक को एप्लीकेशन लेयर में स्थानांतरित करें।
इस अलगाव से यह सुनिश्चित होता है कि यदि एप्लीकेशन कोड बदलता है तो डेटाबेस स्थिर रहता है।
9. स्केलेबिलिटी और पार्टीशनिंग को नजरअंदाज़ करना 📈
छोटे डेटासेट के लिए काम करने वाले डिज़ाइन अक्सर स्केल पर विफल हो जाते हैं। एक सीनियर डेवलपर को वृद्धि की अपेक्षा करनी चाहिए।
- इंडेक्सिंग: खोज और जॉइन ऑपरेशन में उपयोग किए जाने वाले कॉलम के लिए इंडेक्स की योजना बनाएं।
- पार्टीशनिंग: विचार करें कि यदि तालिकाएं बिलियन पंक्तियों तक बढ़ जाएं तो उन्हें कैसे विभाजित किया जाएगा।
- शार्डिंग: समझें कि किन कीज़ का उपयोग किया जाएगा ताकि डेटा को कई सर्वरों पर शार्ड किया जाए।
तुलना: सामान्य गलतियाँ बनाम सर्वोत्तम प्रथाएँ
| क्षेत्र | सामान्य गलती ❌ | सर्वोत्तम प्रथा ✅ |
|---|---|---|
| संबंध | साक्ष्य के बिना 1:1 मान लेना | व्यापार आवश्यकताओं के साथ कार्डिनैलिटी की पुष्टि करें |
| प्रदर्शन | स्टोरेज के लिए अत्यधिक सामान्यीकरण | सामान्यीकरण और प्रश्न की आवश्यकताओं के बीच संतुलन बनाएँ |
| नाम | छोटे, अस्पष्ट एलियास | वर्णनात्मक, स्थिर नामकरण मानक |
| इतिहास | केवल कठोर हटाना | मृदु हटाने और लेखा परीक्षण लॉग कार्यान्वित करें |
| पैसा | फ्लोट/डबल का उपयोग करना | दशमलव/स्थिर-बिंदु प्रकारों का उपयोग करें |
| तर्क | सत्यापन के लिए ट्रिगर | एप्लिकेशन-स्तरीय सत्यापन |
| वृद्धि | कोई इंडेक्सिंग रणनीति नहीं | इंडेक्स और विभाजन की योजना शुरू में बनाएँ |
10. फ्रंटएंड टीमों के साथ संचार के अंतराल 🤝
स्कीमा को एक निर्वात में नहीं बनाया जाता है। इसे फ्रंटएंड एप्लिकेशन द्वारा उपयोग किए जाने वाले API कॉन्ट्रैक्ट्स को सेवा करना चाहिए। ERD और API उत्तर संरचना के बीच असंगति तनाव पैदा करती है।
- नाम संघर्ष:डेटाबेस कॉलम अक्सर स्नेक_केस का उपयोग करते हैं, जबकि APIs कैमल_केस का उपयोग करते हैं। स्पष्ट मैपिंग रणनीति सुनिश्चित करें।
- डेटा उजागर: आ inter nal आईडी (जैसे
उपयोगकर्ता_आईडी) सार्वजनिक एपीआई में तब तक न दिखाएं जब तक आवश्यक न हो। सुरक्षा के मामले में अस्पष्ट पहचानकर्ता का उपयोग करें। - संस्करण निर्माण: स्कीमा माइग्रेशन के लिए योजना बनाएं। ईआरडी में परिवर्तन मौजूदा क्लाइंट्स को तोड़ने नहीं चाहिए।
11. सुरक्षा पर विचार 🔒
सुरक्षा अक्सर ईआरडी डिजाइन में बाद में ध्यान में लाई जाती है। संवेदनशील डेटा को विशिष्ट तरीके से संभालने की आवश्यकता होती है।
पीआईआई और एन्क्रिप्शन
व्यक्तिगत रूप से पहचाने जाने वाली जानकारी (पीआईआई) को स्कीमा में पहचाना जाना चाहिए। ईमेल, फोन नंबर या पते वाले फ़ील्ड को एन्क्रिप्शन या हैशिंग के लिए चिह्नित किया जाना चाहिए।
पहुंच नियंत्रण
जबकि डेटाबेस पंक्ति-स्तरीय सुरक्षा का प्रबंधन करता है, स्कीमा इसका समर्थन करना चाहिए। यदि बहु-प्रयोगकर्ता संरचना आवश्यक है, तो टेंट अलगाव या भूमिका-आधारित पहुंच नियंत्रण के लिए तालिकाओं को डिज़ाइन करें।
12. मानव तत्व: समीक्षा और सहयोग 👥
यहां तक कि सर्वश्रेष्ठ डिज़ाइनर भी कुछ चूक जाते हैं। सहकर्मी समीक्षा अनिवार्य है। एक ताज़ा नज़र एक चक्रीय निर्भरता या नामकरण टकराव को देख सकती है जिसे मूल लेखक ने नज़रअंदाज़ कर दिया था।
- डिज़ाइन समीक्षा: ऐसे सत्रों की योजना बनाएं जहां ईआरडी को लाइन दर लाइन चलाया जाए।
- हितधारक प्रतिक्रिया: सुनिश्चित करें कि क्षेत्र विशेषज्ञ डेटा मॉडल के वास्तविक दुनिया के प्रक्रियाओं के साथ मेल खाता है यह सुनिश्चित करें।
- दस्तावेज़ीकरण: आरेख को कोडबेस के साथ अद्यतन रखें।
मुख्य बातों का सारांश 📌
- कार्डिनैलिटी की पुष्टि करें: कभी भी संबंधों के बारे में अनुमान न लगाएं। व्यापार नियमों के खिलाफ उनकी पुष्टि करें।
- नॉर्मलाइज़ेशन का संतुलन बनाएं: स्टोरेज और प्रश्न प्रदर्शन दोनों के लिए अनुकूलित करें।
- नामकरण मानकीकरण: स्कीमा के भीतर स्पष्ट, संगत नियमों का उपयोग करें।
- इतिहास के लिए योजना बनाएं: सॉफ्ट डिलीट और लेखा टाइमस्टैम्प लागू करें।
- प्रकारों का ध्यान से चयन करें: पैसे के लिए दशमलव का उपयोग करें और स्ट्रिंग्स के लिए उचित लंबाई का उपयोग करें।
- लॉजिक को अलग करें: डेटाबेस को डेटा के लिए रखें, व्यापार नियमों के लिए नहीं।
- सब कुछ दस्तावेज़ीकरण करें: डिज़ाइन निर्णयों के पीछे के “क्यों” की व्याख्या करें।
- स्केल को ध्यान में रखें: दिन भर के लिए इंडेक्सिंग और पार्टीशनिंग को ध्यान में रखते हुए डिज़ाइन करें।
- सहयोग करें: डिज़ाइन प्रक्रिया में फ्रंटएंड और हितधारकों को शामिल करें।
एक एंटिटी रिलेशनशिप डायग्राम डिज़ाइन करना एक महत्वपूर्ण कार्य है जो पूरे एप्लिकेशन के आधार को तय करता है। इन सामान्य गलतियों से बचकर, सीनियर बैकएंड डेवलपर्स यह सुनिश्चित कर सकते हैं कि उनके सिस्टम टिकाऊ, रखरखाव योग्य और वृद्धि के लिए तैयार हैं। लक्ष्य केवल डेटा स्टोर करना नहीं है, बल्कि उसे इस तरह संरचित करना है जो व्यापार को अनंतकाल तक समर्थन करे।